
ent 是 Facebook 开源的一款 Go 语言实体框架,是一款简单而强大的用于建模和查询数据的 ORM 框架。
图是用来对对象之间的成对关系建模的数学结构,由"节点"或"顶点"(Vertex)以及连接这些顶点的"边"(Edge)组成。
在离散数学中,图(graph)是用于表示物体与物体之间存在某种关系的结构。数学抽象后的“物体”称作节点或顶点(vertex, node, point),节点间的相关关系则称作 边(edge)。
图的应用非常广泛,可在物理、生物、社会和信息系统中建模许多类型的关系和过程,许多实际问题可以用图来表示。
例如社交网络中的好友关系、计算机网络连接关系、地图道路等等,图的种类多种多样,根据不同的业务需求,选择不同的图。
ent 是 Facebook 开源的一款 Go 语言实体框架,是一款简单而强大的用于建模和查询数据的 ORM 框架。
它遵循以下原则,可轻松构建和维护具有大型数据模型的应用程序:
- 将数据库 schema 建模为图形结构
- 像写 Go 代码一样定义 schema
- 基于代码生成的静态类型
- 便于编写数据库查询和图遍历
- 使用 Go 模板实现扩展和定制
使用 ent 的过程大致分为以下几步。
- 先定义好 schema
- 根据 schema 生成代码
- 使用生成的 CRUD 代码编写业务代码
执行以下命令安装 ent cli 工具。
接下来,我们将快速开始一个简单示例。
创建一个 entdemo 项目,执行以下命令完成项目初始化。
在项目的根目录下执行以下命令,创建一个 schema。
该命令会在项目目录下创建一个 目录,其中包含 目录和一个 文件。
文件中的内容便是定义的 schema。
其中,
- 结构体保存实体的 schema 定义。
- 方法返回 中都有哪些字段。
- 方法返回 与其他实体的关系。
修改 文件,向 的 schema 添加2个字段:
在项目根目录执行以下命令,根据上述 schema 生成代码。
将会生成以下文件。
使用生成的代码,实现实体的CRUD操作。
ent 支持 SQLite、PostgreSQL、MySQL(MariaDB),本文以 MySQL 为例。
首先,创建一个新客户端来运行 schema 迁移并与实体进行交互:
运行 schema 迁移后,我们就可以创建用户了。在本例中,我们将此函数命名为 CreateUser :
为每个实体模式生成一个包,其中包含属性、默认值、验证器和有关存储元素的附加信息(列名、主键等)。
在教程的这一部分,我们要在 schema 中声明与另一个实体的边(关系)。
让我们创建两个额外的实体,分别名为 和 ,并添加一些字段。使用下面的 ent CLI 命令生成初始 schema :
然后,手动添加其余字段:
文件:
文件:
让我们定义第一个关系。到的边定义了一个用户可以拥有 1 辆或多辆汽车,但一辆汽车只有一个车主(一对多关系)。
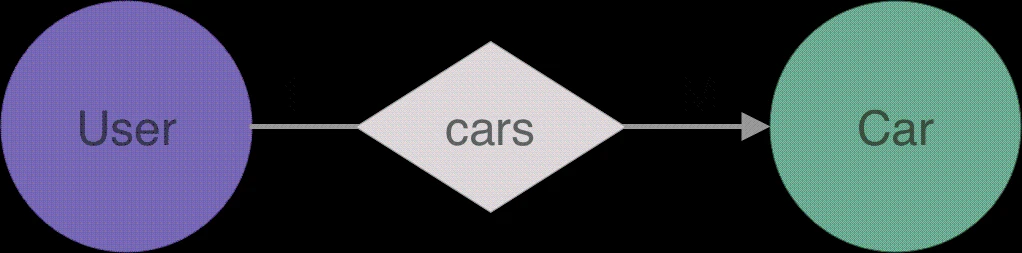
让我们将 “Car” 边添加到 schema 中,在 文件中添加以下内容,并运行 生成代码:。
接下来,创建两辆车并将其关联到用户身上。
想要查询用户的汽车,可以按下面的方式查询。
假设我们有一个 “)对象,并想获得它的所有者,即这辆车的用户。为此,我们使用 函数定义了另一种名为 “反向边缘 ”的边缘。
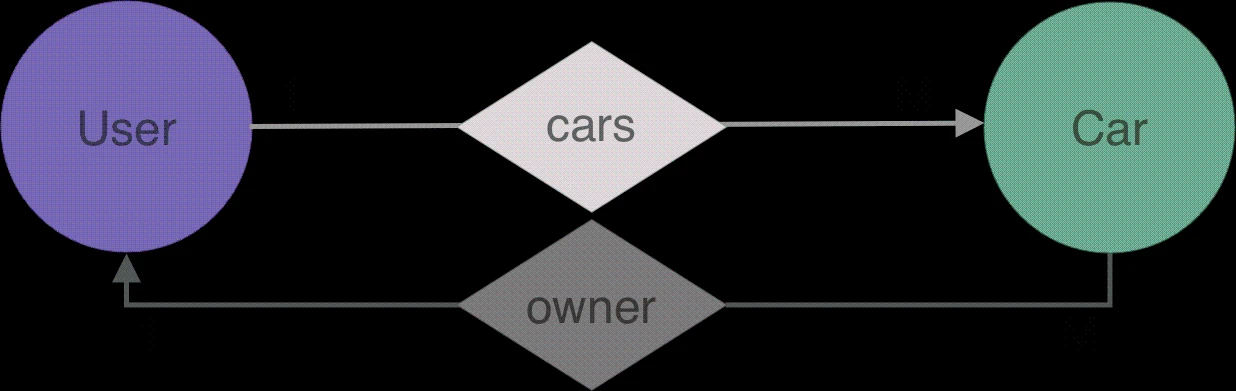
上图中创建的新边是半透明的,以强调我们不会在数据库中创建另一条边。这只是对真实边缘(关系)的反向引用。
让我们在 的 schema 中添加一个名为 的反向边,将其引用到 schema 中的 边,然后运行 。
我们将通过查询反向边缘来继续上面的用户/汽车示例。
我们将继续我们的示例,在用户和组之间创建M2M(多对多)关系。

每个 Group 实体可以有多个 User,并且一个 User 可以连接到多个 Group; 这是一个简单的“多对多”关系。在上图中,Group 模式是用户边(关系)的所有者,User 实体对这个名为 Group 的关系具有反向引用/反向边。让我们在 schema 中定义这种关系:
文件中增加以下内容。
文件中添加一个 。
修改完上述内容后,执行以下命令生成代码。
要查看 Ent 为数据库生成的 SQL 模式,请安装 Atlas 并运行以下命令:
在你的终端执行以下命令。
Mac:
Windows:
点击下载链接 下载最新版本,然后将其添加到环境变量中。
输入以下命令。
首先,我们需要按下图生成一些数据(节点和边,或者换句话说,实体和关系)。
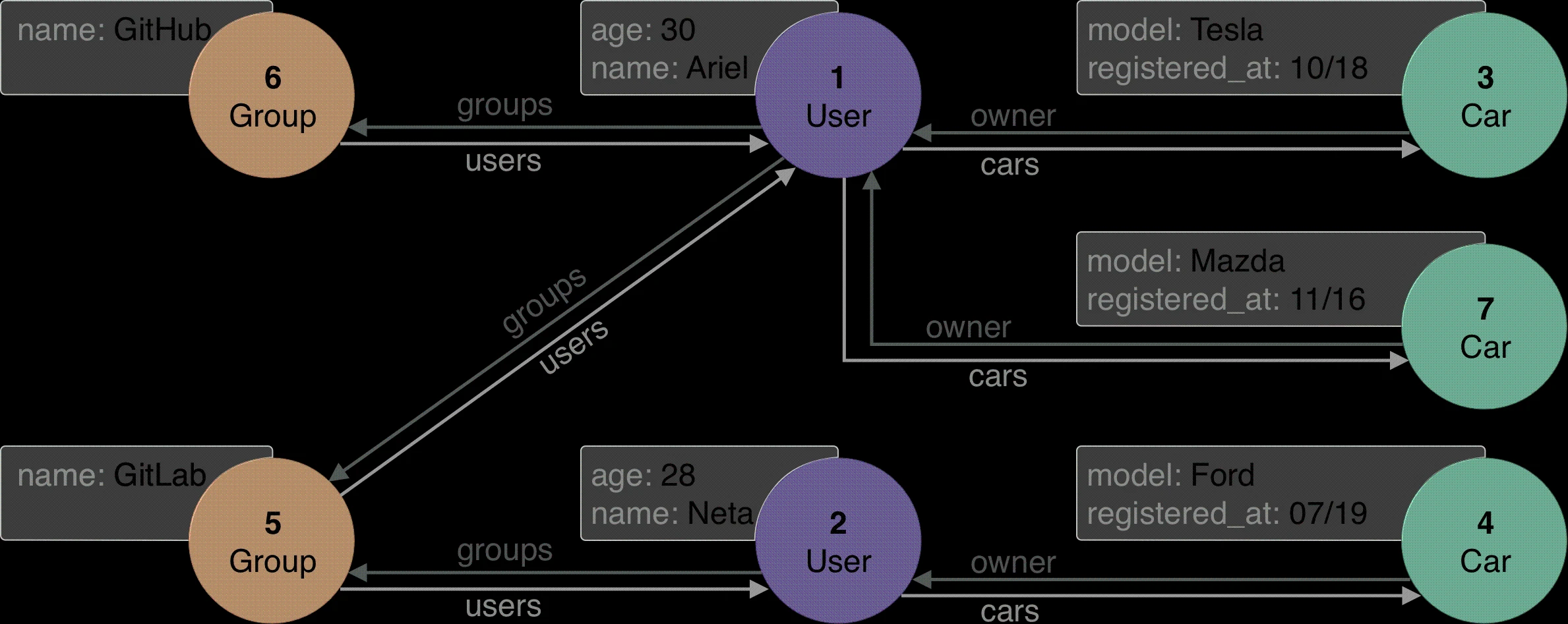
实际创建数据的代码:
执行上面的代码后,会生成准备好的数据。我们就可以对它执行一些查询:
- 获取名为“ GitHub”的组中所有用户的汽车:
- 根据 查询符合要求的汽车。
- 获取所有有用户的组(查询时使用查找谓词):
Ent 提供了两种运行模式迁移的方法:自动迁移和版本化迁移。
以下是每种方法的简要概述:
通过自动迁移,我们可以使用以下 API 来保持数据库模式与生成的 SQL 模式 中定义的模式对象保持一致:
这种方法主要用于原型设计、开发或测试。因此,建议在关键任务的生产环境中使用版本化迁移方法。通过使用版本化的迁移,用户事先就知道要对数据库应用哪些更改,并且可以根据需要轻松地调优这些更改。
可通过阅读自动迁移文档了解更多。
与自动迁移不同,版本迁移方法使用 Atlas 自动生成一组迁移文件,其中包含迁移数据库所需的 SQL 语句。这些文件可以编辑以满足特定需求,并使用现有的迁移工具(如Atlas、golang migrate、Flyway和Liquibase)进行应用。这种方法的 API 包括两个主要步骤。
生成迁移
提交迁移
阅读版本化迁移文档了解更多信息。

版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/hd-nodejs/69798.html