
1 算法简介
现代机器学习技术取得了长足的进步,但是机器在某些领域的表现仍然远远不如人类。其中最关键的原因之一,机器往往缺乏人类的常识和推理能力,这使得机器在面对一些复杂的任务时表现不佳,例如自然语言理解、文本生成等。
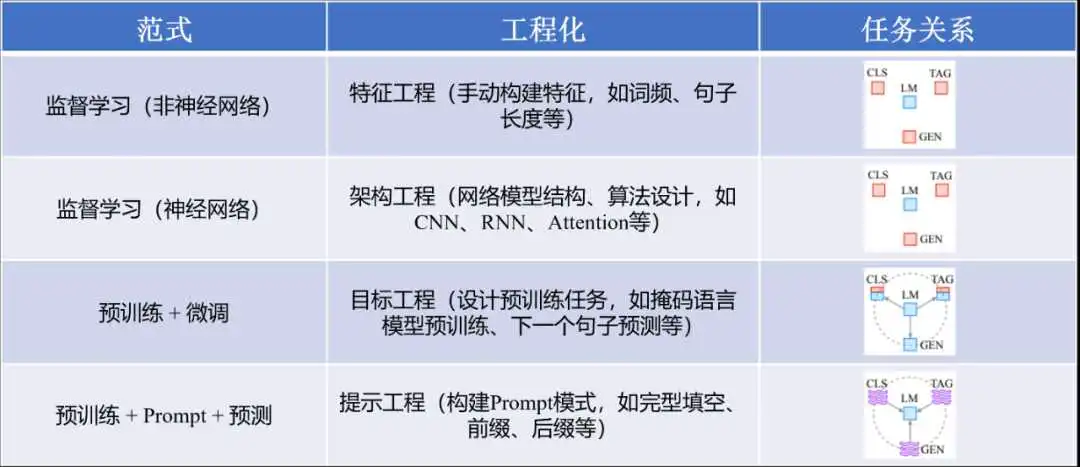
图1 典型NLP技术范式
2 算法原理
传统的深度学习需要一定规模的训练数据,但在具体的应用场景中,标注数据往往有限,限制了深度学习的应用与推广。为此,研究者提出小样本学习(Few-shot learning),它是一种在给定少量训练样本的情况下,进行深度学习模型训练和应用的方法。Prompt learning就是典型的小样本学习方法,它充分利用在预训练阶段获取的掩码语言模型(Masked Language Model,MLM),将下游任务建模为语言模型的掩码生成问题,也使得模型可以在Few-shot、Zero-shot等低资源场景下保持良好的表现。
Prompt learning本质上就是设计一个比较契合上游预训练任务的模板,通过模板的设计就是挖掘出上游预训练模型的潜力,让上游的预训练模型在尽量不需要标注数据的情况下比较好的完成下游的任务,关键包括3个步骤:
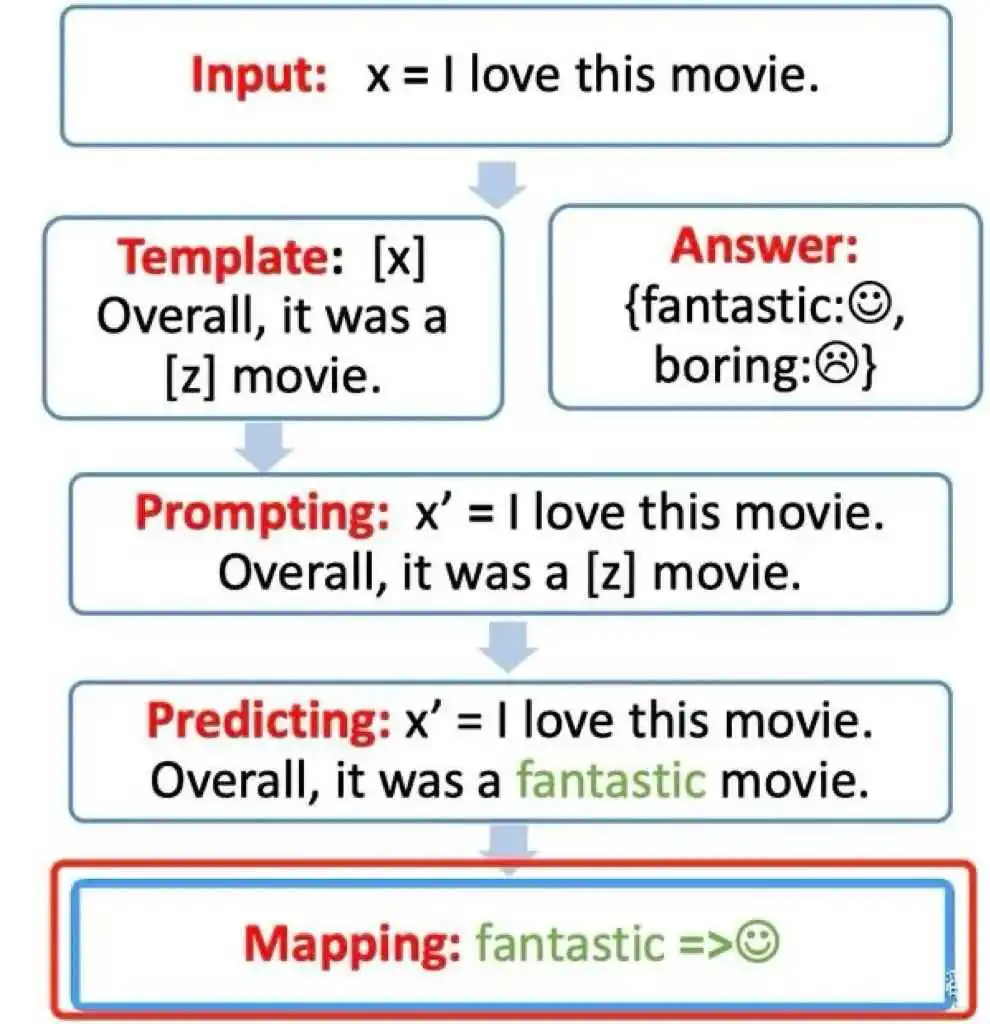
图2 Prompt learning的步骤图
3 算法应用
Prompt Learning的应用广泛,包括但不限于自然语言处理任务、计算机视觉、多模态、生物医学等领域。在医学领域,Prompt Learning的应用是一个新兴的研究方向,它可以利用预训练语言模型通过少量示例快速适应医学专业任务。例如在针对面向诊断的医疗对话系统无法支持精准医疗所需的信息粒度、难以同时满足医疗领域中多样化的槽值表示形式的缺陷,研究中提出了一种基于提示学习的多层次生成式医疗对话理解方法,即用多层次槽结构替代当前对话理解任务中单层的槽结构,以表示更细粒度的信息,之后采用一种基于对话风格提示的生成式方法,利用提示字符模拟医患对话,从多轮交互中获得多层次信息;提出在推理过程中使用一种受限的解码策略,使模型能够以统一的方式处理意图识别与分类型和抽取型的槽填充任务,避免复杂的建模;此外,针对医疗领域缺少标注数据的问题,提出了一种两阶段训练策略,以充分利用大规模的无标注医疗对话语料来提升性能。实验架构图见图3。最终实验结果表明,所提方法能够有效解析医疗对话中的各种复杂实体,相比已有的生成方法,其性能高出2.18%,而在小样本的场景下两阶段训练最高能提高模型5.23%的性能。
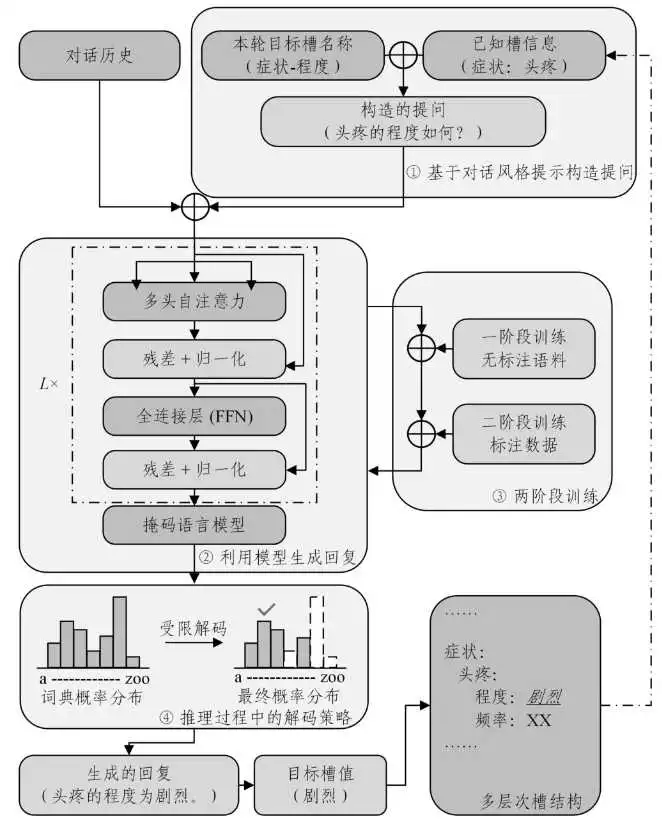
图3 架构图
4 小结
Prompt Learning的优势在于它不需要大量的标记数据,只需少量样本即可开始训练,这大大降低了训练成本。同时,通过使用不同的提示,大模型可以快速适应各种任务,无需重新训练或微调。然而,Prompt Learning也存在一些挑战和限制,如何构建有效的提示是一个关键问题,不同的任务和数据集可能需要不同的提示形式;此外,在某些场景下,我们仍然需要一定数量的标注数据来优化模型性能;由于Prompt Learning依赖于预训练模型,其性能也受到预训练模型质量的影响。
总的来说,Prompt Learning作为一种新型的训练方法,具有广阔的应用前景和巨大的发展潜力。随着技术的不断进步和研究的深入,Prompt Learning将在未来为人工智能领域带来更多的创新和突破。
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/82311.html