
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序来实现的,单链表是指每个节点只有一个指针域的链表(本篇文章文章讨论的单链表是无头结点不循环单向链表),这里就引出了结点的概念。
与顺序表不同的是,链表中的每个元素的空间都是独立申请下来的,我们称之为结点。结点结点有两个部分组成:数据域和指针域,数据域中存储的是该结点要保存的数据,指针域中保存的是下一个结点的地址。
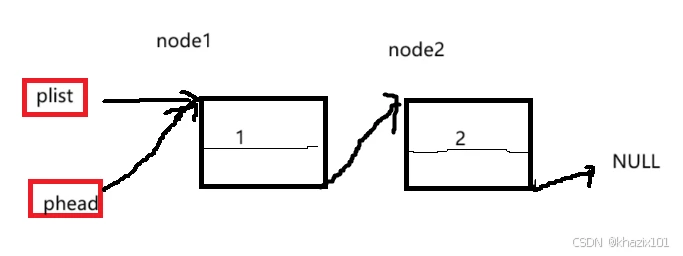
下面给出单链表的结构图。

图中的plist保存的是第一个有效结点(首结点)的地址,我们称plist指向首结点,链表中的每个结点都是独立申请的,我们需要通过指针变量保存下一个结点位置才能从当前结点找到下一个结点。尾结点的指针域为NULL,表示后面没有结点。
- 链式结构在逻辑上连续,在物理结构不一定连续(大概率是不连续的)。
- 结点一般从堆上申请。
- 申请来的空间,时按照一定的策略分配出来的,每次申请的空间可能连续,也可能不连续。
由于链表是由结构相同的若干个结点组成的,所以这里给出单链表结点结构的定义。
上述代码定义了单链表的结点结构并使用关键字类型重命名为SLTNode,data是这个结点的数据,next是一个指针变量指向了下一个结点。
当然也可以单独的类型重命名,有点冗余但便于理解。
上面我们给出了单链表的结点结构,那我们就可以使用这个结构来构造一个单链表。
我们首先使用malloc函数定义了4个结点,然后把每个结点的数据域赋值,然后把结点通过指针域连接起来,尾结点的指针域置为NULL, 最后定义一个结点指针plist指向首节点。
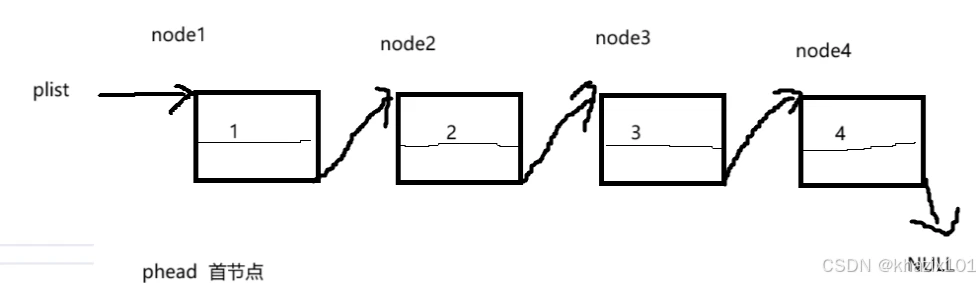
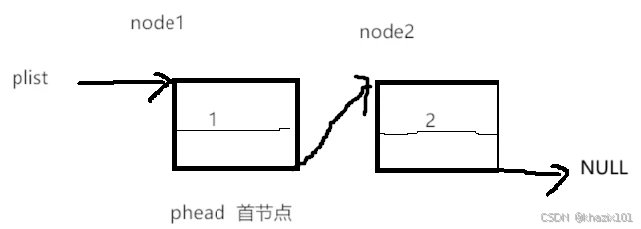
这个就是我们刚刚构造的单链表的结构图,plist是指向首节点的,这里的phead也是首节点,但是plist作为实参,phead为形参。
我们写一个打印单链表的函数把刚刚构造的单链表打印出来
遍历打印即可,这里有一个问题:为什么不直接使用phead,而是要定义一个pcur?其实是为了避免指针指向的改变,无法找到链表的首节点。在这个函数中直接使用phead同样可以完成打印,我们只要了解这个思想即可,在其他的函数中或许需要用到。
在我们需要对单链表进行插入操作的时候,首先我们需要有一个这样的结点来插入。
我们申请了一个结点,把数据域和指针域初始化,然后返回了这个结点,下面测试一下是否真的可以生成一个结点.
尾插就是在单链表的末端插入一个数据元素。单链表存在两种状态即plist != NULL或者plist == NULL,分别对应的是单链表中已经存在结点或不存在结点,但无论单链表处于那种状态,其实我们一般不会像 1.4 那样手动的构造一个链表,而是选择插入的方式。
先给出第一个版本的代码。
我们首先要申请一个结点,然后遍历找到当前单链表的尾结点,把尾结点的next指向这个新申请的结点,这样就完成了尾插,但是上面这个代码是有bug的,因为我们没有考虑到单链表为空的情况,即plist == NULL,这样phead形参为NULL,ptail也定义为NULL,这样ptail->next就是就是NULL进行解引用操作,这样是错误的,下面给出第二个版本的代码。
当链表尾空的时候,直接把直接让phead指向新申请的结点。
测试一下
当plist == node1的时候,我们发现结果是正确的,函数完成了正确的尾插。
但是当plist为空的时候,结点没有正确的插入,这是为什么呢?我们画一个图理解一下。
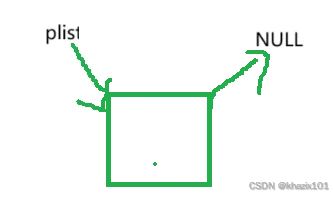
当plist不为空的时候,由于函数是传值调用,phead拷贝了plist的数据。phead和plist同时指向了单链表的第一个结点,由于链表中有数据元素,plist一直指向首元素的地址不需要改变,通过phead可以正确的找到尾结点实现尾插。

当plist为空的时候,phead也为空,但是在尾插的函数中,phead指向了新申请的结点,由于尾插函数是传值调用,形参phead的改变不影响实参plist,当使用打印函数的时候,传入plist打印还是NULL。所以我们应该使用传址调用。
测试一下

这里我们总结一下:plist是用于指向单链表的首节点,当实现某些功能的函数可能会导致plist指向的内容发生变化的时候,就要传址。其实我们可以设置一个哨兵尾/头结点来避免这个问题,这样我们只需要传值调用即可,头结点的设置也可以简化部分代码的实现,至于什么是头结点,我们放在后面的文章中讲解,本篇文章讲解的是”不带头不循环单链表”。
头插这里是必须传址调用,因为plist指向一定会改变。

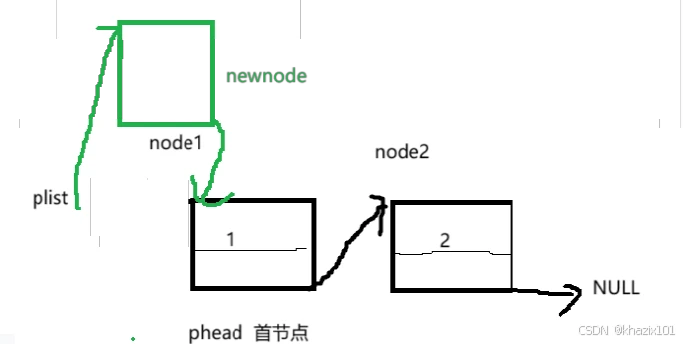
大家可以根据图来理解一下代码。
这里要指出的是,指针改变的先后顺序是确定的,pphead的修改一定是在newnode指向pphead之后的,否则就会出现newnode自循环的bug,大家可以自行画图验证。
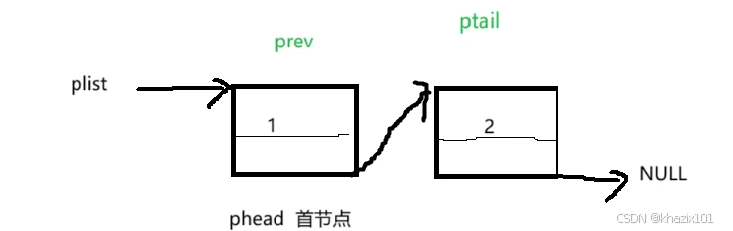
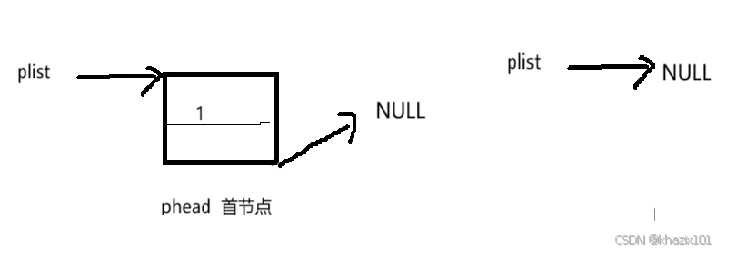
尾删的思路是找到尾结点和倒数第二个结点,把尾结点的空间释放,把倒数第二个结点的next置为NULL,同样的,尾删也有特殊情况需要处理,当链表只有一个结点的时候,这个结点即是首节点也是尾结点,while循环进不去并且prev被初始化为NULL,这样会产生NULL解引用这样的bug,所以单链表只有一个结点的时候,我们只需要释放首节点空间然后把指向首结点的指针置为空即可。
下面给出图结合代码理解一下。

测试一下
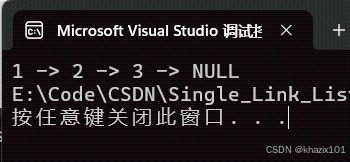
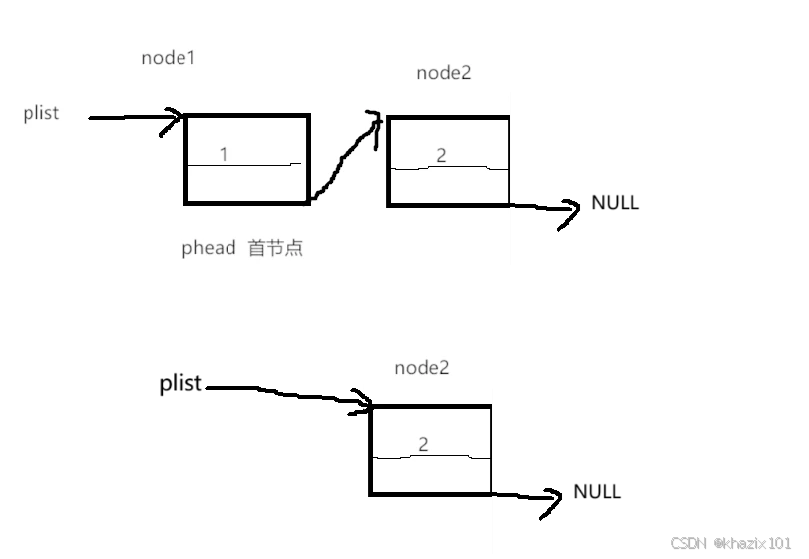
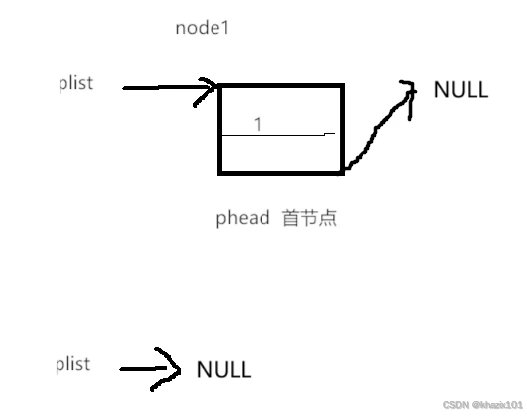
头删还是比较简单的,只需要把指向首节点的指针指向首节点的下一个指针,然后释放首节点的空间即可。
这个头删的代码对于只有一个元素的单链表也同样适用,这里说明一点,
头删和尾删中 是为了保证单链表中存在元素可以用来被删除。
测试一下。
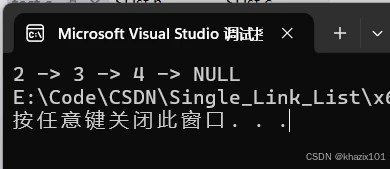
遍历单链表查找指定数据的元素并返回元素的地址,如果没有查找到就返回NULL,查找这个函数就不会像头删、尾删、头插、尾插函数可能会对指向首元素的指针进行改动,所以直接使用形参只使用一级指针对plist拷贝一份即可。
测试一下

把3改为4看看
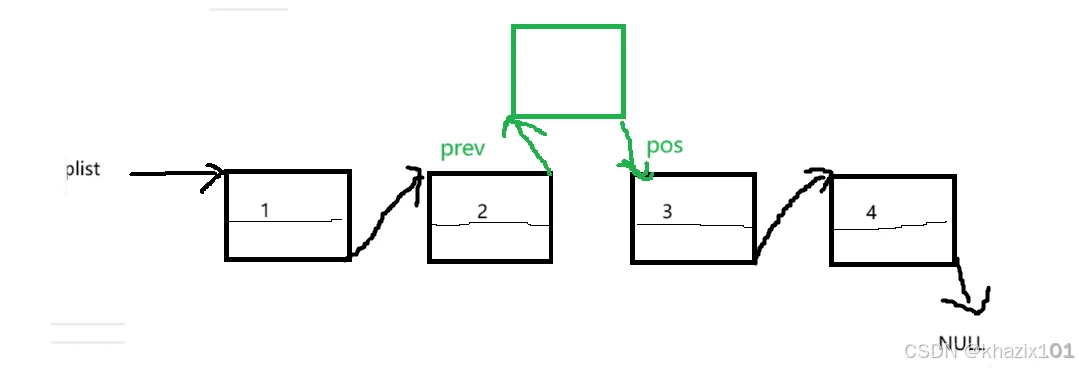
在指定位置之前插入数据首先我们要找到这个位置前面的一个数据,这个时候就需要通过遍历链表来找到,需要传首节点的地址,当指定的数据是首节点的时候,指向首节点的指针需要改变,所以这个函数要传二级指针进行传址调用。
这里需要单独处理并且指针指向的改变顺序确定,这是因为pos为首节点的地址的时候,prev->遍历完链表也不会跳出循环,最后NULL解引用出现bug,这里可以结合下面的图来理解,另外再说一下这里特殊情况的处理,其实就是头插,可以直接调用前面写好的头插的函数。
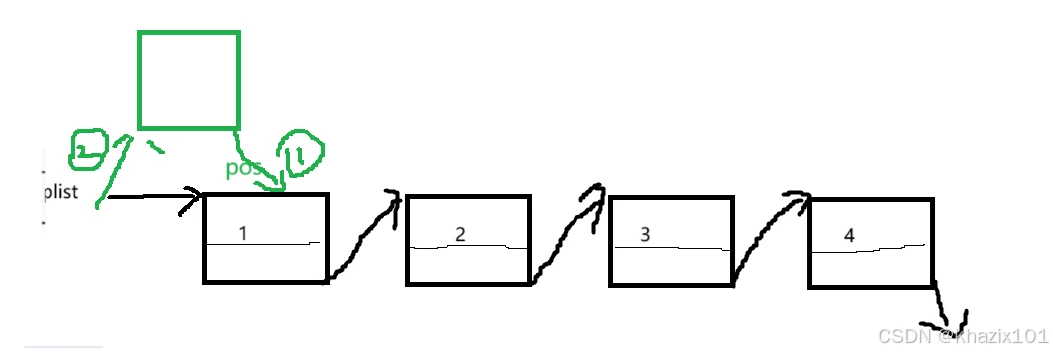
在指定位置后插入数据比在指定位置前要简单很多,不需要遍历确定prev,也不需要考虑特殊情况,但是这里步骤是一定的,必须先1后2,不然会造成newnode自己向自己。
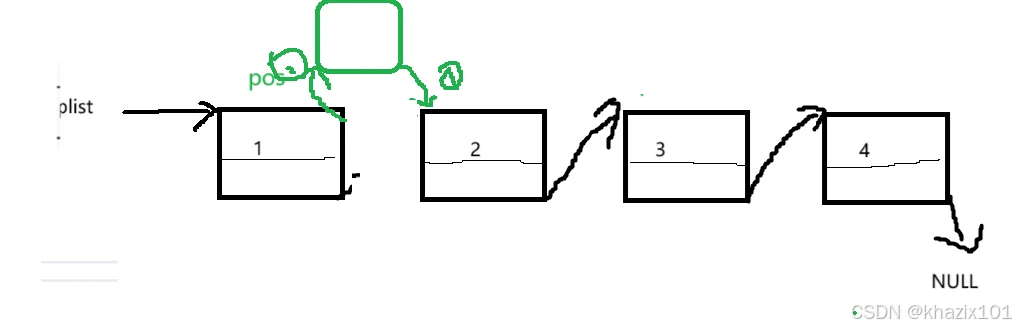
代码同样适用于pos指向尾结点的情况
测试一下。
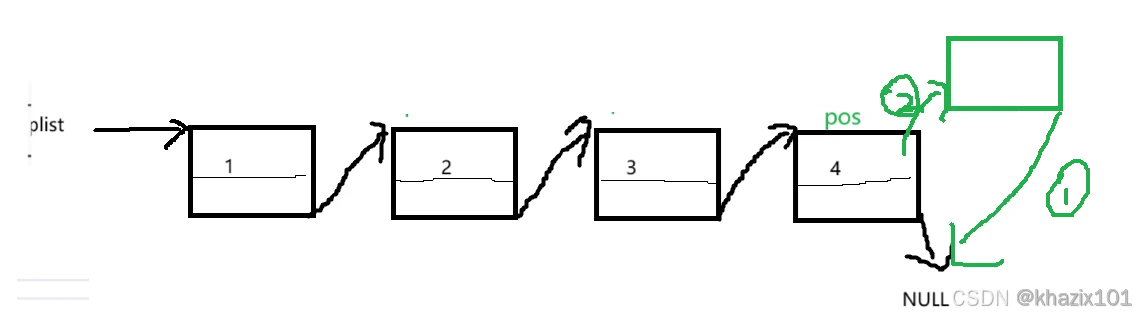
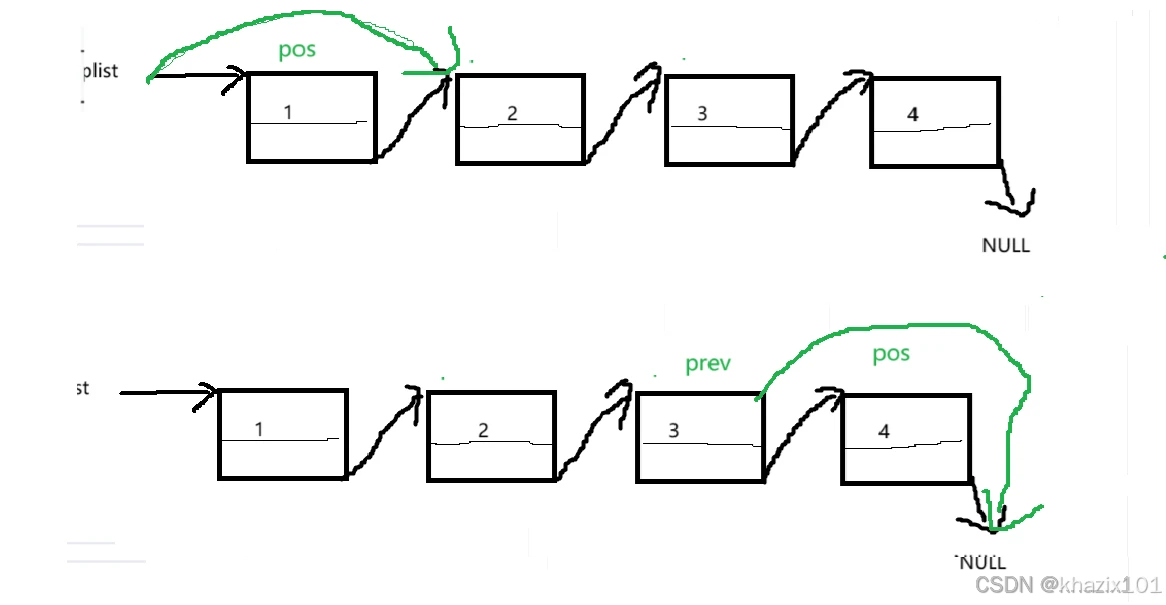
这个函数和在pos结点之前插入数据类似需要分情况处理,,因为在pos不为首节点的时候遍历找到prev的代码对于pos为首节点是不适用的,同时这里pos结点也可能指向首节点,所以要传二级指针。
当pos指向首节点的时候,其实就是头删,直接调用头删的代码即可。
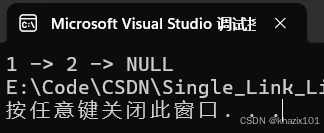
测试一下
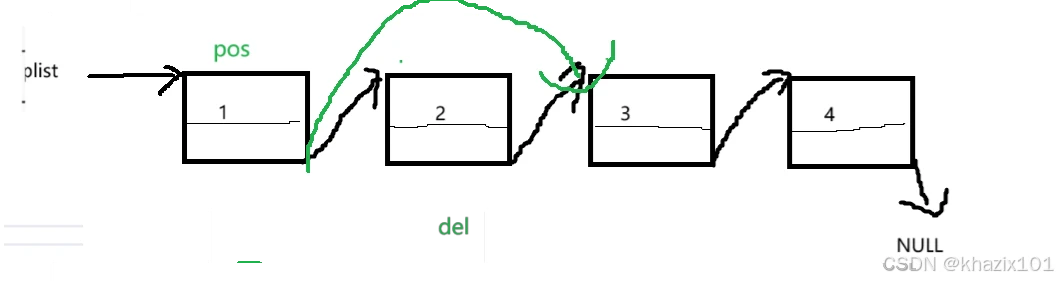
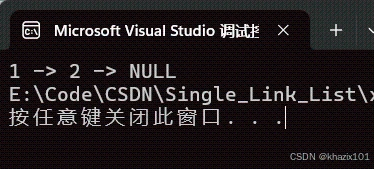
这个函数的实现比较简单,但是要注意pos之后的结点不为空,也就是pos->next != NULL。
链表是由一个个的结点组成,所以我们需要遍历的销毁组成链表的结点,这里首节点也要被销毁,也要传二级指针,来改变实参。
大家可以自行调试观察链表的销毁过程。
- 单链表是实现后面数据结构的基础,希望大家可以多多练习。
- 这里的单链表是无头结点的,链表的某些操作会改变首节点的地址,这个时候就需要传递二级指针来改变实参的值。
- 头结点不仅可以让函数只传递一级指针,并且可以简化代码,一些操作因为引入了头结点就没有了特殊情况的处理,可以简化代码。
- 头结点和首节点等概念会在我的下一篇文章《双向链表》中进一步论证。
- 再有些操作在进行特殊情况处理的时候,就是一个完整的其他的操作,可以直接调用对应操作的代码。
这篇文章篇幅较长,感谢大家耐心阅读,同时也欢迎大家在评论区讨论。
到此这篇单链表的存储密度小于1吗(单链表的存储密度小于1吗为什么)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/qkl-jc/73213.html