

在人工智能的发展历程中,自然语言处理(NLP)与计算机视觉(CV)的飞速发展已深刻重塑了人机互动的图景。如今,这股变革的浪潮正汹涌澎湃地涌入机器人技术领域,特别是具身智能的崭新篇章。清华大学的研究团队近期取得了具有里程碑意义的突破——揭示了data scaling laws的奥秘。这一发现不仅惊人地揭示了机器人领域与语言模型之间的深刻相似性,更为我们预测数据规模与模型性能之间的关系提供了坚实支撑。
研究团队借助便携式手持夹爪UMI,在丰富多样的真实环境中精心收集了超过4万条人类演示数据。这些数据广泛覆盖了火锅店、咖啡厅、公园等多种日常场景,更不乏喷泉旁、电梯内等独特环境,为模型训练提供了丰富的素材。
图2:使用UMI采集人类示教数据

物体泛化
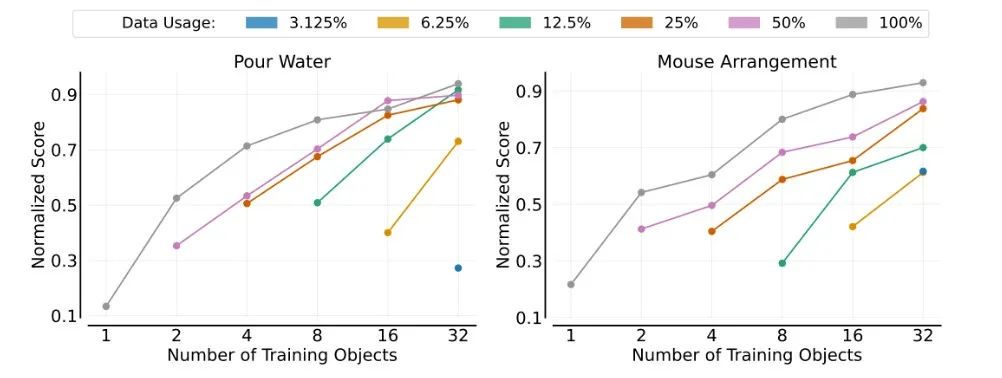
图5:对象泛化
每条曲线对应不同的演示使用量,显示的归一化分数是训练对象数量的函数。
环境泛化
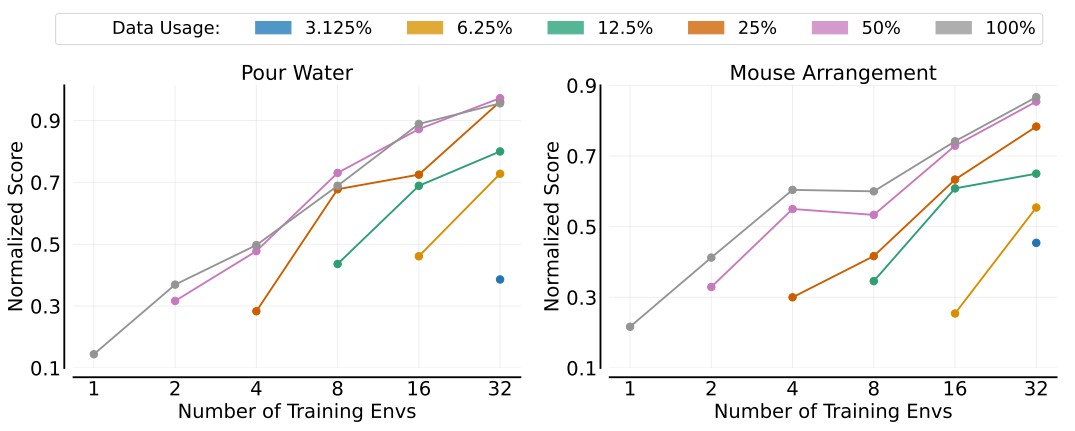
图6:环境泛化。
每条曲线对应不同的演示使用率,显示的归一化分数是训练环境数量的函数。
环境-物体组合泛化
在环境-物体组合泛化实验中,研究者同时调整训练环境和训练物体的数量,全面评估模型在未见环境-物体组合上的表现。此实验旨在深入剖析模型对新环境-物体组合的泛化能力如何随训练环境-物体对数量的增加而提升。
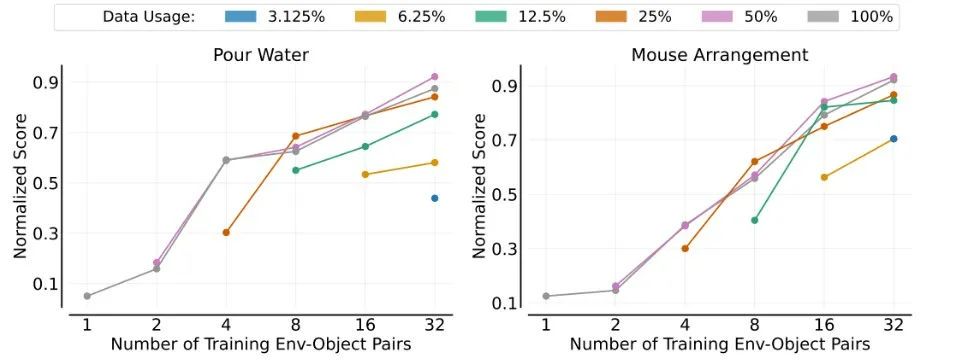
图7:跨环境和对象的泛化
每条曲线对应不同的每条曲线都对应于所使用的演示的不同比例,并以训练环境-对象对数的函数形式显示归一化分数。
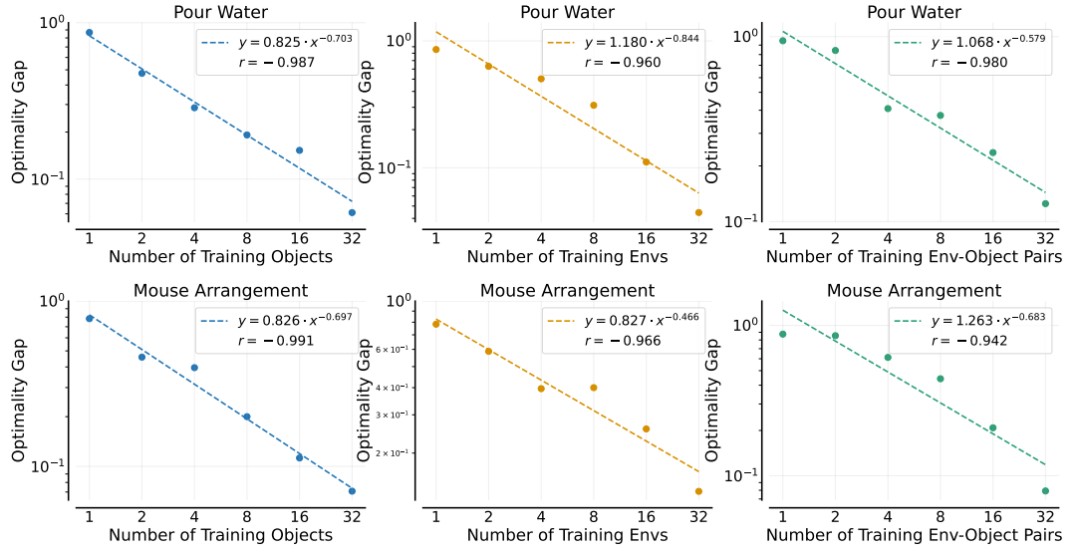
研究团队还成功攻克了业界长期以来的一个难题:在给定操作任务的前提下,如何科学合理地选择环境数量、物体数量以及每个物体的演示次数?
除了数据规模,研究团队在模型规模化方面也取得了三项重要发现:
数据规模化正引领机器人技术步入一个全新的时代。但研究团队也提醒我们,盲目追求数据量的增长并非明智之举。相较于单纯增加数据量,提升数据质量可能更为关键。未来的挑战在于,如何准确识别出真正需要扩展的数据类型,并探索最高效的数据采集策略,以获取这些高质量的数据资源。
Data Scaling Laws in Imitation Learning for Robotic Manipulation
编译|sienna
审核|fafa

深蓝知识星球开启!!
覆盖多个热门领域🔥
城市线下沙龙聚会🧑🎓
打破信息壁垒的技术交流社区👏
CoEdge: 面向自动驾驶的协作式边缘计算系统,实现分布式实时深度学习任务的高效调度与资源优化
燃爆!自主机器人技术研讨会 ——19 位青年报告嘉宾集结,火热报名中
*点击赞+在看收藏并推荐本文*
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/13294.html