
hashMap的源码我们分三块来看,第一块就是HashMap的容器初始化,第二块就是put方法的流程,第三块就是get方法的流程。
首先,我们先来看一下hashmap是怎么初始化的。直接进入hashmap的构造函数里。这里可以看到这个无参构造函数只是做了一个loadFactor的初始化,初始化的值为0.75, 其实就是我们底层容器数据扩容的一个值,叫做加载因子, 意思就是当数组里面的元素已经占到百分之七十五时,那么我们这个数据就要提前进行扩容了。 我们看这个注释其实就够了,这里就是说要构造一个空的hashMap,它的默认初识容量是16,并且默认的加载因子是0.75。
这个方法还是很简单的,接下来我们就看一个复杂一点的有参构造函数。这个构造函数需要传一个initialCapacity,就是一个初始容量,我们可以传一个10进来。
进入tableSizeFor方法,同样是先看注释,这里的注释意思就是要返回一个给定目标容量的2次幂。 再详细一点来说,就是要返回一个大于或者等于cap值的最小2的幂, 举个例子, 我们来看一下2的幂有哪些值,比如说2的0次方就是1, 2的1次方就是2, 2的2次方就是4,2的3次方就是8。 那么此时我传入的cap是10的话,那我就要在这里找一个大于10的最小值,所以没啥疑问,这肯定就是16了。 如果传入的cap是33的话,那么这里返回的就是64了。
假如说我们这里传入的cap是65,那么这里的n就是64,减了一。
然后,这里执行了一个n |= n >>> 1的操作,这个操作其实有两步,第一步是n向右移动1位,这个移位操作,是在二进制下执行的。所以,我们先得把64从10进制转为2进制,64的二进制,就是0。然后我们要把0右移一位,就是得到,并且,高位要补0,就是0。补完之后,我们还要将这个 移位的值和原始的值做一个或运算, 这个等号前面的竖线就是或运算符。或运算,我们看到图里,1或1的时候,就是1, 1 或0的时候还是1, 0或0的时候,就是0了。意思就是只要有 1,那么结果就是1。那我们这里计算的时候,就能得到一个 0的结果。

此时,如果我们再给他执行一次向右移动一位的操作的话,就会得到0, 然后再进行或运算,就得到一个0。

如果咱们再右移一位,那么就是这样的结果。

这里经过两次的位移运算,其实我们可以找到一个规律。它这里其实就是在做一个抹零的操作,从最高位的1开始,一步一步往后抹零。

所以如果我们每次右移一位的话,在一个最坏的情况下,就是cap取最大值的时候,就是1 << 30,这个值是000000000000000000000,如果我们要把后面30个零抹掉的话,就要右移并做或运算30次才能得到这个结果,这样,其实是比较浪费性能的。

所以,这里回到代码。它这里仅仅是第一次右移一位,第二次,就是右移两位了。我们可以来看一下这个变化。

所以,这里通过这种优化,将30次的位移运算减少到了5次。回到代码里,我们这里如果cap传的是65的话,那么64通过这五次位移,得出来的一个二进制结果就是0。这个二进制转为10进制就是127,然后return的时候,会将127+1,那么就是128了!65最接近的最小2的幂,就是128。OK,代码走下去,这里的初始化流程就结束了。
初始化完成了之后,那么我们就来看一下怎么把元素添加到容器里面。我们直接debug到put里面去。这里它又重新调用了一个putVal方法,里面会将key的hash值,key的原始值,value值都传进去,并且,这里有两个别的参数,这两个参数后面我们在看源码的时候再讲。
1.2.1、hash计算
我们先来看一下这里是怎么去获取key的hash值的。如果key为null的话,那么这里的hash直接返回0,如果不是null的话,那就直接调用一个hashCode的native方法,这里咱们就不深入下去了。它这里就是会返回一个32位的hashCode。拿到hashCode后,它还要把这个hashCode右移16位,并且还要将原始的hashCode和右移后的hashCode做一个异或运算。那这又是什么操作,求出了hash,还要做一些这么复杂的事情。这里来算一下:
1. 第一步,我们在debug里先拿到这个key的原始hashCode,-, 拿到之后我们可以把这个值转二进制来看一下。
2. 拿到这个值之后,我们就来做一个右移16位的运算。

3. 做完右移运算之后,这里还得做一个异或运算,可以看到1和1,还有0和0的结果都是0,只要是相同的就是0。

4. 这里这样做的原因,就是Java为了尽最大的努力避免hash冲突才这样设计的。它是怎么尽力的,我们再看看一下。这里其实要和这里的寻址算法来综合着看。假如说,咱们put了两个key过来了,一个username,一个password。他们的原始的hashCode假设分别是这俩,如果咱们的数
组的长度是16,那么通过tab[i = (n - 1) & hash]这个寻址算法,就可以通过将hashcode和15进行与运算了,与运算,就是都要为1的才能是1,不然就是0。那么15的二进制是四个1。
此时我们对这两个原始的hashCode来做与运算,假如说这两个hash的低位都是一样的,只有高位不一样,因为只有低位在做与运算,高位参与不进来,所以高位就相当于没用,低位一样就导致了 hash冲突。所以为了避免hash冲突, hashMap让高位也参与了运算。

但是,我们如果让高位和低位进行一个异或运算的话,那这个结果就会根据高位的不同而发生改变,自然hash冲突的概率就小了。其实说白了,很简单,就像你去一个地方找人,然后你看到一个人和你想找的人的眼睛很像,那你就能确定这个就是你要找的人吗,那肯定不行,所以最好是能多一点条件,比如说,鼻子,嘴巴,耳朵等等等等。这个扰动函数也是相同的原理,你要尽可能让更多的元素来参与寻址运算。
1.2.1.1、 第一阶段:初始化数组
我们debug进到putVal里面,这里,因为我们是第一次put值到hashMap里,此时hashMap里的这个数组它是还没有创建的。这里其实就是有一个懒加载的机制,当你真正要用到hashMap的时候,我才会创建这个数组,这样在某些情况下,就避免了一些内存空间上的浪费。OK,我们来看下源码是怎么实现的初始化。
我们再debug到resize里面,看看这个初始化数组是怎么做的。
1.2.1.2、 第二阶段:put第一个值进去
回到putVal方法。这里n就是返回16了。
接着往下执行。
执行完这里,咱们第一个key value设置到HashMap的流程就走完了。
1.2.1.3、第三阶段:发生hash冲突
我们先让感叹号put进去,然后再走到put 1的地方debug进去,进入putVal方法。
1.2.1.4、第四阶段:扩容操作
接下来我们再看一下扩容的操作。这里我们创建一个初始化容量是3的HashMap,实际数组长度其实是4,扩容的阈值则是3,那么当我们这里put元素到第四个的时候,就会执行扩容的操作。我们在put 4 的地方打一下断点。
通过putVal的一系列操作进入到resize方法内部
1.2.1.5、第五阶段:数据迁移
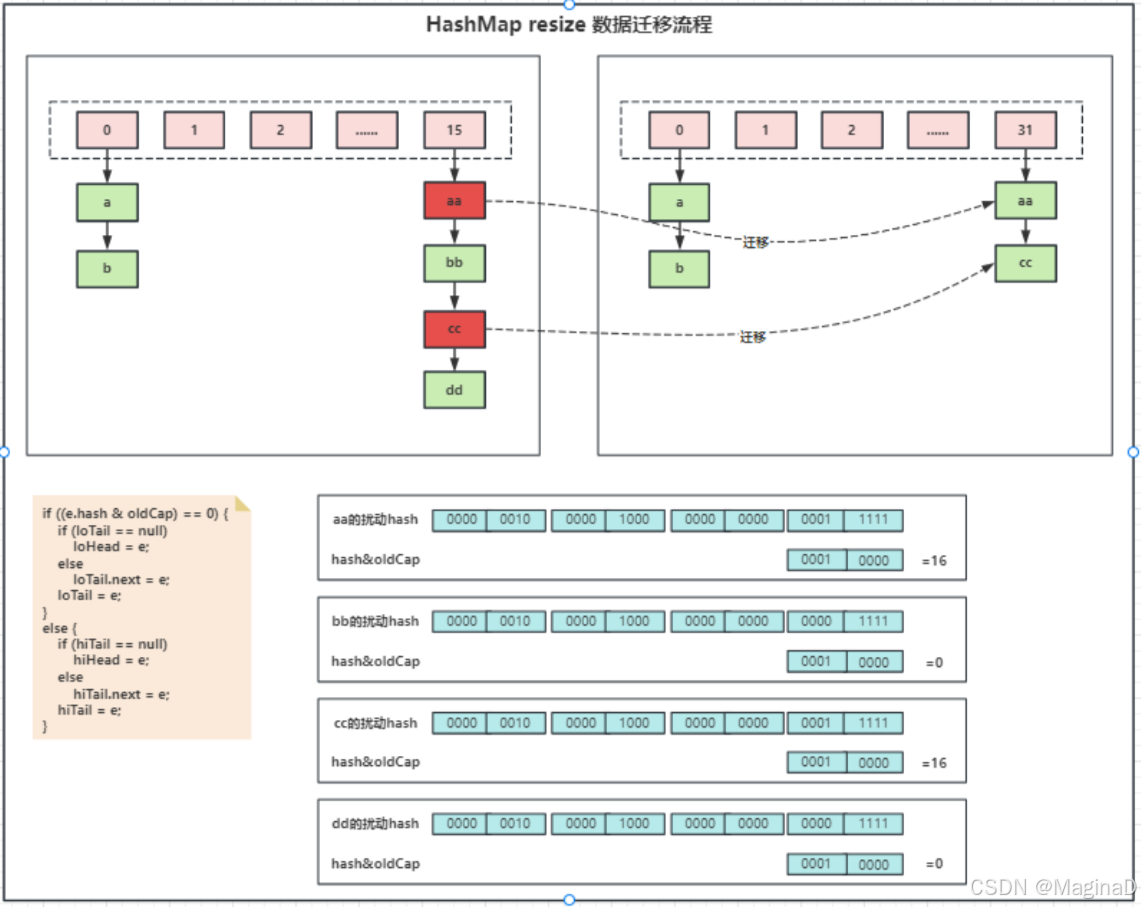
1. 这里假设咱们的原始数组的容量有16个,此时扩容是乘以2的操作,所以扩容后的数组容量是32个。
2. 我们看到下标为15的位置里,这里的链表有4个节点,分别为a,b,c,d这里,它的逻辑其实就是会尽量平衡的把一部分留在15这个原始的位置,然后把一部分迁移到31这个节点。
3. 这里为什么可以做到尽量平衡。我们可以来看一下这个代码逻辑。
4. 这个低位的头尾节点其实就是图里下标15的位置的bb,dd,就是要留到原始位置的链表的头尾节点。 高位的头尾节点,就是要搬家到下标31位置的链表头尾节点了。
5. 然后接下来,咱们就会对这个原始的链表进行一个遍历作了,用do while循环来做的。
6. 这里,我们可以看到a的扰动函数,假如它后面五位是五个一,然后,oldCap因为是16嘛,所以,它的二进制就是1加四个0,它这里如果进行与预算的话,诶,上下都是1, 就是1,否则是0,那么这里的结果就是10000,就是16 嘛,这个值大于0,所以我们会把a这个节点迁移到高位链 表里面。
7. 然后我们再看b这个节点,它的扰动函数后面五位是 0四个1,这样,大家看一下,第五位进行对比,0与1,那肯定 是0,然后后面的,16的二进制,后面全是0,所以后面毋庸置疑也都是0 ,最终结果就是0。
8. OK,这里大家有没有发现一个规律,因为像8,16,32,64的 这种2的幂,它肯定是只有第一位是1,后面全是0,所以,它进行与运算的时候,只有第一位能起决定性的作 用。 所以我们看到图里面,其实起作用的就只有扰动 hash的第五位的值。如果它是1,那么大于0,迁移到高位,如果是0,那么0与上1,就是0了,直接放到低位里面。
9. 我们看到c和d,也是一样的逻辑,只有第五位起作用。所以,这个do while循环就是不停的把原始链表分为两个链表,一个低位,一个高位。
10. 等这个循环分完之后,这里就来判断一下低位的和高位的 是不是不为null啊,不是null的话,那我就帮你把这两个链表放到对应的位置了。
最后我们再来看一下get操作,get操作就很简单了。
再调用getNode方法。
好,这就是HashMap的整体流程了。
假如HashMap在多线程的环境下,hashMap的put方法,resize方法等都是没有加锁的,会出现线程安全问题。
这个代码 ,我们创建了200个线程,然后五个线程会分别向这个hashmap里面添加200次key value,这里如果是没有并发问题的话,按道理我们输出map的结果应该是200乘以200,40000的一个结果。我们来运行看一下。这里的结果,可以看到结果在意料之中,它是小于40000的。

这个问题我们可以看到put的源码。
在这个获取table的地方,假如说我现在刚把这个table拿到,然后这个table被其他线程修改了,那么我现在拿到的这个table其实就是一个过期的table,我会去覆盖掉之前其他线程的操作,就会造成数据丢失。而且我们可以看到size这个变量,它没有用volatile进行修饰,所以说,在多个线程操作的时候,size这个值就会有线程之间不可见的问题,所以咱们获取size的时候,那个结果是会出现问题的。
最后,我们来简单看一下CHM的代码是怎么实现的。 其实很简单,我们把HashMap搞懂了之后再看CHM也是差不多的。只是有一点小小的差异。
其实大体上都是和HashMap类似的逻辑,只不过CHM为了并发安全,使用了CAS去设置节点,然后使用synchronized锁住node节点来进行添加,其实就是减小了锁的粒度。还有一些不同的地方我们再来简单看一下。
首先就是这个spread方法,这个方法的hash计算和hashmap的是有一点区别的。
它这里不仅仅做了高位与低位的异或运算,还做了一个与运算。和一个HASH_BITS。这个值是0x7fffffff,转换为二进制,第一个是0 ,后面跟31个1,做一下与运算的话,就会把第一位的值转为0, 第一位,其实是符号位,判断这个数是正数还是负数的,0是正数的意思,所以这里的作用就是把这个hash值强制转为一个正数。因为,hash值是负数,在CHM中有特殊的含义,就比如说我们之前看的那个协助扩容的逻辑,如果hash值是-1的话,代表了咱们的CHM正在做扩容。
sizeCtl这个值有多个含义。
1. -1 代表有线程正在创建 table;
2. -N 代表有 N-1 个线程正在复制 table;
3. 在 table 被初始化前,代表根据构造函数传入的值计算出的应被初始化的大小;
4. 在 table 被初始化后,则被设置为 table 大小 的 75%,代表 table 的容量(数组容量)。
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/57078.html