
图是一种抽象数据结构,本质和树结构是一样的。
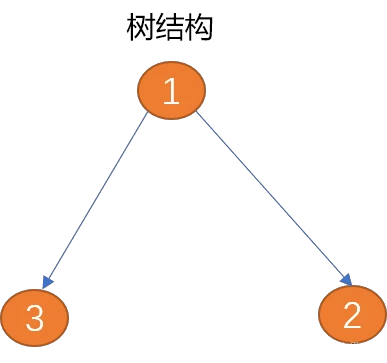
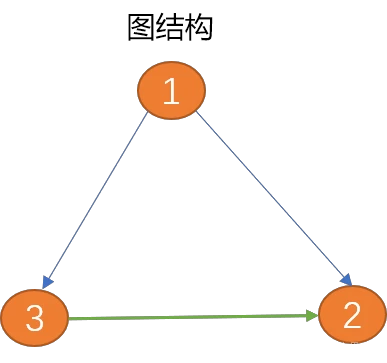
图与树相比较,图具有封闭性,可以把树结构看成是图结构的前生。在树结构中,如果把兄弟节点之间或子节点之间横向连接,便构建成一个图。
树适合描述从上向下的一对多的数据结构,如公司的组织结构。
图适合描述更复杂的多对多数据结构,如复杂的群体社交关系。
借助计算机解决现实世界中的问题时,除了要存储现实世界中的信息,还需要正确地描述信息之间的关系。
如在开发地图程序时,需要在计算机中正确模拟出城市与城市、或城市中各道路之间的关系图。在此基础上,才有可能通过算法计算出从一个城市到另一个城市、或从指定起点到目标点间的最佳路径。
类似的还有航班路线图、火车线路图、社交交系图。
图结构能很好的对现实世界中如上这些信息之间的复杂关系进行映射。以此可使用算法方便的计算出如航班线路中的最短路径、如火车线路中的最佳中转方案,如社交圈中谁与谁关系最好、婚姻网中谁与谁最般配……
顶点:顶点也称为节点,可认为图就是顶点组成的集合。顶点本身是有数据含义的,所以顶点都会带有附加信息,称作"有效载荷"。
顶点可以是现实世界中的城市、地名、站名、人……
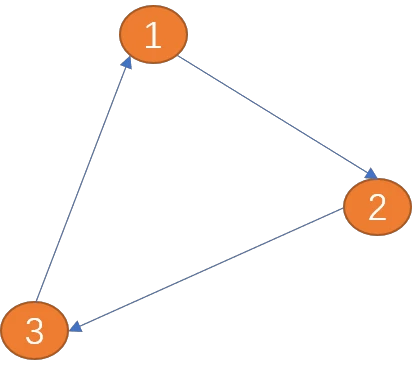
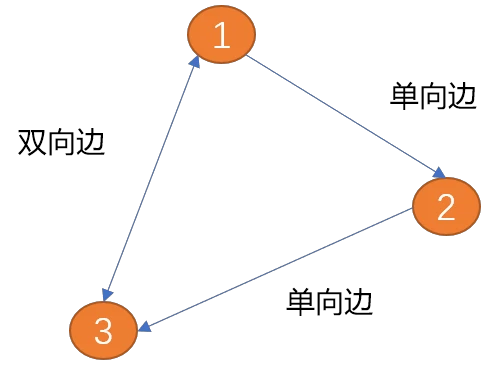
边: 图中的边用来描述顶点之间的关系。边可以有方向也可以没有方向,有方向的边又可分为单向边和双向边。
如下图(项点1)到(顶点2)之间的边只有一方向(箭头所示为方向),称为单向边。类似现实世界中的单向道。
(顶点1)到(顶点2)之间的边有两个方向(双向箭头),称为双向边。 城市与城市之间的关系为双向边。
权重: 边上可以附加值信息,附加的值称为权重。有权重的边用来描述一个顶点到另一个顶点的连接强度。
如现实生活中的地铁路线中,权重可以描述两个车站之间时间长度、公里数、票价……
边描述的是顶点之间的关系,权重描述的是连接的差异性。
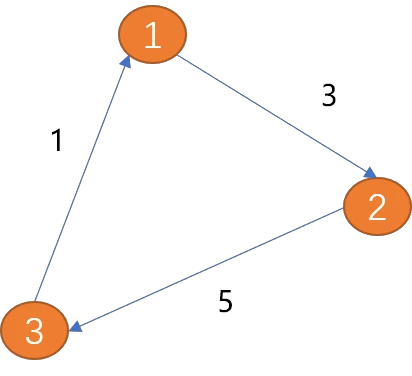
路径:
先了解现实世界中路径概念
如:从一个城市开车去另一个城市,就需要先确定好路径。也就是 从出发地到目的地要经过那些城市?要走多少里程?
可以说路径是由边连接的顶点组成的序列。因路径不只一条,所以,从一个项点到另一个项点的路径描述也不指一种。
在图结构中如何计算路径?
- 无权重路径的长度是路径上的边数。
- 有权重路径的长度是路径上的边的权重之和。
如上图从(顶点1)到(顶点3)的路径长度为 8。
环: 从起点出发,最后又回到起点(终点也是起点)就会形成一个环,环是一种特殊的路径。如上 就是一个环。
图的类型:
综上所述,图可以分为如下几类:
- 有向图: 边有方向的图称为有向图。
- 无向图: 边没有方向的图称为无向图。
- 加权图: 边上面有权重信息的图称为加权图。
- 无环图: 没有环的图被称为无环图。
- 有向无环图: 没有环的有向图,简称 DAG。
根据图的特性,图数据结构中至少要包含两类信息:
所有顶点构成集合信息,这里用 V 表示(如地图程序中,所有城市构在顶点集合)。
所有边构成集合信息,这里用 E 表示(城市与城市之间的关系描述)。
如何描述边?
边用来表示项点之间的关系。所以一条边可以包括 3 个元数据(起点,终点,权重)。当然,权重是可以省略的,但一般研究图时,都是指的加权图。
如果用 表示图,则 。每一条边可以用二元组 也可以使用 三元组 描述。
表示起点, 表示终点。且 , 数据必须引用于 集合。
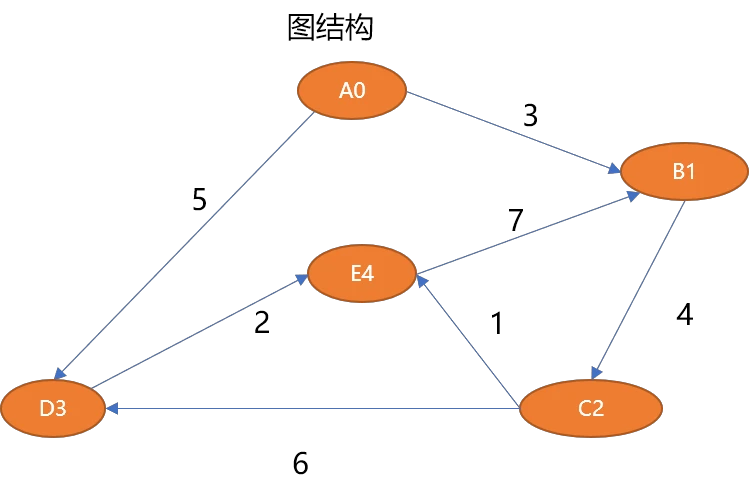
如上的图结构可以描述如下:
图的抽象数据描述中至少要有的方法:
- : 用来创建一个新图。
- :向图中添加一个新节点,参数应该是一个节点类型的对象。
- :在 2 个项点之间建立起边关系。
- :在 2 个项点之间建立起一条边并指定连接权重。
- : 根据关键字 key 在图中查找顶点。
- :查询所有顶点信息。
- :查找.从一个顶点到另一个顶点之间的路径。
图的存储实现主流有 2 种:邻接矩阵和链接表,本文主要介绍邻接矩阵。
使用二维矩阵(数组)存储顶点之间的关系。
如 可以存储 5 个顶点的关系数据,行号和列号表示顶点,第 v 行的第 w 列交叉的单元格中的值表示从顶点 v 到顶点 w 的边的权重,如 表示 C2 顶点和 D3 顶点的有连接(相邻),权重为 6
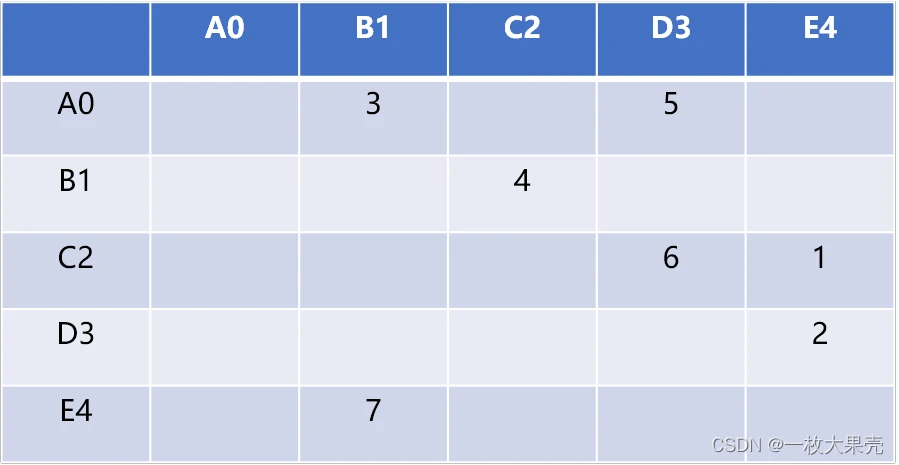
相邻矩阵的优点就是简单,可以清晰表示那些顶点是相连的。因不是每两两个顶点之间会有连接,会导致大量的空间闲置,称这种矩阵为”稀疏“的。
只有当每一个顶点和其它顶点都有关系时,矩阵才会填满。所以,使用这种结构存储图数据,对于关系不是很复杂的图结构而言,会产生大量的空间浪费。
邻接矩阵适合表示关系复杂的图结构,如互联网上网页之间的链接、社交圈中人与人之间的社会关系……
因顶点本身有数据含义,需要先定义顶点类型。
顶点类:
顶点类中 和 很好理解。为什么要添加一个 ?
这个变量用来记录顶点在路径搜索过程中是否已经被搜索过,避免重复搜索计算。
图类:图类的方法较多,这里逐方法介绍。
初始化方法
初始化方法用来初始化图中的数据类型:
一维列表 保存所有顶点数据。
二维列表 保存顶点与顶点之间的关系数据。
使用列表模拟队列或栈,用于后续的广度搜索和深度搜索。
怎么使用列表模拟队列或栈?
列表有 、 2 个很价值的方法。
用来向列表中添加数据,且每次都是从列表最后面添加。
默认从列表最后面删除且弹出数据, 可以提供索引值用来从指定位置删除且弹出数据。
使用 append() 和 pop() 方法就能模拟栈,从同一个地方进出数据。
使用 append() 和 pop(0) 方法就能模拟队列,从后面添加数据,从最前面获取数据
: 用来保存使用广度或深度优先路径搜索中的结果。
添加新节(顶)点方法:
上述方法注意一点,节点的编号由图内部逻辑提供,便于节点编号顺序的统一。
添加边方法
此方法是邻接矩阵表示法的核心逻辑。
添加边信息的方法有 2 个,一个用来添加无权重边,一个用来添加有权重的边。
查找某节点
使用线性查找法从节点集合中查找某一个节点。
查询所有节点
此方法仅为了查询方便。
查询节点之间的关系
测试代码:
在图中经常做的操作,就是查找从一个顶点到另一个顶点的路径。如怎么查找到 A0 到 E4 之间的路径长度:
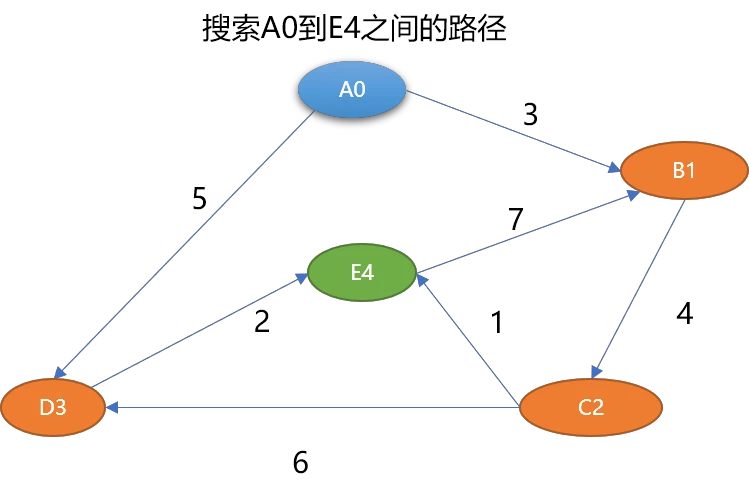
从人的直观思维角度查找一下,可以找到如下路径:
- 路径长度为 8。
- 路径长度为 7。
- 路径长度为 15。
人的思维是知识性、直观性思维,在路径查找时不存在所谓的尝试或碰壁问题。而计算机是试探性思维,就会出现这条路不通,再找另一条路的现象。
所以路径算法中常常会以错误为代价,在查找过程中会走一些弯路。常用的路径搜索算法有 2 种:
- 广度优先搜索
- 深度优先搜索
先看一下广度优先搜索的示意图:
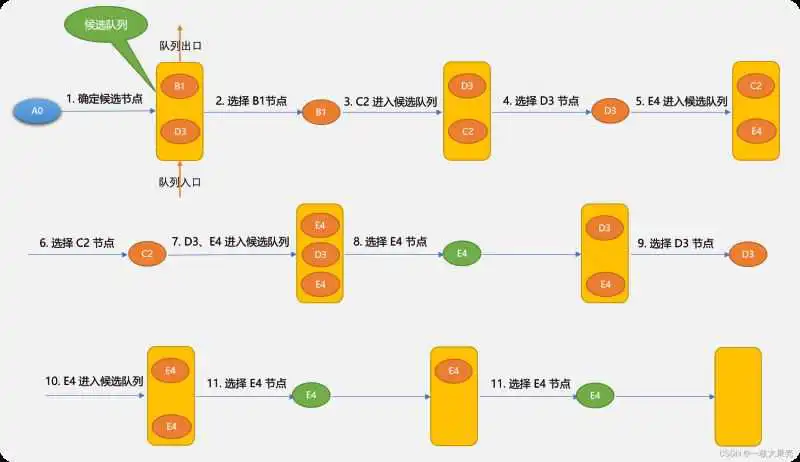
广度优先搜索的基本思路:
- 确定出发点,本案例是 A0 顶点。
- 以出发点相邻的顶点为候选点,并存储至队列。
- 从队列中每拿出一个顶点后,再把与此顶点相邻的其它顶点做为候选点存储于队列。
- 不停重复上述过程,至到找到目标顶点或队列为空。
使用广度搜索到的路径与候选节点进入队列的先后顺序有关系。如第 1 步确定候选节点时 和 谁先进入队列,对于后面的查找也会有影响。
上图使用广度搜索可找到 路径是:
其实 也是一条有效路径,有可能搜索不出来,这里因为搜索到 后不会马上搜索 ,因为 先于 进入,广度优先搜索算法只能保证找到路径,而不能保存找到最佳路径。
编码实现广度优先搜索:
广度优先搜索需要借助队列临时存储选节点,本文使用列表模拟队列。
在图类中实现广度优先搜索算法的方法:
广度优先搜索过程中,需要随时获取与当前节点相邻的节点, 方法的作用就是用来把当前节点的相邻节点压入队列中。
测试广度优先搜索算法:
使用递归实现广度优先搜索算法:
先看一下深度优先算法的示意图。
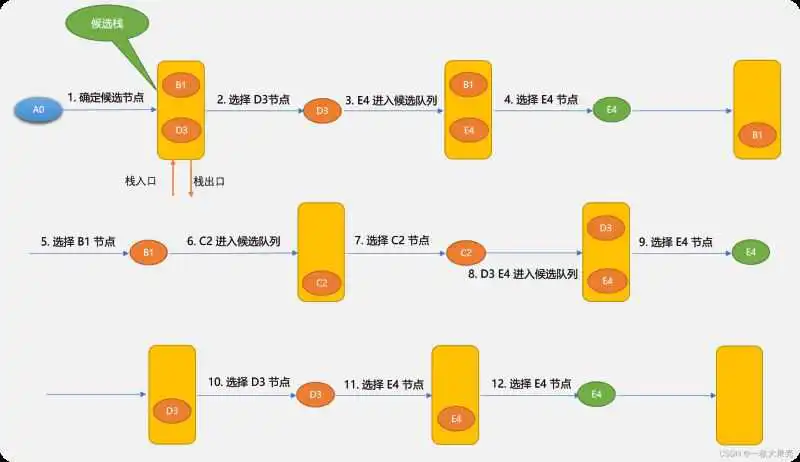
深度优先搜索算法与广度优先搜索算法不同之处:候选节点是放在栈中的。因栈是先进后出,所以,搜索到的节点顺序不一样。
使用循环实现深度优先搜索算法:
深度优先搜索算法需要用到栈,本文使用列表模拟。
测试:
使用递归实现深度优先搜索算法:
递归实现时,不需要使用全局栈,只需要获到当前节点的相邻节点便可。
图是一种很重要的数据结构,因这个世界中万事万物之间的关系并不是简单的你和我,我和你的关系,本质都是错综复杂的。
图能准确的映射现实世界的这种错综复杂关系,为计算机处理现实世界的问题提供了可能,也拓展了计算机在现实世界的应用领域。
到此这篇关于Python实现图的广度和深度优先路径搜索算法的文章就介绍到这了,更多相关Python图 路径搜索内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
到此这篇广度优先搜索实现(广度优先搜索实现方法)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/48347.html