
数据透视表将每一列数据作为输入,输出将数据不断细分成多个维度累计信息的二维数据表。在实际数据处理过程中,数据透视表使用频率相对较高,今天云朵君就和大家一起学习pandas数据透视表与逆透视的使用方法。
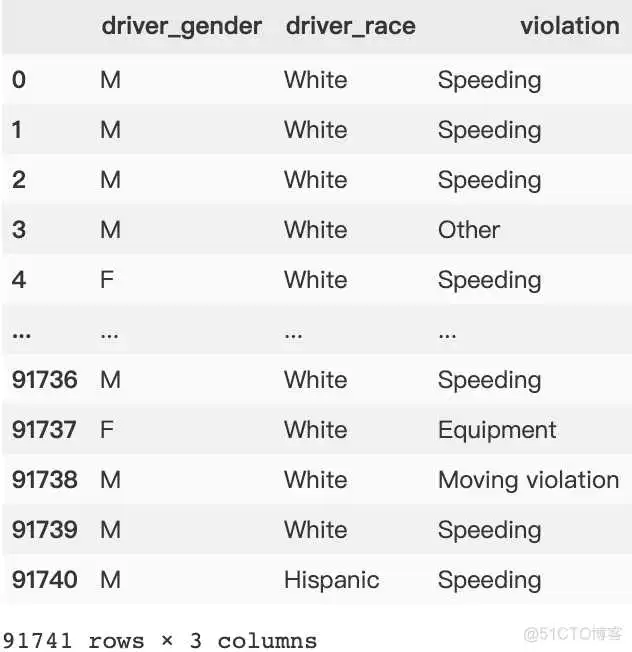
本次使用的数据来源于Kaggle,车辆被警察拦下并进行搜查记录数据集,简称车辆数据。
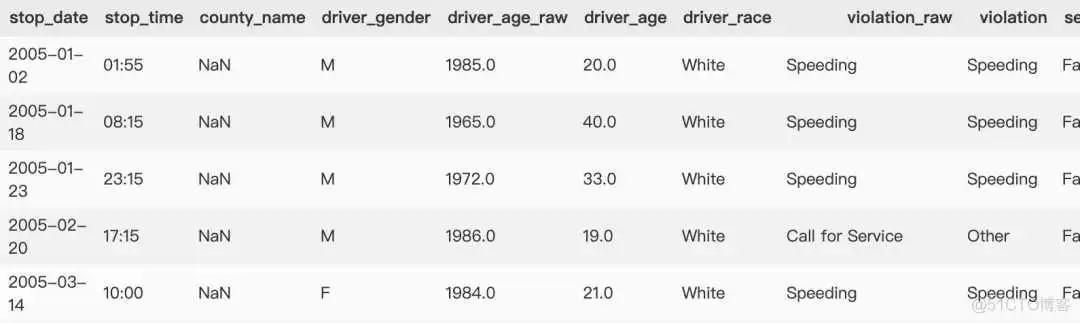
数据基本情况
groupby数据透视表
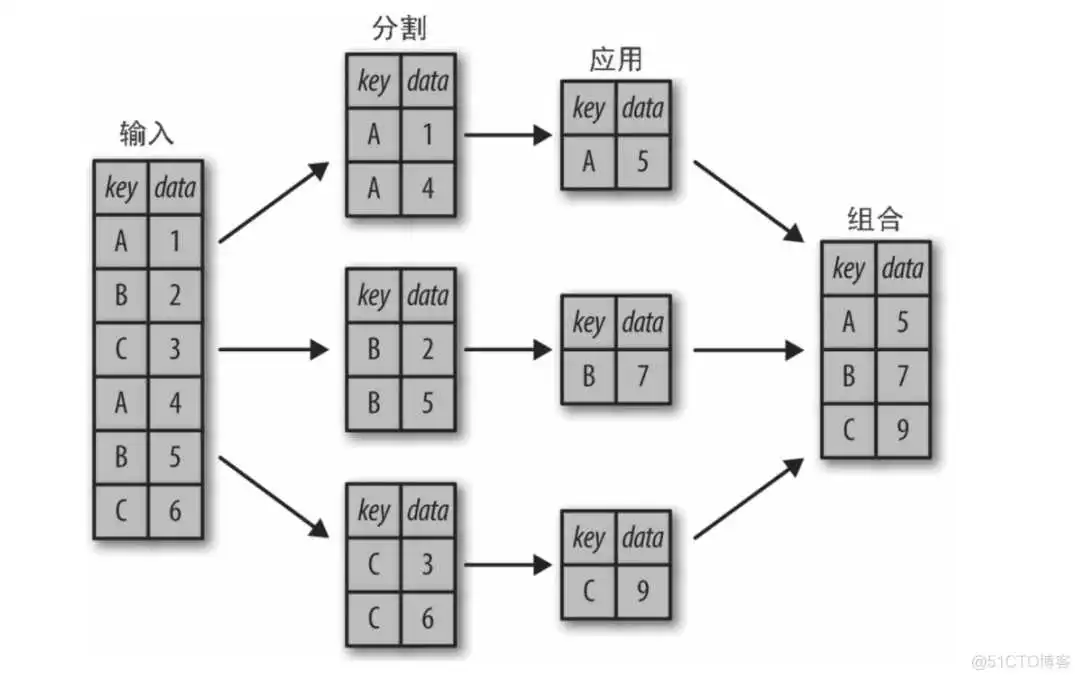
使用 pandas.DataFrame.groupby 函数,其原理如下图所示。
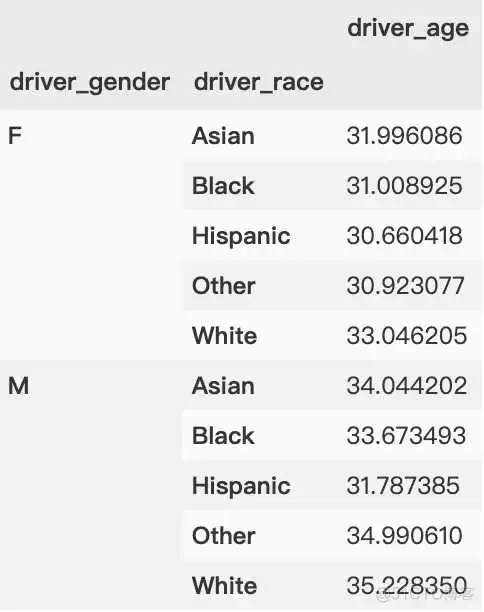
使用车辆数据集统计不同性别司机的平均年龄,聚合后用二维切片可以输出DataFrame数据框。

在聚合后一维切片会得到 pandas.Series.
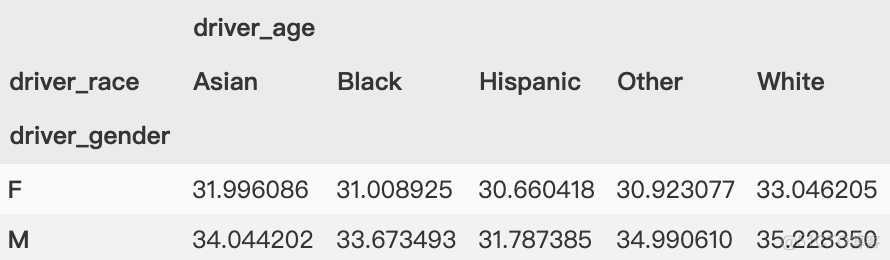
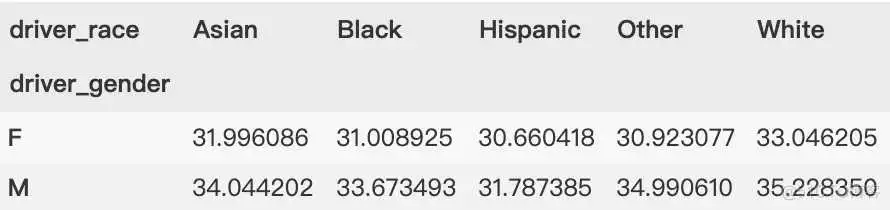
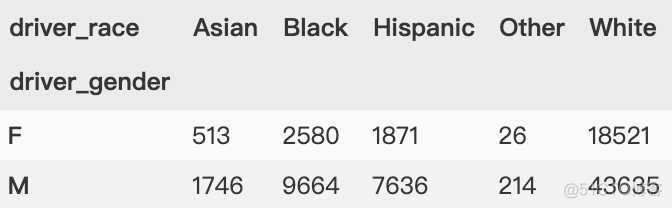
可能还想进一步探索,同时观察不同司机性别与司机种族的平均年龄。根据 GroupBy 的操作流程,我们也许能够实现想要的结果:将司机种族('driver_race')与司机性别('driver_gender')分组,然后选择司机年龄('driver_age')列,应用均值('mean')累计函数,再将各组结果组合,最后通过行索引转列索引操作将最里层的行索引转换成列索引,形成二维数组。
通过unstack重排数据表
如果原表只有一级索引,unstack就将每一个列都分出来,然后全部纵向叠加在一起,每一个列名作为新的一级索引,原本的索引作为二级索引。如果原表有二级索引,那么unstack就会将二级索引作为新的列名,一级索引作为新的索引。
pivot_table
虽然这样就可以更清晰地观察出不同司机性别与司机种族的平均年龄,但代码有点复杂。要理解这个长长的语句可不是那么容易的事。
由于二维的 GroupBy 应用场景非常普遍,因此 Pandas 提供了一个快捷方式 pivot_table 来快速解决多维的累计分析任务。
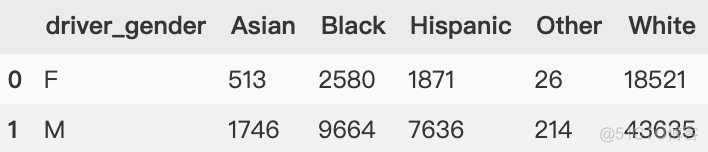
同样是上面的需求,同时观察不同司机性别与司机种族的平均年龄 ,用pivot_table实现透视表。
多级数据透视表
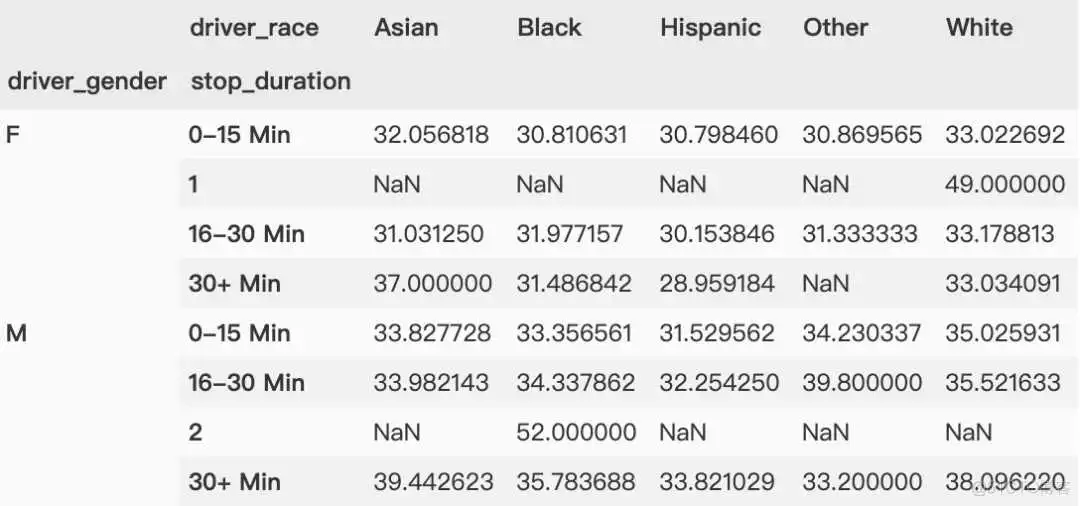
与 GroupBy 类似,数据透视表中的分组也可以通过各种参数指定多个等级。
行索引和列索引都可以再设置为多层,不过行索引和列索引在本质上是一样的,大家需要根据实际情况合理布局。
自定义聚合函数
aggfunc 参数用于设置累计函数类型,默认值是均值(mean)。累计函数可以用一些常见的字符串 ('sum'、'mean'、'count'、'min'、'max' 等)表示,也可以用标准的累计函数(np.sum()、min()、sum() 等)。
还可以通过字典为不同的列指定不同的累计函数。
- 如果传入参数为list,则每个聚合函数对每个列都进行一次聚合。
- 如果传入参数为dict,则每个列仅对其指定的函数进行聚合, 此时values参数可以不传。

这里没有使用参数 values。其实在我们通过字典为 aggfunc 指定映射关系的时候,待透视的数值就已经确定了。
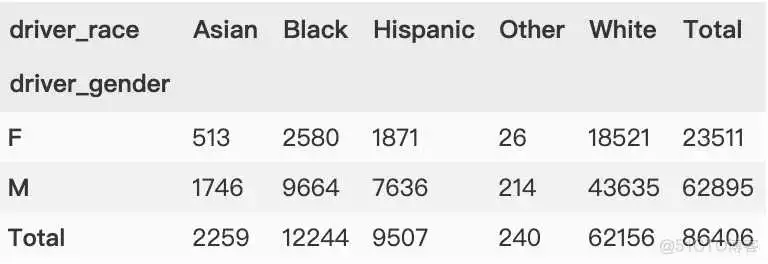
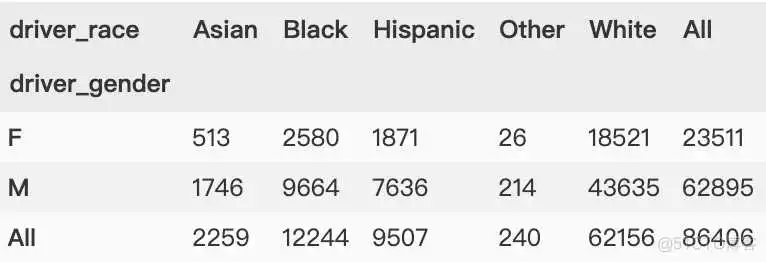
margin 的标签可以通过 margins_name 参数进行自定义, 默认值是 "All"。
下面按行、按列进行汇总,指定汇总列名为“Total”
pandas.crosstab
crosstab 是交叉表,是一种特殊的数据透视表默认是计算分组频率的特殊透视表(默认的聚合函数是统计行列组合出现的次数)。如果指定了聚合函数则按聚合函数来统计,但是要指定values的值,指明需要聚合的数据。
pandas.crosstab 参数
index:指定了要分组的列,最终作为行。
columns:指定了要分组的列,最终作为列。
values:指定了要聚合的值(由行列共同影响),需要指定aggfunc参数。
rownames:指定了行名称。
colnames:指定了列名称。
aggfunc:指定聚合函数。必须指定values的值。
margins:布尔值,是否分类统计。默认False。
margins_name:分类统计的名称,默认是"All"。
dropna:是否包含全部是NaN的列。默认是True。
如果说 将长数据集转换成宽数据集, 则是将宽数据集变成长数据集 既是顶级类函数也是实例对象函数,作为类函数出现时,需要指明 的名称
pd.melt 参数
frame 被 melt 的数据集名称在 pd.melt() 中使用
id_vars 不需要被转换的列名,在转换后作为标识符列(不是索引列)
value_vars 需要被转换的现有列,如果未指明,除 id_vars 之外的其他列都被转换
var_name 自定义列名名称,设置由 'value_vars' 组成的新的 column name
value_name 自定义列名名称,设置由 'value_vars' 的数据组成的新的 column name
col_level 如果列是MultiIndex,则使用此级别
为方便下面转换的理解,经过去除columns的name后得到:
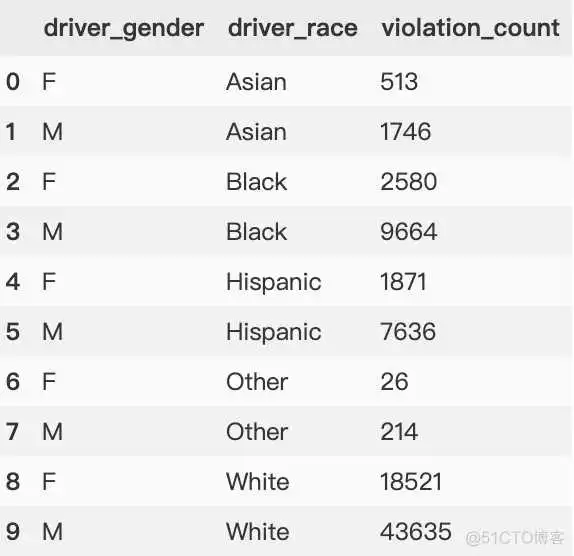
下面开始进行转换。保留"driver_gender",对剩下列全部转换,并给设置对列定义列名。
上述同样的结果用groupby也可以做到,如下所示。
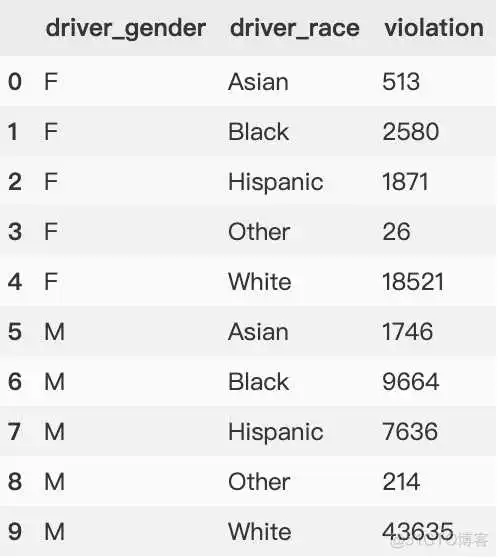
这里补充说明下去除columns的name及index的name的方法。
如下图所示"driver_race" 和 "driver_gender" 分别是columns的name,index的name。
下面演示一个平时较为头疼的事情。即将两个name删掉。下面介绍一个常见的方法。
使用pandas.DataFrame.rename_axis去除columns列的名称
另外一种情况如下图所示,在column上还有一个"driver_age",此时需要在第一步使用pandas.DataFrame.droplevel把"driver_age"删除:df.columns = df.columns.droplevel(0)
然后在执行上面两步。
到此这篇python pivot函数(python pivot table aggfunc)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/pythonbc/11583.html