


💯AI绘画:开启艺术创作新纪元
人工智能正以前所未有的力量重塑我们的世界,而AI绘画作为这股科技浪潮中的璀璨明星,正以其非凡的魅力吸引着无数目光。本文将引领您踏入AI绘画的奇幻之旅,揭秘其背后的技术发展、应用价值,并向您推荐几款强大的AI绘画工具,让您亲身体验这一创新科技带来的无限魅力!

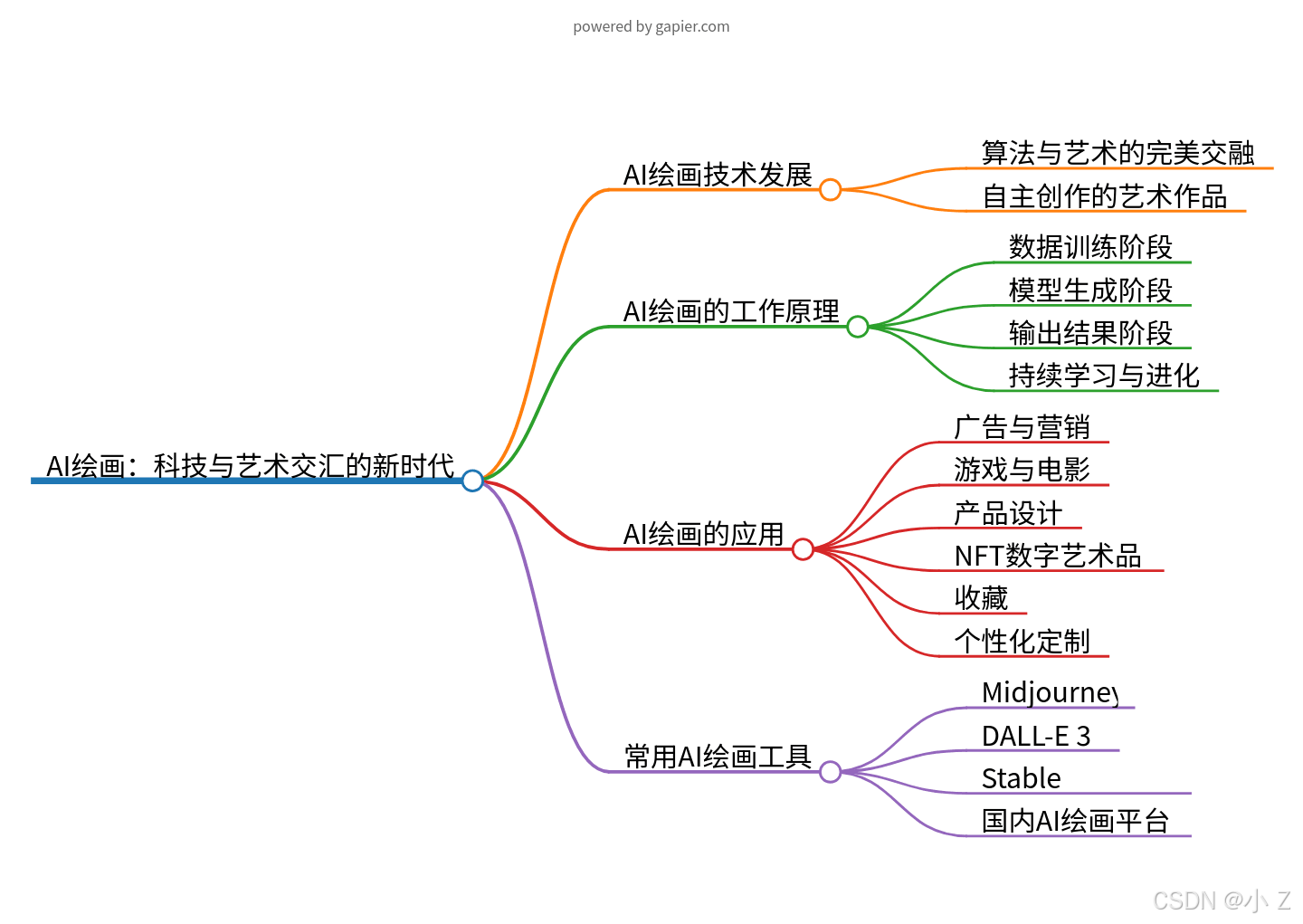
AI绘画技术发展:算法与艺术的完美交融
AI绘画,这一前沿的艺术创新形式,正引领我们进入一个全新的艺术纪元。它巧妙融合了机器学习、深度学习等尖端人工智能技术,让计算机能够模拟人类的绘画创作过程,生成充满艺术美感的图像作品。其核心奥秘在于,通过训练AI模型学习海量的图像数据,从中提炼出独特的艺术风格、精妙的构图规律等关键信息,最终实现自主创作,让技术与艺术在AI绘画中碰撞出璀璨的火花。

AI绘画的工作原理与创意生成
AI绘画究竟是如何工作的呢?
1. 数据训练阶段:
AI模型如同一位勤奋的学者,它需要通过大量的图像数据进行训练。这些数据涵盖了各种绘画风格、色彩搭配以及构图元素,无论是古典的油画笔触,还是现代的抽象艺术,都一一被AI模型吸纳并学习。在这个过程中,AI模型逐渐掌握了艺术创作的规律和技巧,为接下来的创作之旅储备了丰富的灵感库。
2. 模型生成阶段:
当数据训练阶段告一段落,AI模型便拥有了无穷的创意源泉。它可以根据用户的简单文本描述,如“春日的乡间小路”,或者用户提供的图像参考,瞬间挥洒出全新的绘画作品。这一过程中,AI模型将所学的艺术风格和元素进行巧妙的组合和创新,每一幅作品都仿佛蕴含着AI对世界的独特理解和诠释。
3. 输出结果阶段:
AI模型将精心生成的图像作品呈现给用户,但这仅仅是开始。用户如同拥有了一位私人艺术顾问,可以随心所欲地对作品进行修改和调整。无论是调整色彩饱和度,还是改变画面的构图布局,AI都能即时响应,与用户共同探索艺术的无限可能。这种互动式的体验让用户更加深入地参与到艺术创作中来,感受艺术带来的无尽魅力。
4. 持续学习与进化:
AI绘画的魅力不仅在于其当前的创作能力,更在于它的持续学习与进化能力。随着用户反馈的不断积累,AI模型可以不断优化其绘画技巧和艺术理解,为用户带来更加个性化、高质量的艺术作品。可以预见,在未来的日子里,AI绘画将不断突破创作的边界,为我们带来更多前所未有的艺术惊喜。

AI绘画的应用
AI绘画在我们生活中有哪些应用呢?


1. 广告与营销:注入新活力
AI绘画为广告与营销领域带来了前所未有的创意革新。它能够生成独具匠心的广告海报和产品宣传图,为品牌营销注入新的活力。通过深度学习和大数据分析,AI能够洞察消费者喜好和市场趋势,从而创作出更加吸引人眼球的广告作品。这些作品不仅具有高度的个性化,还能在瞬间捕捉观众的注意力,实现品牌与消费者之间的深度互动。

2. 游戏与电影:提升制作效率与艺术表现力
在游戏与电影制作领域,AI绘画同样发挥着举足轻重的作用。它能够迅速生成逼真的游戏场景、角色和道具,为玩家带来更加沉浸式的游戏体验。同时,在电影制作过程中,AI绘画也能够帮助概念设计师快速绘制出令人惊叹的场景和角色设计,极大地提升了制作效率和艺术表现力。这些由AI创作的作品不仅具有高度的真实感,还能展现出独特的艺术风格,为观众带来前所未有的视觉盛宴。

3. 产品设计:助力创新与效率提升
在产品设计领域,AI绘画成为了设计师们的得力助手。它能够辅助设计师进行产品外观设计和图案创作,提供丰富的灵感和创意。通过AI的帮助,设计师们能够更加高效地完成设计任务,同时还能保证作品的创新性和独特性。这种智能化的设计方式不仅提高了设计效率,还为产品的市场竞争力和品牌形象注入了新的活力。

4. NFT:开辟新的创作和变现途径
随着NFT(非同质化代币)的兴起,AI绘画作品也找到了新的应用场景。这些作品可以作为数字艺术品进行确权和交易,为艺术家们开辟了新的创作和变现途径。通过NFT平台,艺术家们可以将自己的AI绘画作品转化为独特的数字资产,实现作品的版权保护和价值转化。这种创新的模式不仅为艺术家们带来了更多的经济收益,还推动了数字艺术品的繁荣和发展。

5. 收藏:独特的艺术风格和收藏价值
除了在应用领域的广泛探索外,AI绘画作品还因其独特的艺术风格和收藏价值而逐渐受到艺术爱好者和收藏家的关注。这些作品不仅展示了AI在艺术创作方面的无限潜力,还体现了人类与机器智能之间的紧密合作。一些具有独特风格和创意的AI绘画作品甚至成为了收藏家们争相追捧的珍品。

6. 个性化定制:满足多元化需求
AI绘画在个性化定制领域也展现出了巨大的潜力。它能够根据用户的需求生成个性化的图像作品,如肖像画、插画等。这种定制化的服务不仅满足了用户多元化的需求,还为AI绘画的应用开辟了新的市场空间。无论是个人用户还是企业客户,都可以通过AI绘画获得独特且富有创意的图像作品。

💯AI绘画工具介绍
- Midjourney:https://www.midjourney.com/home
作为目前最受欢迎的AI绘画工具之一,Midjoumey以其强大的功能和精美的画风著称,用户可以通过简单的文字描述生成充满想象力的图像。

- DALL-E 3: https://openai.com/index/dall-e-3/
DALL-E 3是OpenAI开发的新一代AI绘画模型,其生成图像的质量和细节表现力令人惊叹,被誉为AI绘画领域的里程碑。


- Stable Diffusion https://www.stablediffusion-cn.com/
Stable Diffusion是一个开源的AI绘画模型,用户可以根据自己的需求对模型进行训练和调整,创作出独具个性的作品。

- Leonardo.ai: https://leonardo.ai/
一个非常不错的AI绘画平台,集成了多个主流的AI绘画模型。

- 国内大模型
如文心一言、豆包 :https://www.doubao.com/chat/等,可以文生图,出图效果不如专业的AI绘画平台

- 国内专业AI绘画平台
快影、奇域:https://www.qiyuai.net/、无界、美图秀秀、Vega等在MJ和SD的基础上定制开发,国风表现出色

💯小结
随着AI技术的飞速发展,AI绘画已经从一个遥不可及的梦想转变为现实,并在多个领域展现出巨大的潜力和广泛的应用前景。从广告与营销的创意革新,到游戏与电影制作的效率提升,再到产品设计的创新助力,AI绘画正以其实用性和艺术性并重的特点,深刻改变着我们的创意产业。同时,NFT的兴起为AI艺术作品提供了新的确权与交易方式,进一步推动了数字艺术品的繁荣。- 我们见证了AI绘画工具的不断涌现与进步,从Midjourney的精美画风,到DALL-E 3的惊人细节表现力,再到Stable Diffusion的开源自由,每一款工具都在为艺术家和创作者们打开新的可能。国内市场的崛起也不容忽视,无论是大型模型如文心一言,还是专业的AI绘画平台如奇域、无界等,都在不断探索和突破,为国风文化艺术注入新的活力。
- 未来,随着人工智能技术的不断成熟和应用场景的持续拓展,AI绘画将继续引领艺术创作的潮流,开启一个全新的艺术纪元。我们期待着AI绘画能够为我们带来更多前所未有的艺术体验,同时也期待艺术家与AI之间的合作能够创造出更多令人惊叹的作品。在这场科技与艺术的交融盛宴中,让我们共同见证并参与这一历史性的变革吧!

import torch, torch.nn as nn, torch.optim as optim; from torch.utils.data import DataLoader, Dataset; import torchvision.transforms as transforms, torchvision.utils as vutils; from PIL import Image; import os, random, numpy as np, cv2; class PaintingDataset(Dataset): def __init__(self, root_dir, transform=None): self.root_dir = root_dir; self.transform = transform; self.image_files = os.listdir(root_dir); def __len__(self): return len(self.image_files); def __getitem__(self, idx): img_name = os.path.join(self.root_dir, self.image_files[idx]); image = Image.open(img_name).convert('RGB'); if self.transform: image = self.transform(image); return image; class ResidualBlock(nn.Module): def __init__(self, in_channels, out_channels): super(ResidualBlock, self).__init__(); self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1); self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1); self.relu = nn.ReLU(); def forward(self, x): identity = x; out = self.conv1(x); out = self.relu(out); out = self.conv2(out); out += identity; return self.relu(out); class Generator(nn.Module): def __init__(self): super(Generator, self).__init__(); self.initial = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=1, padding=3), nn.BatchNorm2d(64), nn.ReLU()); self.downsampling = nn.Sequential(nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1), nn.BatchNorm2d(128), nn.ReLU(), nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1), nn.BatchNorm2d(256), nn.ReLU()); self.residual_blocks = nn.Sequential(*[ResidualBlock(256, 256) for _ in range(9)]); self.upsampling = nn.Sequential(nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1), nn.BatchNorm2d(128), nn.ReLU(), nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1), nn.BatchNorm2d(64), nn.ReLU()); self.output_layer = nn.Conv2d(64, 3, kernel_size=7, stride=1, padding=3); self.tanh = nn.Tanh(); def forward(self, x): x = self.initial(x); x = self.downsampling(x); x = self.residual_blocks(x); x = self.upsampling(x); return self.tanh(self.output_layer(x)); class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__(); self.model = nn.Sequential(nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1), nn.LeakyReLU(0.2), nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1), nn.BatchNorm2d(128), nn.LeakyReLU(0.2), nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1), nn.BatchNorm2d(256), nn.LeakyReLU(0.2), nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1), nn.BatchNorm2d(512), nn.LeakyReLU(0.2), nn.Conv2d(512, 1, kernel_size=4, stride=1, padding=1), nn.Sigmoid()); def forward(self, x): return self.model(x); device = torch.device("cuda" if torch.cuda.is_available() else "cpu"); generator = Generator().to(device); discriminator = Discriminator().to(device); def weights_init(m): if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d): nn.init.normal_(m.weight.data, 0.0, 0.02); elif isinstance(m, nn.BatchNorm2d): nn.init.normal_(m.weight.data, 1.0, 0.02); nn.init.constant_(m.bias.data, 0); generator.apply(weights_init); discriminator.apply(weights_init); transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]); dataset = PaintingDataset(root_dir='path_to_paintings', transform=transform); dataloader = DataLoader(dataset, batch_size=16, shuffle=True); criterion = nn.BCELoss(); optimizerG = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999)); optimizerD = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999)); fixed_noise = torch.randn(16, 3, 256, 256, device=device); for epoch in range(200): for i, data in enumerate(dataloader): real_images = data.to(device); batch_size = real_images.size(0); optimizerD.zero_grad(); real_labels = torch.ones(batch_size, 1, 16, 16, device=device); fake_labels = torch.zeros(batch_size, 1, 16, 16, device=device); output_real = discriminator(real_images); noise = torch.randn(batch_size, 3, 256, 256, device=device); fake_images = generator(noise); output_fake = discriminator(fake_images.detach()); loss_real = criterion(output_real, real_labels); loss_fake = criterion(output_fake, fake_labels); lossD = (loss_real + loss_fake) / 2; lossD.backward(); optimizerD.step(); optimizerG.zero_grad(); output_fake = discriminator(fake_images); lossG = criterion(output_fake, real_labels); lossG.backward(); optimizerG.step(); with torch.no_grad(): fake_images = generator(fixed_noise).detach().cpu(); grid = vutils.make_grid(fake_images, padding=2, normalize=True); vutils.save_image(grid, f'output/fake_painting_epoch_{
epoch}.png'); def artistic_style_transfer(content_path, style_path, output_path, num_steps=500, style_weight=, content_weight=1): vgg = models.vgg19(pretrained=True).features.to(device).eval(); content_img = Image.open(content_path).convert('RGB'); style_img = Image.open(style_path).convert('RGB'); content_img = transform(content_img).unsqueeze(0).to(device); style_img = transform(style_img).unsqueeze(0).to(device); target_img = content_img.clone().requires_grad_(True); optimizer = optim.Adam([target_img], lr=0.003); def get_features(image, model): layers = {
'0': 'conv1_1', '5': 'conv2_1', '10': 'conv3_1', '19': 'conv4_1', '21': 'conv4_2', '28': 'conv5_1'}; features = {
}; x = image; for name, layer in model._modules.items(): x = layer(x); if name in layers: features[layers[name]] = x; return features; def gram_matrix(tensor): _, d, h, w = tensor.size(); tensor = tensor.view(d, h * w); gram = torch.mm(tensor, tensor.t()); return gram / (d * h * w); content_features = get_features(content_img, vgg); style_features = get_features(style_img, vgg); style_grams = {
layer: gram_matrix(style_features[layer]) for layer in style_features}; for step in range(num_steps): optimizer.zero_grad(); target_features = get_features(target_img, vgg); content_loss = torch.mean((target_features['conv4_2'] - content_features['conv4_2']) 2); style_loss = 0; for layer in style_grams: target_gram = gram_matrix(target_features[layer]); style_gram = style_grams[layer]; layer_style_loss = torch.mean((target_gram - style_gram) 2); style_loss += layer_style_loss / len(style_grams); total_loss = style_weight * style_loss + content_weight * content_loss; total_loss.backward(); optimizer.step(); output_image = target_img.squeeze().cpu().clamp(0, 1); vutils.save_image(output_image, output_path);
到此这篇【AIGC】AI绘画:科技与艺术交汇的新时代_科技与绘画相结合的案例的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/qkl-szzc/7863.html