

opentelemetry 【IT老齐432】可观测性,优雅零侵入,Spring Boot接入OpenTelemetry_哔哩哔哩_bilibili
算力平台log采集方案:
iLogtail 回顾视频:开源两周年,感恩遇见,畅想未来_哔哩哔哩_bilibili
借鉴hdfs的逻辑写一套minio追加写的客户端,主要是控制 间隔时间、行数、以及主动提交
8.flume实时监控文件hdfs sink使用演示_哔哩哔哩_bilibili
DT-A的级联分发是不用走落盘的,直接走网络传输
DTN DT-A数据采集,解决flume的级联方式,并且flume支持事务,保证数据的一致性,可扩展用于以后的数据对账使用
https://www.cnblogs.com/typ1805/p/10405313.html
https://www.cnblogs.com/xuziyu/p/11004103.html
https://download.csdn.net/blog/column//
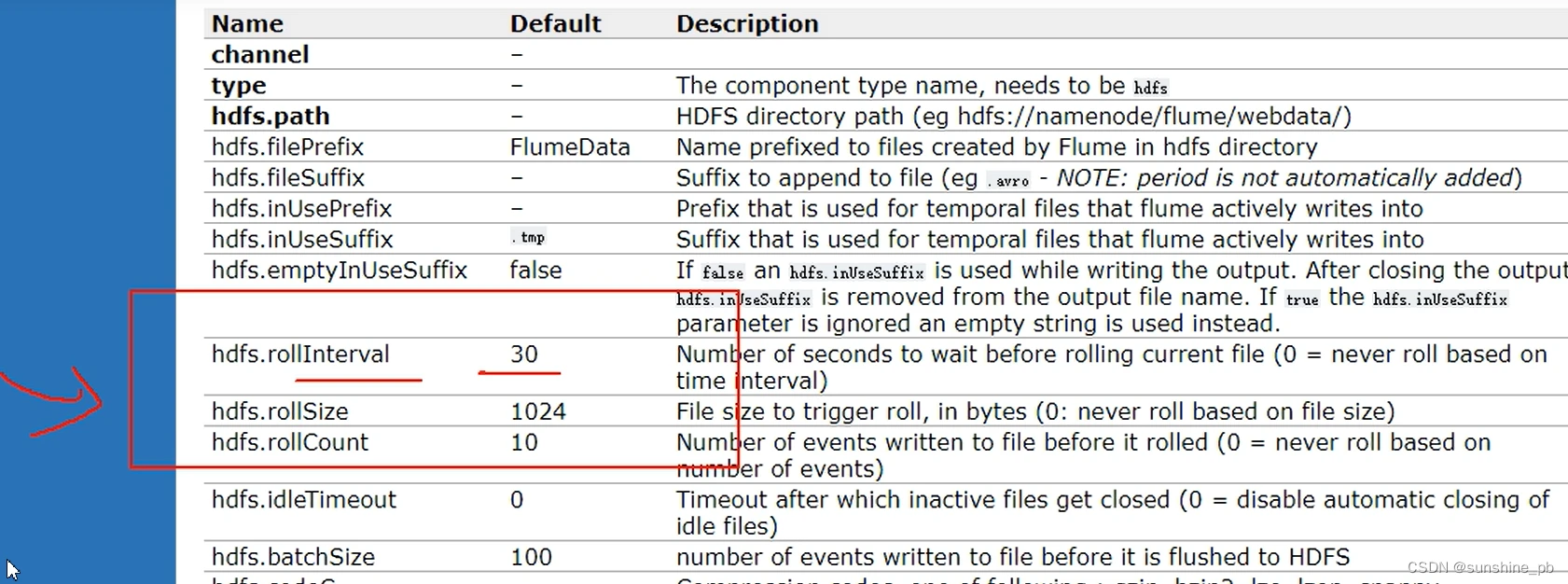
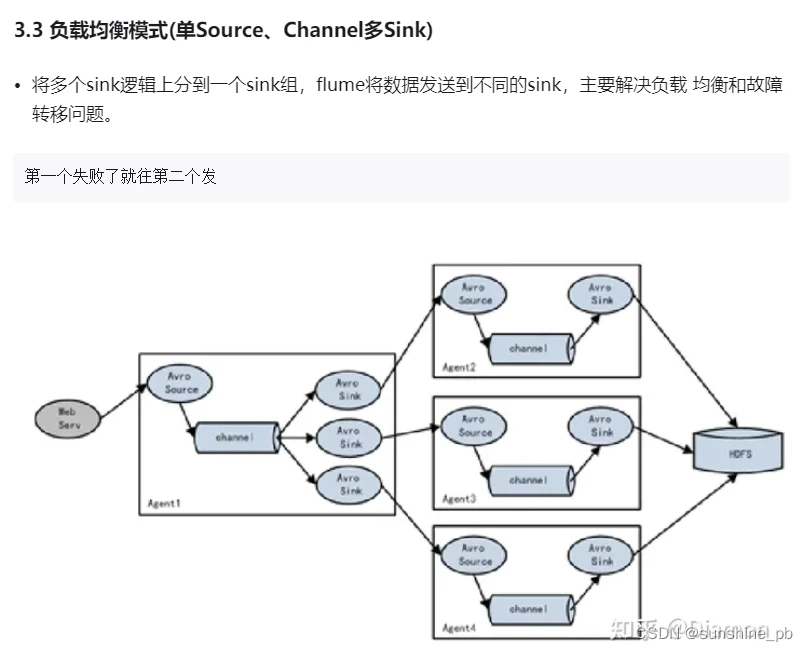
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。
比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,
也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes,这也正是Flume强大之处。如下图所示:
数据清洗:
pandas、tablesaw
去重:
探索数据清洗新境界:csvdedupe - 精准去重利器-CSDN博客
GitHub - dedupeio/dedupe: :id: A python library for accurate and scalable fuzzy matching, record deduplication and entity-resolution.
https://github.com/dedupeio/dedupe?tab=readme-ov-file
Dedupe 2.0.17 — dedupe 2.0.17 documentation
csvdedupe、csvlink、csvkit
对于比较100GB无序CSV数据这类大规模数据比较任务,直接在内存中操作可能不太现实,因此需要采取更高效和可扩展的方法。以下是一些建议:
注意事项
- 在处理前,确保有足够的磁盘空间用于临时文件和输出。
- 考虑数据的唯一标识符或键,这将直接影响比较的效率和准确性。
- 性能优化也很关键,比如使用高效的编码格式(如gzip压缩)来减少I/O开销,合理分配计算资源等。
综上所述,根据你的资源和技术栈选择最合适的方法,处理100GB无序CSV数据比较任务。
【JVM 监控工具】性能诊断--JProfiler的使用_逆流°只是风景-bjhxcc的博客-CSDN博客
Pointofix,软件官网:https://www.pointofix.de/download.php

lsieun | Every search begins with beginner’s luck. And every search ends with the victor’s being severely tested. – The Alchemist
java agent: GitHub - YorkHwang/exec-timer: 基于java agent实现无侵入方法执行时长打印
到此这篇报文解析工具V2.3(报文解析工具J)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/qdvuejs/47387.html