
多进程在使用中是非常常见的,如果对多进程比较陌生,那可以换个说法,叫多任务。
多个任务。比如我们使用电脑时,打开浏览器,是一个任务、打开视频,是一个任务、打开聊天工具,是一个任务。同时打开多个软件,就是多任务了。
一个CPU可以运行一个任务,也可以运行多个任务。例如现在的电脑一般都是4核或8核,就是有几个CPU的意思。如果我们此时同时打开4个软件,那操作系统可以让每个CPU去执行一个任务,这样任务之间是同时在进行的。
轮流让多个任务交替执行。比如有ABC三个任务,那此时只有一个CPU,那CPU就会让A任务运行1毫秒,马上切换到B任务运行1毫秒,再切换到C任务运行1毫秒。因为CPU切换任务的速度很快,所以我们看起来就好像3个任务同时在运行一样。
线程呢?线程可以理解为进程的小弟。那一个进程就可以有一个或多个线程,线程之间协同工作,共同维持进程的工作。
比如当我们打开视频软件时,就开启了一个任务,此时播放画面需要一个线程,播放声音需要一个线程,播放弹幕又需要一个线程。所以当我们在看视频时,只要有三个线程在维持着这个进程。
单个CPU维持多个任务是不是多进程呢?严格来说是不算的。只有多个CPU执行多个任务,才能叫多进程。
那当需要同时执行多个任务时怎么办?有三种方法:
- 启动多个进程,每个进程只启动一个线程来完成一种任务。多个进程就能同时执行多个任务。即多进程模式。
- 启动一个进程,这个进程启动多个线程。多个线程同时执行多个任务。即多线程模式。
- 创建多个进行,每个进程启动多个线程。多线程来执行多任务。即多进程+多线程模式。
第三种复杂度比较高,很少会使用。
Linux和Unix提供了fork()函数。因为windows没有fork功能,所以这里不做过多介绍。这里我们介绍可以跨平台使用的multiprocessing模块。
Porcess类来代表一个进程对象。Process函数有两个传参,Process(target=函数名,args=("参数",))。
os.getpid和os.getppid函数。os.getpid获取当前任务的ID值,os.getppid获取当前任务的父任务ID值。
见如下代码:
结果:
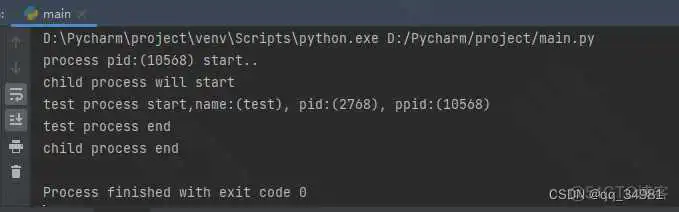
id为2768的子任务test,在子任务test里获取父ID为10568,与在程序最初运行时打印为ID相同,说明产生的子任务是通过父任务创建的。
start方法用来启动创建的子任务,join方法是父任务等待,等待到子任务结束后再继续往下执行(通常用于任务间的同步)。
同时启动多个子进程的时候,Pool函数就可以帮我们实现。
先看测试代码:
结果:
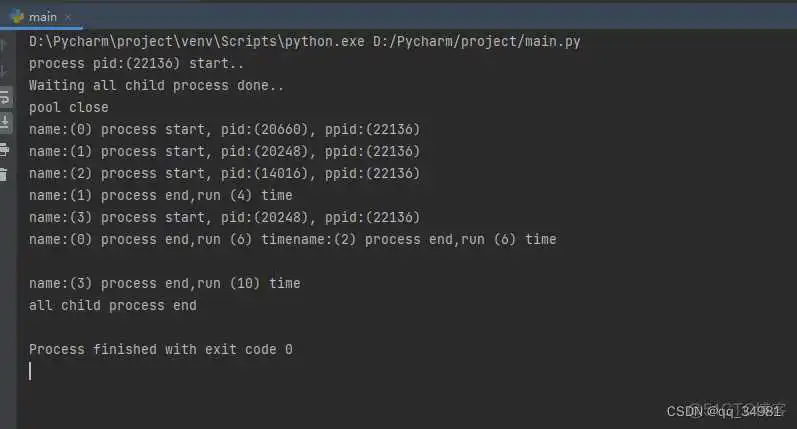
Pool了3个进程。这个方法就是说当前能同时运行的最大进程数量。然后调用 apply_async 创建4个进程。
apply_async
创建非阻塞异步任务
方法原型:def apply_async(self, func, args=(), kwds={}, callback=None,error_callback=None):
func为任务执行内容,args为参数。
p.close停止任务添加。调用该方法后,就不能继续添加新的任务了。
p.join 主任务挂起,等待子任务全部执行完成。
在子任务中,我们打印了任务的ID和其父ID。可以看到创建的4个子任务的父ID都是主任务ID。
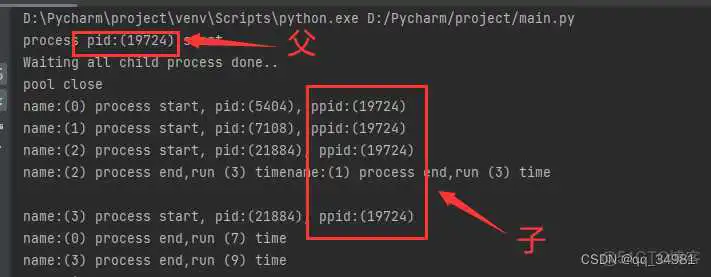
这里可以看出几个事情。
同时运行的任务只有3个,所以任务0、1、2顺序先被创建。但是因为达到了最大同时运行的数量,所以任务3并没有开始执行,而是等待。当任务2运行结束的时候,任务3马上开始执行。
任务2和任务3的ID是相同的,也就是说,任务2在执行完之后释放掉了ID,而该ID又被任务3继续使用。即ID在被释放后,可以被其他任务使用。
当所有任务都执行完之后,主任务才继续开始执行。
apply
阻塞同步任务
方法原型:def apply(self, func, args=(), kwds={}):
func为任务执行内容,args为参数。
参考代码:
结果:
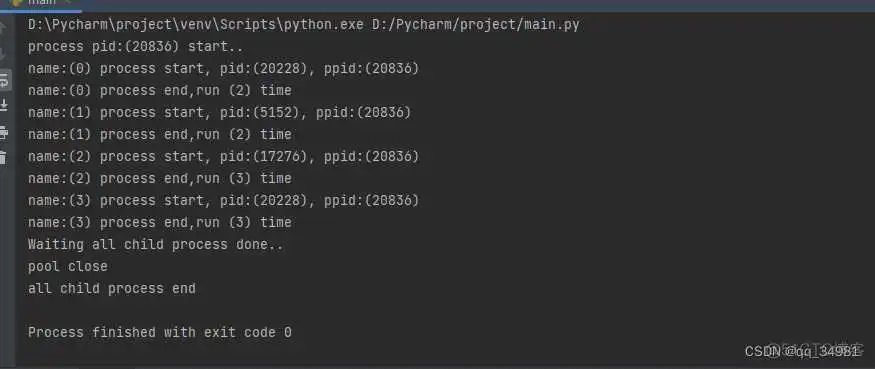
阻塞式的。如果当前任务不执行完成,则不继续向下执行。以顺序的方式,一个一个执行子任务。结束后再执行apply后面的主任务代码。
Queue、Pipes等方式来实现数据交互。
最安全的方式了。创建一个被多个线程共享的Queue对象,多个线程通过Queue的put()和get()来向队列中添加和删除元素。
注:Queue对象已经包含了必要的锁,所以可以通过Queue在多个线程间安全的共享数据。
见例程
结果:
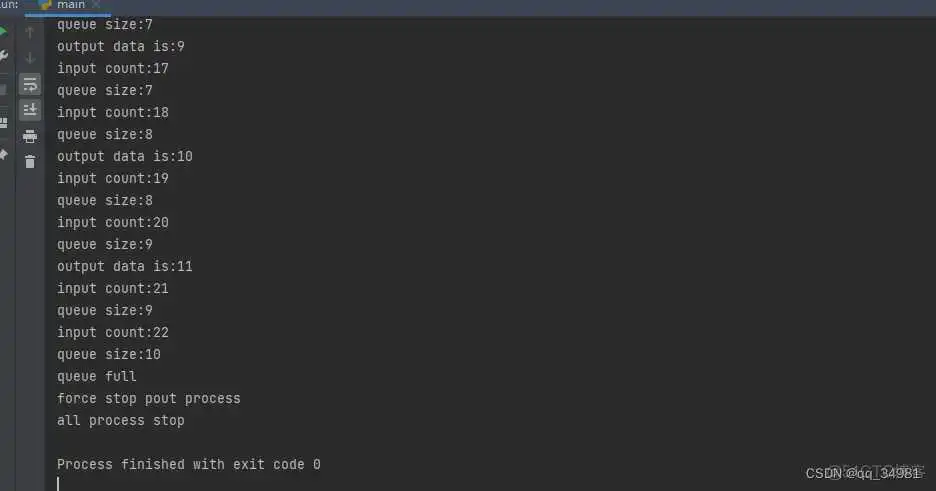
X表示当前队列最多可容纳的数据条数。比如在上面程序中,就创建了一个可容纳10条数据的队列。q=Queue(10)。而在process_queue_input中会判断队列长度。如果队列满,则打印消息直接退出。
在input中,每1秒向队列中输送一个数据。而ouput线程中,每2秒才会获取一个元素,所以20秒后队列就会满。
qin_join会阻塞程序,等待进程运行完成。因为output线程中并没有任何异常判断,且是一个死循环。所以这里调用.terminate将该线程强行终止。
两个端口(以列表的形式),一个端口作为输入端,一个端口作为输出端。 Pipe方法可以使用send()发送数据,使用recv()接收数据。如果管道中没有消息,则一直阻塞。如果管道关闭,则抛出EOFError异常
见代码
结果:
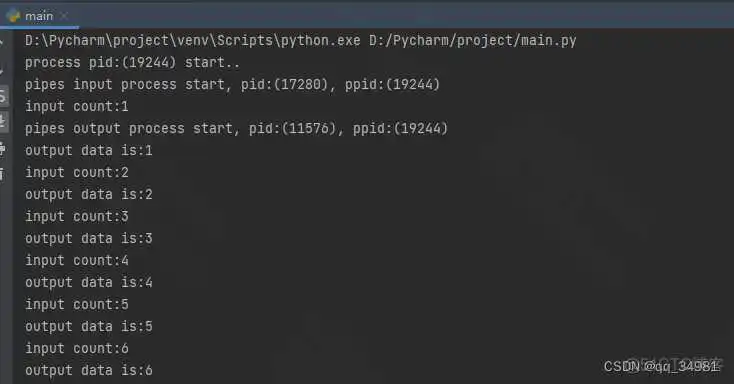
注明管道号。在申请管道的时候是申请了一个管道元组(tuple),这个管道元组上有很多可用的管道。我们在调用的时候要指定固定的管道。所以我们看到在传入参数时,传入的是元组对应的特定元素。

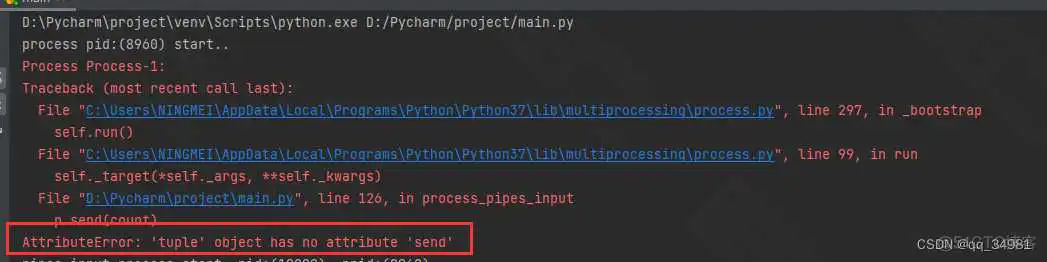
如果直接传入管道元组,如下:

发现是直接报错的。
见如下代码:
结果:
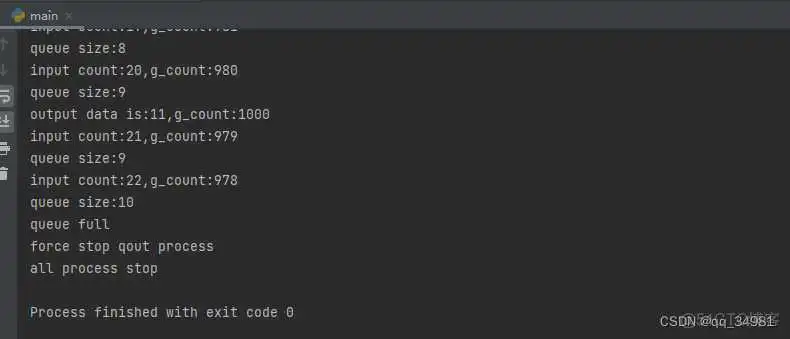
全局变量在进程中是不共享的。
到此这篇py文件闪退,怎么打开它(py文件闪退,根本打不开)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/63783.html