
- 物流信息的需求分析
- 技术实现分析
- 基于MongoDB的功能实现
- 多级缓存的解决方案
- Redis缓存存在的问题分析并解决



基于上面的需求分析,我们该如何实现呢?首先要分析一下物流信息功能的特点:
- 数据量大
- 查询频率高(签收后查询频率低)
如果采用MySQL的存储,一般是这样存储的,首选设计表结构:
插入测试数据:


基于MongoDB的实现,可以充分利用MongoDB数据结构的特点,可以这样存储:

在TransportInfoService中定义了3个方法:
- 新增或更新数据
- 根据运单号查询物流信息
4.2.1、saveOrUpdate
4.2.2、查询
根据运单号查询物流信息。
4.2.3、测试
通过测试用例进行测试:

4.2.1、分析
通过前面的需求分析,可以发现新增物流信息的节点比较多,在取件、派件、物流转运环节都有记录物流信息,站在整体架构的方面的考虑,该如何在众多的业务点钟记录物流信息呢?
一般而言,会有两种方式,一种是微服务直接调用,另一种是通过消息的方式调用,也就是同步和异步的方式。选择哪种方式比较好呢?
在这里,我们选择通过消息的方式,主要原因有两个:
- 物流信息数据的更新的实时性并不高,例如,运单到达某个转运中心,晚几分种记录信息也是可以的。
- 更新数据时,并发量比较大,例如,一辆车装了几千或几万个包裹,到达某个转运中心后,司机入库时,需要一下记录几千或几万个运单的物流数据,在这一时刻并发量是比较大的,通过消息的方式,可以进行对流量削峰,从而保障系统的稳定性。
4.2.2、消息结构
消息的结构如下:
可以看出,在消息中,有具体信息、状态、机构id、运单号、时间,其中在info字段中,约定通过占位符表示机构,也就是,需要通过传入的查询机构名称替换到中,当然了,如果没有机构,无需替换。
4.2.3、功能实现
在TransportInfoMQListener中对消息进行处理。
4.2.4、测试



目前我们已经实现了物流信息的保存、更新操作,基本功能已经了ok了,但是有个问题我们还没解决,就是前面提到的并发大的问题,一般而言,解决查询并发大的问题,常见的手段是为查询接口增加缓存,从而可以减轻持久层的压力。
按照我们以往的经验,在查询接口中增加Redis缓存即可,将查询的结果数据存储到Redis中,执行查询时首先从Redis中命中,如果命中直接返回即可,没有命中查询MongoDB,将解决写入到Redis中。
这样就解决问题了吗?其实并不是,试想一下,如果Redis宕机了或者是Redis中的数据大范围的失效,这样大量的并发压力就会进入持久层,会对持久层有较大的影响,甚至可能直接崩溃。
如何解决该问题呢,可以通过多级缓存的解决方案来进行解决。

- 浏览器的本地缓存
- 使用Nginx作为反向代理的架构时,可以启用Nginx的本地缓存,对于代理数据进行缓存
- 如果Nginx的本地缓存未命中,可以在Nginx中编写Lua脚本从Redis中命中数据
- 如果Redis依然没有命中的话,请求就会进入到Tomcat,也就是执行我们写的程序,在程序中可以设置进程级的缓存,如果命中直接返回即可。
- 如果进程级的缓存依然没有命中的话,请求才会进入到持久层查询数据。
以上就是多级缓存的基本的设计思路,其核心思想就是让每一个请求节点尽可能的进行缓存操作。
:::danger
🚨说明,由于我们没有学习过Lua脚本,所以我们将Redis的查询逻辑放到程序中进行,也就是我们将要在程序中实现二级缓存,分别是:JVM进程缓存和Redis缓存。
:::
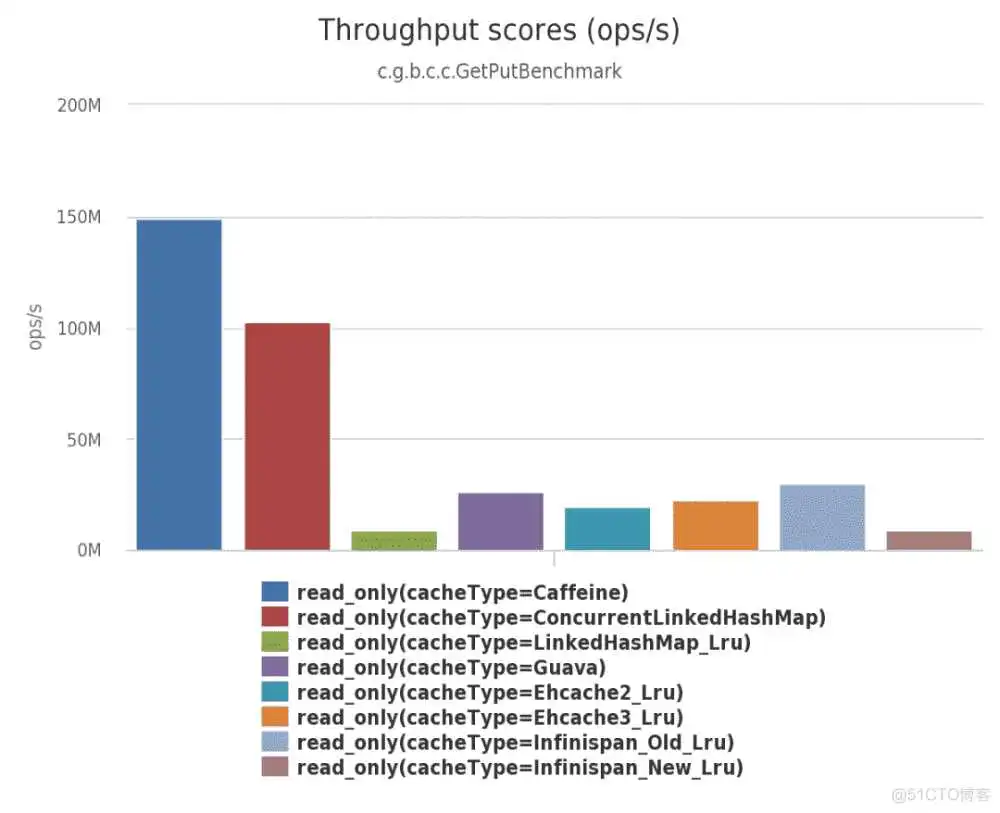
5.2.1、使用
导入依赖:
基本使用:
5.2.2、驱逐策略
- 基于容量:设置缓存的数量上限
- 基于时间:设置缓存的有效时间
- 基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
:::danger
🚨注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
:::
下面我们通过增加Caffeine实现一级缓存,主要是在 中实现缓存逻辑。
5.3.1、Caffeine配置
具体的配置项在Nacos中的配置中心的中:

5.3.2、实现缓存逻辑
在中进行数据的命中,如果命中直接返回,没有命中查询MongoDB。
5.3.3、测试



二级缓存通过Redis的存储实现,这里我们使用Spring Cache进行缓存数据的存储和读取。
5.4.1、Redis配置
Spring Cache默认是采用jdk的对象序列化方式,这种方式比较占用空间而且性能差,所以往往会将值以json的方式存储,此时就需要对RedisCacheManager进行自定义的配置。
5.4.2、缓存注解
接下来需要在Service中增加SpringCache的注解,确保数据可以保存、更新数据到Redis。
5.4.3、测试

这样的话就可以删除Caffeine中的数据,也就意味着下次查询时会从二级缓存中查询到数据,再存储到Caffeine中。
5.6.1、问题分析
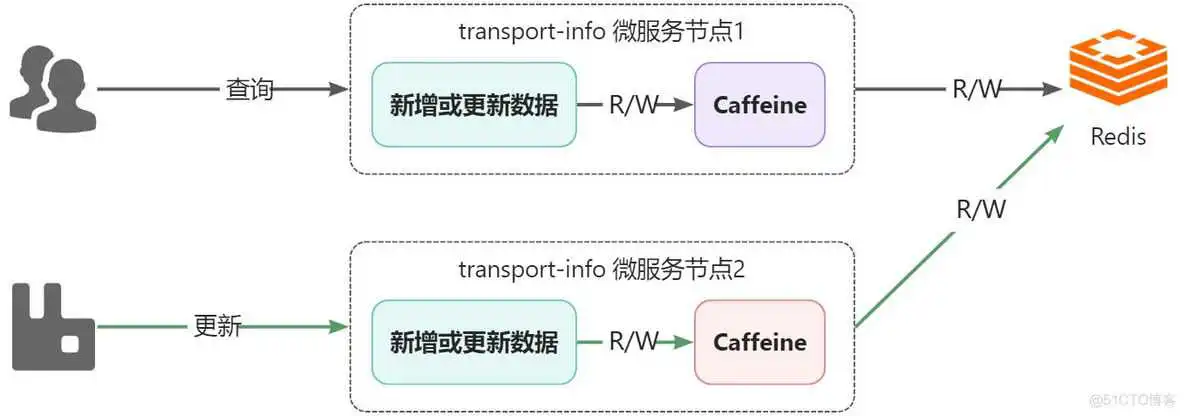
- 部署了2个transport-info微服务节点,每个微服务都有自己进程级的一级缓存,都共享同一个Redis作为二级缓存
- 假设,所有节点的一级和二级缓存都是空的,此时,用户通过节点1查询运单物流信息,在完成后,节点1的caffeine和Redis中都会有数据
- 接着,系统通过节点2更新了物流数据,此时节点2中的caffeine和Redis都是更新后的数据
- 用户还是进行查询动作,依然是通过节点1查询,此时查询到的将是旧的数据,也就是出现了一级缓存与二级缓存之间的数据不一致的问题
5.6.2、问题解决
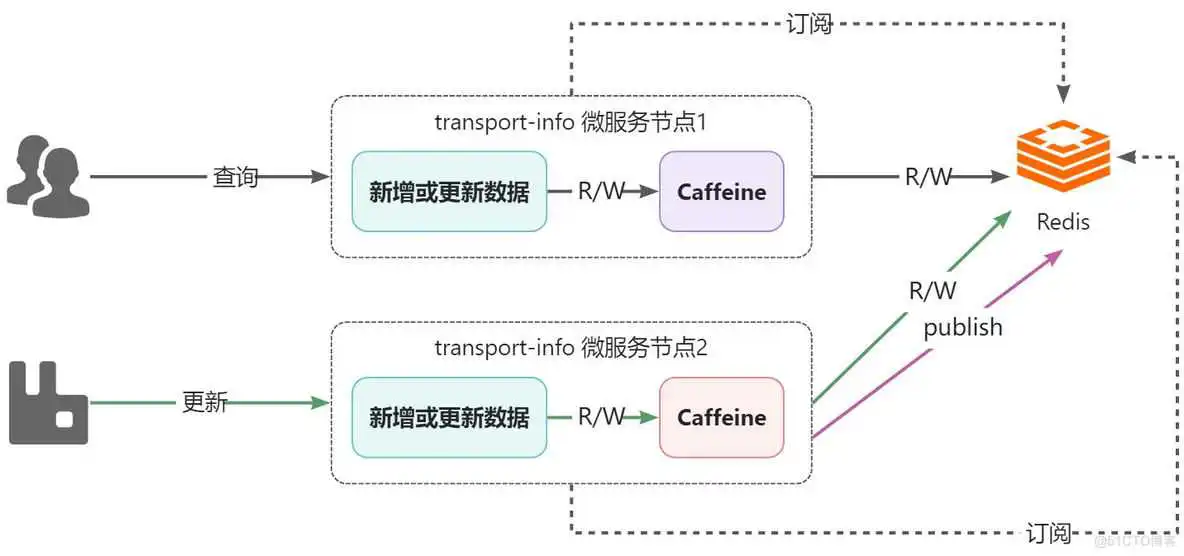

在增加订阅的配置:
编写用于监听消息,删除caffeine中的数据。
更新数据后发送消息:
5.6.3、测试


在使用Redis时,在高并发场景下会出现一些问题,常见的问题有:缓存击穿、缓存雪崩、缓存穿透,这三个问题也是面试时的高频问题。
6.1.1、说明
缓存击穿是指,某一热点数据存储到redis中,该数据处于高并发场景下,如果此时该key过期失效,这样就会有大量的并发请求进入到数据库,对数据库产生大的压力,甚至会压垮数据库。
6.1.2、解决方案
针对于缓存击穿这种情况,常见的解决方案有两种:
- 热数据不设置过期时间
- 使用互斥锁,可以使用redisson的分布式锁实现,就是从redis中查询不到数据时,不要立刻去查数据库,而是先获取锁,获取到锁后再去查询数据库,而其他未获取到锁的请求进行重试,这样就可以确保只有一个查询数据库并且更新缓存的请求。
6.1.3、实现

6.2.1、说明
缓存雪崩的情况往往是由两种情况产生:
- 情况1:由于大量 key 设置了相同的过期时间(数据在缓存和数据库都存在),一旦到达过期时间点,这些 key 集体失效,造成访问这些 key 的请求全部进入数据库。
- 情况2:Redis 实例宕机,大量请求进入数据库
6.2.2、解决方案
针对于雪崩问题,可以分情况进行解决:
- 情况1的解决方案
- 错开过期时间:在过期时间上加上随机值(比如 1~5 分钟)
- 服务降级:暂停非核心数据查询缓存,返回预定义信息(错误页面,空值等)
- 情况2的解决方案
- 事前预防:搭建高可用集群
- 构建多级缓存,实现成本稍高
- 熔断:通过监控一旦雪崩出现,暂停缓存访问待实例恢复,返回预定义信息(有损方案)
- 限流:通过监控一旦发现数据库访问量超过阈值,限制访问数据库的请求数(有损方案)
6.2.3、实现
我们将针对【情况1】的解决方案进行实现,主要是在默认的时间基础上随机增加1-10分钟有效期时间。
需要注意的是,使用SpringCache的注解是无法指定有效时间的,所以需要自定义对有效期时间进行随机设置。
自定义:
使用:
6.2.4、测试


6.3.1、说明
缓存穿透是指,如果一个 key 在缓存和数据库都不存在,那么访问这个 key 每次都会进入数据库
- 很可能被恶意请求利用
- 缓存雪崩与缓存击穿都是数据库中有,但缓存暂时缺失
- 缓存雪崩与缓存击穿都能自然恢复,但缓存穿透则不能
6.3.2、解决方案
针对缓存穿透,一般有两种解决方案,分别是:
- 如果数据库没有,也将此不存在的 key 关联 null 值放入缓存,缺点是这样的 key 没有任何业务作用,白占空间
- 采用BloomFilter(布隆过滤器)解决,基本思路就是将存在数据的哈希值存储到一个足够大的Bitmap(Bit为单位存储数据,可以大大节省存储空间)中,在查询redis时,先查询布隆过滤器,如果数据不存在直接返回即可,如果存在的话,再执行缓存中命中、数据库查询等操作。
6.3.3、布隆过滤器

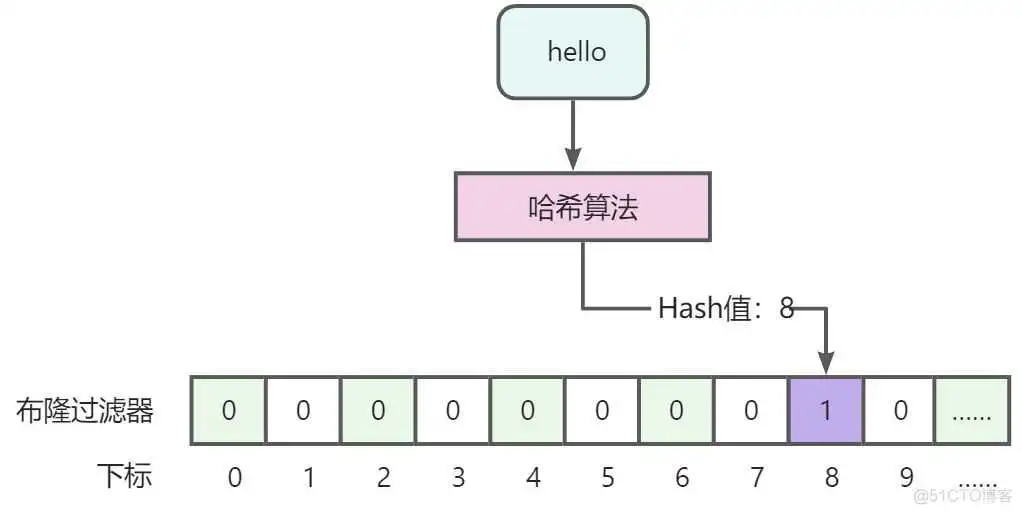
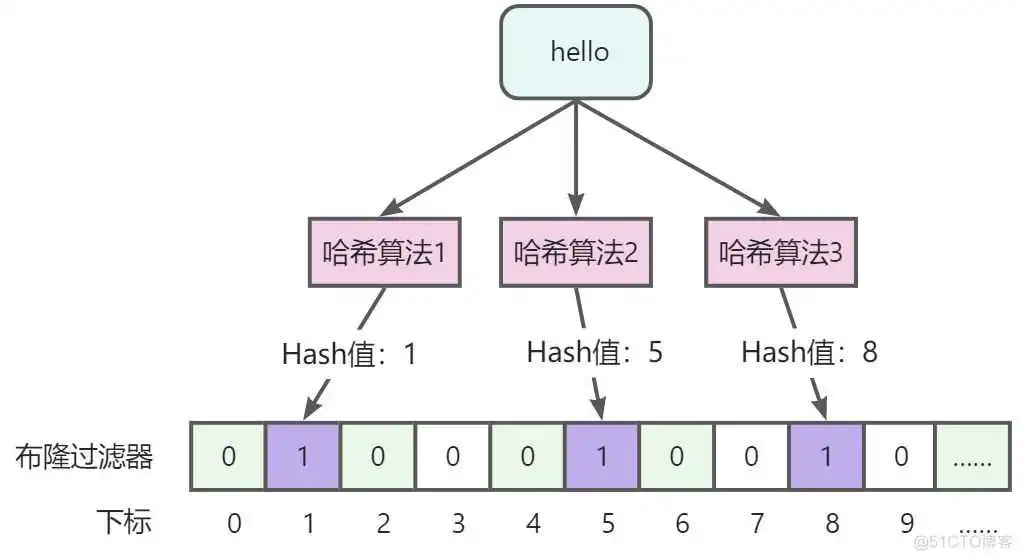
- 优点
- 存储的二进制数据,1或0,不存储真实数据,空间占用比较小且安全。
- 插入和查询速度非常快,因为是基于数组下标的,类似HashMap,其时间复杂度是O(K),其中k是指哈希算法个数。
- 缺点
- 存在误判,可以通过增加哈希算法个数降低误判率,不能完全避免误判。
- 删除困难,因为一个位置可能会代表多个值,不能做删除。
牢记结论:布隆过滤器能够判断一定不存在,而不能用来判断一定存在。
6.3.4、实现
关于布隆过滤器的使用,建议使用Google的Guava 或 Redission基于Redis实现,前者是在单体架构下比较适合,后者更适合在分布式场景下,便于多个服务节点之间共享。
Redission基于Redis,使用string类型数据,生成二进制数组进行存储,最大可用长度为:。
引入Redission依赖:
导入Redission的配置:
自定义布隆过滤器配置:
定义接口:
编写实现类:
改造TransportInfoController的查询逻辑,如果布隆过滤器中不存在直接返回即可,无需进行缓存命中。
改造方法,将新增的运单数据写入到布隆过滤器中:

难度系数:★★★★☆
描述:在work微服务中完成发送【物流信息】的消息的逻辑,这样的话,work微服务就和transport-info微服务联系起来了。
提示,一共有4处代码需要完善:
- com.sl.ms.work.mq.CourierMQListener#listenCourierPickupMsg()
- com.sl.ms.work.service.impl.PickupDispatchTaskServiceImpl#saveTaskPickupDispatch()
- 此处实现难度较大,会涉及到基础服务系统消息模块,需要阅读相应的代码进行理解。
- com.sl.ms.work.service.impl.TransportOrderServiceImpl#updateStatus()
- com.sl.ms.work.service.impl.TransportOrderServiceImpl#updateByTaskId()
:::danger
另外,包裹的签收与拒收的消息已经在【快递员微服务】中实现,学生可自行阅读源码: - com.sl.ms.web.courier.service.impl.TaskServiceImpl#sign()
- com.sl.ms.web.courier.service.impl.TaskServiceImpl#reject()
:::
- 你们项目中的物流信息那块存储是怎么做的?为什么要选择MongoDB?
- 针对于查询并发高的问题你们是怎么解决的?有用多级缓存吗?具体是怎么用的?
- 多级缓存间的数据不一致是如何解决的?
- 来,说说在使用Redis场景中的缓存击穿、缓存雪崩、缓存穿透都是啥意思?对应的解决方案是啥?实际你解决过哪个问题?
- 说说布隆过滤器的优缺点是什么?什么样的场景适合使用布隆过滤器?
:::
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/cjjbc/28891.html