
前言:由于考虑到elasticsearch单节点的不稳定性和服务的高可用性,随着用户量和数据量的增加,elasticsearch需要搭建集群,集群的优点这里就不赘述了。
一、准备环境
1.192.168.11.24 和192.168.11.25(需要安装java环境)
2.elastisearch安装包:elasticsearch-6.2.2.tar.gz,
3.两个服务器上需要创建es权限的非root用户,以上不会的可以参考我之前的博客:centos服务器配置elasticsearch
在服务器上将安装包拷贝出来一份,我的es安装目录在/usr/local下,所以我在该目录下建立一个slave目录用于存放需要集群的es。
二、搭建集群环境
1.集群概况:
| 服务器ip | 节点名称 | 是否为主节点 | 是否为数据节点 |
| 192.168.11.24 | master | 是 | 是 |
| 192.168.11.25 | slave-1 | 否 | 是 |
| 192.168.11.25 | slave-2 | 否 | 是 |
2.配置主节点
集群名称,每个节点配置成一样的名称才能形成正确的集群 cluster.name: htflsys 节点名称,每个节点配置不同名称 node.name: master 是否主节点 node.master: true 是否数据节点 node.data: true 单机最大节点数 node.max_local_storage_nodes: 3 索引数据的存储路径(可自定义,我这里不设置就默认安装路径) #path.data: /usr/local/es/data 日志文件的存储路径(可自定义,我这里不设置就默认安装路径) #path.logs: /usr/local/es/logs 启动时锁定内存,设置为true来锁住内存。因为内存交换到磁盘对服务器性能来说是致命的,当jvm开始swapping时es的效率会降低,所以要保证它不swap bootstrap.memory_lock: true bootstrap.system_call_filter: false 绑定的ip地址 network.host: 192.168.11.24 设置对外服务的http端口,默认为9200 http.port: 9200 设置节点间交互的tcp端口,默认是9300 transport.tcp.port: 9300 transport.tcp.compress: true 设置集群中节点的初始列表,可以通过这些节点来自动发现新加入集群的节点 discovery.zen.ping.unicast.hosts: ["192.168.11.24:9300","192.168.11.25:9300","192.168.11.25:9301"] 防止脑裂现象,如果没有这种设置,遭受网络故障的集群就有可能将集群分成两个独立的集群 - 这将导致数据丢失(单个master无需设置,如果是3个master需设置成2)(N/2)+1 #discovery.zen.minimum_master_nodes: 2 #在删除索引时,是否需要明确指定名称,该值为false时,将可以通过正则或_all进行所以 删除 #action.destructive_requires_name: true 防止同一个shard的主副本存在同一个物理机上 cluster.routing.allocation.same_shard.host: true3.重启成功节点信息截图(由于我原始数据快照问题出现Unassigned请忽略):
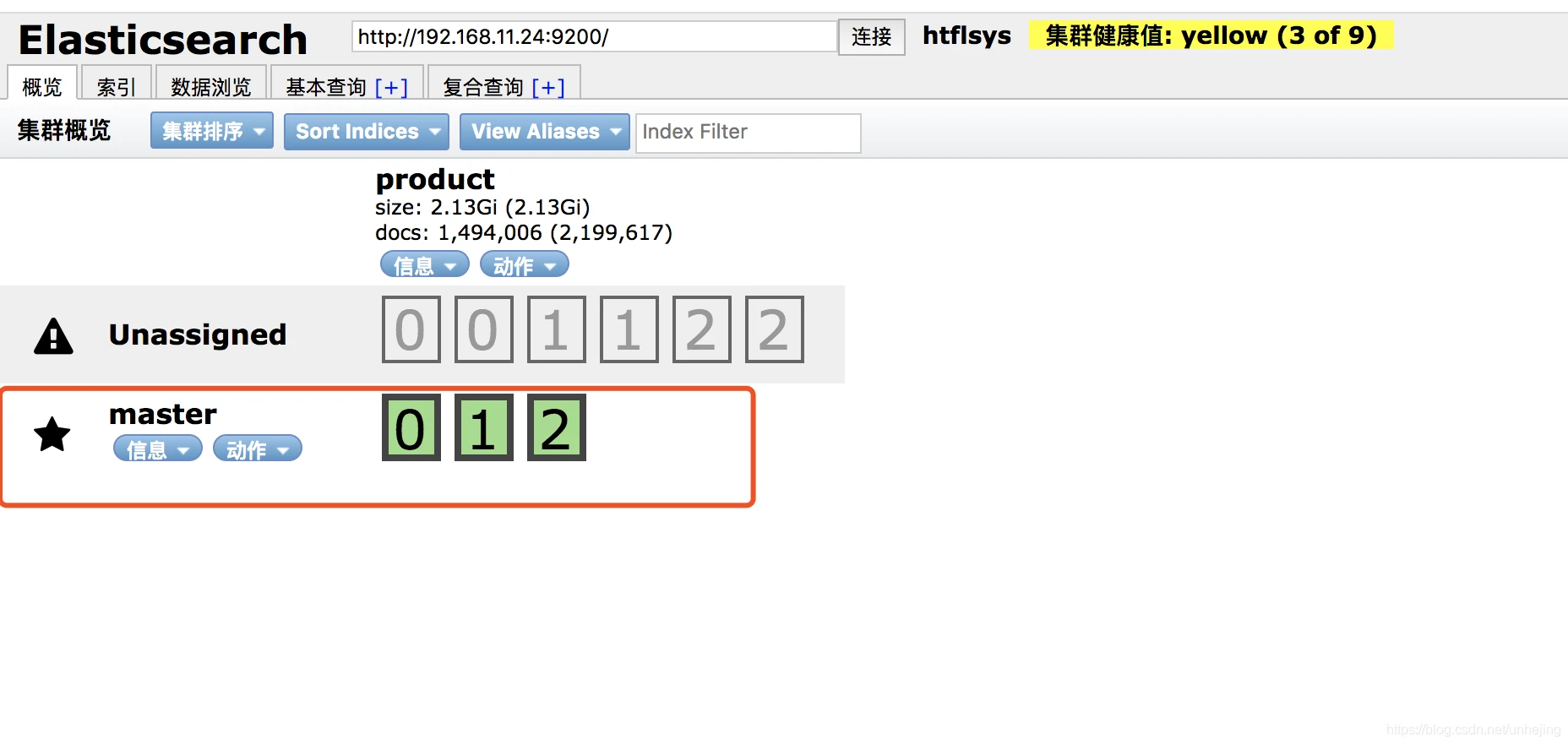
4.配置子节点
需要修改的参数有:node-name、node-master、network.host、http.port、transport.tcp.port
子节点1配置如下:
集群名称,每个节点配置成一样的名称才能形成正确的集群 cluster.name: htflsys 节点名称,每个节点配置不同名称 node.name: slave-node1 是否主节点 node.master: false 是否数据节点 node.data: true 单机最大节点数 node.max_local_storage_nodes: 3 索引数据的存储路径(可自定义,我这里不设置就默认安装路径) #path.data: /usr/local/es/data 日志文件的存储路径(可自定义,我这里不设置就默认安装路径) #path.logs: /usr/local/es/logs 启动时锁定内存,设置为true来锁住内存。因为内存交换到磁盘对服务器性能来说是致命的,当jvm开始swapping时es的效率会降低,所以要保证它不swap bootstrap.memory_lock: true bootstrap.system_call_filter: false 绑定的ip地址 network.host: 192.168.11.25 设置对外服务的http端口,默认为9200 http.port: 9200 设置节点间交互的tcp端口,默认是9300 transport.tcp.port: 9300 transport.tcp.compress: true 设置集群中节点的初始列表,可以通过这些节点来自动发现新加入集群的节点 discovery.zen.ping.unicast.hosts: ["192.168.11.24:9300","192.168.11.25:9300","192.168.11.25:9301"] 防止脑裂现象,如果没有这种设置,遭受网络故障的集群就有可能将集群分成两个独立的集群 - 这将导致数据丢失(单个master无需设置,如果是3个master需设置成2)(N/2)+1 #discovery.zen.minimum_master_nodes: 2 #在删除索引时,是否需要明确指定名称,该值为false时,将可以通过正则或_all进行所以 删除 #action.destructive_requires_name: true 防止同一个shard的主副本存在同一个物理机上 cluster.routing.allocation.same_shard.host: true子节点2配置如下:
集群名称,每个节点配置成一样的名称才能形成正确的集群 cluster.name: htflsys 节点名称,每个节点配置不同名称 node.name: slave-node2 是否主节点 node.master: false 是否数据节点 node.data: true 单机最大节点数 node.max_local_storage_nodes: 3 索引数据的存储路径(可自定义,我这里不设置就默认安装路径) #path.data: /usr/local/es/data 日志文件的存储路径(可自定义,我这里不设置就默认安装路径) #path.logs: /usr/local/es/logs 启动时锁定内存,设置为true来锁住内存。因为内存交换到磁盘对服务器性能来说是致命的,当jvm开始swapping时es的效率会降低,所以要保证它不swap bootstrap.memory_lock: true bootstrap.system_call_filter: false 绑定的ip地址 network.host: 192.168.11.25 设置对外服务的http端口,默认为9200 http.port: 9201 设置节点间交互的tcp端口,默认是9300 transport.tcp.port: 9301 transport.tcp.compress: true 设置集群中节点的初始列表,可以通过这些节点来自动发现新加入集群的节点 discovery.zen.ping.unicast.hosts: ["192.168.11.24:9300","192.168.11.25:9300","192.168.11.25:9301"] 防止脑裂现象,如果没有这种设置,遭受网络故障的集群就有可能将集群分成两个独立的集群 - 这将导致数据丢失(单个master无需设置,如果是3个master需设置成2)(N/2)+1 #discovery.zen.minimum_master_nodes: 2 #在删除索引时,是否需要明确指定名称,该值为false时,将可以通过正则或_all进行所以 删除 #action.destructive_requires_name: true 防止同一个shard的主副本存在同一个物理机上 cluster.routing.allocation.same_shard.host: true5.配置子节点
从192.168.11.24上将安装包上传值192.168.11.25服务器
scp elasticsearch-6.2.2.tar.gz root@192.168.11.25:/usr/local/在usr/local下创建目录,将安装包复制进去,分别解压配置,安装,启动:
/usr/local/elasticsearch/salve1 /usr/local/elasticsearch/salve2备注:从节点配置过程需要赋予elk权限:
groupadd elk # 创建用户组elk useradd elk -g elk -p # 创建新用户elk,-g elk 设置其用户组为 elk,-p 设置其密码6个1 chown -R elk:elk /usr/local/elasticsearch # 更改 /usr/local/elasticsearch 文件夹及内部文件的所属用户及组为 elk:elkelasticsearch chmod -R 777 /usr/local/elasticsearch # 启动报日志无权限需赋予文件夹可读写权限配置成功截图:
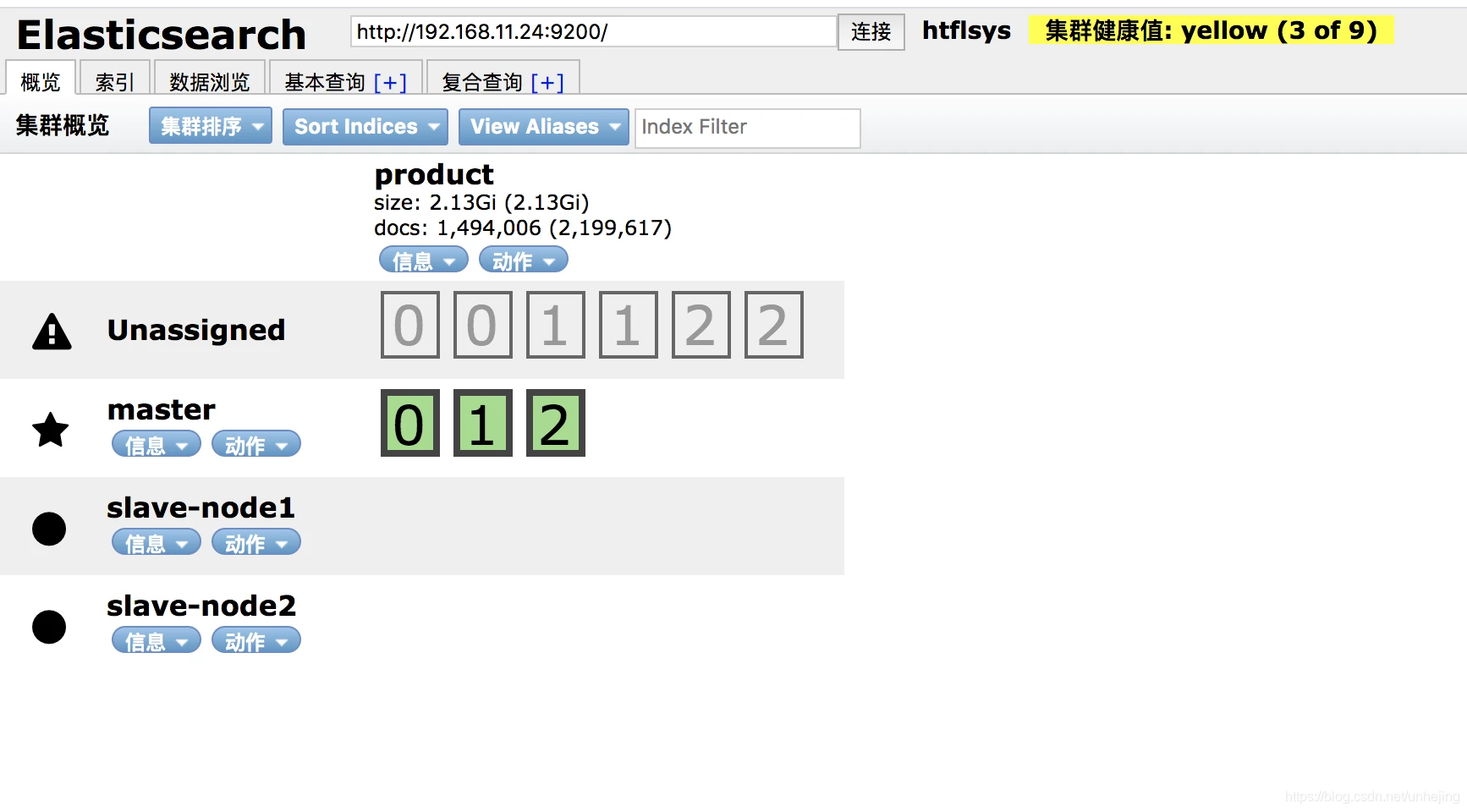
5. ElasticSearch监控工具 - cerebro
选择的原因是:cerebro的使用特别简单,页面漂亮,支持高版本
安装过程:
--下载安装包(安装包下载耗时非常久,如果需要我的安装包可以关注公众号FOSSspace,联系我)
wget https://github.com/lmenezes/cerebro/releases/download/v0.8.3/cerebro-0.8.3.tgz--解压安装到安装目录(我习惯和es同级/usr/local)
tar xzf cerebro-0.8.3.tgz--指定端口启动(默认是9000)
./cerebro -Dhttp.port=8888后台运行:
nohup /usr/local/cerebro-0.8.3/bin/cerebro -Dhttp.port=8888 &
--配置服务器(选配)
经常使用相同的es地址,可在conf/application.conf中配置好:
hosts = [ { host = "http://localhost:9200" name = "master" }, # Example of host with authentication #{ # host = "http://some-authenticated-host:9200" # name = "Secured Cluster" # auth = { # username = "username" # password = "secret-password" # } #} ]--使用
浏览器打开连接http://192.168.11.24:8888
6.需要注意的!!
由于master上的product索引安装了ik分词器插件,所以商品数据无法分片到从节点,从节点也需要单独安装ik分词器。
安装方法:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.2/elasticsearch-analysis-ik-6.2.2.zip安装完一定要重启,观察启动项是否有分词器,血的教训!!!!!!!!
总结:
1.如果是单机多节点,只是提高了ES服务器cpu的利用率,当服务器出现问题之后,整个集群还是不能正常使用。
2.配置elasticsearch.yml文件的时候我的node.master属性是指定死的,所以比较依赖master服务,如果master服务挂掉的话,整个服务也会挂掉,解决方案是在该服务器上创建多个master,如果master服务器挂掉,服务仍然会挂掉,所以最终解决方案可以是在两台服务器上创建master。如果使用node.master属性的默认值,如果指定的master挂掉了,整个集群可以正常使用,但是master节点就依赖谁先启动谁就是master。
该博客的完成参考了:elasticsearch集群(多机版)
到此这篇elasticsearch集群(多机版)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/10611.html