
主要详细介绍Pod资源的各种配置(即yaml文件)和原理。
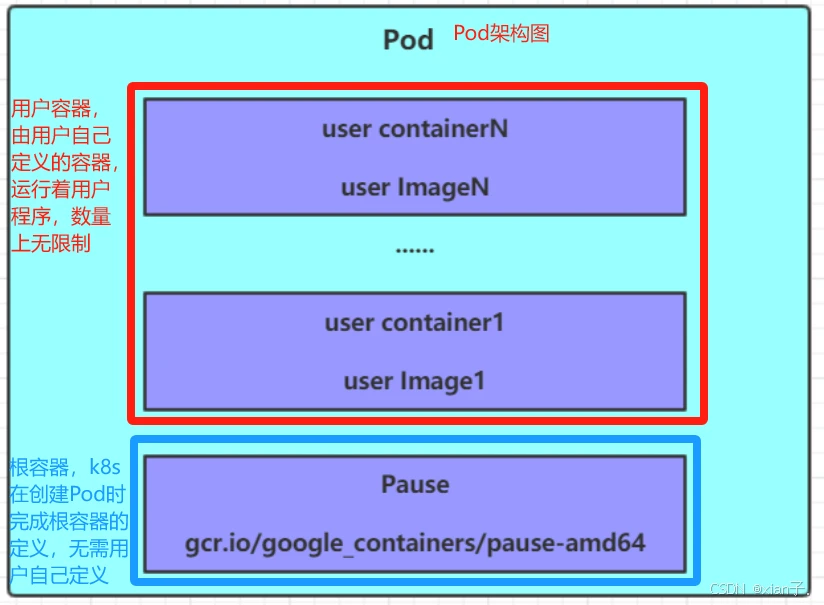
Pause容器,这是每个Pod都会有的一个根容器,它的作用有两个:
- 可以以它为依据,评估整个Pod的健康状态(Pod的寿命与Pause相同,而与用户容器无关);
- 可以在根容器上设置IP地址,其它容器都此IP(Pod IP),以实现Pod内部的网络通信(Pod的之间的通信采用虚拟二层网络技术来实现,当前环境用的是Flannel)。
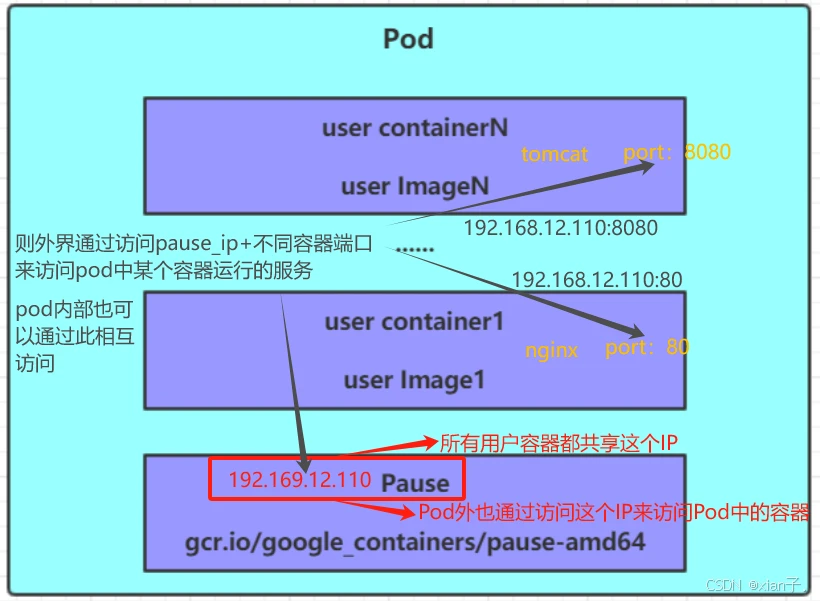
summary:知道pod里有1根容器(Pause)+n个用户容器,可通过Pause容器判断健康状态、可以做IP共享。
Pod资源清单(yaml配置文件的编写,以下为常用的参数):
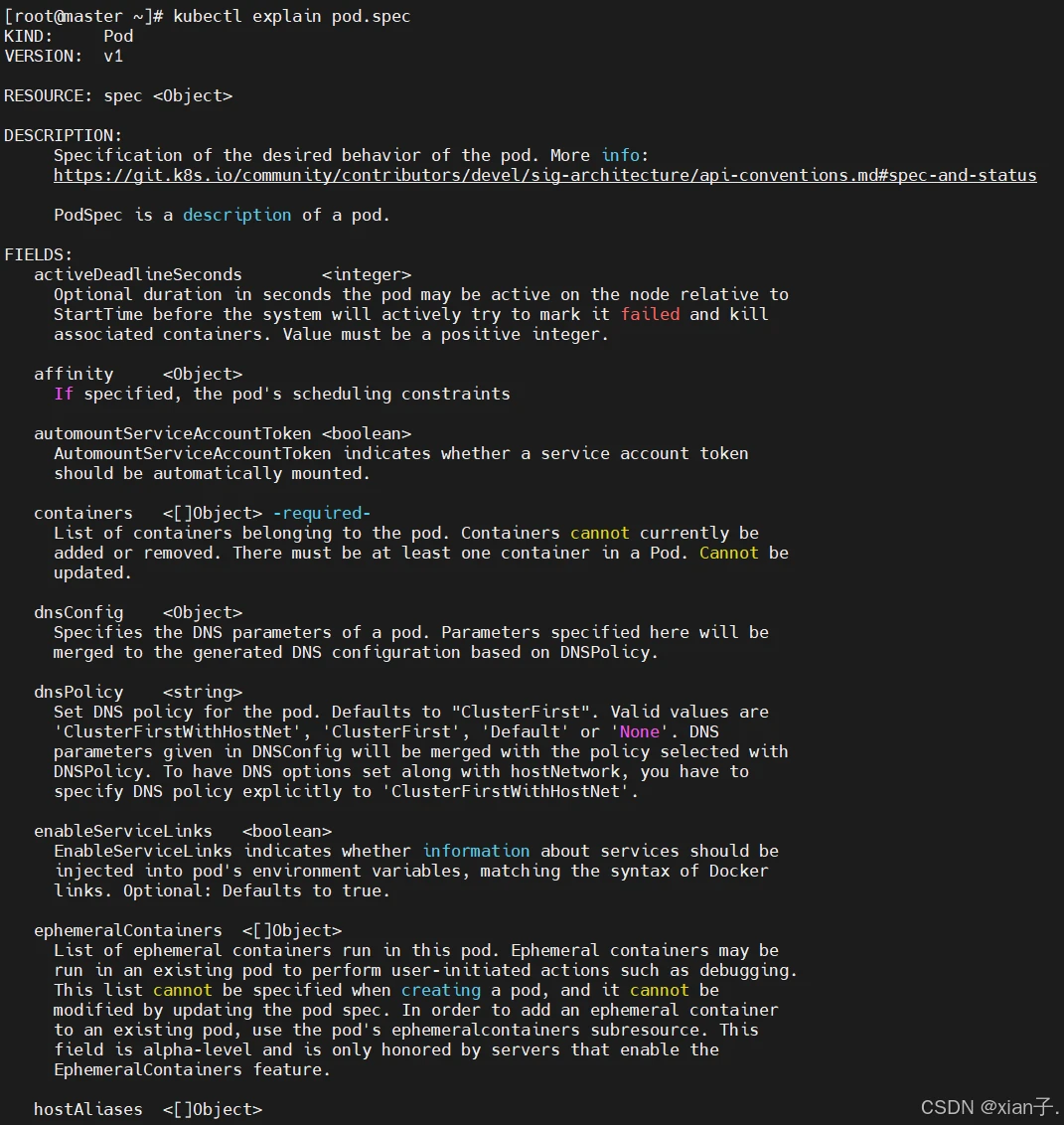
可以按照层级结构来学习pod.yaml的编写,如第一层:apiVersion / kind / metadata / spec …;第一层之下又有第二层、第三层…。还可以通过如下命令查看每种资源的可配置项:
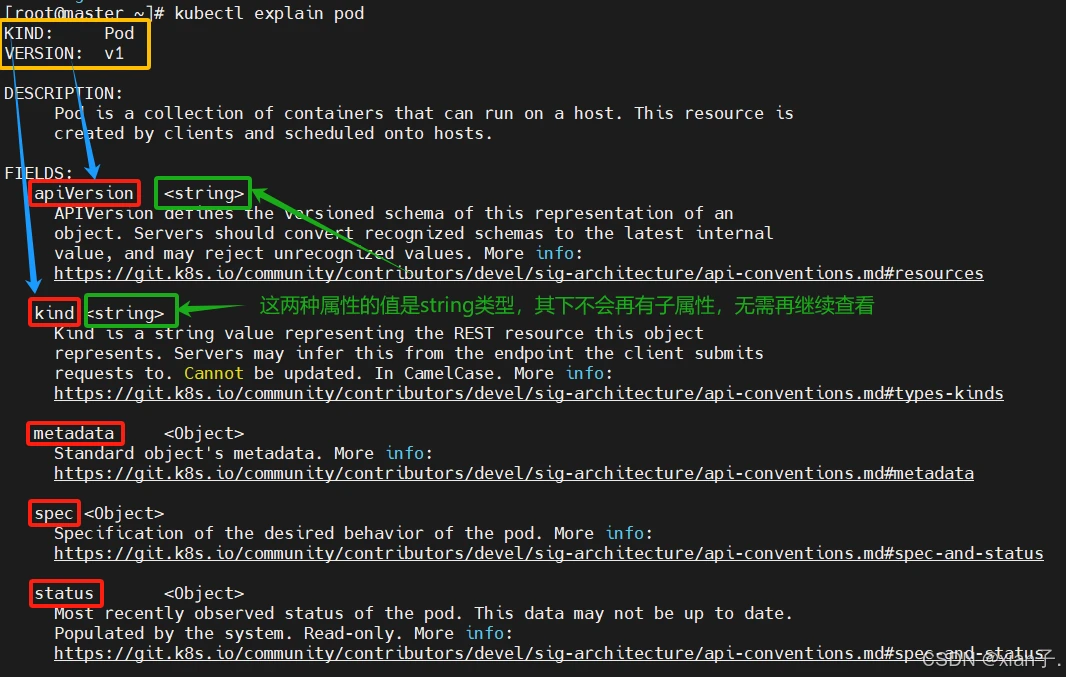
- kubernetes中基本所有资源的一级属性都是一样的,主要包含5部分:
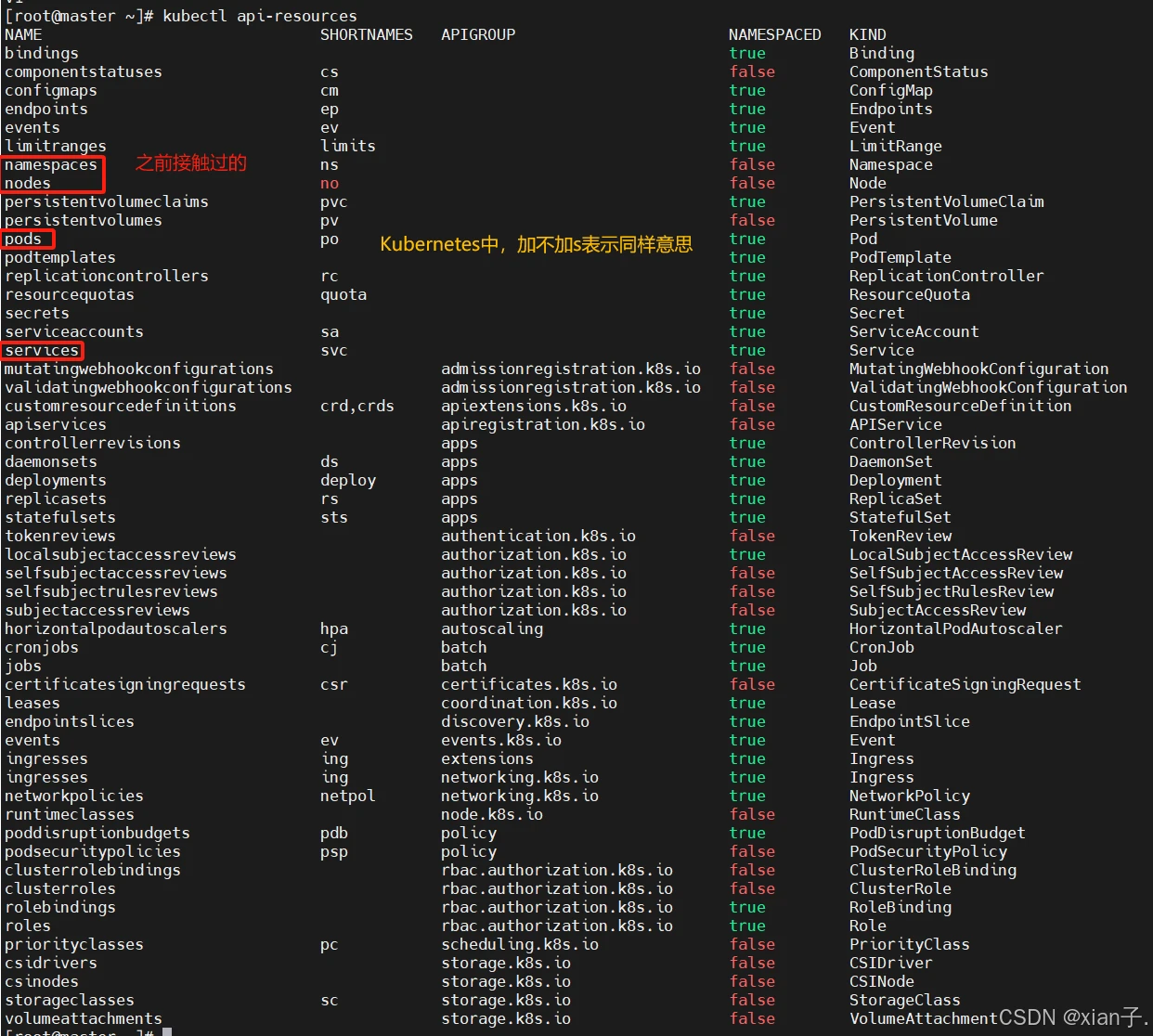
- : 版本,由kubernetes内部定义,版本号必须可以用 kubectl api-versions 查询到;
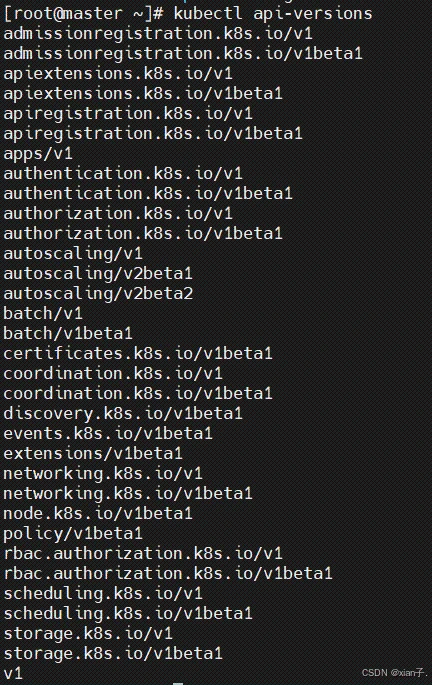
- :类型,由kubernetes内部定义,版本号必须可以用 kubectl api-resources 查询到;
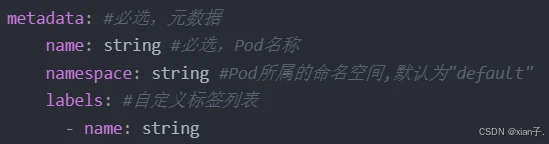
- : 元数据,主要是资源标识和说明,常用的有name、namespace、labels等;常用的如下:
- : 描述,这是配置中最重要的一部分,里面是对各种资源配置的详细描述;
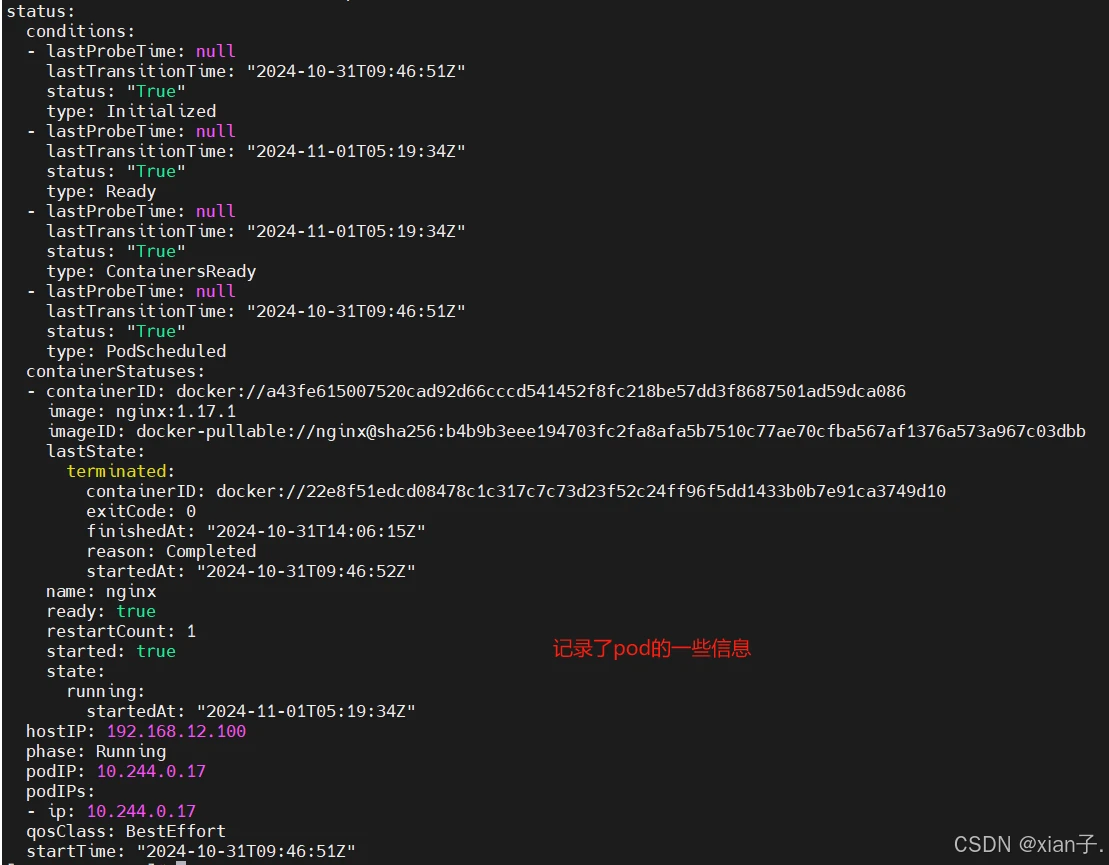
- : 状态信息,里面的内容不需要定义,由kubernetes自动生成,可以通过此字段查看pod(等资源)的状态。例如使用如下命令查看一个pod的状态:
- : 版本,由kubernetes内部定义,版本号必须可以用 kubectl api-versions 查询到;
查看某种资源属性的子属性:
- 在上面的一级属性中,spec是重点,其子属性为:
- :指定调度节点,根据nodeName的值将pod调度到指定的Node节点上;
- :根据NodeSelector中定义的信息选择将该Pod调度到包含这些label的Node上;
- :是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络。如果使用宿主机网络,则需要保证端口不要重复,因此一般不使用宿主机IP;

- :存储卷,用于定义Pod上面挂在的存储信息;
- : 重启策略,表示Pod在遇到故障的时候的处理策略(重启?删除?不管?)。
这一节主要来研究 pod.spec.containers 属性,这也是pod配置中最为关键的一项配置。
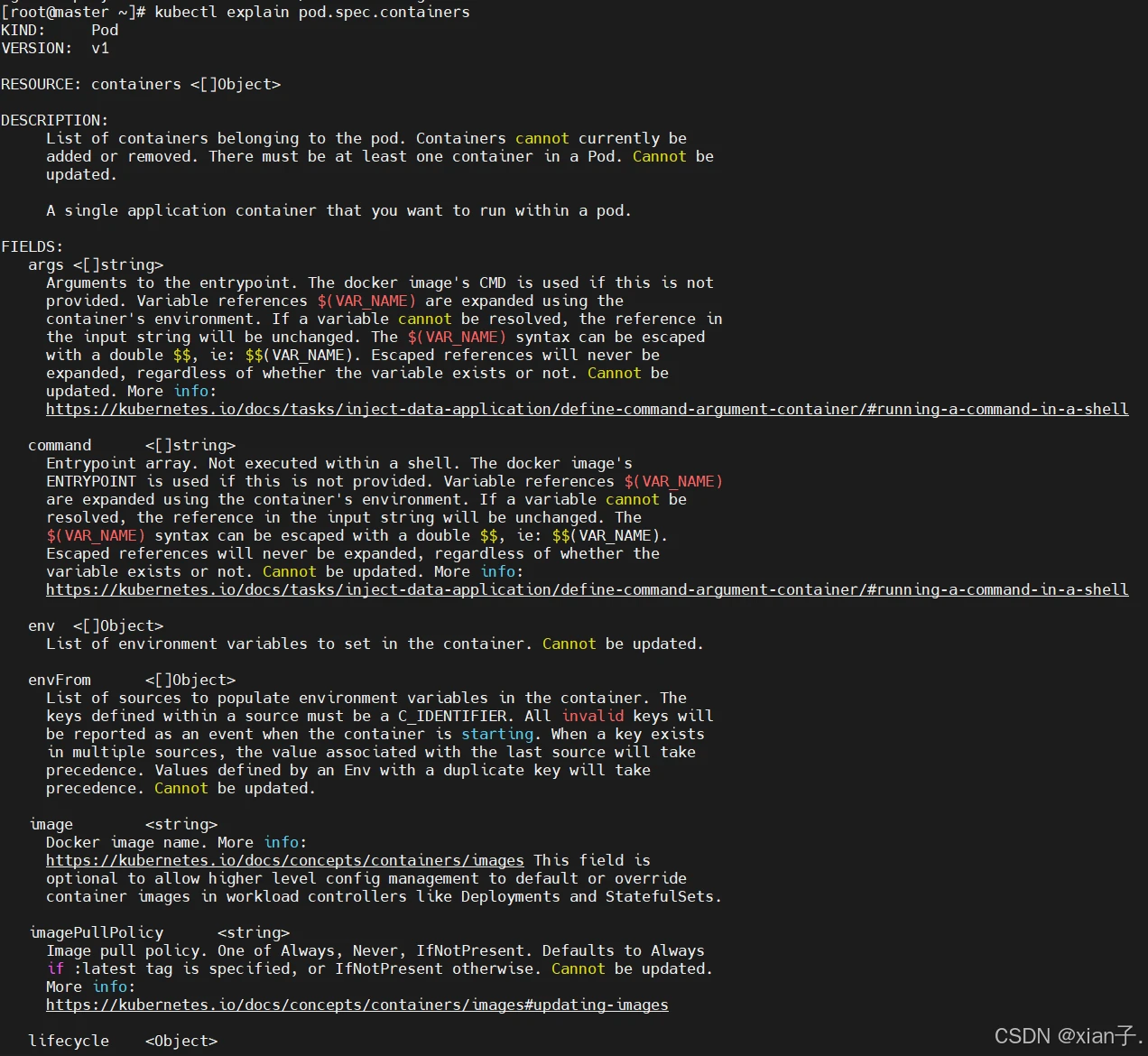
常用参数:
上面定义了一个比较简单Pod的配置,里面有两个容器:
然后运行如下命令:
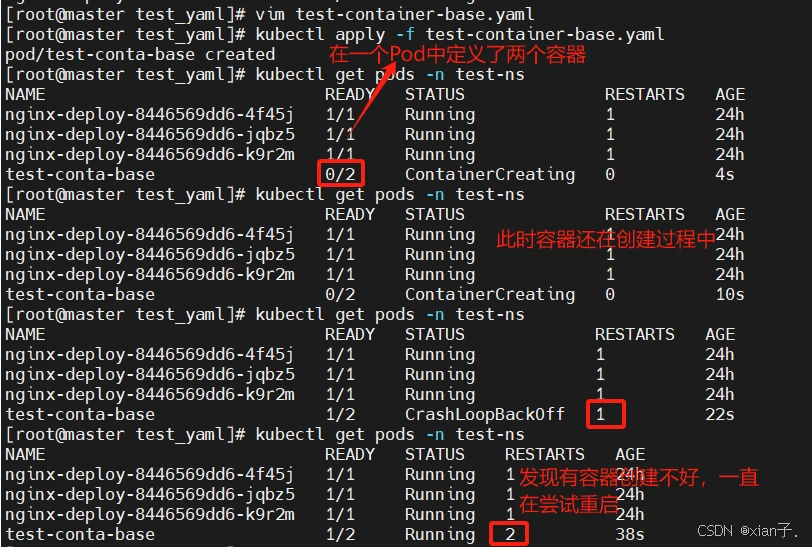
查看一下pod中的详情信息:
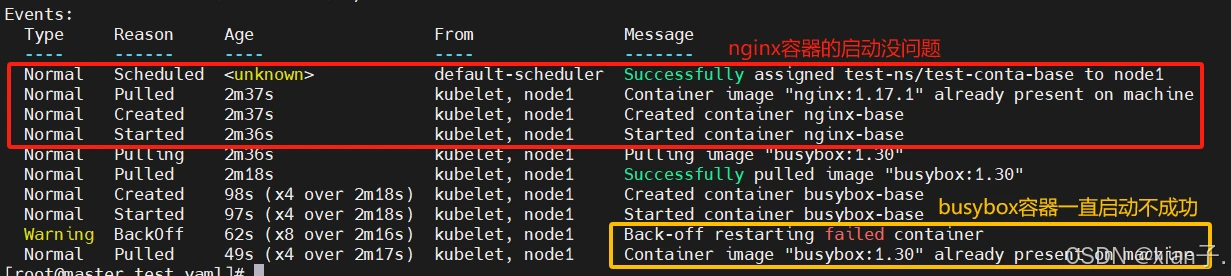
因此只有一个容器成功启动,另一个有问题(后续讲解问题——启动命令部分)。
imagePullPolicy用于设置镜像拉取策略,kubernetes支持配置三种拉取策略:

imagePullPolicy的默认值取决于镜像的tag,如果镜像tag为具体版本号,默认策略是:IfNotPresent;如果镜像tag为:latest(最新版本) ,默认策略是always。在实际使用中一般不会使用镜像的最新版本,为了稳定会为其指定版本号,因此常用的imagePullPolicy默认值就是IfNotPresent。
创建如下yaml文件:
查看一下本地已经拉取的镜像:
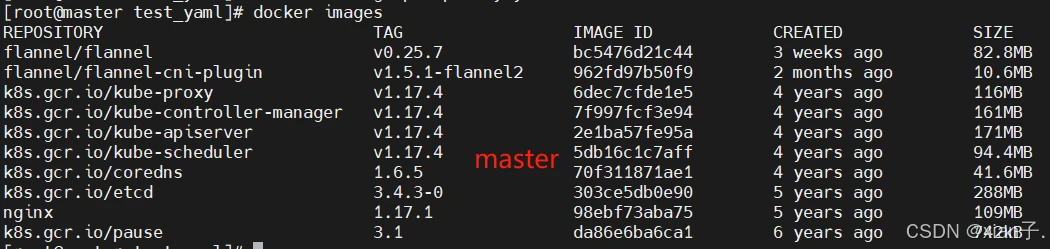
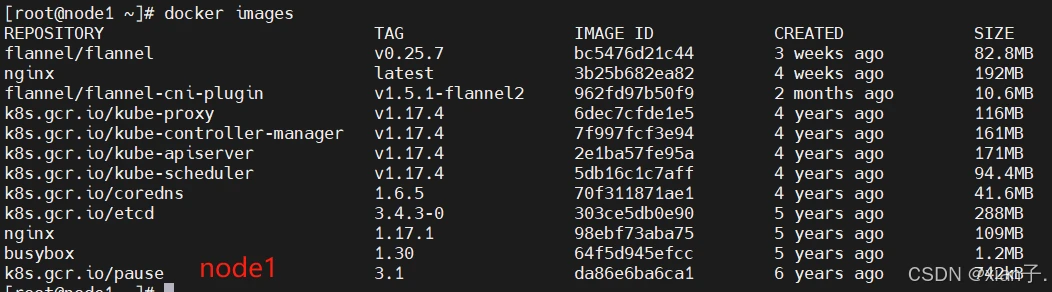
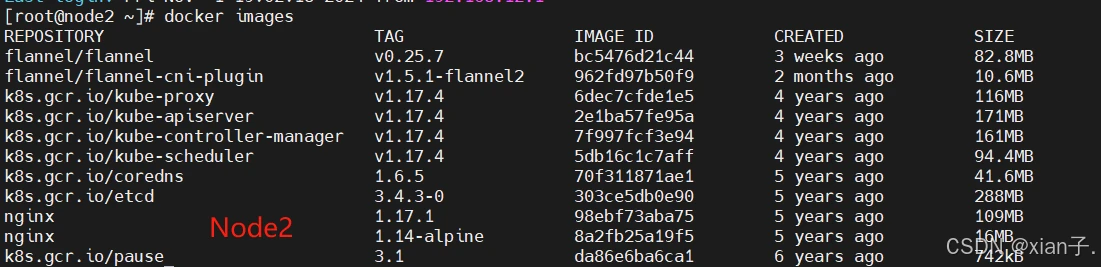
可以看到,三个节点上均没有上述yaml文件指定的nginx:1.17.2镜像,同时镜像拉去策略为Nerver(只使用本地镜像,从不去远程仓库拉取),那这样的话运行结果是什么?
运行如下命令创建Pod:
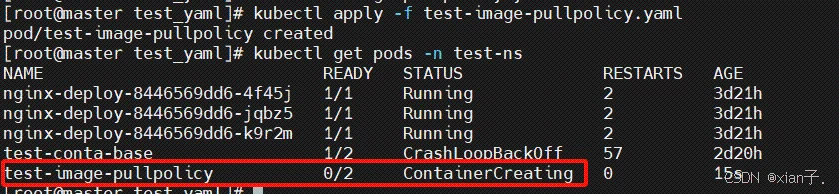
发现pod没有启动成功,查看出了什么错误:

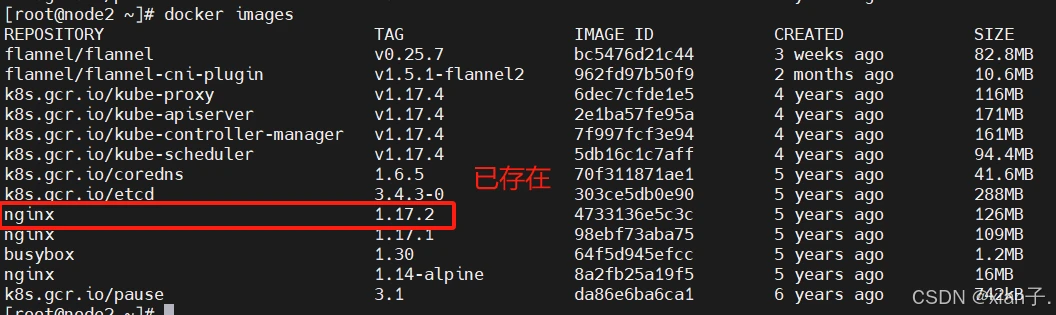
可以看到镜像不存在。初始将这个pod调度到了node2上,查看node2上的docker images:没有nginx:1.17.2
若想使其运行成功,则只需修改镜像拉去策略为IfNotPresent:
发现修改文件之后不能直接使用kubectl apply -f命令,因为仅当框框中的spec的值发生改变时才会更新,此处修改imagePullPolicy相当于没有改变。因此需要先删除pod,再重新apply。
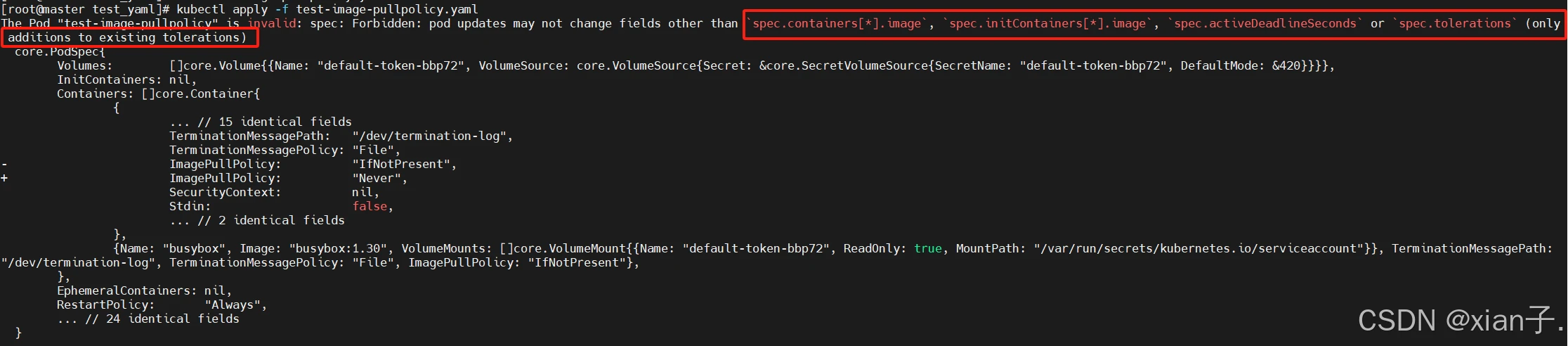
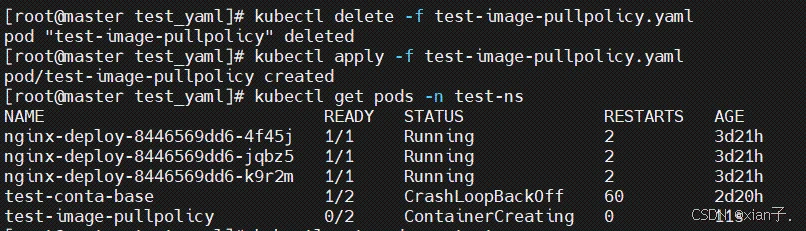
虽然还没有运行成功(先不管,此处只关注镜像的拉取),查看一下pod中的状况:
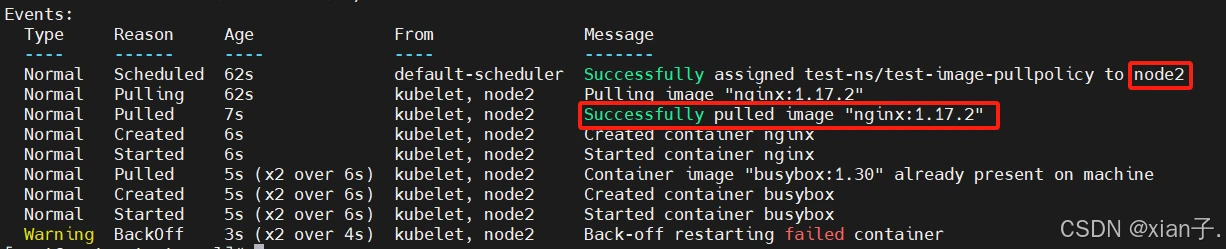
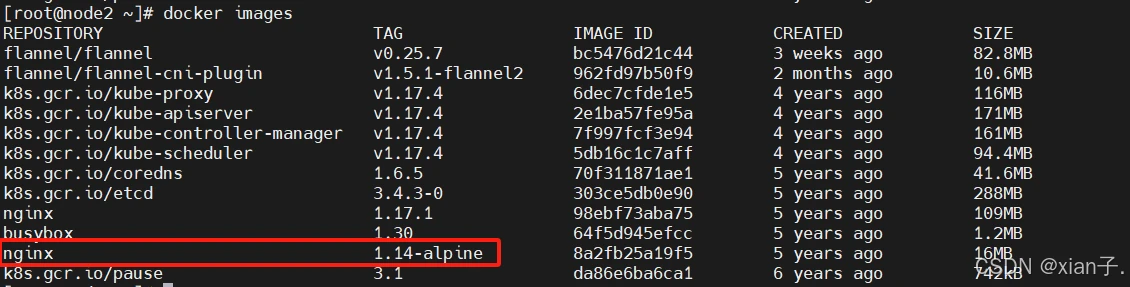
此时可以看到,这个pod被调度到了node2上,且nginx:1.17.2已经被成功拉取,查看一下node2节点上的docker镜像:
在前面的案例中,一直有一个问题没有解决,就是的busybox容器一直没有成功运行(1/2:只运行了nginx容器,busybox容器没有成功运行)

那么到底是什么原因导致这个容器的故障呢?原来busybox并不是一个程序,而是类似于一个工具类的集合,即busybox里面并没有一个进程在运行,而都是一些小的命令,kubernetes集群启动管理后,它会自动关闭(因为容器中没有一个进程在占据着他,因此一启动就结束了)。解决方法就是让其一直在运行(例如在busybox中运行一个死循环),这就用到了command配置。
创建test-pod-command.yaml文件,内容如下:
command:用于在pod中的容器初始化完毕之后运行一个命令。
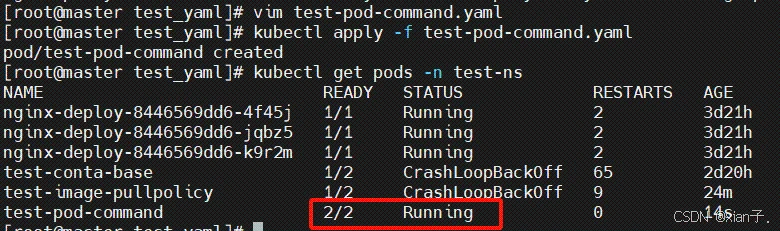
显示nginx与busybox容器都运行成功了。查看/tmp/hello.txt是否有内容,即上述command指令是否正常执行:首先要进入容器:
- 【说明】:
通过上面发现command已经可以完成启动命令和传递参数的功能,为什么这里还要提供一个args选项,用于传递参数呢?这其实跟docker有点关系,kubernetes中的command、args两项其实是实现覆盖Dockerfile中ENTRYPOINT的功能:
- 如果command和args均没有写,那么用Dockerfile的配置;
- 如果command写了,但args没有写,那么Dockerfile默认的配置会被忽略,执行输入的command;
- 如果command没写,但args写了,那么Dockerfile中配置的ENTRYPOINT的命令会被执行,使用当前args的参数(相当于使用Dockerfile命令,但为其配置新的参数);
- 如果command和args都写了,那么Dockerfile的配置被忽略,执行command并追加上args参数。
env参数:环境变量,用于在pod中的容器设置环境变量。数组类型,一个环境变量就是一个键值对。

创建test-pod-env.yaml文件,内容如下:
首先创建pod:
然后进入容器,查看环境变量:

这种方式不是很推荐,推荐将这些配置单独存储在配置文件中(在后面介绍)。
端口的设置对应pod.spec.containers.ports=容器需要暴露的端口号列表,查看ports的子选项:
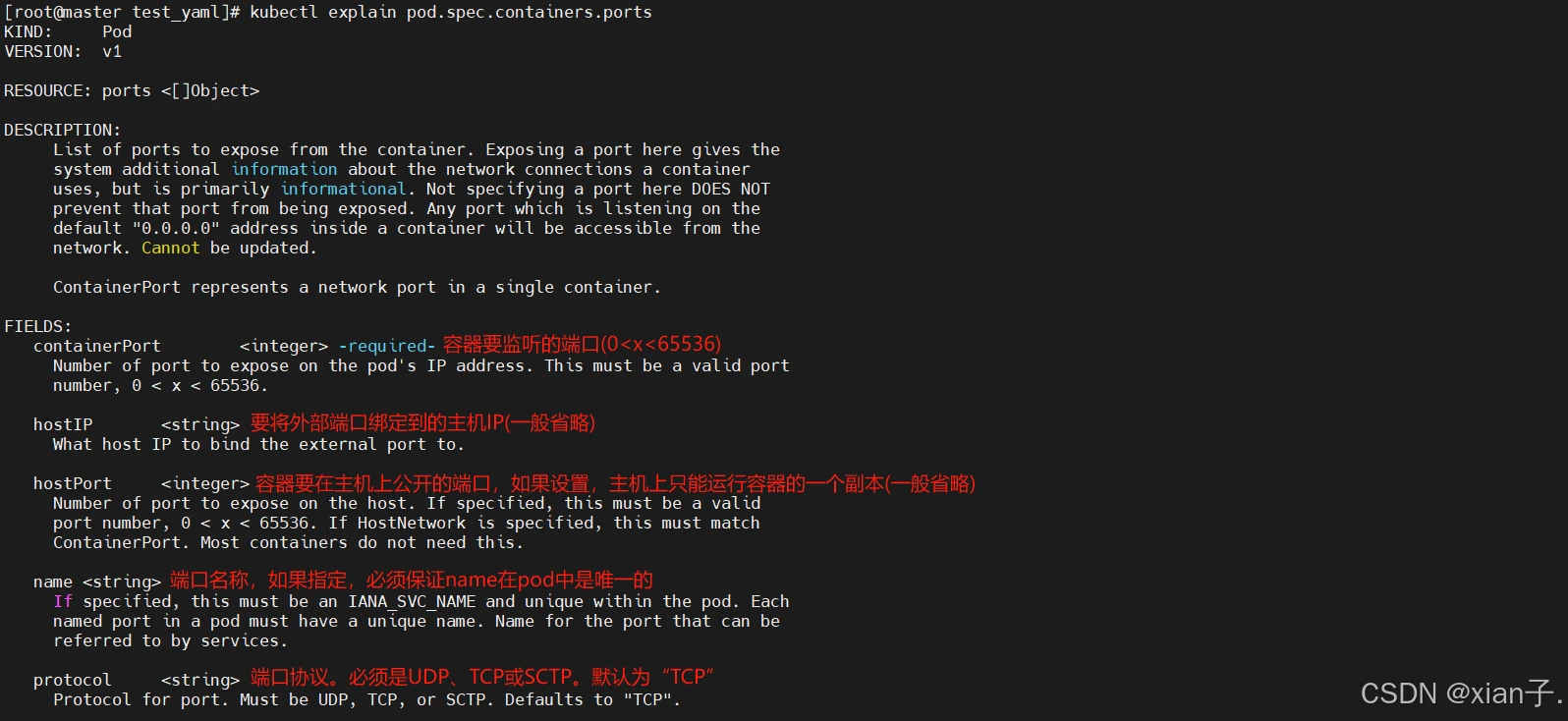
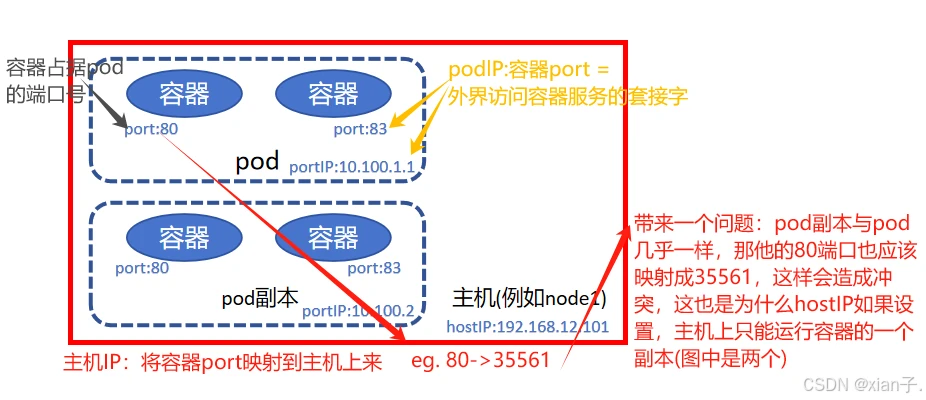
hostIP、hostPort解释:
编写一个测试案例test-pod-ports.yaml:

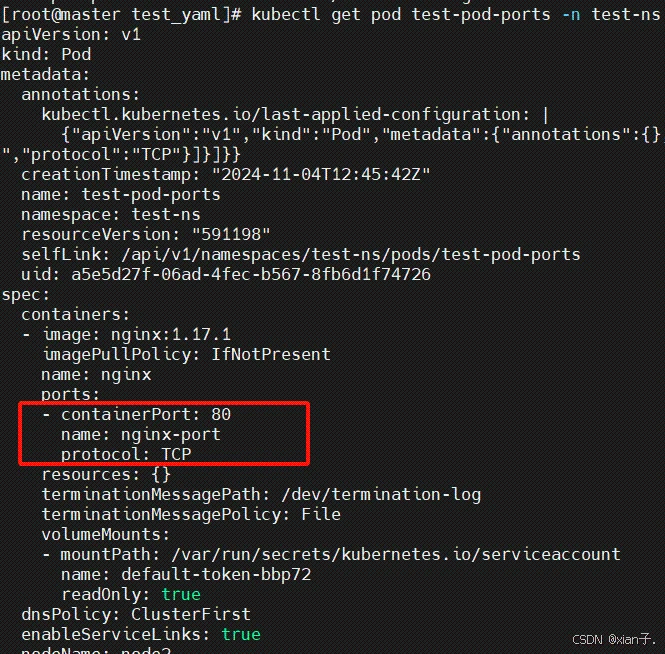
访问容器中的程序需要使用的是 podIP:containerPort。
容器中的程序要运行,肯定是要占用一定资源的,比如cpu和内存等,如果不对某个容器的资源做限制,那么它就可能吃掉大量资源,导致其它容器无法运行(一个节点上的资源总额是一定的,例如内存,若A容器忽然“发疯”,开始大量消耗内存,如果未对其进行限制,则势必会导致BCDE…等其他容器无法正常运行)。针对这种情况,kubernetes提供了对内存和cpu的资源进行配额的机制,这种机制主要通过resources选项实现,他有两个子选项:可以通过下面两个选项设置资源的上下限。
编写一个测试案例(针对CPU和内存),创建test-pod-resources.yaml
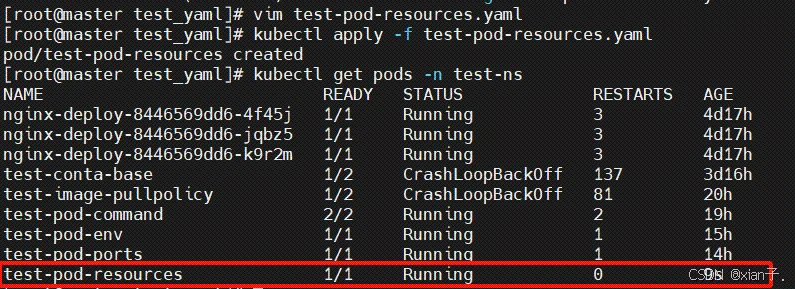
运行成功了,即当前的环境满足配置文件中的条件了。若将pod的资源下限改为10Gi还能运行成功吗:
首先删除原pod:
然后修改test-pod-resources.yaml中的上述配置信息,重新创建pod:
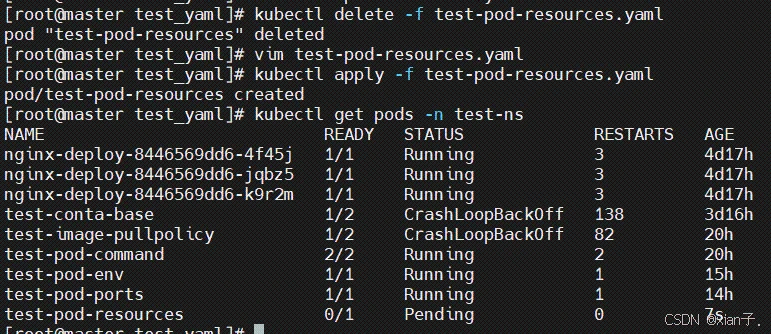
可以看到,新创建的pod没有运行成功,处于Pending状态。查看详细信息:

显示三个节点上没有可以满足内存需求的,因此没有调度部署成功。
参考:B站大学
到此这篇kubernetes发音(kubectl发音)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/do-docker-k8s/51066.html