

本文介绍在本地环境部署大模型服务的过程,主要介绍依赖的安装、大模型服务的部署、基于gradio的可视化demo。
上图是本文相关的技术内容,可以通过一段话的总结来理解它们的关系:使用了一张RTX3090的显卡,有24GB显存,使用的大模型是Qwen1.5-14B-Chat-GPTQ-Int4,在部署上使用了vllm提升大模型的性能,使用fschat将大模型部署成服务,并基于gradio创建了一个可视化的聊天窗口。
关于环境
大模型服务主要依赖于GPU资源,这次的实验是在一个虚拟机上完成的,分配了一张RTX3090卡,有24G显存,大模型服务启动之后,显存使用在20GB左右。
关于大模型
本次使用的大模型是Qwen1.5-14B-Chat-GPTQ-Int4,这里借用Kimi对这个大模型的名字进行解释:
Qwen1.5-14B-Chat-GPTQ-Int4:这个名称可能表示一个名为Qwen的模型,版本为1.5,具有140亿参数,主要用于聊天应用,采用了GPT架构的某种变种,并使用了4字节整数的数据类型。
Kimi
具体可查看:https://kimi.moonshot.cn/share/cp269sivk6g8dhe16o3g
关于大模型的估算问题
按照我的理解,大模型因为其参数庞大所以需要占用很多的显存。比如大模型动辄上百亿的参数,假如使用16位浮点数存储这些参数值,则大致需要的显存有:
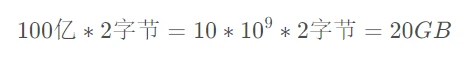
所以,在FP16的精度下,一个10B参数规模的大模型,大概需要20GB的显存。
大模型经过量化之后可以显著降低资源开销,比如Int4量化即使用4bit来存储一个参数,与原来16bit的存储精度相比减少到1/4的资源开销,则10B参数规模的大模型只需要5GB的显存。但是出于某些原因,并无法达成这么协调的换算,根据经验所需要的显存大概缩减到1/3左右。所以一个10B参数规模的Int4量化版本,大概需要的显存是:
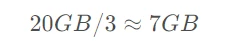
这里的某些原因,有一些合理的说法,比如大模型的资源占用不只是用来存参数,其他的开销可能没有通过量化技术得到缩减。
根据上述信息,我所使用的Qwen1.5-14B-Chat-GPTQ-Int4估算应该占用的显存是:
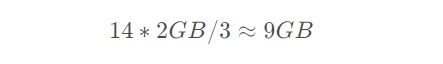
关于大模型量化技术的讨论,可以参考:https://kimi.moonshot.cn/share/cp26kssubms6ha9a3cjg
关于大模型的推理速度
直接加载大模型并部署服务,其性能低的可怜,具体表现在一次请求的答案生成过程很慢,以及多个并发请求需要排队时间较长才能得到结果。
当然我们可以通过堆GPU服务器,部署更多的大模型服务实例来提高其吞吐率,但是鉴于GPU资源的价格昂贵,而大模型对GPU资源的需求较高,更合理的想法是从技术上找提高性能的方案。
比如在实践经验中验证,使用vllm [https://github.com/vllm-project/vllm] 可以将生成速率提高34倍,吞吐率提高45倍,将GPU资源使用率从50%提升到90%左右。这表示它需要使用更多的GPU,但确实带来了很高的回报。
安装依赖
按需安装下面的依赖:
安装过程中遇到的问题
安装vllm过程遇到的错误:

使用Kimi进行分析:https://kimi.moonshot.cn/share/cour4rgnsmmsr9ubddqg
最后通过手动下载nccl并放置到错误信息中提到的目录,且进行了重命名:
启动服务
分别启动controller、worker、api服务。
启动gradio:
上述脚本内容已经过完善。
启动服务过程中遇到的问题
启动vllm_worker报错:
修改指令,添加参数控制:
这个设置可能会影响到大模型的性能,但是目前我的主要目标是跑通整个流程,所以也就暂时这样了。后面真正落地应用,还需要考虑效果、算力资源、性能等更多因素来给一个综合的设置方案。
Kimi对于该问题的分析:https://kimi.moonshot.cn/share/cour5ui2jko0hi3eb4h0
使用gradio构建聊天窗口
效果:
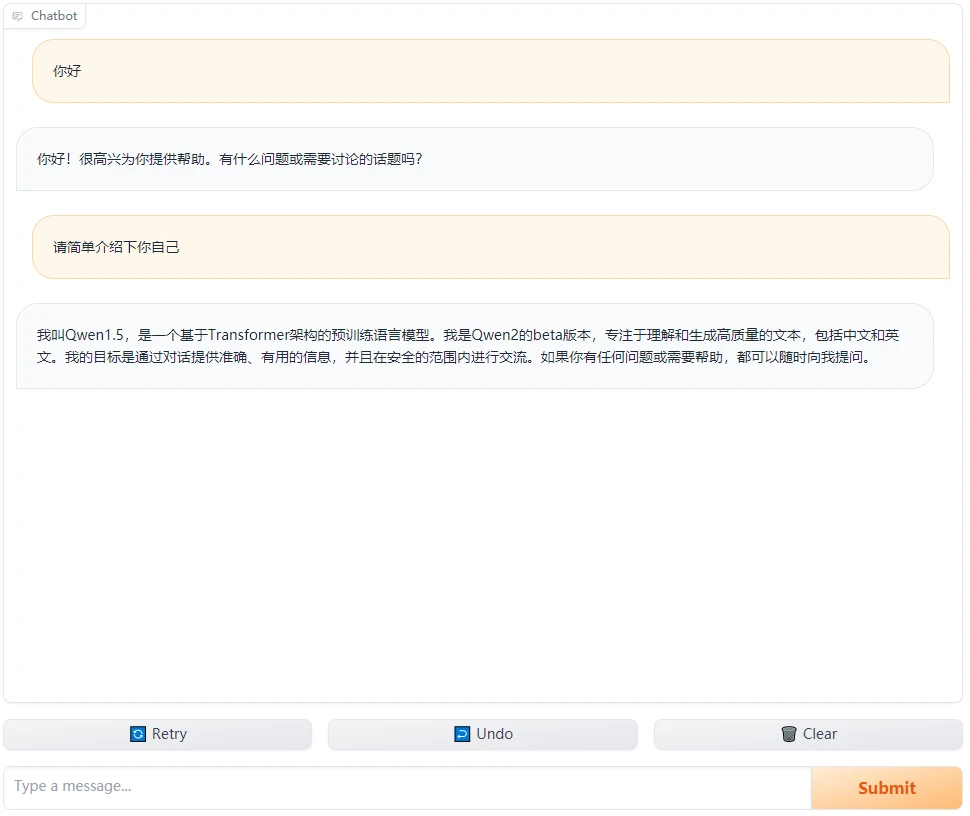
脚本:
过程中遇到的问题
gradio错误信息无法查看
我原本使用脚本启动app,并在后台执行:
但是程序报错,且无法看到错误信息。后来我直接把代码放到Jupyter上运行,就可以看到了。暂时没有继续深究里面的原因。
使用openai的client api时遇到的各种错误
在这个过程中出现的错误主要有三个:
- api_key 没有设置,或者设置的内容是空
- base_url 填写了chat接口的完整地址,如 `http://127.0.0.1:7777/v1/chat/completions`
- 使用了流式的请求,但当前的服务部署模式可能还不支持流式的
使用API调用大模型服务
下面是通过restful api调用大模型服务,但为了复用代码,模仿了gradio的history结构。

结果验证
通过日志确认相关服务已经启动:
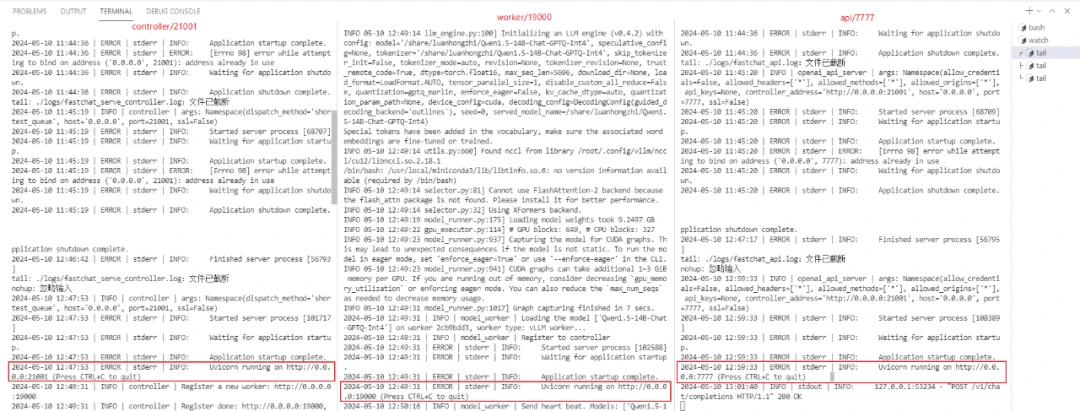
验证API访问大模型服务:
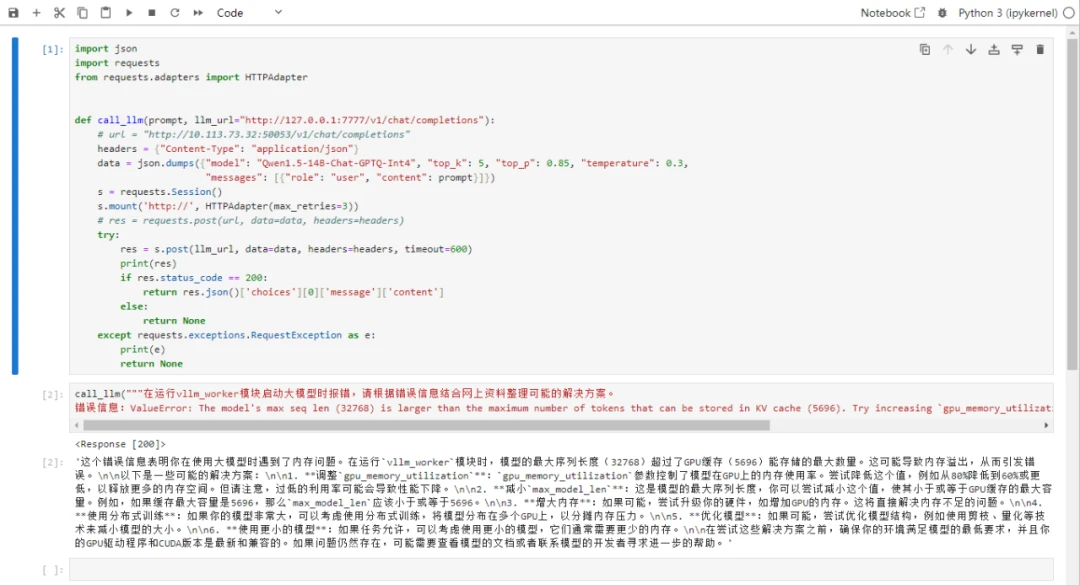
验证可以通过gradio访问:
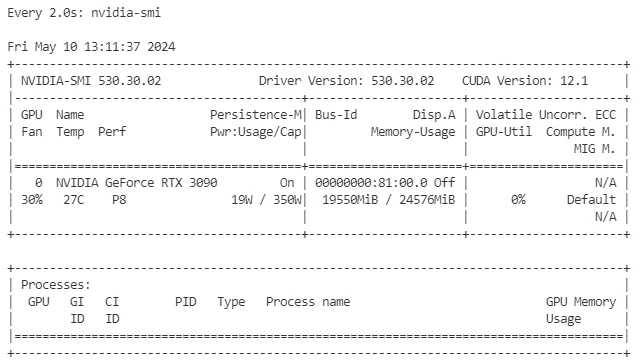
确认GPU资源使用情况:
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
到此这篇模型部署到服务器(模型部署到服务器怎么操作)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/hd-yjs/42360.html