

来源:Deephub Imba本文约6000字,建议阅读10分钟 本文 我们将使用聚类和重新排序等技术来实现如何从语义搜索结果中过滤无关内容。

如果你曾使用过OpenAI的模型生成嵌入,你可能会好奇它与其他模型的效果对比到底如何呢?











第一步就是数据导入# 带有嵌入的合成LinkedIn档案dataset = load_dataset("ilsilfverskiold/linkedin_profiles_synthetic")profiles = dataset['train']# 带有嵌入的匿名职位描述dataset = load_dataset("ilsilfverskiold/linkedin_recruitment_questions_embedded")applications = dataset['train']
嵌入已经被添加到数据集中,你可以在'profiles'中看到这一点。# profiles数据集Dataset({features: [...,'embeddings_nv-embed-v1', 'embeddings_nv-embedqa-e5-v5', 'embeddings_bge-m3', 'embeddings_arctic-embed-l', 'embeddings_mistral-7b-v2', 'embeddings_gte-large-en-v1.5', 'embeddings_text-embedding-ada-002', 'embeddings_text-embedding-3-small', 'embeddings_voyage-3', 'embeddings_mxbai-embed-large-v1 '],num_rows: 6904})
application = applications[1] # 选择第二个应用 - 一个产品营销经理职位application_text = application['natural_language']print("application we're looking for: ",application_text)

# 获取特定嵌入模型的查询嵌入 - 这里我们选择mxbai-embed-large-v1query_embedding_vector = np.array(application['embeddings_mxbai-embed-large-v1'])embeddings_list = [np.array(emb) for emb in profiles['embeddings_mxbai-embed-large-v1 ']] # 注意额外的空格texts = profiles['text']
# 首先尝试计算余弦相似度(不使用聚类)def cosine_similarity(a, b):a = np.array(a)b = np.array(b)return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))similarities = []for idx, emb in enumerate(embeddings_list):sim = cosine_similarity(query_embedding_vector, emb)similarities.append(sim)
results = list(zip(range(1, len(texts) + 1), similarities, texts))sorted_results = sorted(results, key=lambda x: x[1], reverse=True)# 显示结果print("\nSimilarity Results (sorted from highest to lowest):")for idx, sim, text in sorted_results[:30]: # 可以调整显示数量percentage = (sim + 1) / 2 * 100text_preview = ' '.join(text.split()[:10])print(f"Text {idx} similarity: {percentage:.2f}% - Preview: {text_preview}...")
Similarity Results (sorted from highest to lowest):Text 3615 similarity: 89.59% - Preview: Product Marketing Manager | Building Go-to-Market Strategies for Growth Results-driven...Text 6299 similarity: 89.56% - Preview: Product Marketing Manager | Driving Growth & Customer Engagement Results-driven...Text 3232 similarity: 89.09% - Preview: Product Marketing Manager | Driving Product Growth through Data-Driven Strategies...Text 5959 similarity: 88.90% - Preview: Product Marketing Manager | Data-Driven Growth Expert Results-driven Product Marketing...Text 5635 similarity: 88.84% - Preview: Product Marketing Manager | Driving Growth through Data-Driven Marketing Strategies...Text 5835 similarity: 88.74% - Preview: Product Marketing Manager | Cloud-Based SaaS Results-driven Product Marketing Manager...Text 139 similarity: 88.66% - Preview: Product Marketing Manager | Scaling Growth through Data-Driven Strategies Experienced...Text 6688 similarity: 88.48% - Preview: Product Marketing Manager | Driving Business Growth through Data-Driven Insights...
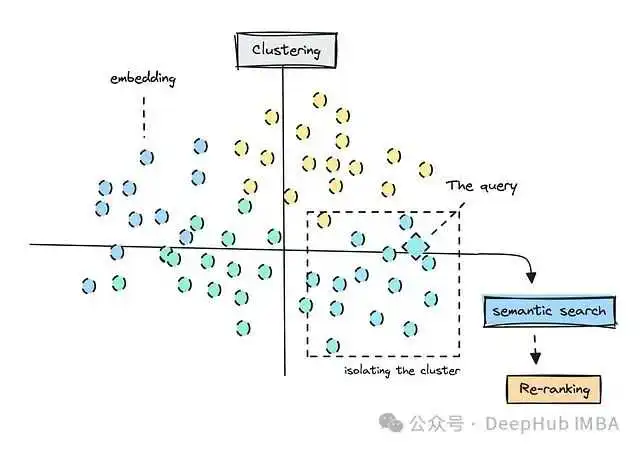
embeddings_array = np.array(embeddings_list)num_clusters = 10 # 你可以选择其他数量kmeans = KMeans(n_clusters=num_clusters, random_state=42)kmeans.fit(embeddings_array)cluster_labels = kmeans.labels_pca = PCA(n_components=2)reduced_embeddings = pca.fit_transform(embeddings_array)
# 现在看看查询如何适应聚类query_embedding_array = np.array(query_embedding_vector).reshape(1, -1)reduced_query_embedding = pca.transform(query_embedding_array)# 预测查询应该属于哪个聚类query_cluster_label = kmeans.predict(query_embedding_array)[0]print(f"The query belongs to cluster {query_cluster_label}")



# 现在我们只在正确的聚类中进行语义搜索cluster_indices = np.where(cluster_labels == query_cluster_label)[0]cluster_embeddings = embeddings_array[cluster_indices]cluster_texts = [texts[i] for i in cluster_indices]similarities_in_cluster = []for idx, emb in zip(cluster_indices, cluster_embeddings):sim = cosine_similarity(query_embedding_vector, emb)similarities_in_cluster.append((idx, sim))similarities_in_cluster.sort(key=lambda x: x[1], reverse=True)top_n = 40 # 可以调整此数字以显示更多匹配结果top_matches = similarities_in_cluster[:top_n]print(f"\nTop {top_n} similar texts in the same cluster as the query:")for idx, sim in top_matches:percentage = (sim + 1) / 2 * 100text_preview = ' '.join(texts[idx].split()[:10])print(f"Text {idx+1} similarity: {percentage:.2f}% - Preview: {text_preview}...")
Top 40 similar texts in the same cluster as the query:Text 3615 similarity: 89.59% - Preview: Product Marketing Manager | Building Go-to-Market Strategies for Growth Results-driven...Text 3232 similarity: 89.09% - Preview: Product Marketing Manager | Driving Product Growth through Data-Driven Strategies...Text 5959 similarity: 88.90% - Preview: Product Marketing Manager | Data-Driven Growth Expert Results-driven Product Marketing...Text 5635 similarity: 88.84% - Preview: Product Marketing Manager | Driving Growth through Data-Driven Marketing Strategies...Text 5835 similarity: 88.74% - Preview: Product Marketing Manager | Cloud-Based SaaS Results-driven Product Marketing Manager...Text 139 similarity: 88.66% - Preview: Product Marketing Manager | Scaling Growth through Data-Driven Strategies Experienced...Text 6688 similarity: 88.48% - Preview: Product Marketing Manager | Driving Business Growth through Data-Driven Insights...Text 6405 similarity: 88.27% - Preview: Product Marketing Manager | Scaling SaaS Products for Global Markets...Text 5183 similarity: 87.86% - Preview: Product Marketing Manager | B2B SaaS Experienced Product Marketing Manager...

本文的Colab笔记本可以在以下链接找到:
https://colab.research.google.com/gist/ilsilfverskiold/d3ffde6e0dded3ffc/visualize_different_embedding_models.ipynb
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/cjjbc/13894.html