
简介
灰狼优化算法(GWO)模拟了自然界灰狼的领导和狩猎层级,在狼群中存在四种角色, α \alpha α狼负责领导是最具有智慧的在狩猎当中可以敏锐的知道猎物的位置, β \beta β狼可以认为是军师比较具有智慧比较能知道猎物的位置, δ \delta δ狼负责协助前两个层级的狼,最后是 ω \omega ω狼负责跟从。
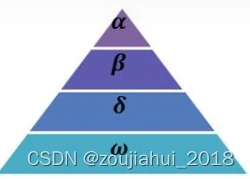
在狩猎(寻优)的过程中,狼群的这三种层级并不是一成不变的,也会根据各个狼的适应度(fitness)进行调整,适应度最强的狼将会成为新的 α \alpha α狼,其次是 β \beta β狼,依次类推。通过很多次的寻找猎物(寻优)中三个层级逐渐趋于稳定,这个时候我们取 α \alpha α狼的位置作为猎物(最优解)所处的位置。
注意:注意智能优化算法都是在优化函数光滑性较差,容易落入局部最优时才使用的,不要乱用。智能优化算法的收敛是一种概率意义的收敛,所以得到的解并不一定绝对最优,并且往往收敛较慢。
算法
- Step1: 根据优化的问题,设计fitness函数(目标函数,默认的是极小化问题),设置可行域
- Step2: 初始化狼群的个数N,每头狼的位置 X i ( i = 1 , . . . , N ) X_i(i=1,...,N) Xi(i=1,...,N),并指定 α , β , δ \alpha,\beta,\delta α,β,δ狼的位置 X α , X β , X δ X_\alpha,X_\beta,X_\delta Xα,Xβ,Xδ, 以及它们对应的适应度 f α , f β , f δ = f_\alpha,f_\beta,f_\delta= fα,fβ,fδ=inf.
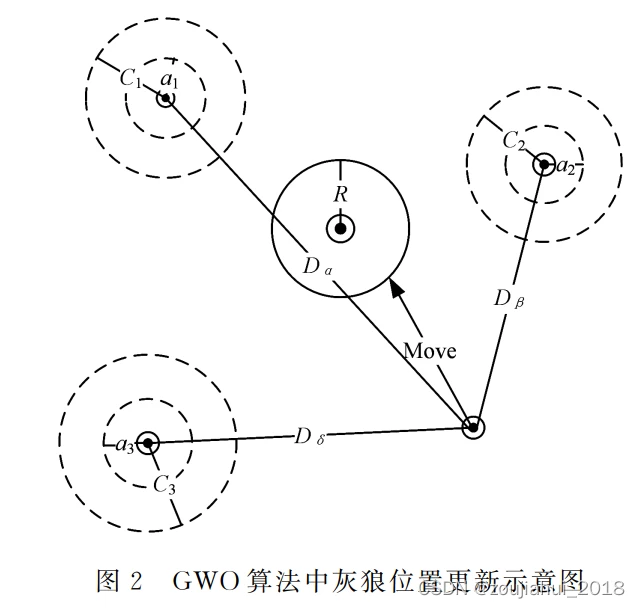
- Step3: 依次更新每头狼的位置。对于第 i i i头狼,计算其与 α , β , δ \alpha,\beta,\delta α,β,δ狼的距离
D α = ∣ C 1 ∘ X α − X i ∣ , D β = ∣ C 2 ∘ X β − X i ∣ , D δ = ∣ C 3 ∘ X δ − X i ∣ , \begin{aligned} D_\alpha=|C_1\circ X_\alpha-X_i|,\\ D_\beta=|C_2\circ X_\beta-X_i|,\\ D_\delta=|C_3\circ X_\delta-X_i|,\\ \end{aligned} Dα=∣C1∘Xα−Xi∣,Dβ=∣C2∘Xβ−Xi∣,Dδ=∣C3∘Xδ−Xi∣,
并产生向三头狼移动的趋势项
Q 1 = X α − A 1 ∘ D α , Q 2 = X β − A 2 ∘ D β , Q 3 = X δ − A 3 ∘ D δ , \begin{aligned} Q_1=X_\alpha-A_1\circ D_\alpha,\\ Q_2=X_\beta-A_2\circ D_\beta,\\ Q_3=X_\delta-A_3\circ D_\delta,\\ \end{aligned} Q1=Xα−A1∘Dα,Q2=Xβ−A2∘Dβ,Q3=Xδ−A3∘Dδ,
其中, ∘ \circ ∘表示hardmard乘积, r 1 , r 2 ∼ r_1,r_2\sim r1,r2∼ Unif([0,1]), A i = a ( 2 r 1 − 1 ) , C i = 2 r 2 ( i = 1 , 2 , 3 ) A_i=a(2r_1-1),C_i=2r_2(i=1,2,3) Ai=a(2r1−1),Ci=2r2(i=1,2,3), a = 2 ( 1 − t / T ) a=2(1-t/T) a=2(1−t/T)(t是当前迭代次数,T是最大迭代次数)。如果 A i , C i A_i,C_i Ai,Ci是分量,则每个分量都独立生成,以上运算按照广播规则。最后可以得到第 i i i头狼的位置更新为
X i ← 1 3 ( Q 1 + Q 2 + Q 3 ) . \begin{aligned} X_i\leftarrow \frac{1}{3}(Q_1+Q_2+Q_3). \end{aligned} Xi←31(Q1+Q2+Q3). - Step4:不断重复Step3直至 α \alpha α狼群的位置稳定。
二进制灰狼算法
- Step1: 根据优化的问题,设计fitness函数(目标函数,默认的是极小化问题),设置可行域
- Step2: 初始化狼群的个数N,每头狼的位置 X i ( i = 1 , . . . , N ) X_i(i=1,...,N) Xi(i=1,...,N),并指定 α , β , δ \alpha,\beta,\delta α,β,δ狼的位置 X α , X β , X δ X_\alpha,X_\beta,X_\delta Xα,Xβ,Xδ, 以及它们对应的适应度 f α , f β , f δ = f_\alpha,f_\beta,f_\delta= fα,fβ,fδ=inf.
- Step3: 依次更新每头狼的位置。对于第 i i i头狼,计算其与 α , β , δ \alpha,\beta,\delta α,β,δ狼的距离
D α = ∣ C 1 ∘ X α − X i ∣ , D β = ∣ C 2 ∘ X β − X i ∣ , D δ = ∣ C 3 ∘ X δ − X i ∣ , \begin{aligned} D_\alpha=|C_1\circ X_\alpha-X_i|,\\ D_\beta=|C_2\circ X_\beta-X_i|,\\ D_\delta=|C_3\circ X_\delta-X_i|,\\ \end{aligned} Dα=∣C1∘Xα−Xi∣,Dβ=∣C2∘Xβ−Xi∣,Dδ=∣C3∘Xδ−Xi∣,
并产生向三头狼移动的趋势项
Q 1 = X α − A 1 ∘ D α , Q 2 = X β − A 2 ∘ D β , Q 3 = X δ − A 3 ∘ D δ , \begin{aligned} Q_1=X_\alpha-A_1\circ D_\alpha,\\ Q_2=X_\beta-A_2\circ D_\beta,\\ Q_3=X_\delta-A_3\circ D_\delta,\\ \end{aligned} Q1=Xα−A1∘Dα,Q2=Xβ−A2∘Dβ,Q3=Xδ−A3∘Dδ,
其中, ∘ \circ ∘表示hardmard乘积, r 1 , r 2 ∼ r_1,r_2\sim r1,r2∼ Unif([0,1]), A i = a ( 2 r 1 − 1 ) , C i = 2 r 2 ( i = 1 , 2 , 3 ) A_i=a(2r_1-1),C_i=2r_2(i=1,2,3) Ai=a(2r1−1),Ci=2r2(i=1,2,3), a = 2 ( 1 − t / T ) a=2(1-t/T) a=2(1−t/T)(t是当前迭代次数,T是最大迭代次数)。如果 A i , C i A_i,C_i Ai,Ci是分量,则每个分量都独立生成,以上运算按照广播规则。最后可以得到第 i i i头狼的位置更新为
X i ← { 1 , i f s i g m o i d { 1 3 ( Q 1 + Q 2 + Q 3 ) } ≥ z 0 , o t h e r w i s e . \begin{aligned} X_i\leftarrow \begin{cases} 1,\quad if\quad sigmoid\left\{\frac{1}{3}(Q_1+Q_2+Q_3)\right\}\geq z\\ 0,\quad otherwise. \end{cases} \end{aligned} Xi←{ 1,ifsigmoid{ 31(Q1+Q2+Q3)}≥z0,otherwise.
其中, z ∼ z\sim z∼unif([0,1]), sigmoid(x)= 1 1 + e − 10 ( x − 0.5 ) \frac{1}{1+e^{-10(x-0.5)}} 1+e−10(x−0.5)1. - Step4:不断重复Step3直至 α \alpha α狼群的位置稳定。
代码
clear;clc; % 狼群数量 SearchAgents_no = 30; % 最大迭代次数 Max_iter = 200; % 变量维度 dim = 2; % 上限 ub = 10 * ones(1, dim); % 下限 lb = -10 * ones(1, dim); %%%%% 初始化 Alpha_pos = zeros(1, dim); Alpha_score = inf; Beta_pos = zeros(1, dim); Beta_score = inf; Delta_pos = zeros(1, dim); Delta_score = inf; % 初始化位置 Positions = rand(SearchAgents_no, dim) .* repmat(ub - lb, SearchAgents_no, 1) + repmat(lb, SearchAgents_no, 1); Convergence_curve = zeros(1, Max_iter); % 主循环 for l = 1 : Max_iter for i = 1:SearchAgents_no % 边界处理:越界赋值为边界值 Flag4ub = Positions(i, :) > ub; Flag4lb = Positions(i, :) < lb; Positions(i, :) = (Positions(i, :) .* (~(Flag4ub + Flag4lb))) + ub .* Flag4ub + lb .* Flag4lb; % 计算目标函数 fitness = ObjFun(Positions(i, :)); % 更新 Alpha、Beta 和 Delta if fitness < Alpha_score Alpha_score = fitness; Alpha_pos = Positions(i, :); end if fitness > Alpha_score && fitness < Beta_score Beta_score = fitness; Beta_pos = Positions(i, :); end if fitness > Alpha_score && fitness > Beta_score && fitness < Delta_score Delta_score = fitness; Delta_pos = Positions(i, :); end end % 线性递减 a = 2 - l * 2 / Max_iter; % 更新位置 for i = 1 : SearchAgents_no for j = 1: dim %%%%% 更新策略 r1 = rand(); r2 = rand(); A1 = 2*a*r1 - a; C1 = 2*r2; D_alpha = abs(C1*Alpha_pos(j) - Positions(i, j)); X1 = Alpha_pos(j) - A1*D_alpha; r1 = rand(); r2 = rand(); A2 = 2*a*r1 - a; C2 = 2*r2; D_beta = abs(C2*Beta_pos(j) - Positions(i, j)); X2 = Beta_pos(j) - A2*D_beta; r1 = rand(); r2 = rand(); A3 = 2*a*r1 - a; C3 = 2*r2; D_delta = abs(C3*Delta_pos(j) - Positions(i, j)); X3 = Delta_pos(j) - A3*D_delta; Positions(i, j) = (X1 + X2 + X3) / 3; end end Convergence_curve(l) = Alpha_score; end disp(['最优值:' num2str(Alpha_pos)]); disp(['最优值对应目标函数:' num2str(Convergence_curve(end))]); subplot(1, 2, 1) plot(Convergence_curve, 'LineWidth', 2); xlabel('迭代次数'); ylabel('适应度值'); title('适应度曲线'); len = 50; xRange = linspace(lb(1), ub(1), len); yRange = linspace(lb(2), ub(2), len); [xMap, yMap] = meshgrid(xRange, yRange); zMap = zeros(len); for i = 1 : len for j = 1 : len zMap(i, j) = ObjFun([xMap(i, j), yMap(i, j)]); end end subplot(1, 2, 2) surf(xRange, yRange, zMap); view(-45, -45); shading interp hold on plot3(Alpha_pos(1), Alpha_pos(2), ObjFun(Alpha_pos), 'o', 'MarkerFaceColor', 'r', 'MarkerSize', 10); hold off set(gcf, 'Position', [400, 200, 900, 400]); function result = ObjFun(x) x1 = x(1); x2 = x(2); t = x1^2 + x2^2; result = 0.5 + (sin(sqrt(t))^2 - 0.5) / (1 + 0.001 * t)^2; end 
参考文献
https://zhuanlan.zhihu.com/p/
https://zhuanlan.zhihu.com/p/
张晓凤, 王秀英. 灰狼优化算法研究综述[J]. 计算机科学, 2019, 046(003):30-38.
Mirjalili S, Mirjalili SM, Lewis A. Grey wolf optimizer. Adv Eng Software 2014;69:46–61
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/hd-xnyh/10337.html