
基于潜在语义分析的文本挖掘方法主要包括:
LSA(Latent Semantic Analysis)
PLSA(Probabilistic Latent Semantic Analysis)
LDA(Latent Dirichlet Allocation)
这里为什么是潜在语义呢?
顾名思义是通过分析文章(documents )来挖掘文章的潜在意思或语义(concepts )。如果每个单词都仅以着一个语义,同时每个语义仅仅由一个单词来表示,那么简单地将进行语义和单词间的映射。不幸的是,不同的单词可以表示同一个语义,或一个单词同时具有多个不同的意思,这些的模糊歧义使语义的准确识别变得十分困难。
一、导入第三方库
二、中文分词
三、LDA分析


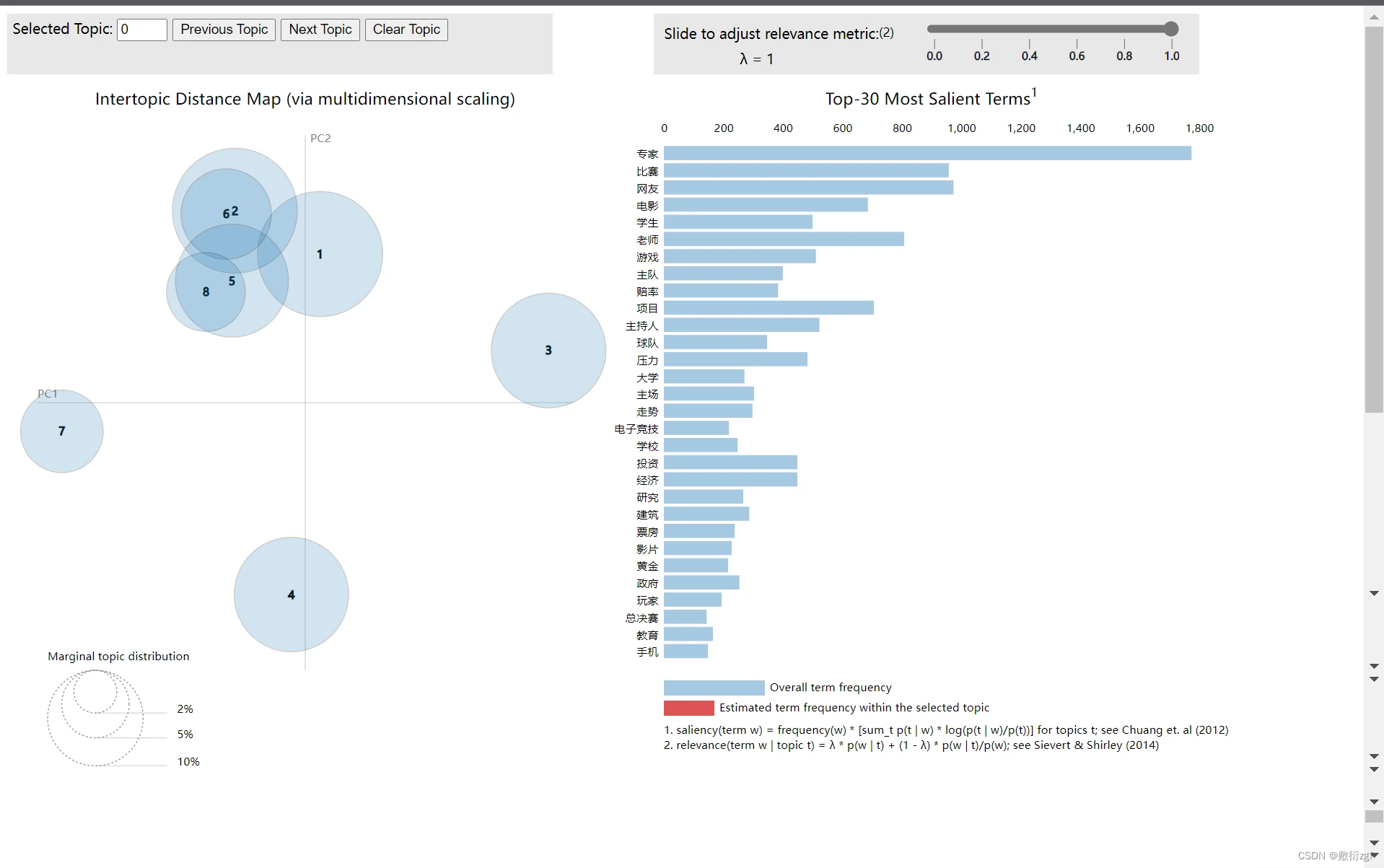
这里的主题数为啥是自定义为8(0~7),并不是凭空想象的,接下来可以通过可视化数据以及主题困惑度的方法得到最优的主题数。
四、可视化
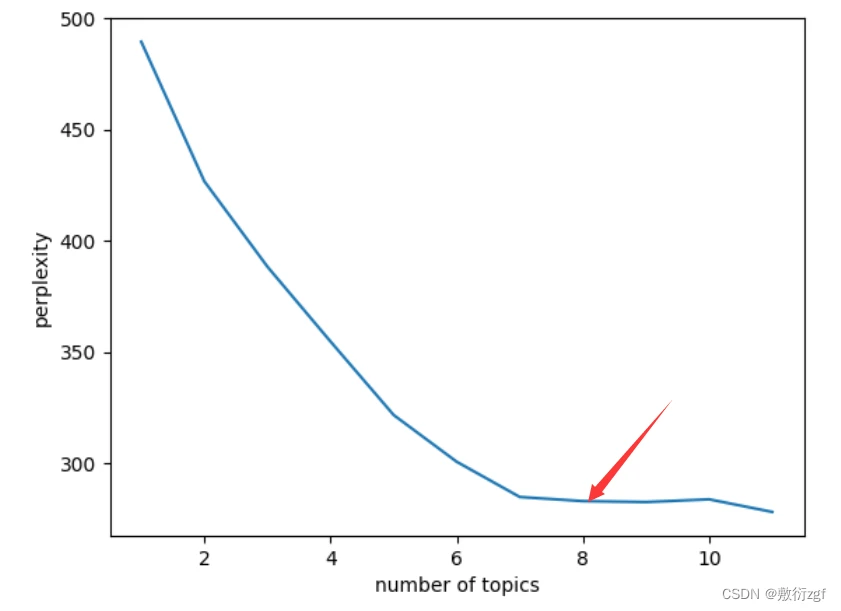
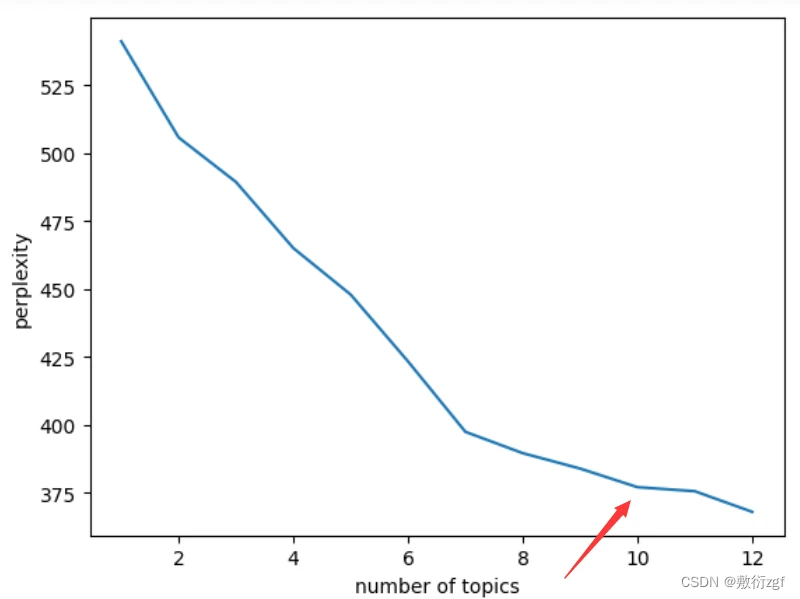
五、主题困惑度
六、导出生成的主题号与原始主题进行对比
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/38911.html