
SpringBoot与数据访问
对于数据访问层,无论是SQL还是NOSQL,SpringBoot默认采用整合 Spring Data的方式进行统一处理,添加大量自动配置,屏蔽了很多设置。在这其中,SpringBoot引入各种xxxTemplate,xxxRepository来简化我们对数据访问层的操作(使用SpringBoot的JPA方式,非常方便,后面会进行讲解)。对我们来说只需要进行简单的设置即可。我们将在数据访问章节测试使用SQL相关。接下来我们将讲解SpringBoot使用如下三个数据访问方式
- JDBC
- MyBatis
- JPA
SpringBoot中使用JDBC
其实JDBC算是比较原始的数据库访问方式了,但不得不说,很多东西都是基于它进行封装的,而且还有非常多的项目喜欢使用JDBC,所以我们学习的时候,还是需要对JDBC相关进行了解,但是这里我们部队JDBC的原理进行讲解,因为已经超过了本博文的范畴了,所以我们这里只讲怎么使用,在SpringBoot中使用JDBC非常简单。这里我们使用Idea向导创建一个新项目,在勾选依赖的时候,除了照常勾选web模块之外,我们把mysql Dirver和JDBC勾选上
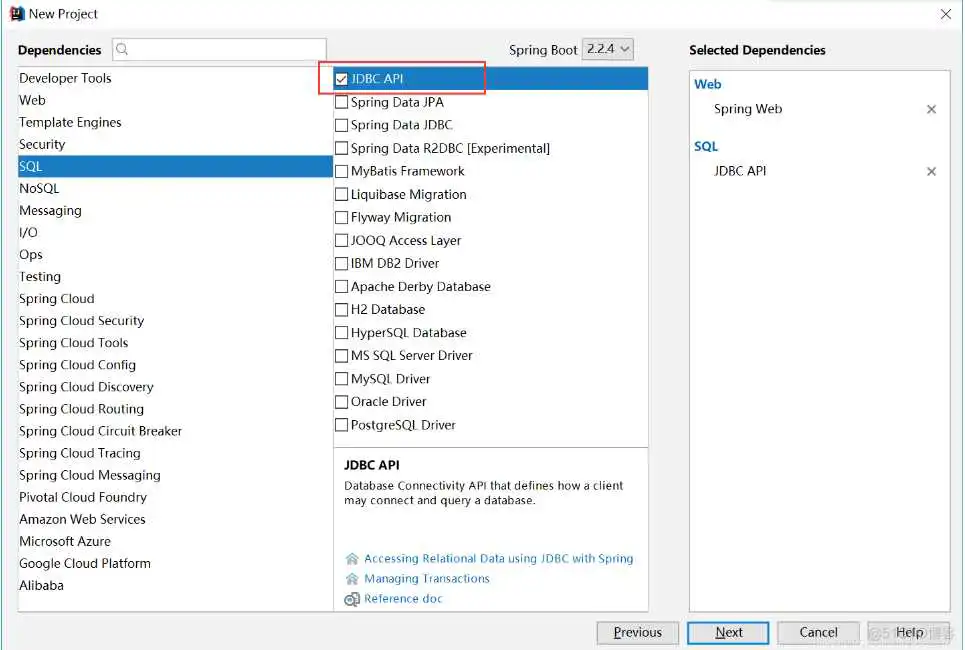
创建项目之后的pom.xml包下的内容像下面这样,当然你也可以创建Maven项目,然后按照这个引入相关依赖
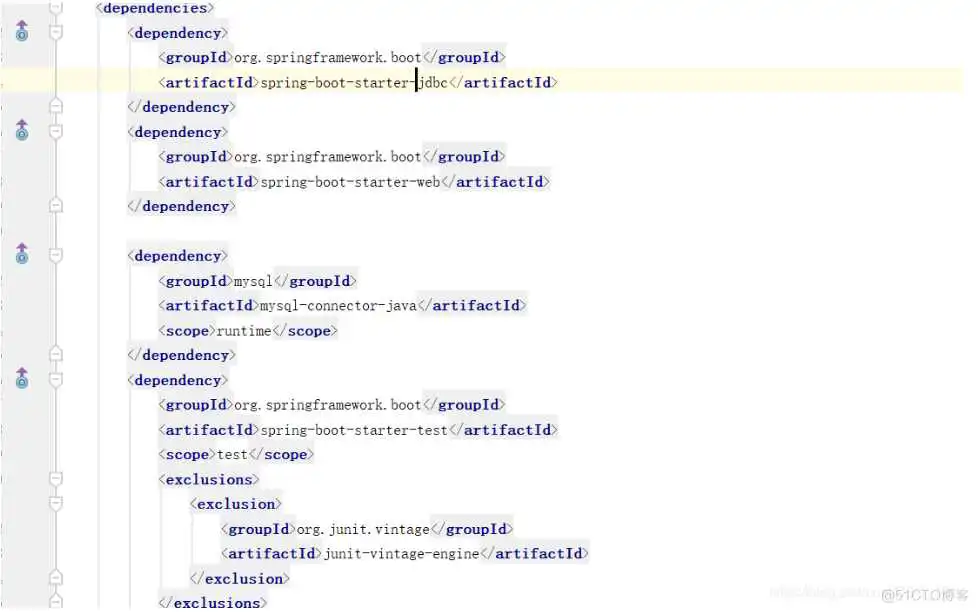
项目创建成功之后,我们怎么使用呢?非常简单,我们只需要在主配置文件中进行一些相关的配置就可以了,比如说数据库账号密码之后的,这里要说的是我们使用的是mysql关系型数据库,如下
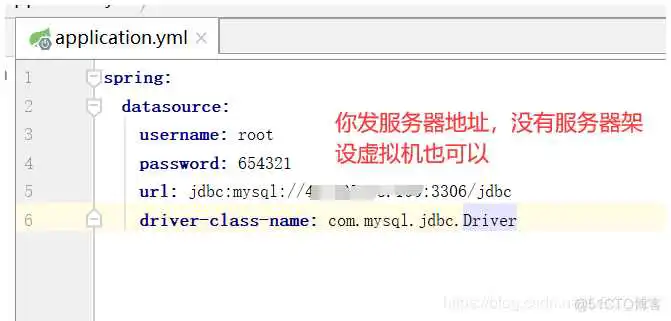
我们可以在测试类中编写下面的代码进行测试,看一下是否连接成功,没有连接成功的话就会报错,正常运行就是连接成功。

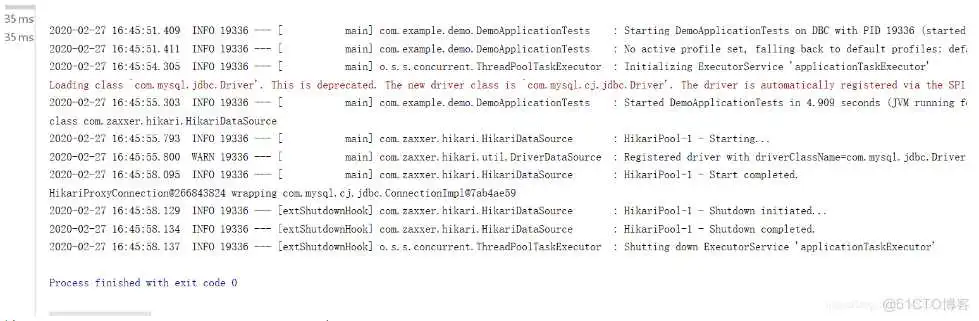
这里我们可以看到控制台输出日志,我们可以知道,SpringBoot默认使用的是class com.zaxxer.hikari.HikariDataSource作为数据源,而数据源的相关配置都在DataSourceProperties里面。
创建数据库的表,我们可以通过SpringBoot帮我们自动创建,如果我们直接在resources下创建sql且不进行任何配置文件中配置的话,我们就需要将sql进行特定的命名,才会生效,当然我们一般都会在主配置文件中进行配置的,如下
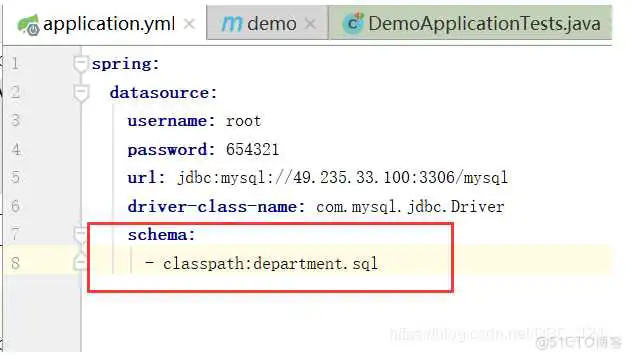
自动配置原理
首先按照惯例,还是找到jdbc的自动配置类,然后通过查阅自动配置类进行分析,而jdbc的自动配置类就是org.springframework.boot.autoconfigure.jdbc
我们可以参考DataSourceConfiguration,根据配置创建数据源,默认使用hikari连接池,其中可以使用spring.datasource.type指定自定义的数据源类型。
这里要提一下,SpringBoot默认可以支持的数据源如下,以前的SpringBoot1.x中,默认使用的是tomcat数据源,而在2.x版本中使用的是Hikari作为数据源
- org.apache.tomcat.jdbc.pool.DataSource
- HikariDataSource
- BasicDataSource
当然,既然有默认的数据源,我们当然可以进行自定义数据源类型
整合Druid数据源
SpringBoot的数据源的话,其实我这里推荐使用2.x默认的Hikari数据源,因为速度快等等优点,具体啥优点可以自己去网上查找,但是这里为了演示,我就演示怎么切换阿里的Druid数据源(Druid数据源用的也挺多的,生态不错,不过感觉停更很久了)
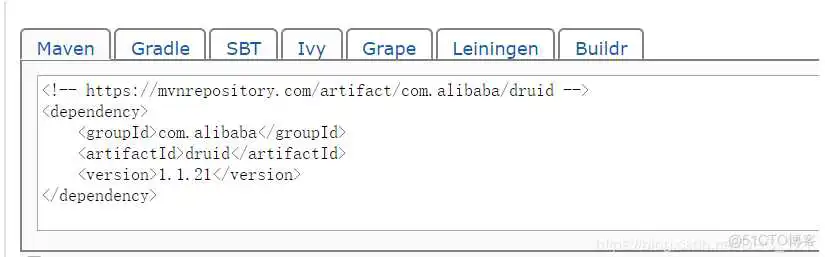
首先在项目中导入druid数据源,然后自己在config目录下创建一个专门用来控制druid的配置类,配置类的测试内容如下,在里面我配置了过滤器和监听器作为示例
第一步当然是先导入MyBatis的依赖,依赖如下
使用步骤:
- 配置数据源相关属性
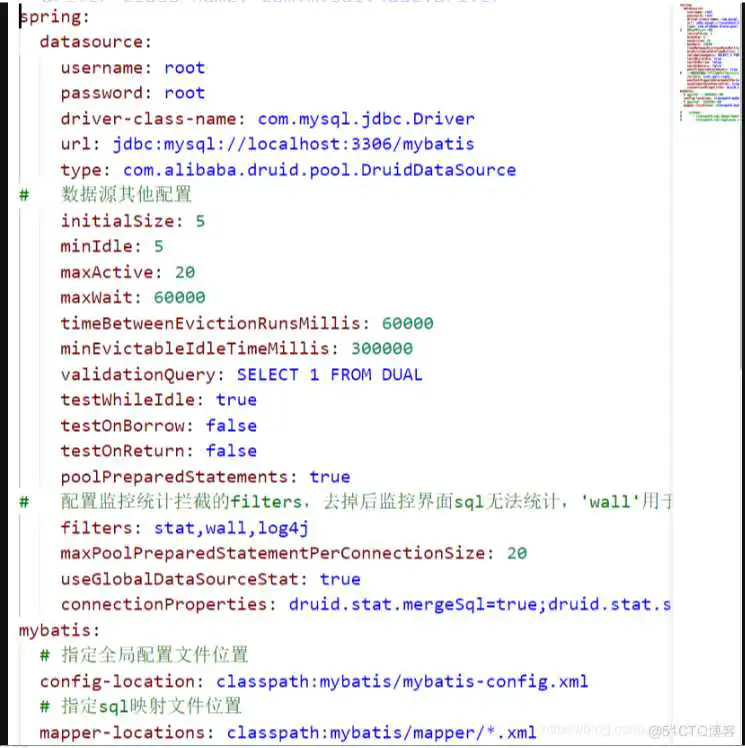
- 给数据库建表
- 创建JavaBean
如何使用注解使用Mybatis
首先在src下创建一个mapper包,然后包下创建对应实体的mapper接口,像下面这样
然后我们只需要通过对应的配置文件,就可以使用,因为SpringBoot有着自定义MyBatis的配置规则,给容器中添加一个ConfigurationCustomizer,使用MapperScan批量扫描所有的Mapper接口。
使用配置文件
SpringBoot整合SpringData JPA
SpringData为我们提供使用统一的API来对数据访问层进行操作;这主要是Spring Data Commons项目来实现的。Spring Data Commons让我们在使用关系型或者非关系型数据访问 技术时都基于Spring提供的统一标准,标准包含了CRUD(创建、获取、更新、删除)、查询、 排序和分页的相关操作。
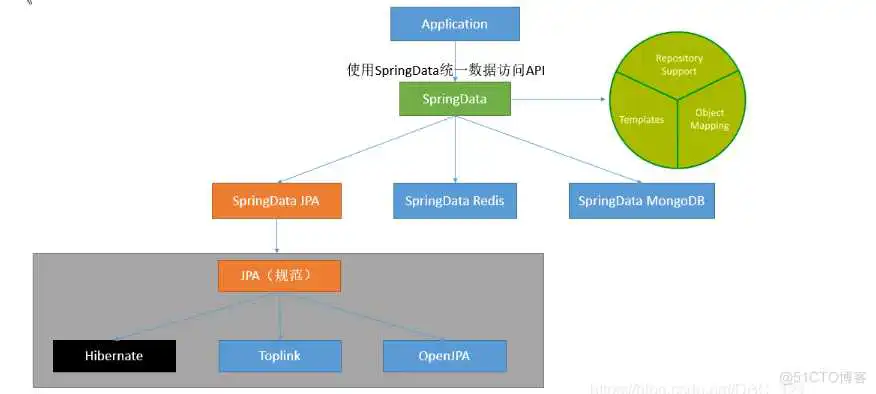
而且SpringDataJPA有着统一的Repository接口如Repository<T, ID extends Serializable>统一接口、 RevisionRepository<T, ID extends Serializable, N extends Number & Comparable>基于乐观 锁机制、CrudRepository<T, ID extends Serializable>基本CRUD操作、PagingAndSortingRepository<T, ID extends Serializable>:基本CRUD及分页
整合SpringData JPA
还是老样子,先引入我们的依赖,引入依赖之后,和原先的数据访问方式不同的是,我们可以编写一个实体类(bean)和数据表进行映射,并且配置好映射关系;
创建好实体类并配置好映射关系之后,我们接着编写一个Dao接口来操作实体类对应的数据表(Repository)
注意了,我们jpa默认使用的hibernate,所以我们可以在配置文件中进行如下基本的配置
到此这篇swagger文档访问地址(swagger接口文档怎么访问)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/29319.html