
GPU分布式训练是指同时利用一台或者多台机器上的 GPU 进行并行计算,使神经网络训练达到更大的batchsize和更快的训练速度,其在大规模网络训练中是十分重要的。本范例基于pytorch的nn.DataParallel和nn.distributedataparallel在多个GPU上切分模型和数据,在训练过程中,每个节点起进程从磁盘加载batch数据,并将它们传递到其节点GPU,每一个节点GPU都有自己的前向过程,然后梯度在各个GPUs间进行All-Reduce。在此过程中,每一层的梯度不依赖于前一层,所以梯度的All-Reduce和后向过程同时计算,能够缓解网络瓶颈。在后向过程的最后,每个节点都得到了平均梯度,这样模型参数保持同步。最终多节点协同训练一个高精度的神经网络模型,本范例实现基于ImageNet图像识别的resnet18模型。
1.1 节点创建
- 使用账号登录“国家未来智能网络试验设施创新试验服务平台” :http://ceni.ustc.edu.cn。
- 登录后,点击“我的试验”→“创建新试验”,填写试验名称及试验说明。
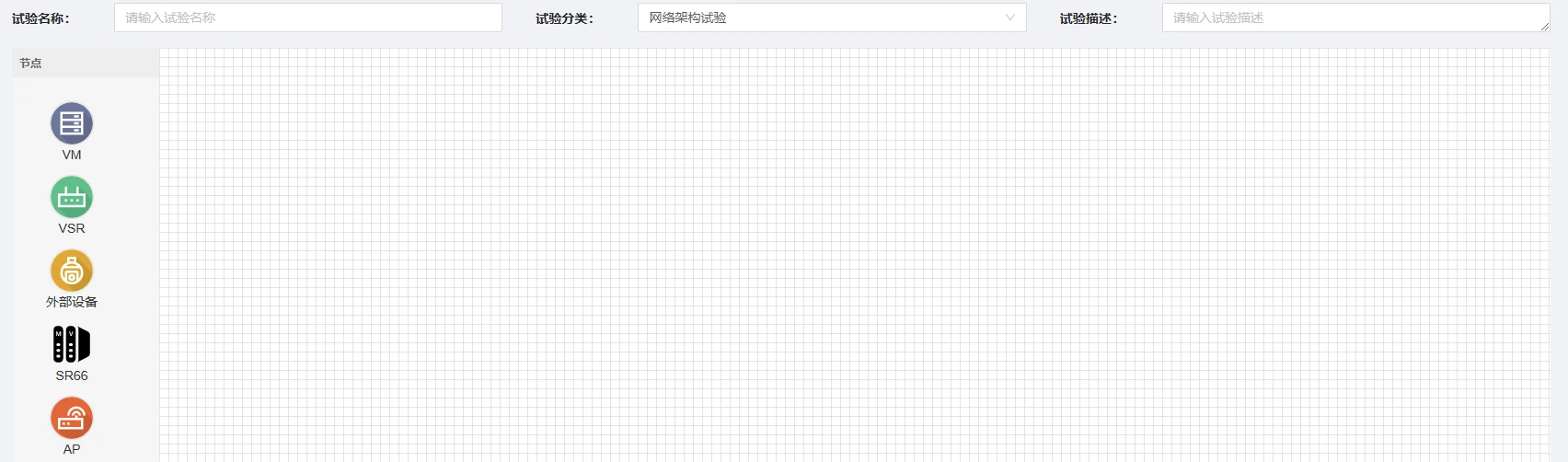
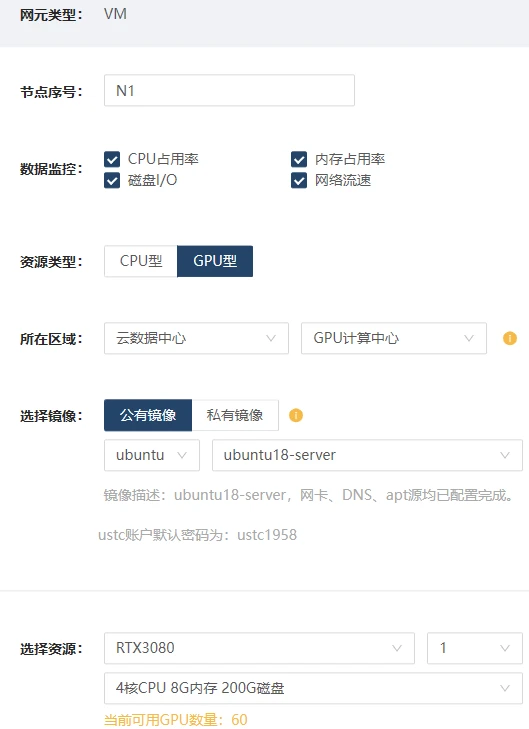
- 点击下一步开始资源配置。将左侧“VM”拖动到右侧网格区域创建新的节点。首先创建GPU型节点N1:所在区域选择“云数据中心”-“GPU计算中心”镜像选择“公有镜像”—“Ubuntu”—“ubuntu18-server”选择资源选择为“RTX3080” —“4核CPU 8G内存 200G磁盘”,其余配置无需更改,配置完成后点击“保存并复制节点”以增加相同配置的其他节点,至少配置两个节点,这里配置3个节点。
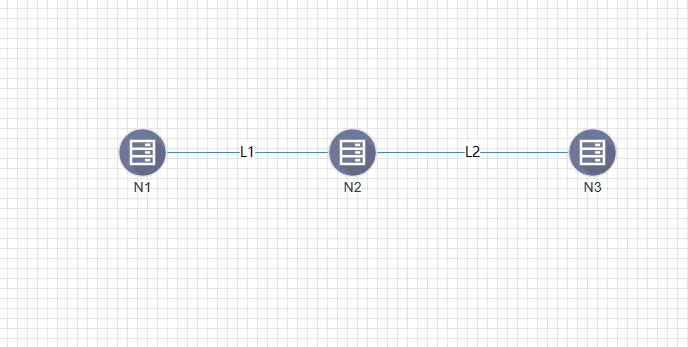
- 将鼠标悬浮在网格中界点上方,点击节点周围红色小圆圈并拖动与其他节点相连,右侧弹出链路信息,带宽选择10Mbps,其余配置无需更改点击确认增加链路。
- 设置完成后点击“创建试验”,创建成功后点击右上角的“运行试验”即可开始试验。
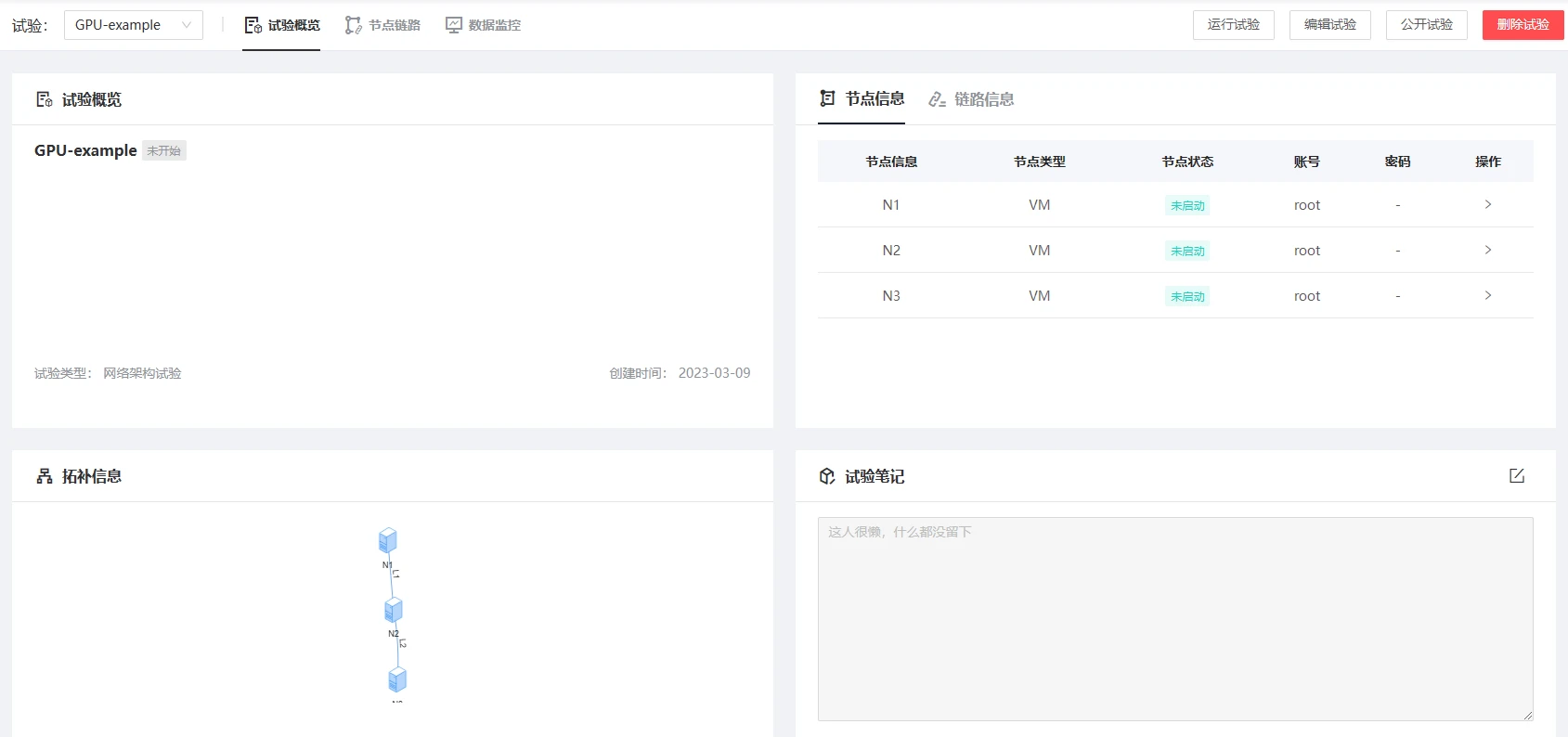
- 点击“控制台”,进入虚拟机登录界面,使用“root”账户登陆,密码见上述界面,依次输入用户名“root”及密码即可进入虚拟机。
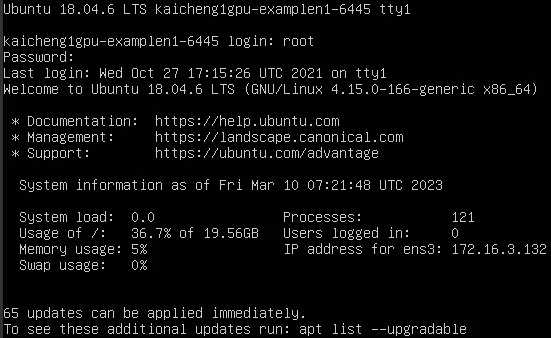
1.2 GPU环境配置
- 安装NVIDIA驱动:
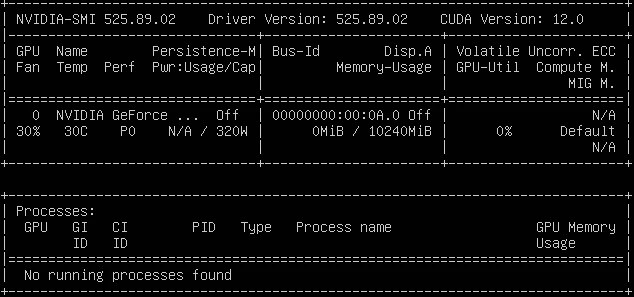
首先终端输入指令、、安装必备的软件包;然后安装NVIDIA驱动,执行下载安装包,下载完成后执行安装NVIDIA驱动,选择“ok”、“yes”完成安装,安装完成后执行指令检查是否安装成功,若出现如下结果则成功安装。
- 安装conda并创建GPU分布式训练环境:
终端执行指令下载miniconda安装包,下载完成后执行进行安装,一直输入回车键确认直到输入“yes or no”,输入默认安装在“root/miniconda”目录下,继续输入执行conda初始化,安装完成后输入重启节点,重启后会自动进入conda base环境。重启后执行指令检查NVIDIA驱动是否挂掉,若NVIDIA驱动没有成功运行,则执行指令、,再次查看NVIDIA驱动可成功运行。接下来配置conda源,终端输入:
然后执行 删除。

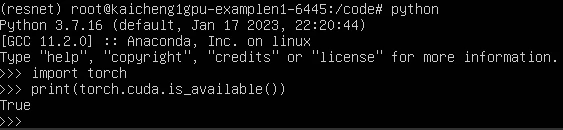
创建GPU分布式训练环境,命名为resnet,执行命令。最后下载pytorch、torchvision和cudatoolkit,切换conda环境为“resnet”,执行命令,在resnet conda环境下,输入进入虚拟环境,输入、显示结果为true则GPU环境配置完成。
1.3 数据集及训练代码下载
- 数据集及代码下载
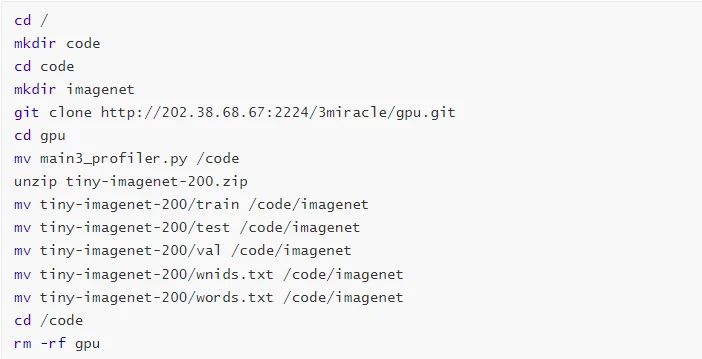
1.4 网络+GPU训练
首先进入conda环境——resnet,执行
单机训练命令:
节点N:

多机训练命令:
N1节点:
N2节点:
N3节点:



注意,三个GPU节点的dist-url都应设置为rank 0的IP和freeport比如8090,端口占用情况查看,其中,main.py用法如下:

-a:神经网络模型结构,可选用的模型有alexnet、convnext_base、googlenet、shufflenet_v2_x0_5、vgg16等,详情python main.py -h
-j:torch数据加载的workers,默认为4,这里设置为2
--epochs:运行的总epoch数,这里设置为30
--gpu:使用的GPU id,仅在单机训练时使用
--dist-url:设置分布式训练url,多机训练时都应为rank0的IP和端口
--dist-backend:分布式训练通信后端
--multiprocessing-distributed:多进程分布式训练
--world-size:分布式训练的节点数
--rank:分布式训练节点索引
每一轮epoch训练结束后会对验证数据集val进行top1 accuracy和top5 accuracy模型评估,同时会生成checkpoint的模型参数checkpoint.pth.tar以便后续在断点开始继续训练,记录最优模型model_best.pth.tar。


2.1 云盘使用注意事项
- 按照ceni首页帮助文档的《平台FAQ》,将云盘操作python脚本下载到新目录下
- 安装python2和Java运行环境jre:
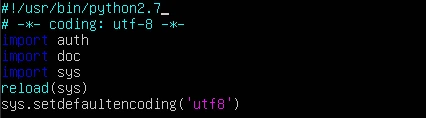
- vim修改openapi_util,新增两行如下,后续所有python脚本操作皆以python2.7开头
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/hd-yjs/11996.html