
有时候我们想要生成一个唯一不重复的随机数,mysql提供了rand()函数来实现该功能。
- rand() 即无参数的,会生成一个[0,1)之间的float型随机数。此时产生的随机数是;
- rand(n),即有参数数,它会使用参数n作为随机数生成的种子。每次使用相同的种子值n,将得到相同的随机排序结果。因此。这种随机数也是伪随机的
rand(n)函数:
- n是int类型的数字,所以只要是数字就行。不同的种子值生成的随机数是不一样的;对于同一个种子值n,每次返回的随机数是固定的。
- 同一次查询时,结果集中可能会产生重复随机数。
- 多次查询时,每次返回的随机数与上一次是一致的。
注意:频繁地在一个很大的数据集上使用RAND()可能会导致性能问题,因为这会导致数据库引擎在每次查询时都生成一个新的随机数。
示例如下:
我们发现:
- 当直接调用rand()函数时,每次生成的随机数都是不同的。
- 当直接调用rand(n)函数时,若种子n相同,则生成的随机数是可重复且多次查询是一致的。
上面我们说rand(n)函数,每次使用相同的种子值n,将得到相同的随机排序结果,这是什么意思呢?为了便于理解上面两种示例,我们把rand(),rand(n) 结合表数据一起看一下。
可以发现:
- rand()函数:每次查询都生成不一样的数据。同一次查询中每行数据的随机数都不一样;。
- rand(n)函数:(注意:数据量小的情况不一定有重复值); 即是指定了随机数的种子,那么多次查询的结果是一样的。
rand()函数用于随机生成一个不重复的数字,所以当rand()与order by组合使用时,可以实现数据随机排序。
使用场景: 例如可以用于样本抽样,先对数据进行随机排序,然后抽取前x条。
:因为是随机排序,所以每次返回不同的结果。如果目标是以随机顺序检索行,则可以使用这样的语句。
round(n,m):对处理的数据进行四舍五入,
n:处理的数据
m:保留的小数位数
实例1.获取某个区间的数据

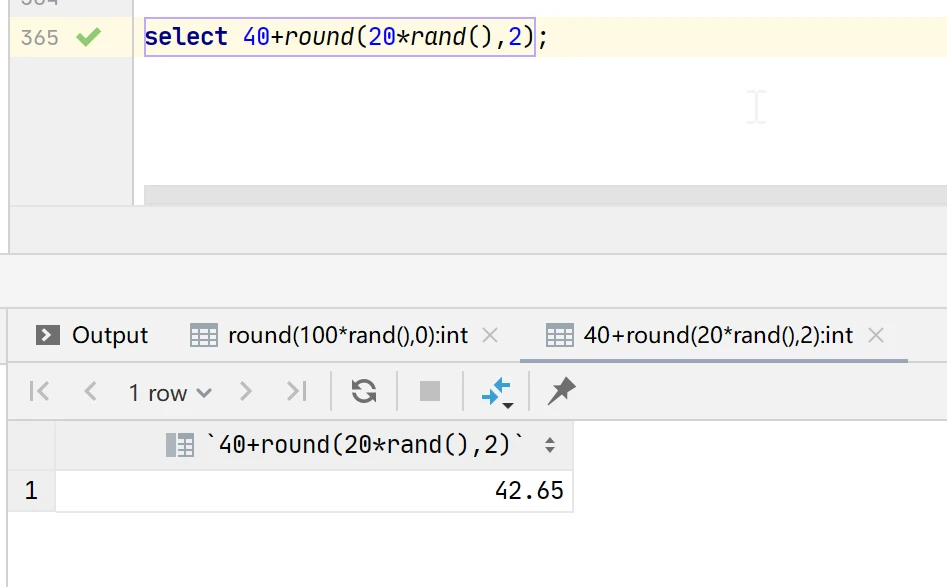
实例2:获取[40,60)的两位小数
ceiling(n):对于数据n向上取整
实例1:select ceiling(1.12)

实例2:select ceiling(rand());
rand():随机在[0,1)之间,故结果肯定为1

实例3:随机获取[60,80)之间的整数

floor():是向下取整
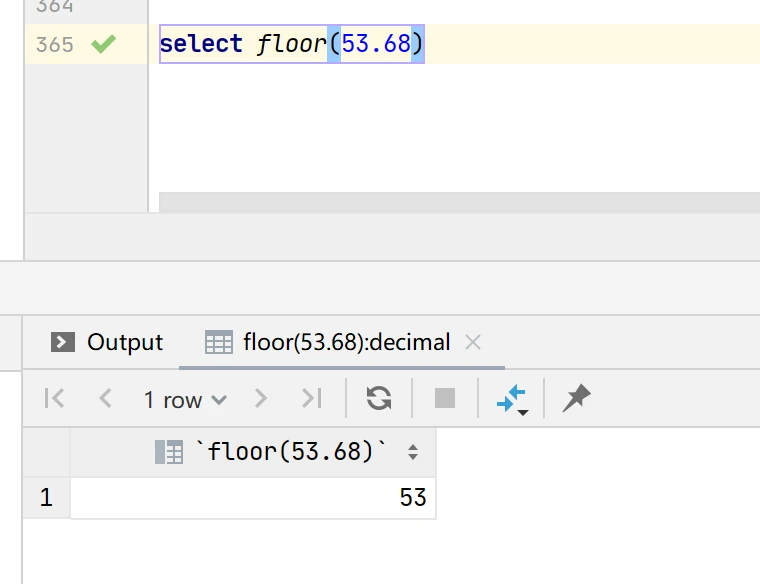
实例1:select floor(53.68)
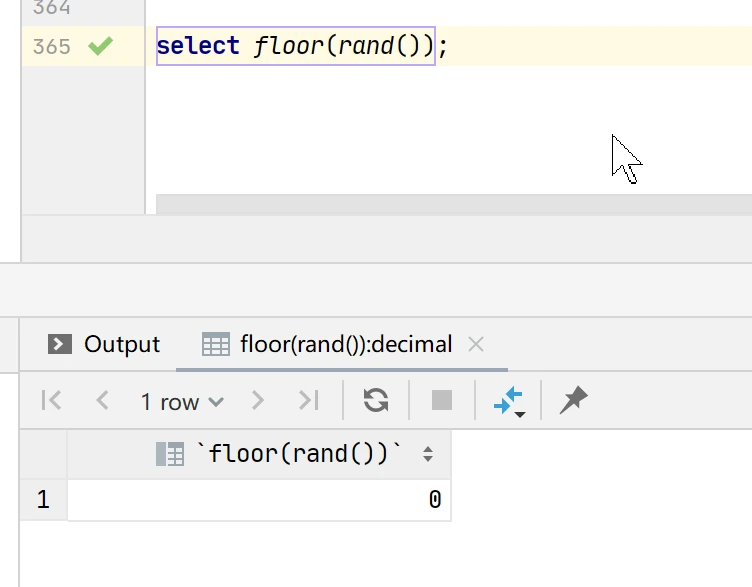
实例2:select floor(rand());
ps:rand()向下取整必然为0
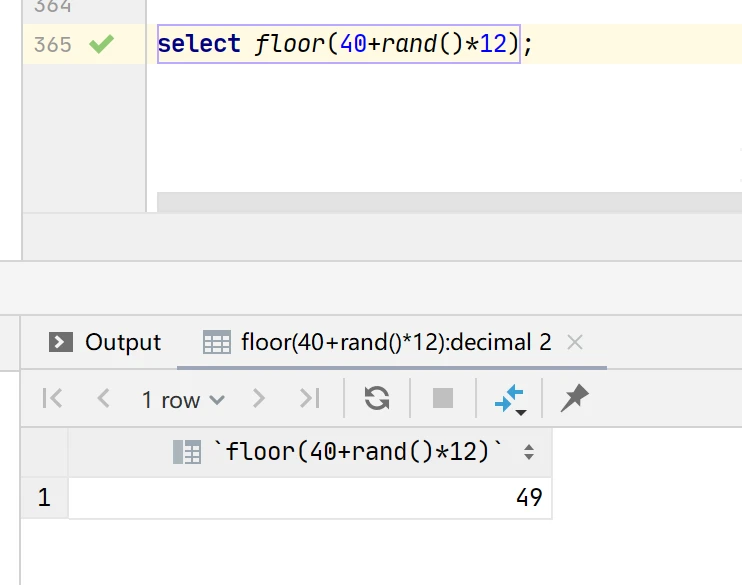
实例3:[40,52)之间取整
实例1:select md5(123.44);
实例2:select md5(rand());

rand()函数
- 每次生成是随机数都是的。
- 适用场景:样本抽样,对数据随机排序后获取前x条。每次排序的结果都是随机的、不一致的。
rand(n:int)函数
- n是个int类型的种子参数,每个种子生成的随机数都是不同的。但是相同的种子每次返回的随机数都是固定的。如rand(2)每次返回的值是固定的。
- 同一次查询时结果集中可能会产生重复的数字。
- 多次查询时每次返回的随机数与上一次查询结果一致。
- 适用场景:用于需要重复生成相同随机数序列的场景,例如模拟实验或测试中需要重复执行相同的随机操作。
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/haskellbc/40668.html