
一、数据准备
1、梳理数据的内在逻辑
关系种类
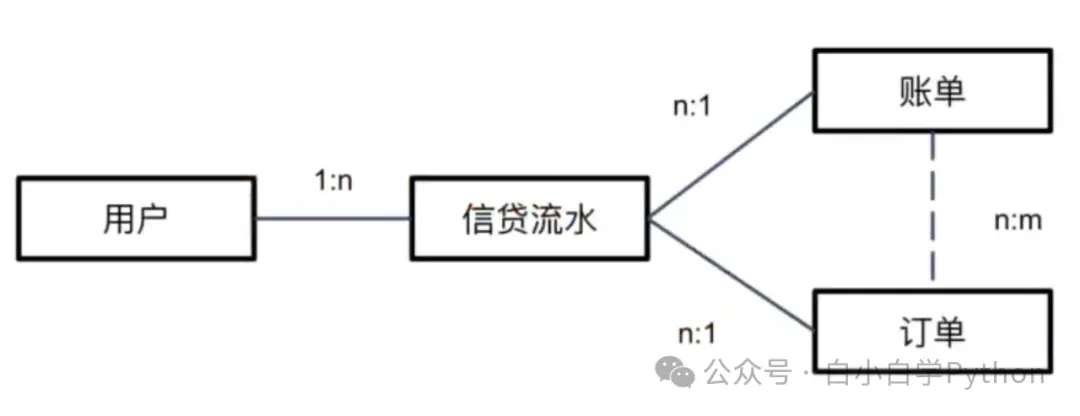
一对一:一个用户有一个注册手机号
一对多:一个用户多笔借款
多对多:一个用户可以登陆多个设备,一个设备可以有多个用户登录
- 举例
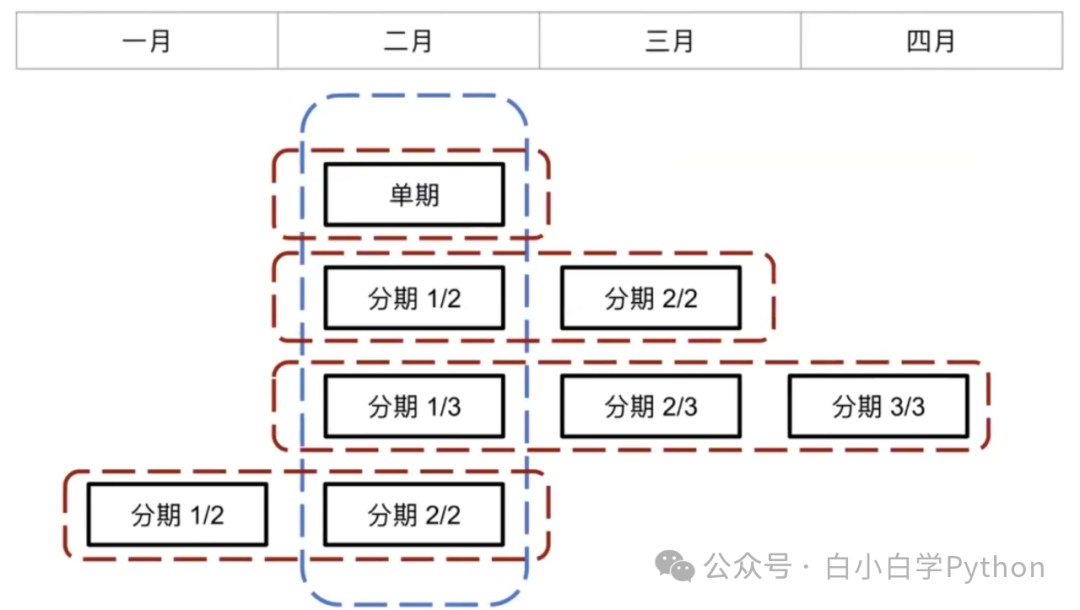
下图,蓝色框为二月当期账单,红色框为订单
梳理类ER图
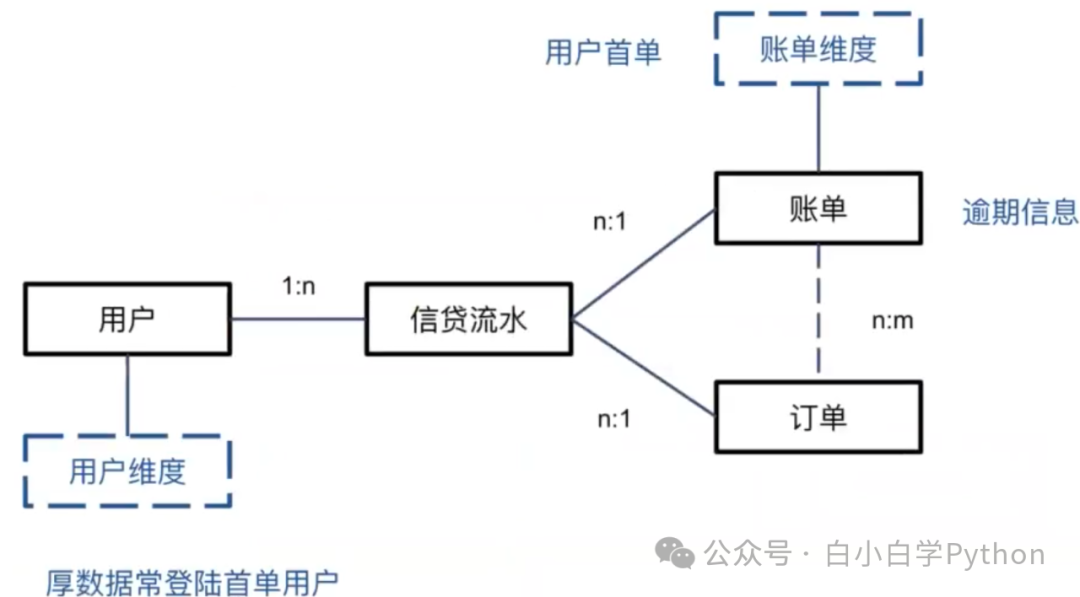
- 任务:分析厚数据常登录首单用户的逾期情况
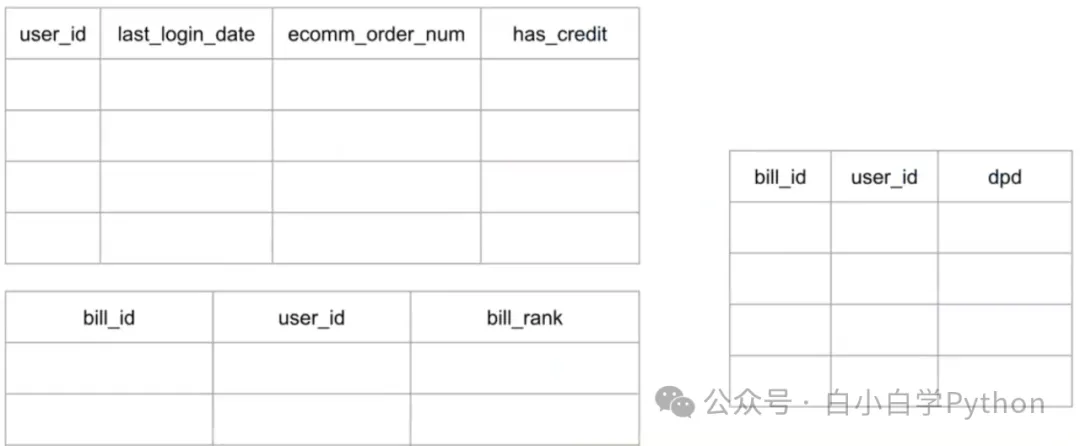
- 可以将表结构展示到特征文档中,说明取数逻辑
2、样本设计和特征框架
- 定义观察期样本
- 确定观察期(定x时间切面)和表现期(定Y的标签)
- 确认样本数目是否合理
- 数据EDA
- 看数据总体分布
- data.shape
- data.isnull()
- data.info()
- data.describe()
- 看好坏样本分布差异
- data[data[label]==0].describe() 好用户
- data[data[label]==1].describe() 坏用户
- 看单个数据
- data.sample(n=10,random_state=1)
- 梳理特征框架
- RFM生成新特征
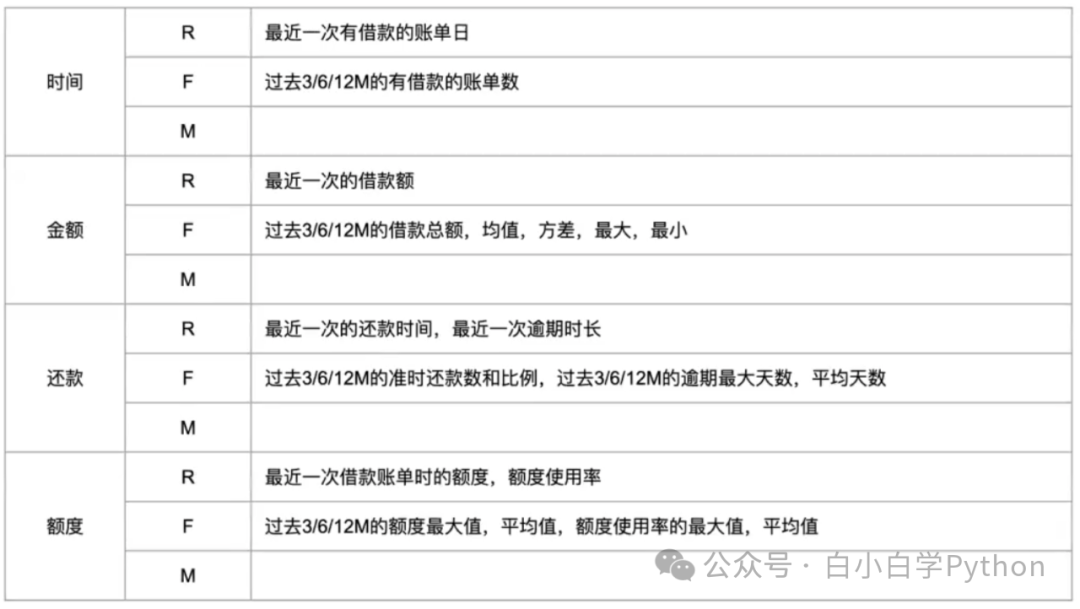
举例 行为评分卡中的用户账单还款特征
- 用户账单关键信息:时间、金额、还款、额度
二、特征构造
1、静态信息特征和时间截面特征
- 用户静态信息特征
- 用户的基本信息(半年内不会变化)
- 用户时间截面特征
- 未来信息当前时间截面之后的数据
- 时间截面数据在取数的时候要小心,避免使用未来信息
- 产生未来信息最直接的原因:缺少快照表
- 金融相关数据原则上都需要快照表记录所有痕迹(额度变化情况,多次申请的通过和拒绝情况…)
- 缺少快照表的可能原因
- 快照表消耗资源比较大,为了性能不做
- 原有数据表设计人员疏忽,没做
- 借用其他业务数据(如电商)做信贷
- 举例
首次借贷 二次借贷 爬虫授权 三次借贷
----------------------------------------------->
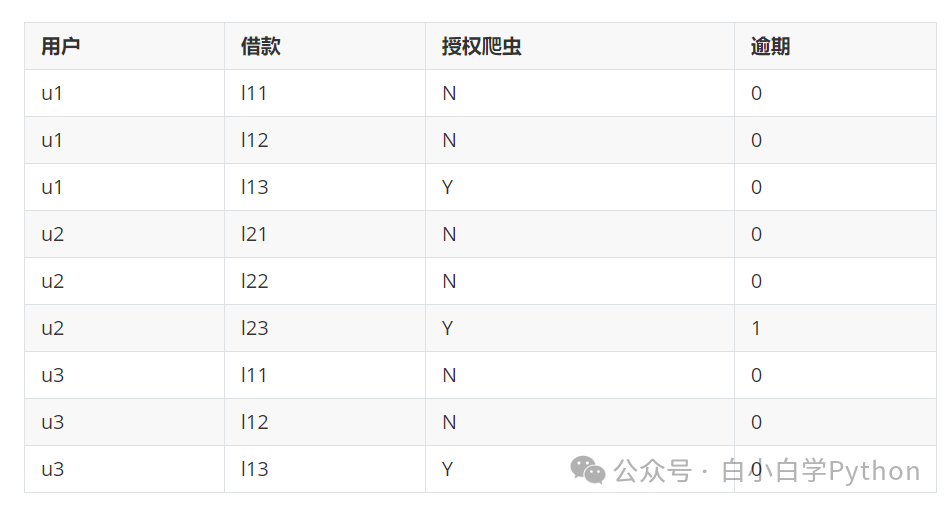
实际存储

join结果
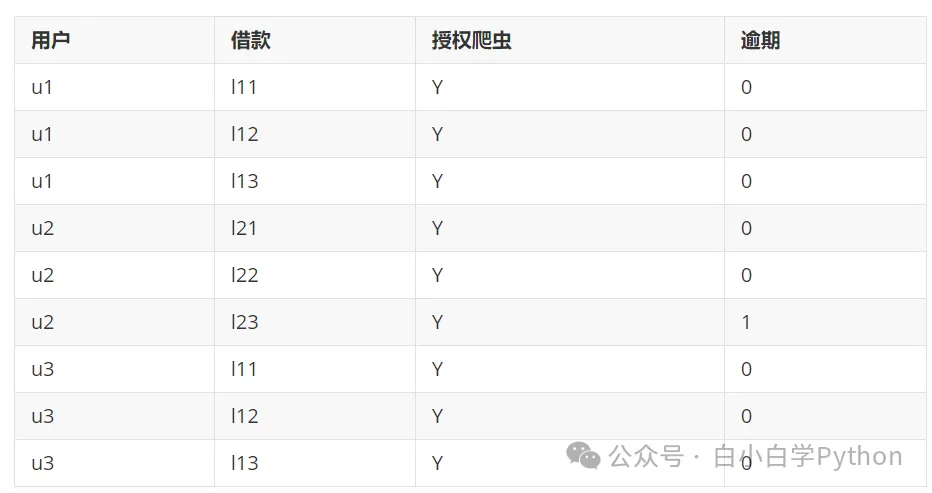
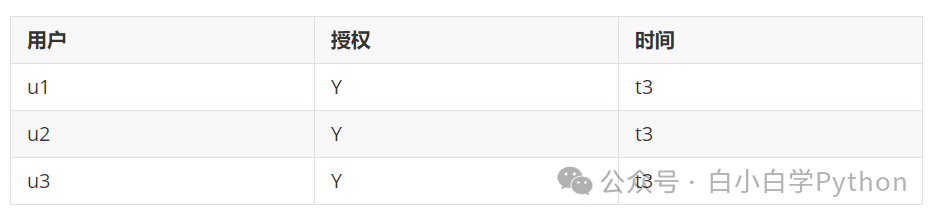
解决方案:加入快照的存储
2、时间序列特征
用户时间序列特征
- 从观察点往前回溯一段时间的数据

时间序列特征衍生
- 上面这种无差别聚合方法进行聚合得到的结果,通常具有较高的共线性,但信息量并无明显增加,影响模型的鲁棒性和稳定性。
- 评分卡模型对模型的稳定性要求远高于其性能
- 在时间窗口为1年的场景下,p值会通过先验知识,人为选择3、6、12等,而不是遍历全部取值1~12
- 在后续特征筛选时,会根据变量的显著性、共线性等指标进行进一步筛选
- 特征组合:又叫特征交叉(feature crossing),指不同特征之间基于常识、经验、数据挖掘技术进行分段组合实现特征构造,产生包含更多信息的新特征。

- 可以通过决策树模型,基于特定指标,贪心地搜索最优的特征组合形式。上一小结最后的案例为例
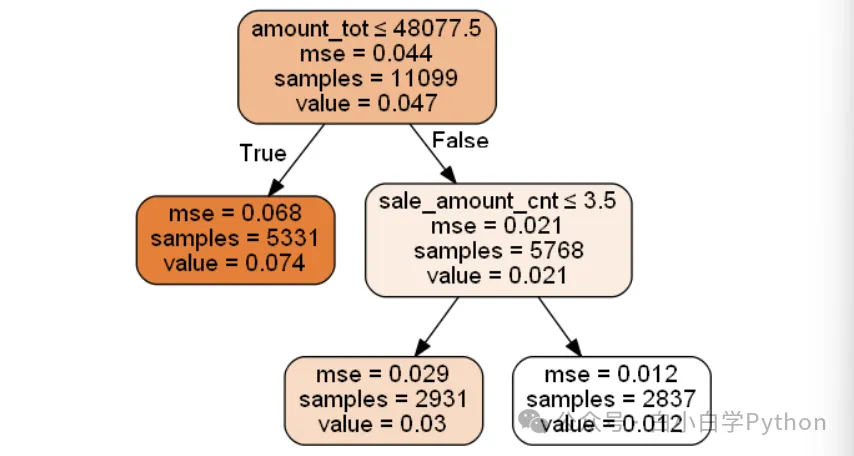
- 基于上述规则可以得出以下特征
- 利用决策树实现特征的自动组合,可以有效降低建模人员的工作难度
- 最近一次(current) 和历史 (history)做对比
- current/history
- current-history

特征变换
- 分箱(离散化)
- 概念
- 特征构造的过程中,对特征做分箱处理时必不可少的过程
- 分箱就是将连续变量离散化,合并成较少的状态
- 分箱的作用
- 离散特征的增加和减少都很容易,易于模型的快速迭代;
- 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
- 分箱(离散化)后的特征对异常数据有很强的鲁棒性
- 单变量分箱(离散化)为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力
- 分箱(离散化)后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
- 分箱(离散化)后,模型会更稳定,如对年龄离散化,20-30为一个区间,不会因为年龄+1就变成一个新的特征。
- 特征离散化以后,可以将缺失作为独立的一类带入模型
- 怎么离散化(分箱)比较好?
- 等频?等距?还是其他
- 分成几箱?10箱?100箱?..
- 分箱时缺失值怎么办
- 常用分箱方法:卡方分箱、决策树分箱、等频分箱、聚类分箱

- 等频分箱

- 按数据的分布,均匀切分,每个箱体里的样本数基本一样
- 在样本少的时候泛化性较差
- 在样本不均衡时可能无法分箱
- 特征分析常用等频分箱
- 等距分箱

- 按数据的特征值的间距均匀切分,每个箱体的数值距离一样
- 一定可以分箱
- 无法保证箱体样本数均匀
- 信用分统计时常用等距分箱
- 卡方分箱:使用卡方检验确定最优分箱阈值
- 将数据按等频或等距分箱后,计算卡方值,将卡方值较小的两个相邻箱体合并
使得不同箱体的好坏样本比例区别放大,容易获得高IV
- 卡方分箱是利用独立性检验来挑选箱划分节点的阈值。卡方分箱的过程可以拆分为初始化和合并两步
- 初始化:根据连续变量值大小进行排序,构建最初的离散化
- 合并:遍历相邻两项合并的卡方值,将卡方值最小的两组合并,不断重复直到满足分箱数目要求

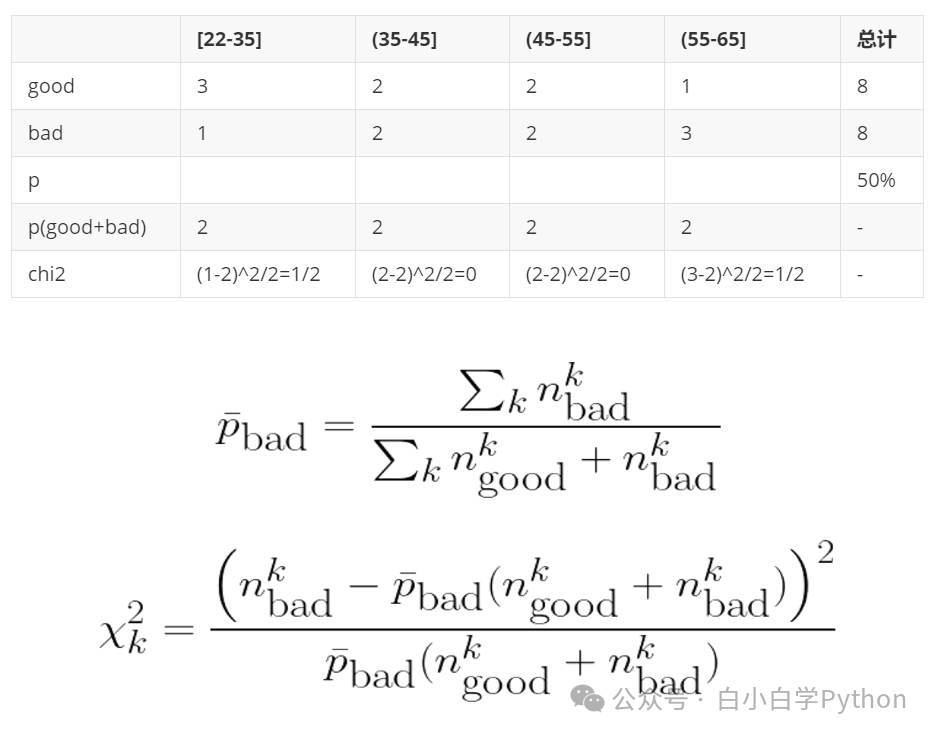
合并坏人比例接近平均水平的箱体,留下比例差异大的箱体
- 案例:使用toad库进行分箱处理,数据集使用germancredit
- Toad 是专为工业界模型开发设计的Python工具包,特别针对评分卡的开发
- Toad 的功能覆盖了建模全流程,从 EDA、特征工程、特征筛选 到 模型验证和评分卡转化
- Toad 的主要功能极大简化了建模中最重要最费时的流程,即特征筛选和分箱。
- 数据字段说明
- Status of existing checking account(现有支票帐户的存款状态)
- Duration in month(持续月数)
- Credit history(信用历史记录)
- Purpose(申请目的)
- Credit amount(信用保证金额)
- Savings account/bonds(储蓄账户/债券金额)
- Present employment since(当前就业年限)
- Installment rate in percentage of disposable income(可支配收入占比)
- Personal status and gender(个人婚姻状态及性别)
- Other debtors / guarantors(其他债务人或担保人)
- Present residence since(当前居民年限)
- Property(财产)
- Age in years(年龄)
- Other installment plans (其他分期付款计划)
- Housing(房屋状况)
- Number of existing credits at this bank(在该银行已有的信用卡数)
- Job(工作性质)
- Number of people being liable to provide maintenance for(可提供维护人数)
- Telephone(是否留存电话)
- foreign worker(是否外国工人)
- creditability 数据标签
- toad 中的combiner类用来进行分箱处理
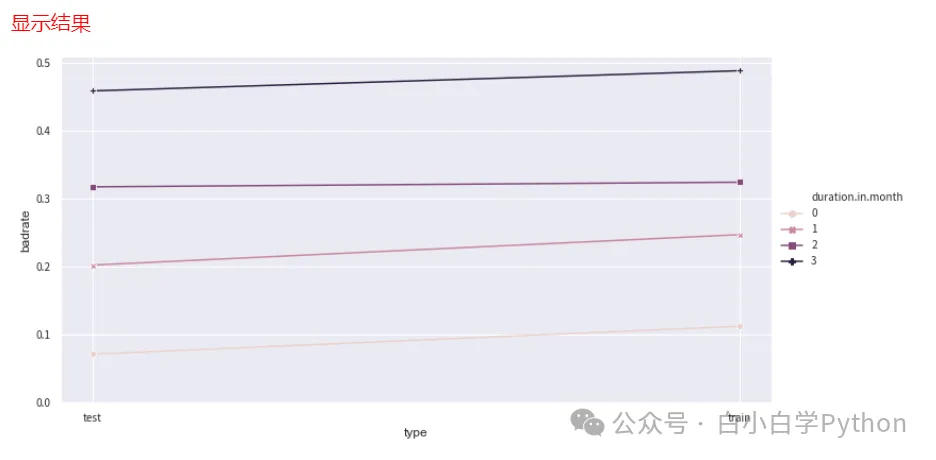
- 通常使用双变量图(Bivar图 Bivariate graph)来评价分箱结果。注意,信贷风险分析中Bivar图,纵轴固定为负样本占比
- 使用bin_plot()画图对分箱进行调整
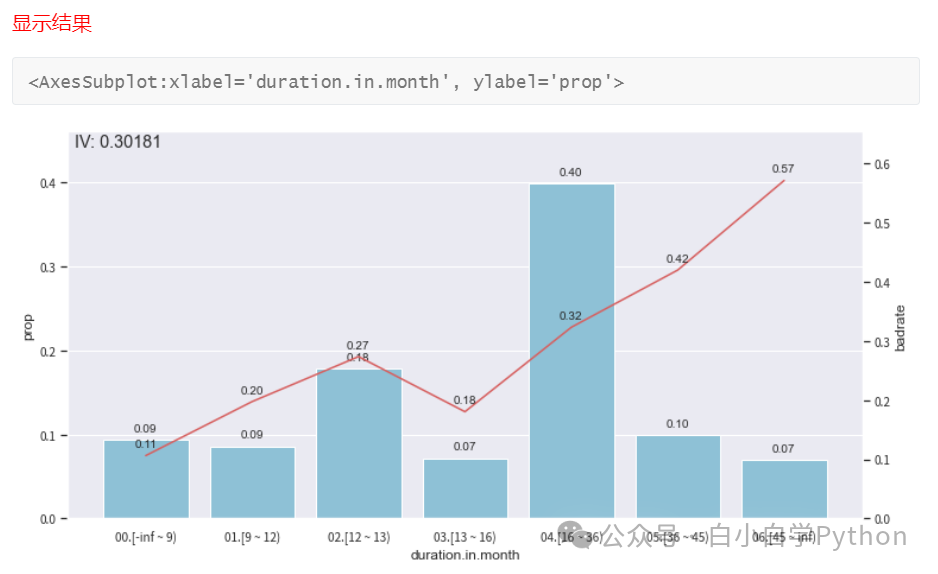
- 上图中柱形图表示每一箱的占比,折线图表示每一箱的坏样本率。一般折线图要呈现出单调的趋势
- 可以通过调整箱数实现单调趋势
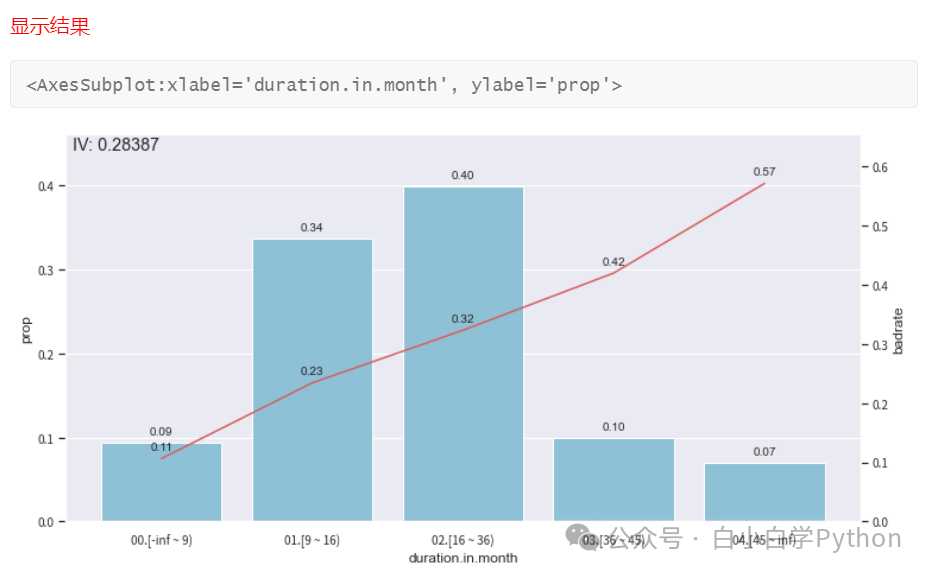
- 其它分箱方法:聚类分箱(k-means), 决策树分箱,等频分箱,等距分箱
- 各种分箱方法对比
- 从单调性和模型稳定性角度考虑一般使用卡方分箱
- 多值无序类别特征需要做encoding处理,常见encoding方法:Onehot Encoding、Label Encoding、WOE Encoding
- Onehot Encoding
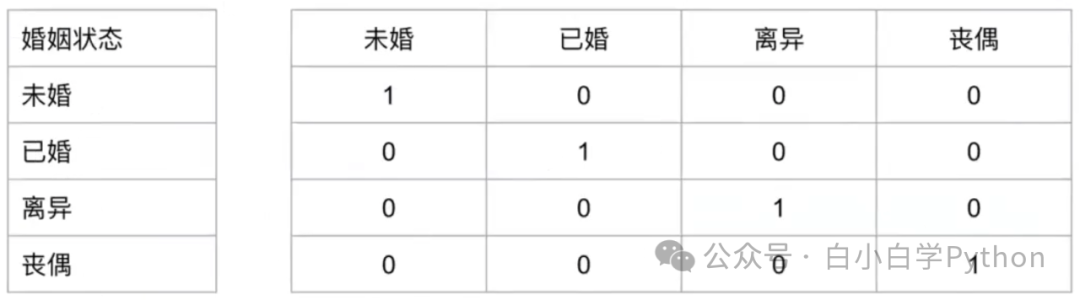
- Label Encoding
婚姻状态 婚姻状态 统计出不同婚姻状态下的逾期率作为数值标签
未婚 dpd rate
已婚 dpd rate
离异 dpd rate
丧偶 dpd rate
缺点:数据量少的情况下,某些数据可能有偏差
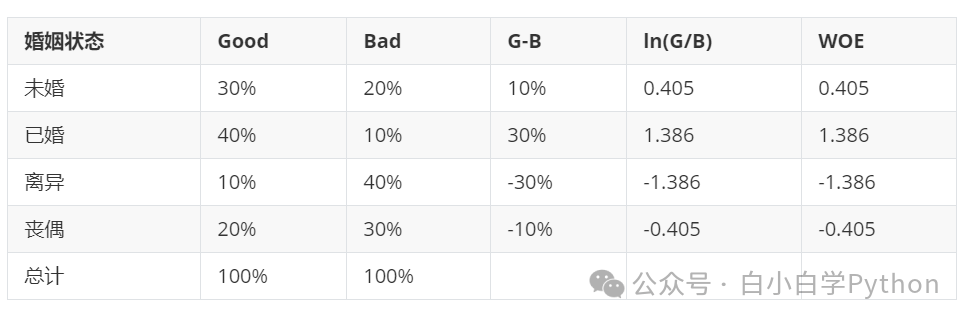
- WOE Encoding
WOE(Weight of Evidence) 反映单特征在好坏用户区分度的度量
W O E _ k = l o g ( p g o o d k / p b a d k ) WOE_k=log(pk_{good}/pk_{bad}) WOE_k=log(pgoodk/pbadk) 好用户比例/坏用户比例
- 使用toad计算woe
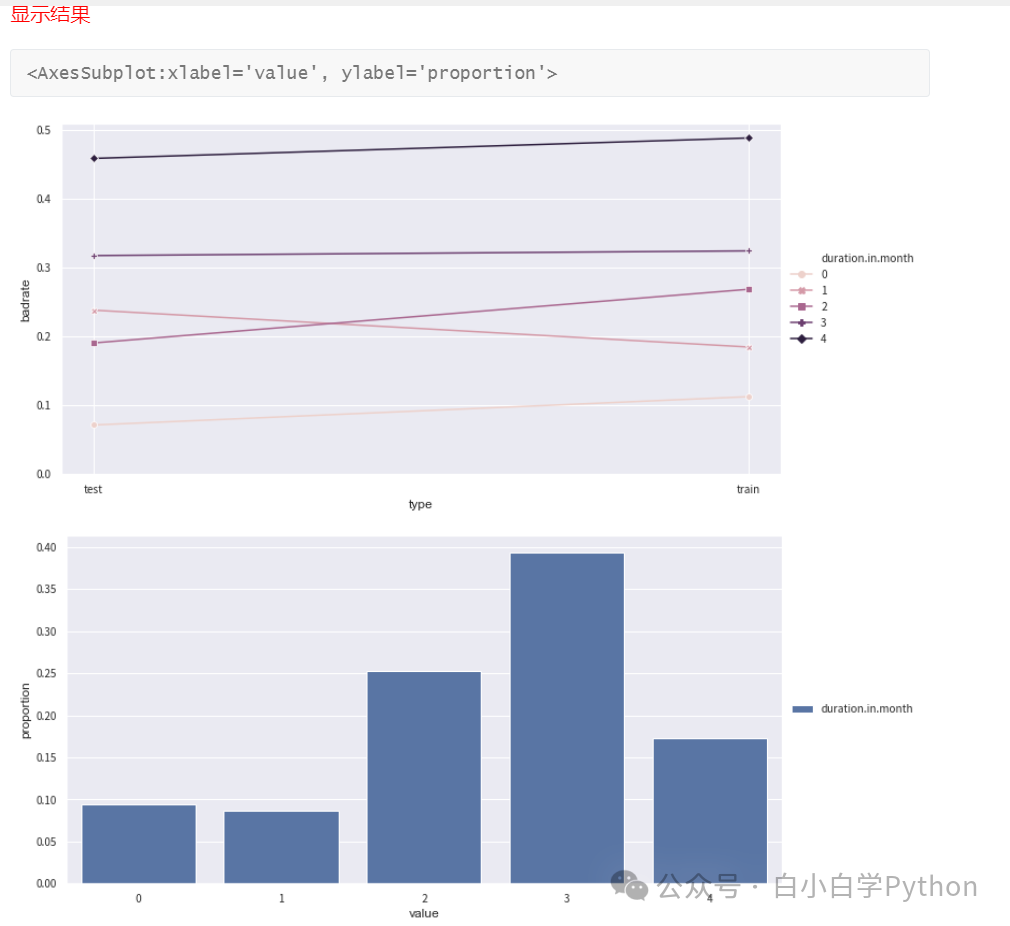
- 上面第一张图中的第一箱和第二箱的bad_rate存在倒挂,说明bad_rate不单调,需要调整。可以将第一箱和第二箱进行合并
- WOE理解:当前组中好用户和坏用户的比值与所有样本中这个比值的差异。差异通过对这两个比值取对数来表示
- WOE越大,差异越大,这个分组里的好用户的可能性就越大
- WOE越小,差异越小,这个分组里的好用户的可能性也就越小。
- 分箱结果对WOE结果有直接影响,分箱不同,WOE映射值也会有很大的不同
- 箱的总数在5~10箱(可以适当调整,通常不超过10箱)
- 并且将每一箱之间的负样本占比差值尽可能大作为箱合并的基本原则
- 每一箱的样本量不能小于整体样本的5%,原则是每一箱的频数需要具有统计意义
- 三种encoding的利弊

- 多值有序类别型特征
- 学历:高中以下,大专,本科,硕士,博士
- 一定程度上学历高低能直接对应用户的信用风险,可以当做有序特征
- 可以把多值有序特征转换为1,2,3…的数值
- 高中以下 → 1, 大专 → 2 ,本科 → 3,硕士→4,博士→5
用户时间序列缺失值处理
- 用户时间序列缺失值处理
- 优先考虑补零:大多数特征都是计数,缺失用0补充
- 用户没有历史购物记录: max_gmv min_gmv 都可以用0补充
- 用0填充缺失值带来的问题
- cur/history_avg: 0/0 cur/history_avg:1/0
- 根据风险趋势填补缺失值 (违约概率大小 无历史购物记录违约概率>有一单历史购物记录>有两单)
用户没有历史购物记录 cur/history_avg : 0/0? 可以填充-2
用户有一单历史购物记录 cur/history_avg : 1/0? 可以填充-1 用户有两单历史购物记录 cur/history_avg : 1/1 可以计算出>0的值
- 用户最后一次逾期距今天数,如果是白户如何填补缺失值?
- 如果缺失值比较多的时候,考虑单独做成特征
- 举例:用户授权GPS序列特征 gps_count_last_3month
- 缺失意味着用户未授权GPS权限
- 缺失有明显业务含义,可以填补业务默认值
- 授信额度(用初始额度)
- 缺失值处理小结
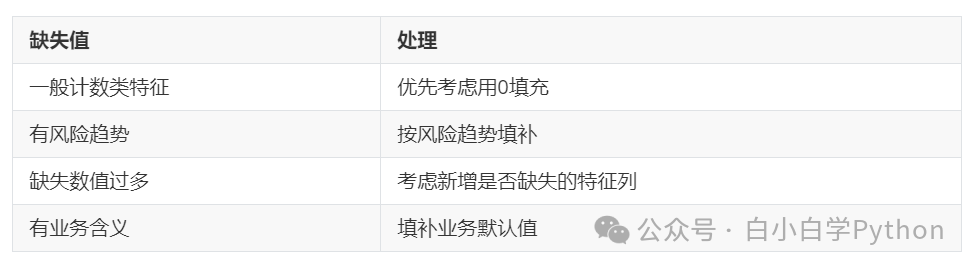
时间序列数据的未来信息

- 以借贷2发生的时间为观测点,下表中的未来信息会把大量退货行为的用户认为是坏客户,但上线后效果会变差

- 特征构建时的补救方法
- 对未来信息窗口外的订单计算有效单的特征net order,nmv
- 对未来信息窗口内订单只计算一般特征order,GMV
- 历史信贷特征也非常容易出现未来信息
- 举例
信用卡 每月1日为账单日,每月10日为还款日,次月10日左右为M1
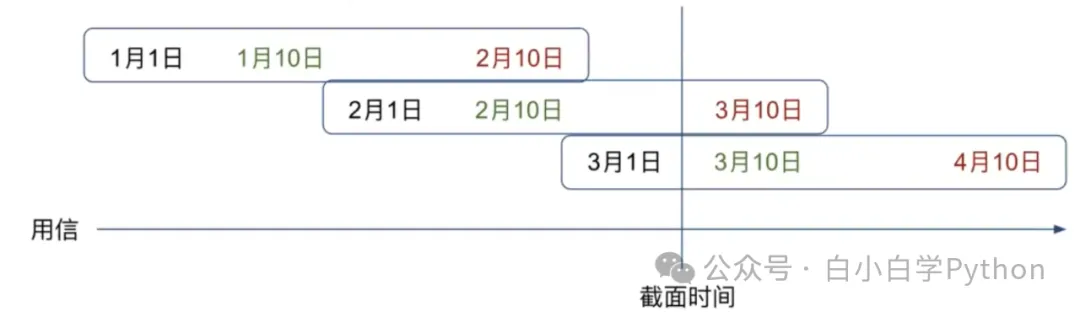
- 在上图所示的截面时间(如3月5日)是看不到2月账单的逾期DPD30的情况的
- 但如果数据库没有快照表会导致我们可以拿到2月账单的DPD30情况
- 解决方案跟上面例子一样,分区间讨论,可以把账单分成3类
- 当前未出账账单
- 最后一个已出账账单
- 其他已出账账单 (只有这个特征可以构建逾期类特征)
- 未来信息处理小结
- 及时增加快照表
- 没有快照表的情况下,将数据区分为是否有未来信息的区间,分别进行特征构造
3、用户关联特征
- 如何评价一个没有内部数据的新客?
- 使用外部第三方数据
- 把新用户关联到内部用户,使用关联到的老客信息评估
- 用户特征关联,可以考虑用倒排表做关联
- 用户→[特征1,特征2,特征3…]
- 特征→[用户1,用户2,用户3…]
- 举例:用户所在地区的统计特征
- geohash:基本原理是将地球理解为一个二维平面,将平面递归分解成更小的子块,每个子块在一定经纬度范围内拥有相同的编码
- 将用户申请时的GPS转化为geohash位置块
- 对每个大小合适的位置块,统计申请时点GPS在该位置块的人的信用分
- 当新申请的人,查询其所在的位置块的平均信用分作为GPS倒排表特征
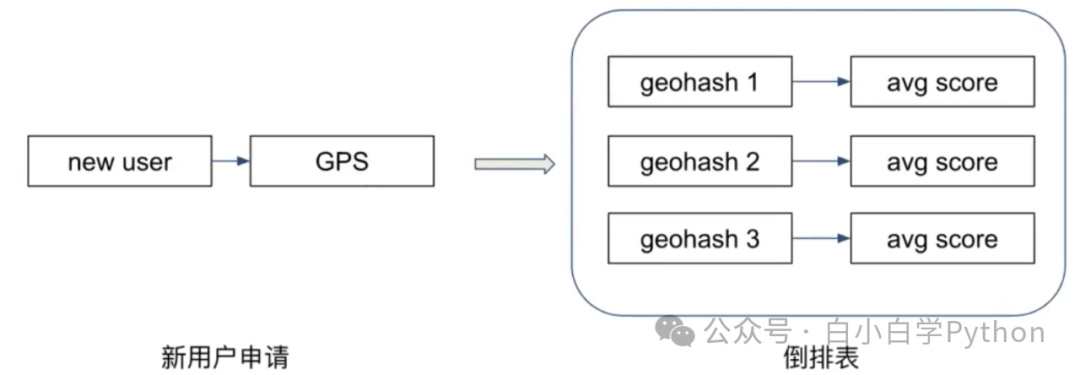
- 倒排表的组成:关键主键+统计指标
- 关键主键:新用户通过什么数据和平台存量用户发生关联
- 统计指标:使用存量用户的什么特征去评估这个新客户
- 常见统计指标
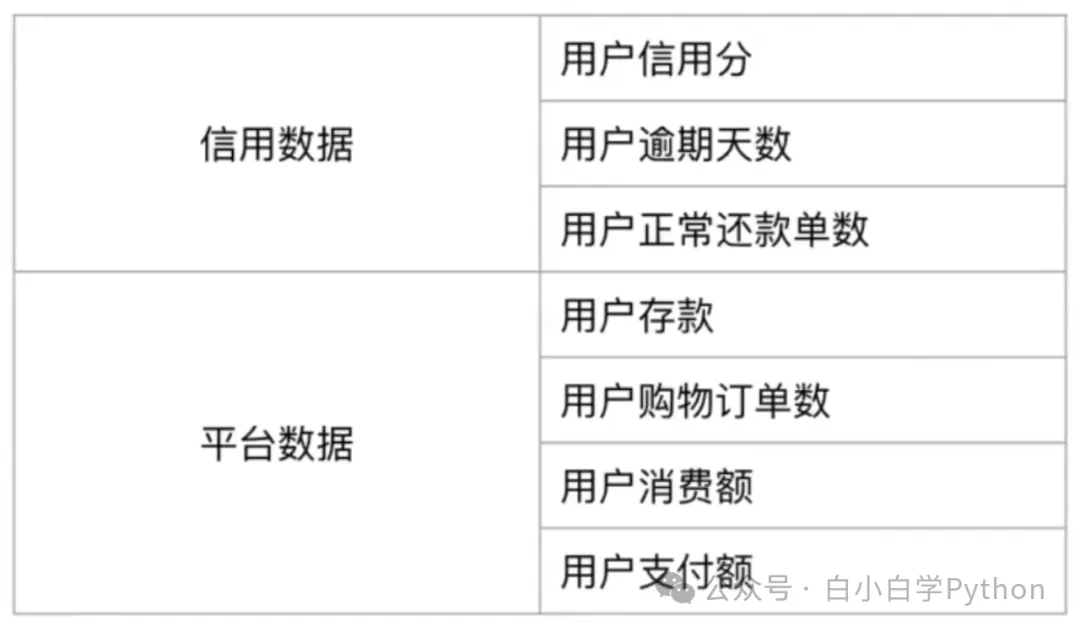
- 常见关联主键
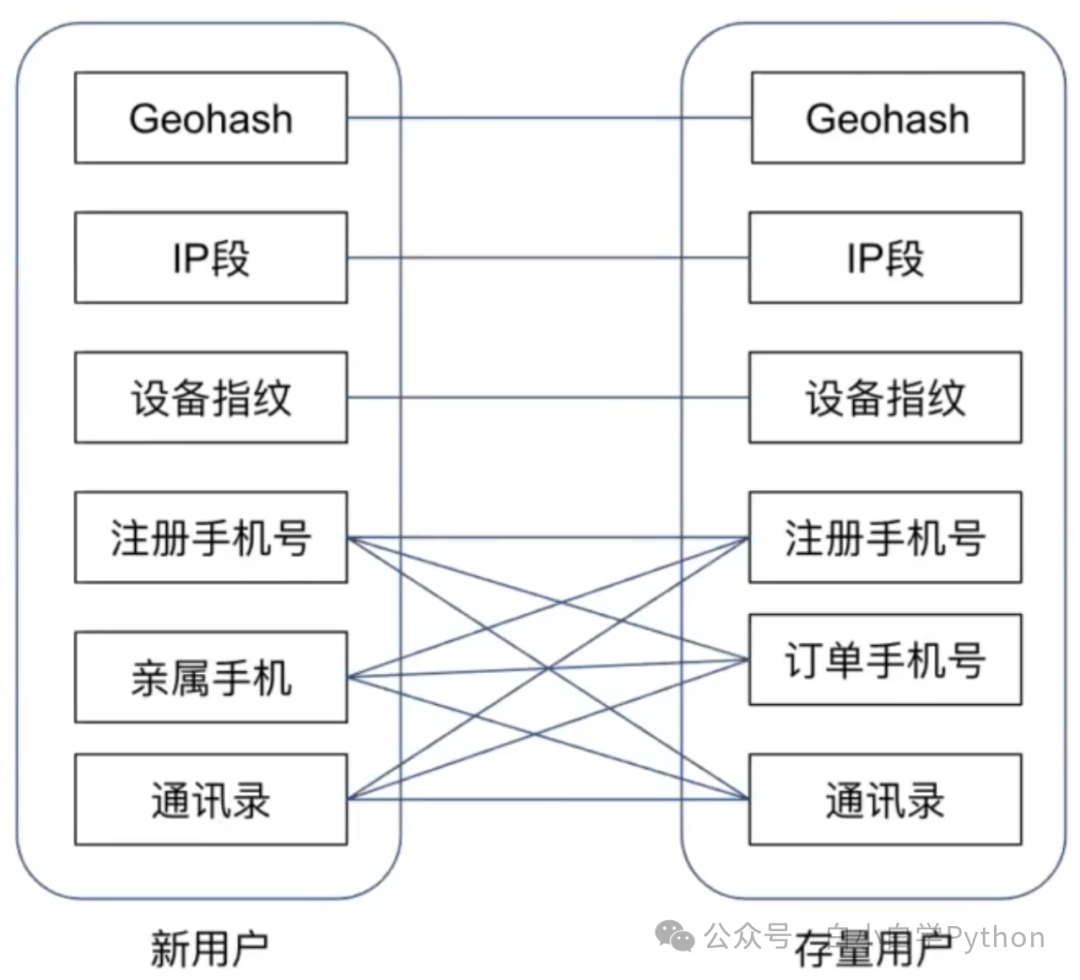
- 信贷业务的特征要求:
- 逻辑简单
- 容易构造
- 容易排查错误
- 有强业务解释性
- 构造特征要从两个维度看数据:归纳+演绎
- 归纳:从大量数据的结果总结出规律(相关关系)
- 演绎:从假设推导出必然的结果(因果关系)
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/kjbd-gc/29320.html