
今天给大家带来一篇曹宇兄的文章,带你进一步理解什么是大语言模型的对齐。
DPO 的论文引用最近已经破千了,成了斯坦福的Chelsea Finn组的机器人超猛PhD学生R.M. Rafailov的第一被引论文。又由于第二梯队的大模型频繁提及DPO的变种,DPO+RM的用法未来估计机器人界的思潮对于LLM的正向影响不会削弱。

按照我平时使用的体验,我们可以将当前的主要头部三强划分为第一梯队,头部开源三强划分成为第二梯队,再加上我一直比较关心的应用侧玩家Apple。
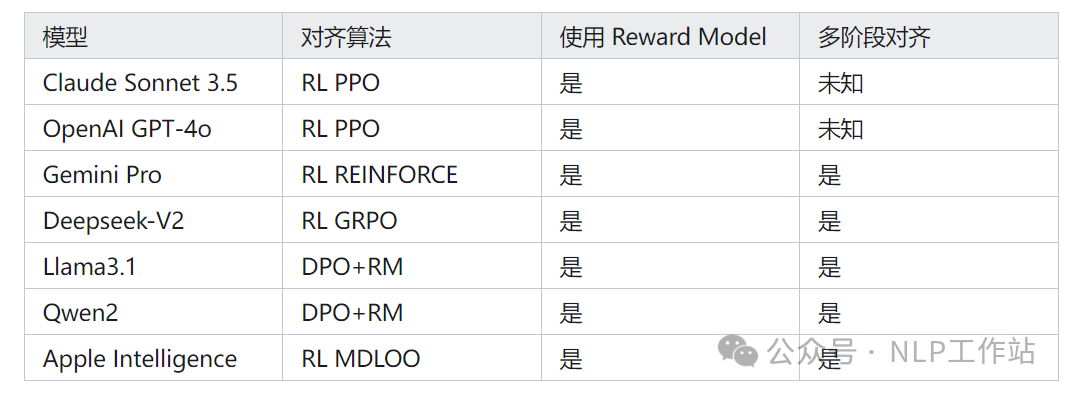
可以发现几点:
- 超头部玩家的对齐策略清一色的还是RL类方法
- 开源头部玩家采用DPO的较多
- 不论是什么PO,基本都是采用了和RM结合的xPO + RM的做法,没有纯原始DPO的玩法
- 大多数对齐玩家都使用了多阶段对齐的策略
这个其实就让很多小伙伴很疑惑了,明明DPO的宣言是Your language model is secretly a reward model,为啥在实际操作的过程中还是需要一个训练好的RM才能work呢?DPO原始论文中的做法,也是直接将偏好对在SFT之后的LLM上训练就取得了甚至超过PPO的做法,为什么在实际的实操中几乎没有头部大模型复现出来这个成果呢?同时更为让人吃惊的是DPO作为off-policy算法,原理上可以直接使用专家示教做类似imitation learning的,但是实际上几乎所有的训练范式都在朝着on-policy的方向走呢?
带着这些疑问,我们可以尝试从最近的一些非常确定的技术趋势和研究来看一看,以帮助我们真正理解什么是大语言模型的对齐,从而帮助我们在实操的过程中积累正确的技术判断能力。

我们知道在老的GAN时代,训练一个模型的方法是使用generator和discriminator对抗的方式完成的。generator尽量产生让discriminator无法判别出好坏的的样本,而discriminator D则尽量尝试识别generator G的样本。

这里面有一个细节,就是我们在利用D-G gap的时候,D和G的更新不是同步做的。D的更新在内环,第三步就做了,而G的更新在外环第五步才做。为什么要这么做呢?因为如果同时更新D和G,对抗的loss会同时反向传播到这两个网络,从梯度上来看D和G的微小gap就弥散在了整个网络里,对抗的效率容易打折扣。
那么传统的RLHF是怎么做的呢,最早版本的online PPO(InstructGPT)之前的早古版本。是通过固定训练时的discriminator实现的,generator做完整个epoch的rollout之后再样本送人标。后期由于online版本的送标成本高,就采用了offline的RM代替了人类discriminator。这种做法也是在一定时间段内固定discriminator的方式,来留给generator足够的时间机会进行偏好学习。
直接同时学习偏好(discriminator)和行为(generator)的方式在原始的DPO论文中,被认为是超越PPO学习效率和效果的一种好的方式。
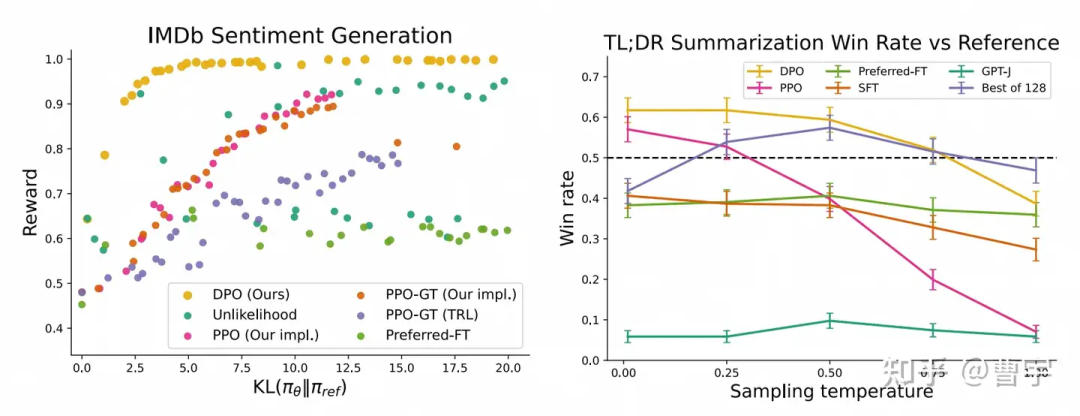
DPO在相同KL散度条件下的Reward更好,相同Temperature下的win rate更高
看起来从效果方面妥妥吊打了PPO这种比较复杂的算法,同时由于不需要训练单独的Reward Model似乎也是一个比较快见效的业务算法。
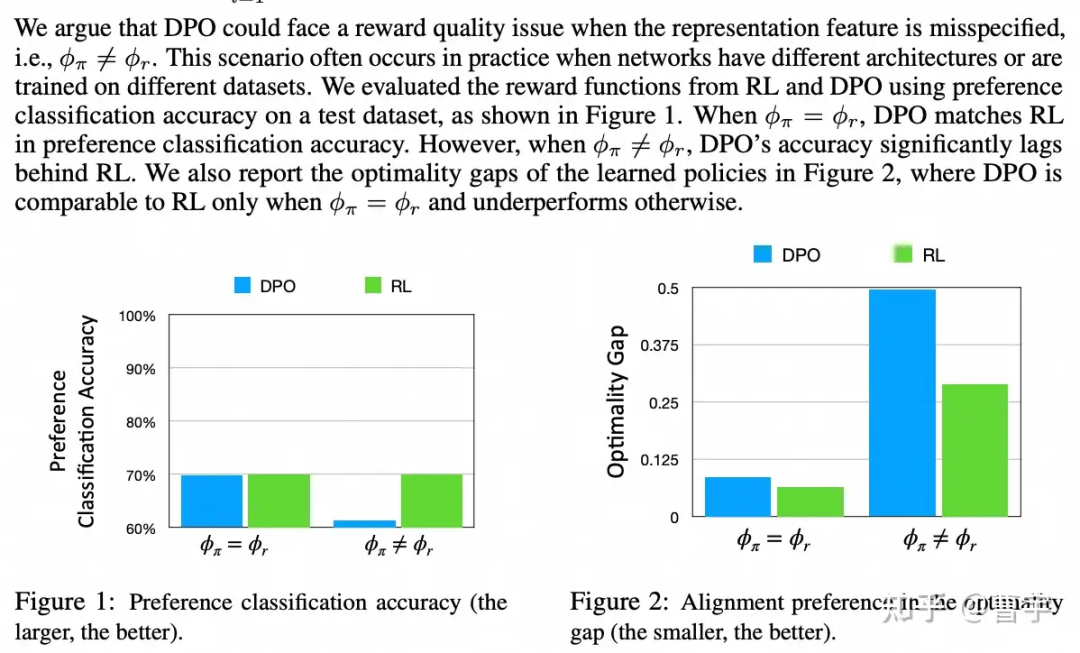
https://openreview.net/pdf?id=lNEFatlsQb
针对DPO在纸面上效果很好,打榜上效果很好,但是在实际业务中仍然需要RM辅助的状况。Ziniu博士比较早期的理论建模工作给出了一些解释:其中最主要的聚焦点在于三个(1)Reward Model建模任务的区别,(2)偏好数据不足导致的可能迁移,(3)纯离线数据推理的offline performance gap
第一点其实非常好理解,Reward Model作为一个神经网络而言,他的输入是state和action。也就是对应着之前的所有状态(对话历史),action则是模型最近一轮的输出,他的目标是输出对于state和action的reward估计。
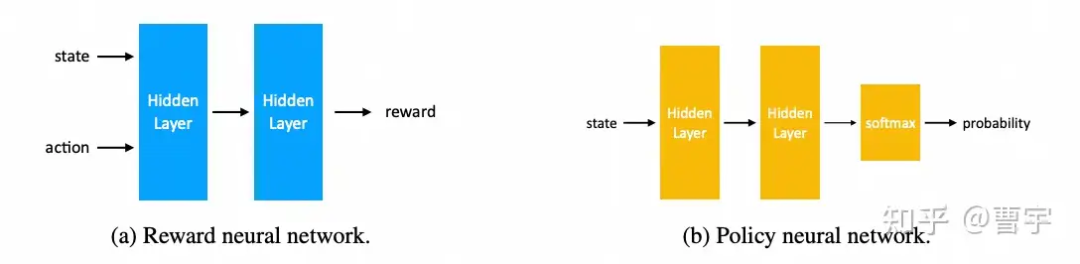
而Policy network则是根据state输出对应token的概率,再加上合适的解码策略之后,变成合适的action。这两个网络从结构上看起来就不太一样,而这种不一样正是前面讲的discriminator和generator拥有gap的基础。
第二点则是在于Reward Model本身的泛化性,使得其能够在一定程度上外插一个没有见过的state和action给出自己的reward判断。这更多的是大语言模型本身的一些能力,加上足够的领域数据泛化出来的。对于DPO而言,要同时学行为和判断就已经不容易了,还要同时学行为和判断泛化就是难上加难了。不过这里更多的是理论上的,实验上的结论后面有。
最后一点则是RL领域的基本sense,在同样on-policy的条件下训练的online程度越高,对于模型来说学习的效果越好。传统DPO采用了比较大量的数据在训练早期进行了offline inference,这样的推理虽然可以很高效地获得大量样本,但是越到训练后期这些offline数据的off-policy程度越高。会造成生产的数据与正在优化的policy之间距离过大的问题,难以取得较好的效果。
Yong Lin在Apple实习期间详细研究了DPO的泛化性问题:

这里面主要是对于刚刚第二点进行了实验中的比较和理论阐释,implicit reward model这个比较抽象,其实简单点理解就是我们采用DPO的方法直接同时学偏好和行为的方式。
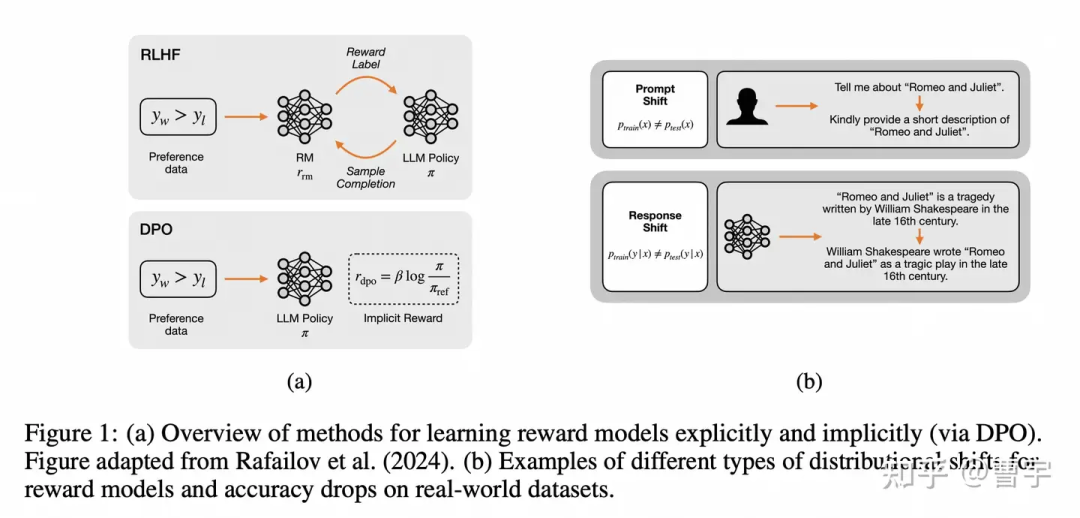
其实Apple做这种研究还是比较有道理的,对于这样海量的用户而言,用户的意图极为复杂,同时在prompt和response程度都会存在distribution shift的可能。同时目标也不是为了打各种In-distribution的榜,所以我们可以看看他的实验结论作为参考。
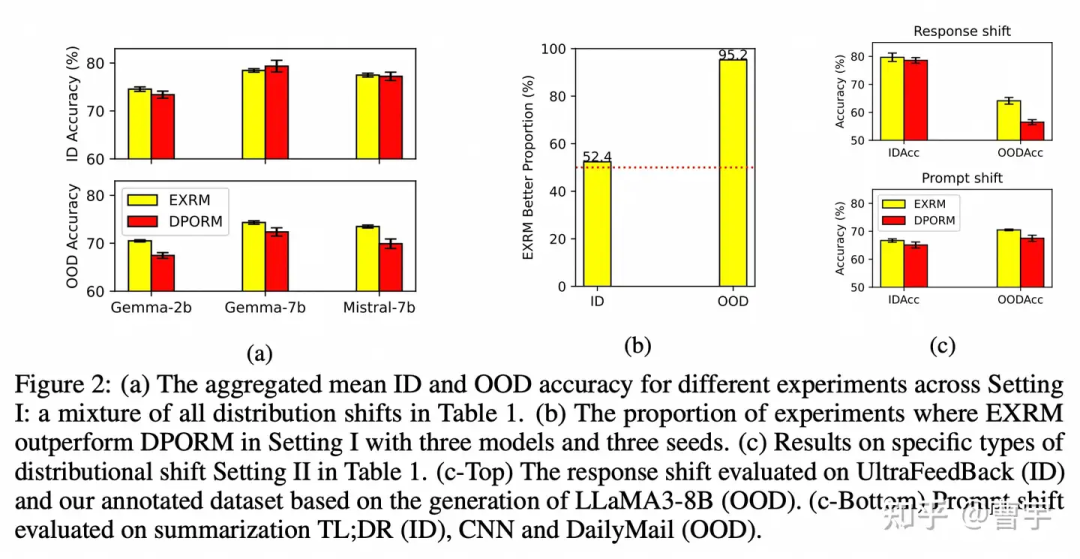
我们首先再解释一下这里造出来的概念:EXRM就是RL方法中单独训练出来的RM,DPORM是假设BT loss之后的DPO训练之后 recover出来的Reward值(DPO也可以得到reward的哦,很多同学忽视了这一点,直接拿着policy就去评测了)。
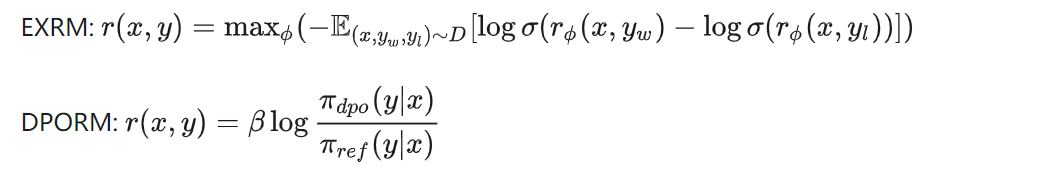
这个实验是怎么做的呢?就是在控制变量的条件下,对于这两种RM建模的方式,混合了prompt shift(Reward Model没见过这种 prompt), 以及 response shift(Reward Model 没见过这种回答)之后RM能达到的精度。可以发现用DPORM这种方式在ID(in-distribution)的混合场景里面表现的还可以。但是一旦面向OOD场景之后,RM的精度就急剧下降。同时对于OOD的response shift表现最差,难以匹配上EXRM的表现。而在控制变量的OOD变现中,EXRM比ID好95.2%。
这其实验证了刚刚讲的第二点,同时学习偏好和行为似乎没有一个专有网络专门学习偏好的效果好。尤其是我们期望的RL scaling领域,如果只能通过大量数据堆叠的方式完全覆盖偏好,是看不到做一个更通用AI系统的希望的。

Shusheng Xu 在ICML的工作就很直接,大家可以仔细研究研究。和前面的互为补充,主要谈的是用DPO学policy可能有什么问题,我仔细展开说一下里面的思路。

假设我们现在有一个待优化的policy , 他在两个可能的actions 和 的原始概率分布大概是各占一半,假设我们按照偏好 给定这个模型进行优化。理想中我们希望拉高 降低 ,其实这两种算法都能达到。但是我们特别想避免的是拉高一个分布外的 , 因为分布外的这个回答极有可能给我一个巨大的惊喜。

为什么DPO优化中允许这种情况发生呢?

因为从DPO的loss来看,这种优化目标太专注于通过压制 来获得chosen和reject的gap。对于分布外的样本其实根本不在这个优化目标的考虑范围内,如果 很好那么赚到,如果 不好,那也只能认赔。

那PPO就不会有这个问题了嘛?我们假设PPO的Reward Model就是有问题的,他就认为这个分布外的 最好。从机制上就没有什么关系,因为假设我们采样到了这个回答,由于这个回答是分布外的,所以作为KL散度约束的分母,会把KL惩罚做的极大,消除所有reward的收益。
聪明的你估计已经看到了,针对在RM的不足,最好的方式是在DPO的时候加上RM的弥补泛化性的不足。然后由于offline带来的DPO分布外的训练不足,需要尽量使得DPO的更新和迭代和PPO一样online化。从头部开源玩家的方法来看,迭代式DPO加RM似乎是一个比较奏效的打榜玩法。
但是问题就来了,DPO加了RM,加了on-policy,又加了online,好像再加一个advantage估计和baseline就是纯RL方法了。这个方法比RL还RL,为什么还叫DPO呢。
领取方式在文末
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/24654.html