
目录
一、随机抽样
在R语言中,可以使用sample()函数,轻易地从一堆数据中抽取样本,这个函数的使用格式如下:
sample(x,size,replace=FALSE,prob=NULL)
- x:向量,代表随机数样本的范围。
- size:正整数,代表取随机样本的数量。
- replace:默认是FALSE,如果是TRUE,则代表抽完一个样本后这个样本需放回去,供下次抽取。
- prob:默认是NULL,如果想将某些样本被抽取的概率增大,则可在这个参数中放置数值向量,代表样本被抽中的比重。
1.1 将随机抽样应用于扑克牌

这个实例每次执行均会有不同的输出结果。
1.2 种子值
set.seed()函数可用于设定种子值,set.seed()函数的参数可以是一个数字,当设置种子值后,在相同种子值后面的sample()所产生的随机数序列将相同。
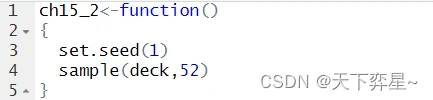

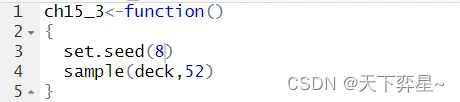
对上述程序而言,每次执行均可以获得相同的扑克牌出牌顺序。在set.seed()函数中放置不同的参数会有不同的出牌顺序。
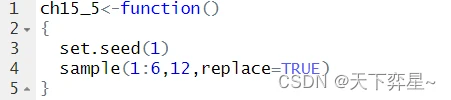
 1.3 模拟骰子
1.3 模拟骰子
骰子由1到6组成,如果我们想要掷12次,同时记录结果,可以使用下列方法:

在上述程序中,由于每次掷骰子必须重新取样,所以replace参数需设为TRUE,可以想成将抽取的样本放回去,然后重新取样。当然设置种子值得方法也适合应用于掷骰子取样。

1.4 比重的设置
如果在取样时,希望某些样本有较高的概率被抽取,可更改比重。
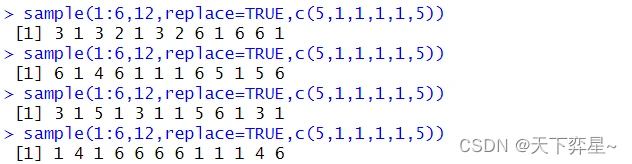
上述程序表示。掷骰子时,1和6设有5倍于平均的比重被随机抽中。
二、再谈向量数据的抽取——以islands为实例

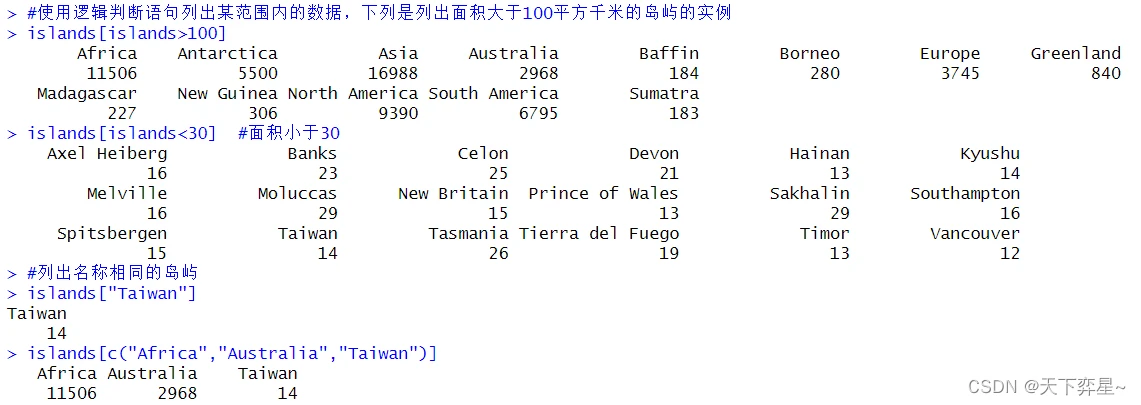
三、数据框数据的抽取——重复值的处理
iris是系统内建的数据框数据集,内含150个记录。
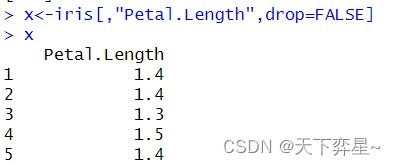
数据框是一个二维的对象,所以在抽取数据时索引须包括行和列。

由上述执行结果可以发现,iris原是数据框数据类型,经上述抽取后,由于是单列的数据,所以数据类型被简化为向量,如果想避免这类情况发生,可以在抽取数据时增加参数“drop=FALSE"。
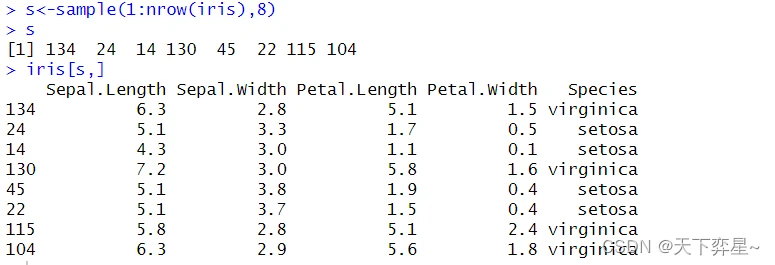
上述只列出部分结果。


 3.1 重复值的搜索
3.1 重复值的搜索
使用duplicated()函数可以搜寻对象是否有重复值,数值在第一次出现时会返回FALSE,未来重复出现时则传回TRUE。
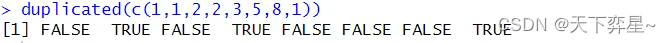
这个函数如果应用于数据框,则必须该行内所有数据与前面某行所有数据重复才算重复。

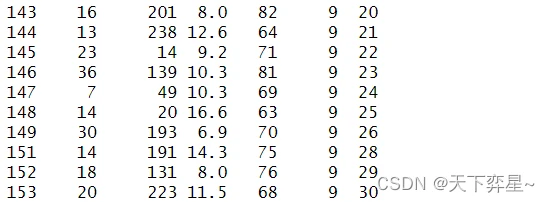
由上述执行结果,可以发现第143行数据返回TRUE,所以这行数据是重复出现的。
3.2 which()函数
which()函数可以传回重复值的索引。

3.3 抽取数据是去除重复值
有两个方法可以在抽取数据时去除重复值,方法1是使用负值索引。
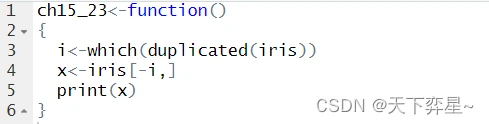
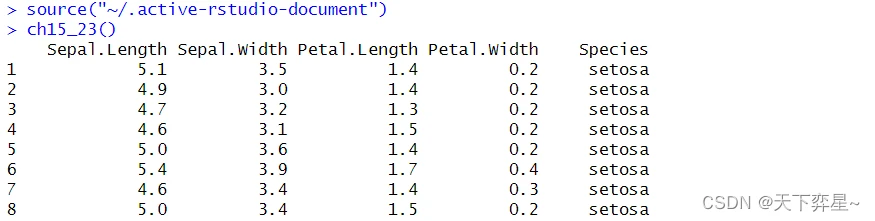 如果往下滚动屏幕,则可以看到下列输出结果:
如果往下滚动屏幕,则可以看到下列输出结果: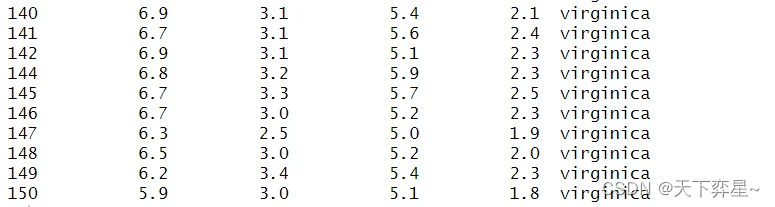 从上述执行结果中可以看到,第143行数据已被去除。
从上述执行结果中可以看到,第143行数据已被去除。
方法2是直接使用逻辑运算语句。
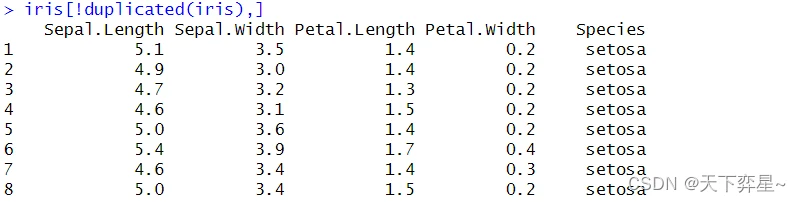
如果往下滚动屏幕,可以看到下列输出结果:
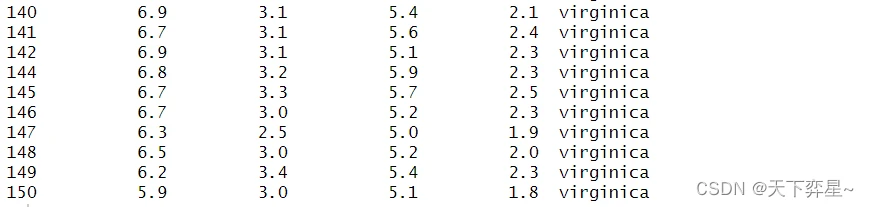 由以上执行结果可以看到第143行数据已被去除。
由以上执行结果可以看到第143行数据已被去除。
四、数据框数据的抽取——缺少值的处理
在真实的世界里,有时候无法收集到正确信息,此时可能用NA代表缺少值。
4.1 抽取数据时去除含NA值得行数据
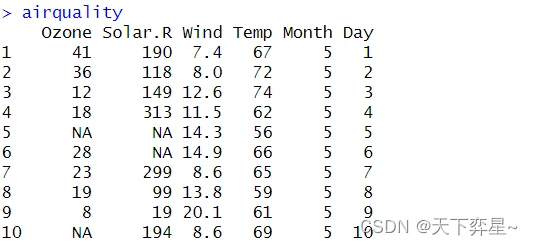
R语言系统有一个内建的数据集airquality,它的数据如下所示:(仅展示部分数据)
以下是使用str()函数了解其结构。
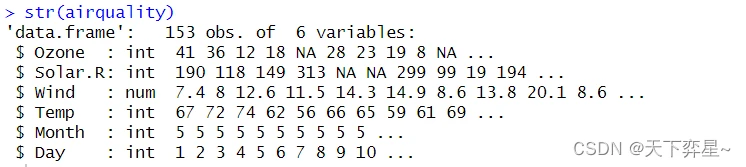
由以上执行结果可以知道airquality是数据框对象,也可以看到上述对象含有许多NA值。R语言提供了complete.cases()函数,如果对象的数据行是完整的则传回TRUE,如果对象数据含NA值则传回FALSE。

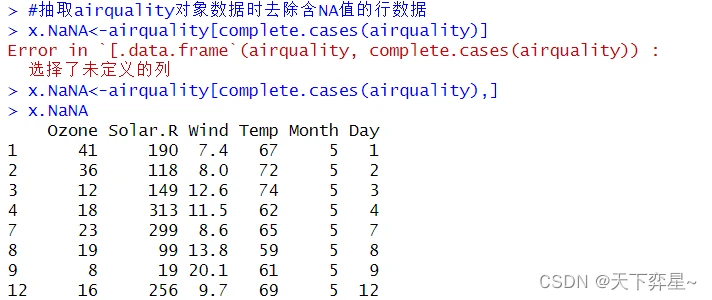 如果往下滚动屏幕,可以看到下列结果:
如果往下滚动屏幕,可以看到下列结果:
由上述执行结果可以看到,x.NaNA对象将不再含有NA的数据了。以下使用str()函数了解新对象的结构。

可以看到,原先有153行数据,最后只剩下111行数据了。
4.2 na.omit()函数
使用na.omit()函数也可以实现上一节的功能。
五、数据框的字段运算
对于数据框而言,每一个字段(列数据)皆是以恶向量,所以对于字段之间的运算,也可以视之为向量的运算。
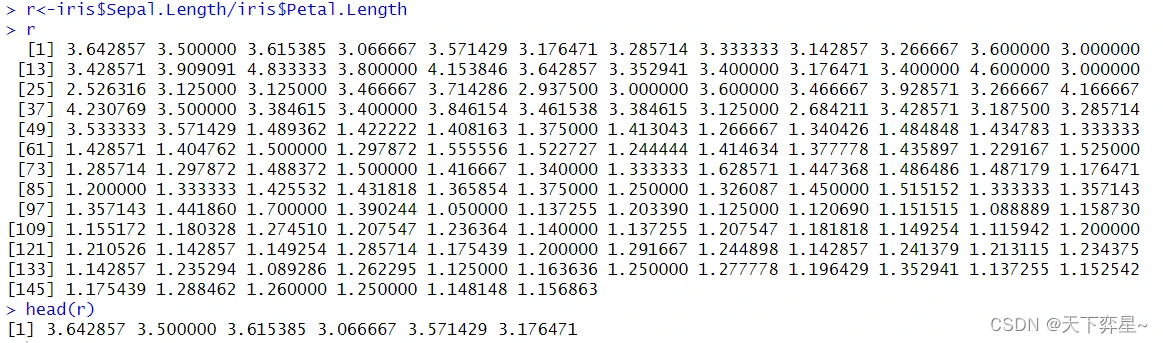
5.1 基本数据框的字段运算
5.2 with()函数
在执行数据框的字段运算时,”数据框名称“加上"$",的确好用,但是with()函数可以省略"$"符号,甚至也可以省略数据框的名称。这个函数的使用格式如下:
with(data,expression,...)data:待处理的对象。
expression:运算公式。

对于上述示例,当R语言遇上with(iris,...)时,编译程序就知道后面的运算公式,是属于iris字段,因此运算公式可以省略对象名称,此例是省略iris。
5.3 identical()函数
identical()函数的基本作用是检测两个对象是否完全相同,如果完全相同则返回TRUE,否则返回FALSE。

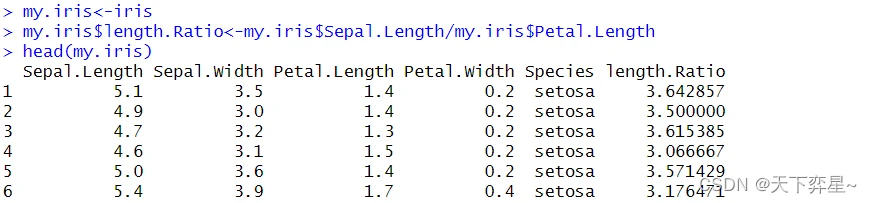
5.4 将字段运算结果存入新的字段
既然我们可以将运算结果存入1个向量内,那么我们也可以将数据框字段的运算结果存入该数据框内称为一个新的字段。
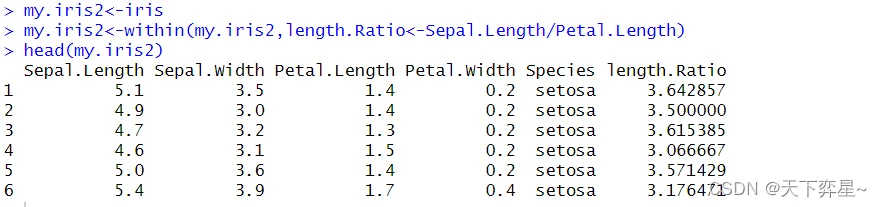
5.5 within()函数
within()函数主要用于在字段运算时将运算结果放在相同对象的新建字段上。

六、数据的分割
6.1 cut()函数
cut()函数可以将数据等量切割,切割后的数据将是因子数据类型。

看到上述用科学符号表示的数据。其实方法是将人口最多的州,减去人数最少的州,再均分成5等份。
6.2 分割数据时直接使用labels设定名称
 6.3 了解每一人口数分类有多少州
6.3 了解每一人口数分类有多少州

七、数据的合并
7.1 之前的准备工作
本节所使用的实例仍将采用R语言系统内建的数据集state.x77,这是一个含有行名称及列名称的矩阵。
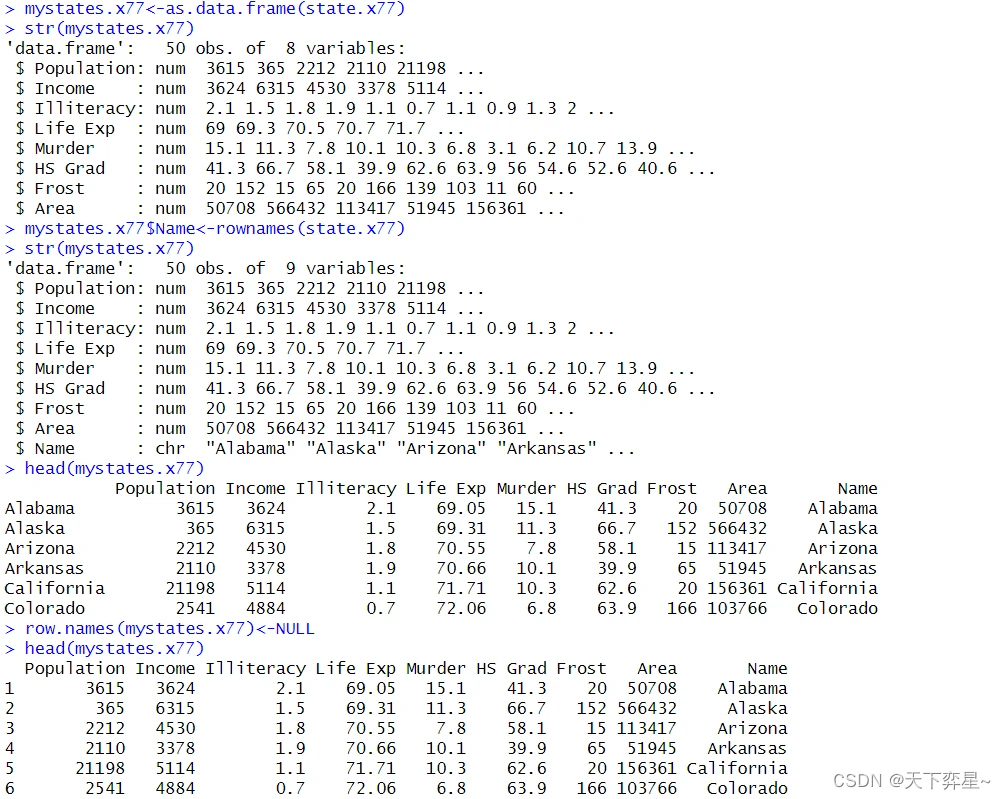
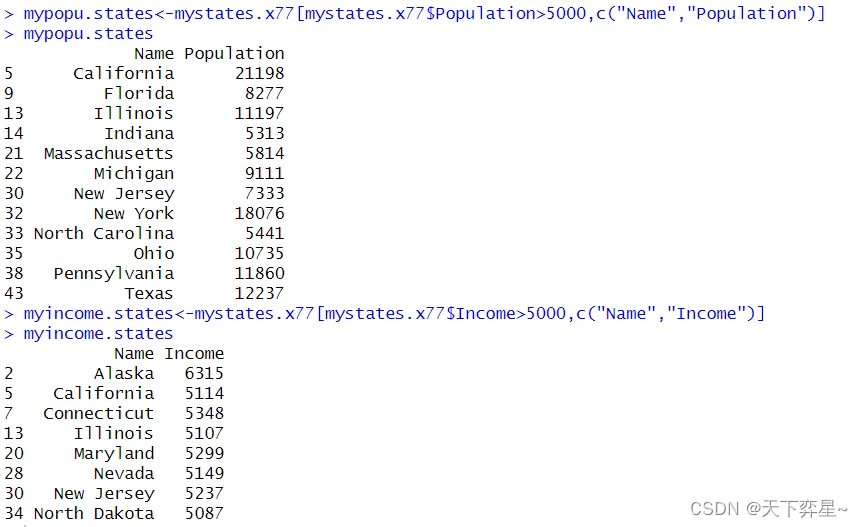 7.2 merge()函数使用于交集合并的情况
7.2 merge()函数使用于交集合并的情况
所谓交集状况是指两个条件皆符合,这个函数的基本使用格式如下:
merge(x,y,all=FALSE)x,y是要做合并的对象,默认情况是“all=FALSE",所以若省略这个参数则是代表执行的是交集的合并。

7.3 merge()函数使用于并集合并的情况
所谓并集是指两个条件有一个符合即可,此时需将参数”all=FALSE"设定为"all=TRUE"。
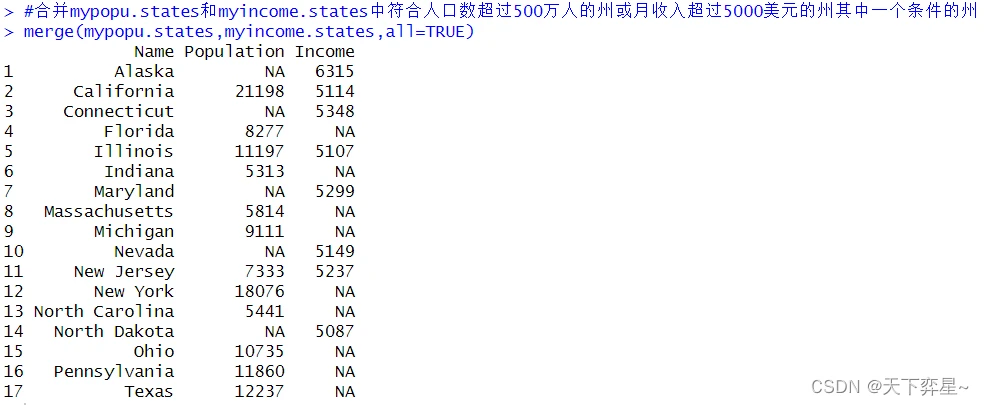
在做并集合并的过程中,原先字段不存在的数据将以NA值填充。
7.4 merge()函数参数"all.x=TRUE"
参数"all.x=TRUE",x是指merge()函数的第一个对象,使用merge()函数时若加上这个参数,则代表所有x对象的数据均在这个合并结果内,在合并结果内中原属于y对象的字段,原字段不存在的数据将以NA值填充。
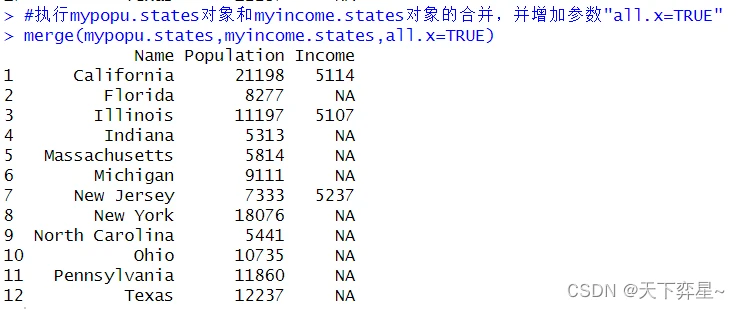
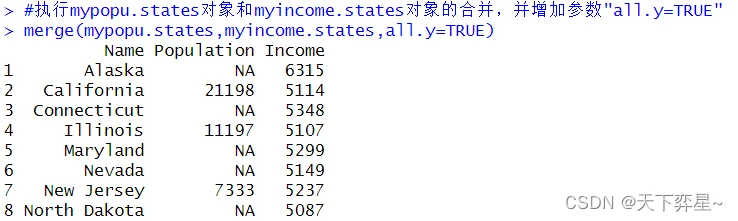
7.5 merge()函数参数"all.y=TRUE"
参数"all.y=TRUE",y是指merge()函数的第二个对象,使用merge()函数时若加上这个参数,则代表所有y对象的数据均在这个合并结果内,在合并结果内中原属于x对象的字段,原字段不存在的数据将以NA值填充。
7.6 match()函数
match()函数类似于两个对象的交集,完整解释应为,对第一个对象x的某行数据而言,若在第二对象y内找到符合条件的数据,则返回第二个对象相应数据的所在位置(可想成索引值),否则返回NA。所以调用完match()函数后会返回一个与第一个对象x的行数长度相同的向量。

7.7 %in%
使用"%in%"符号可以实现类似于前一小节match()函数的功能,不过这个符号将返回与第一个对象长度相同的逻辑向量,在向量为TRUE的元素表示我们想要的数据。
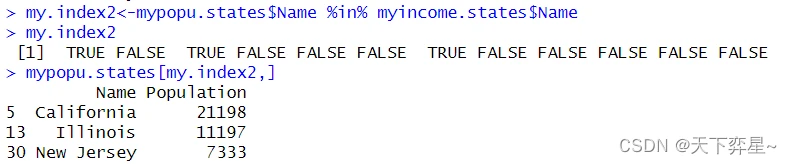
经上述实例后,对"%in%"符号更完整的解释是,当第一个对象在第二个对象内找到符合条件的值时,则传回TRUE,否则传回FALSE。
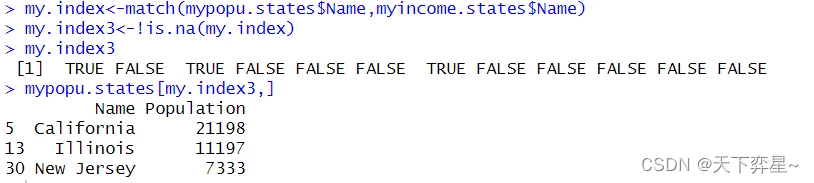
7.8 match()函数结果的调整
match()函数传回的结果时一个向量,其实也可以使用!is.na()函数,将它调整为逻辑向量。
八、数据的排序
8.1 之前准备工作
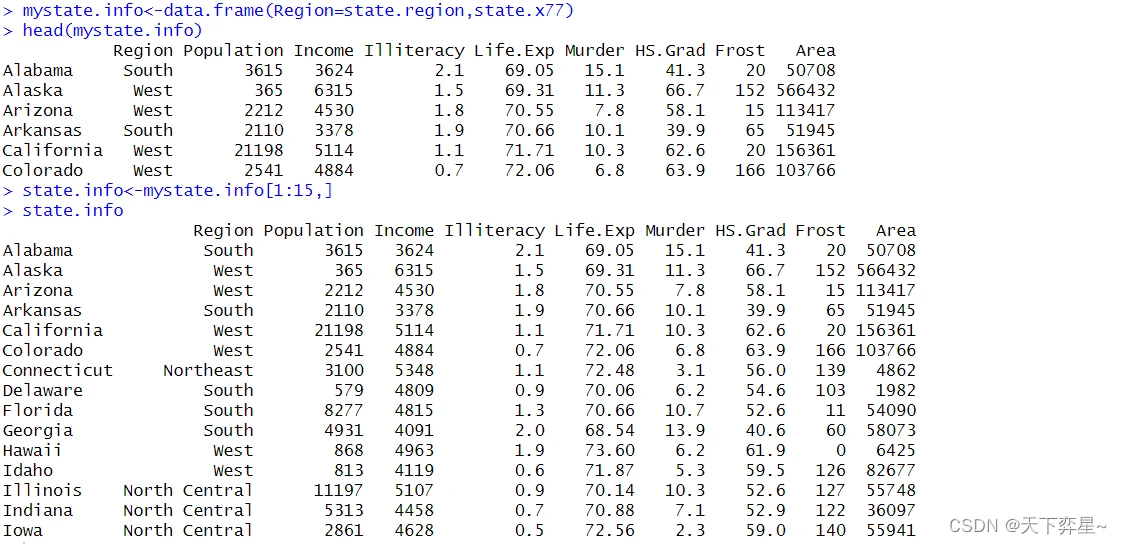
8.2 向量的排序

8.3 order()函数
order()函数也是一个排序函数,这个函数将返回排序后向量的每一个元素在原向量中的位置(索引)。
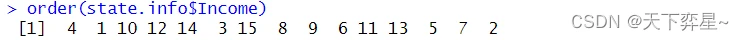

8.4 数据框的排序
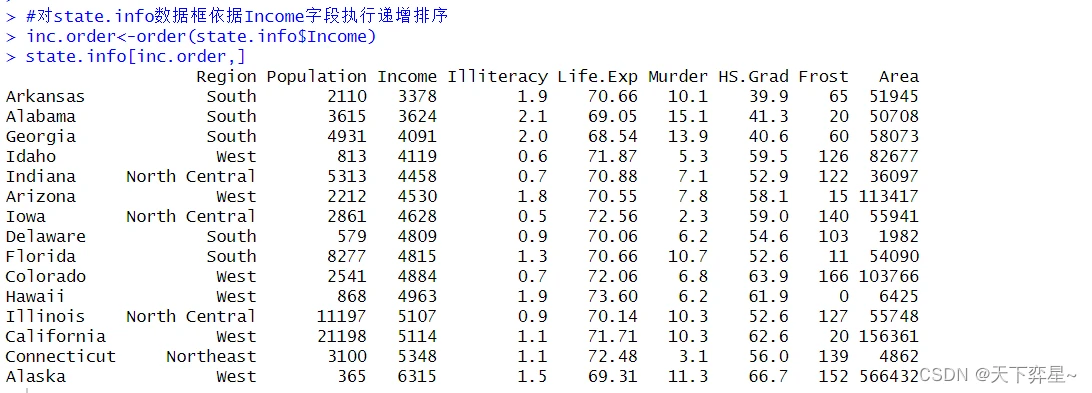
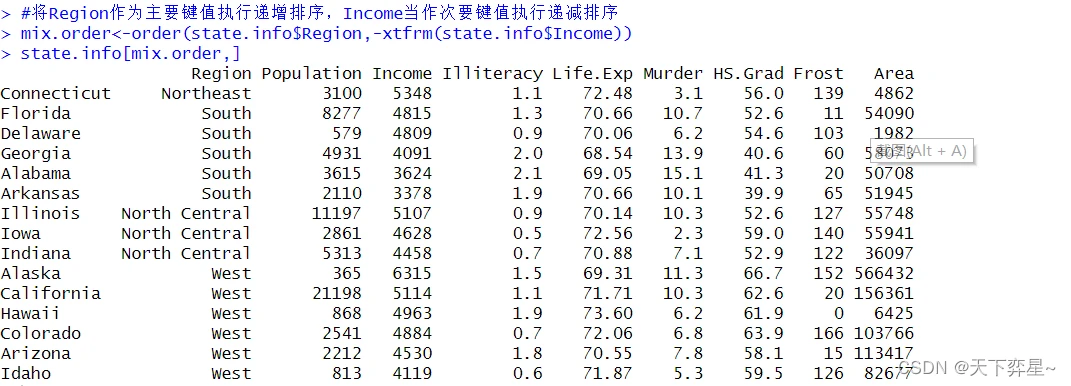
上述执行结果中,整个数据框已依照Income字段执行递增排序了。
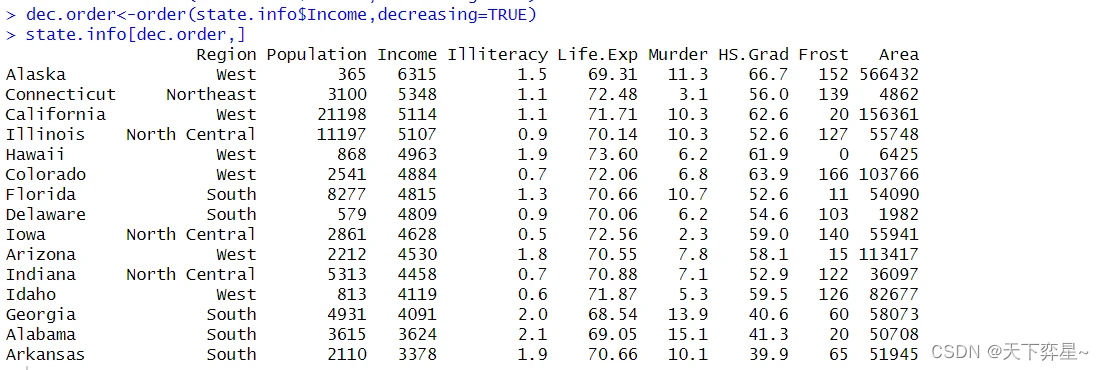 上述执行结果中,整个数据框已依照Income字段执行递减排序了。
上述执行结果中,整个数据框已依照Income字段执行递减排序了。
8.5 排序时增加次要键值的排序
在真实应用中,我们可能会面临当主要键值排序相同时,需要使用次要键值作为排序依据的情况,此时就要在order()函数内,将次要键值的字段名当作第二参数即可,此时order()函数的使用格式如下:
order(主要键值,次要键值,...) # "..."表示可以有更多其他更次要的键值 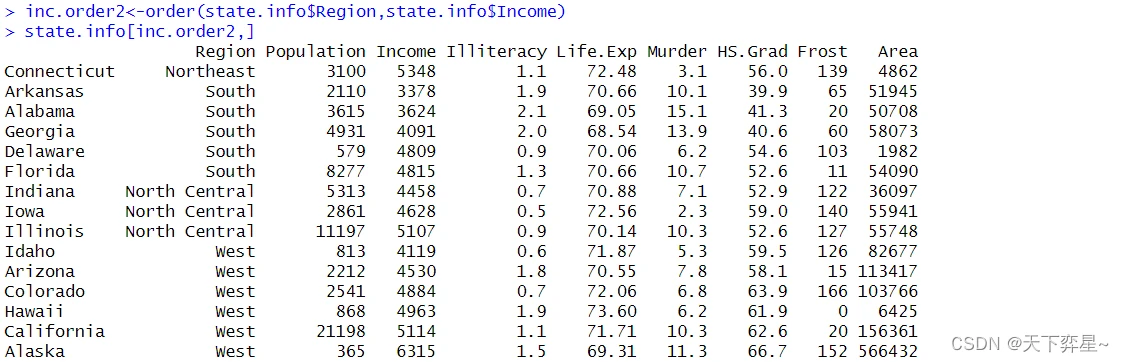
对因子而言order()函数的排序,相当于是执行Level排序。

8.6 混合排序与xtfrm()函数
有时候我们可能会想要对部分字段进行递增排序,对部分字段进行递减排序,此时可以使用xtfrm()函数。这个函数可以将原向量转成数值向量,当你想要以不同的方式排序时,只要在xtfrm()函数前加上减号(“-”)即可。
九、系统内建数据集mtcars
mtcars数据集是各种汽车发动机数据,可用str()函数了解其结构。
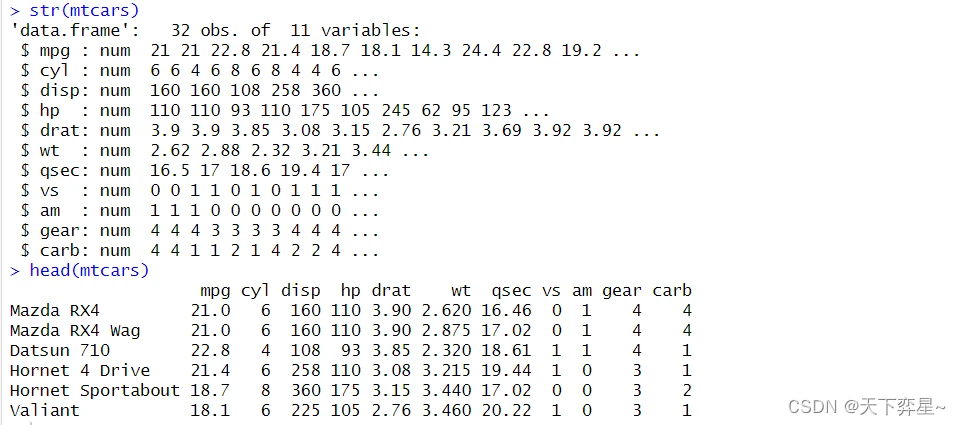
mpg:表示每加仑油可行驶的距离。
cyl:气缸数,有4、6和8三种气缸数。
am:0表示自动挡,1表示手动挡。





十、aggregate()函数
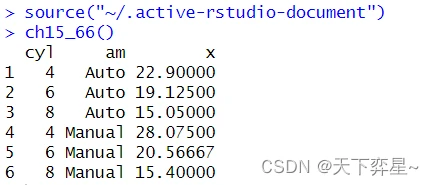
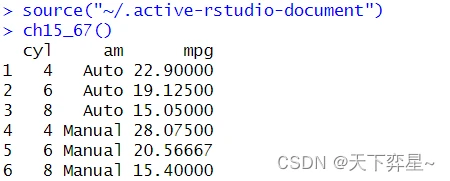
10.1 基本使用
aggregate()函数的使用格式与tapply()函数类似,但是tapply()函数可以返回列表,aggregate()函数则返回向量、矩阵或数组,它的使用格式如下:
aggregate(x,by,FUN,...)
- x:要处理的对象,通常是向量变量,也可是其他数据类型。
- by:一个或多个列表变量。
- FUN:预计使用的函数。
- ...:FUN函数所需的额外参数。

10.2 公式符号
本节的重点公式符号指的是统计学的符号,下列是一些基本的公式符号的用法。
y~a:y是a的函数。
y~a+b:y是a和b的函数。
y~a-b:y是a的函数但排除b。

十一、建立与认识数据表格
首先建立一个数据框。

11.1 认识长格式数据与宽格式数据
长格式和宽格式基本上是指相同的数据使用不同方式呈现的效果。
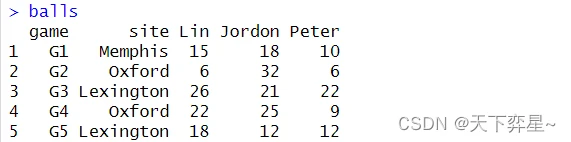
宽格式数据如下:
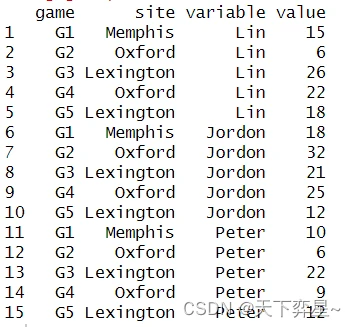
长格式数据如下:
11.2 reshape2扩展包
reshape2扩展包的主要功能是可以简单地让你执行长格式和宽格式数据的转换。
11.3 将宽格式数据转成长格式数据:melt()函数
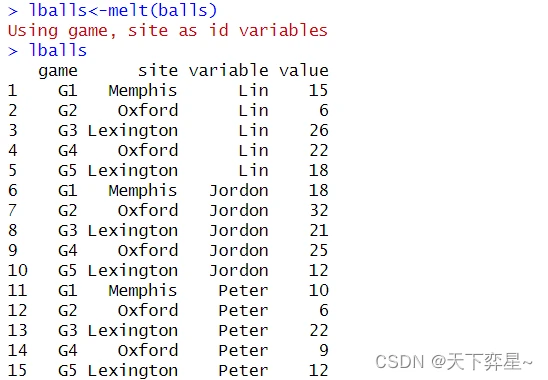
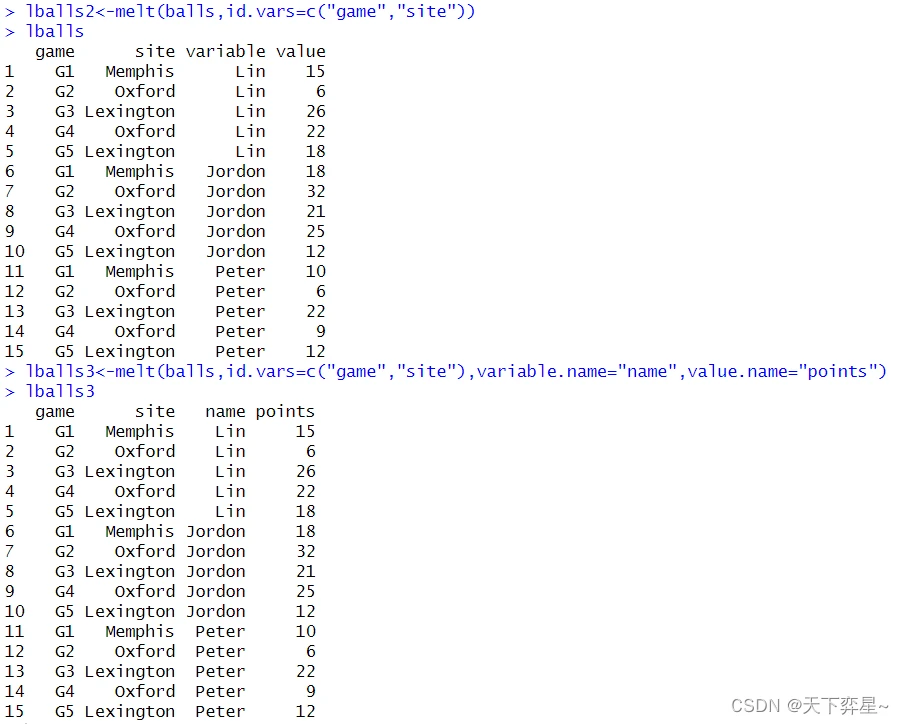
在reshape2扩展包中,将宽格式数据转成长格式数据被称为融化(melt),reshape2函数提供了melt()函数可以执行此任务,这个函数基本使用格式如下:
melt(data,...,id.vars="id.var",variable.name="variable",value.name="value")
- data:宽格式对象。
- id.vars:字段变量名称,如果省略,系统将自动抓取宽格式字段,一般也可满足需求。
- variable.name:设定variable字段变量名称,默认是"variable"。
- value.name:设定value字段变量名称,默认是"value"。
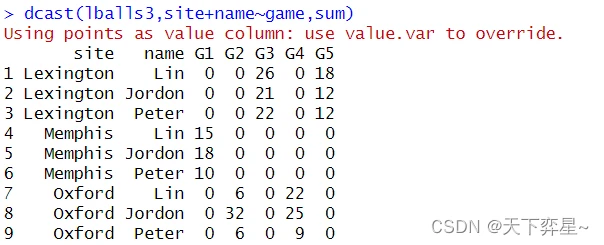
 11.4 将长格式数据转成宽格式数据:dcast()函数
11.4 将长格式数据转成宽格式数据:dcast()函数
在reshape2扩展包中,将长格式数据转成宽格式数据称重铸(cast),reshape2扩展包有提供dcast()函数可以执行此任务,这个函数是用于数据框数据的,其使用格式如下所示:
dcast(data,formula,fun.aggregate=NULL,...)
- data:长格式对象。
- formula:这个公式将指示如何重铸数据。
- fun.aggregate:利用公式执行数据重组时所使用的计算函数,常用的计算函数有sum()和mean()。
注:reshape2扩展包有提供acast()函数,使用于数组数据,将长格式转换成宽格式。

版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/1392.html