
目录
- 梯度下降算法推导
- 优化算法的理解和Python实现
- SGD
- Momentum
- Nestrov
- AdaGrad
- RMSprop
- Adam
- 算法的表现
1
梯度下降算法推导
模型的算法就是为了通过模型学习,使得训练集的输入获得的实际输出与理想输出尽可能相近。极大似然函数的本质就是衡量在某个参数下,样本整体估计和真实情况一样的概率,交叉熵函数的本质是衡量样本预测值与真实值之间的差距,差距越大代表越不相似
1. 为什么要最小化损失函数而不是最大化模型模型正确识别的数目?
2. 如何推导梯度下降?为什么梯度下降的更新方向是梯度的负方向?
下面开始推导
2
优化算法的理解和Python实现
- 计算目标函数关于当前参数的梯度:
- 根据历史梯度计算一阶动量和二阶动量:
- 计算当前时刻的下降梯度:
- 根据下降梯度进行更新:
掌握了这个框架,你可以轻轻松松设计自己的优化算法。步骤3、4对于各个算法都是一致的,主要的差别就体现在1和2上。
注:下面的内容大部分取自引用【2】和【3】
3
SGD
随机梯度下降法不用多说,每一个参数按照梯度的方向来减小以追求最小化损失函数,梯度下降法目前主要分为三种方法,区别在于每次参数更新时计算的样本数据量不同:批量梯度下降法(BGD, Batch Gradient Descent),随机梯度下降法(SGD, Stochastic Gradient Descent)及小批量梯度下降法(Mini-batch Gradient Descent)。
SGD缺点
- 选择合适的learning rate比较困难 ,学习率太低会收敛缓慢,学习率过高会使收敛时的波动过大
- 所有参数都是用同样的learning rate
- SGD容易收敛到局部最优,并且在某些情况下可能被困在鞍点
更新方式

Python实现
4
Momentum
更新方式

Python实现
5
Nestrov
Nestrov也是一种动量更新的方式,但是与普通动量方式不同的是,Nestrov为了加速收敛,提前按照之前的动量走了一步,然后求导后按梯度再走一步。
更新方式

但是这样一来,就给实现带来了很大的麻烦,因为我们当前是在W的位置上,无法求得W+αv处的梯度,所以我们要进行一定改变。由于W与W+αv对参数来说没有什么区别,所以我们可以假设当前的参数就是W+αv。就像下图,按照Nestrov的本意,在0处应该先按照棕色的箭头走αv到1,然后求得1处的梯度,按照梯度走一步到2。
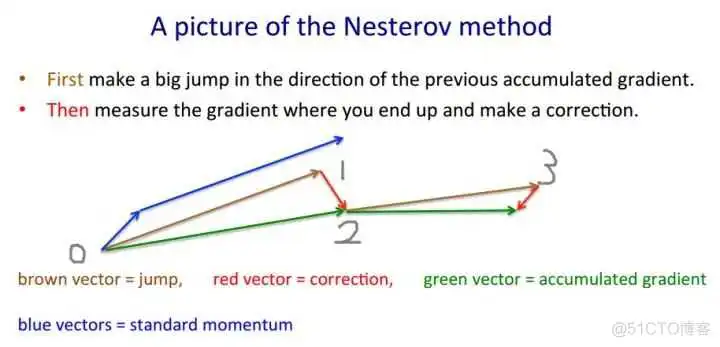
现在,我们假设当前的W就是1处的参数,但是,当前的动量v仍然是0处的动量,那么更新方式就可以写作:

为了便于理解, W和v的更新可以看做是 空间中向量相加 的方式,这样一来,动量v就由0处的动量更新到了下一步的2处的动量。但是下一轮的W相应的应该在3处,所以W还要再走一步αv,即完整的更新过程应该如下所示:

第二行的v是第一行更新的结果,为了统一v的表示,更新过程还可以写作:
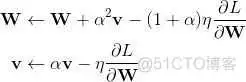
Python实现
但是根据我看到的各个框架的代码,它们好像都把动量延迟更新了一步,所以实现起来有点不一样(或者说是上下两个式子的顺序进行了颠倒),我也找不到好的解释,但是在MNIST数据集上最终的结果要好于原来的实现。
Python实现
6
Adagrad
前面介绍了几种动量法,动量法旨在通过每个参数在之前的迭代中的梯度,来改变当前位置参数的梯度,在梯度稳定的地方能够加速更新的速度,在梯度不稳定的地方能够稳定梯度。
而AdaGrad则是一种完全不同的思路,它是一种自适应优化算法。它通过每个参数的历史梯度,动态更新每一个参数的学习率,使得每个参数的更新率都能够逐渐减小。前期梯度加大的,学习率减小得更快,梯度小的,学习率减小得更慢些。
Adagrad缺点
- 仍需要手工设置一个全局学习率
- , 如果
- 设置过大的话,会使regularizer过于敏感,对梯度的调节太大
- 中后期,分母上梯度累加的平方和会越来越大,使得参数更新量趋近于0,使得训练提前结束,无法学习
更新方式

其中δ用于防止除零错
Python实现
7
RMSprop
AdaGrad有个问题,那就是学习率会不断地衰退。这样就会使得很多任务在达到最优解之前学习率就已经过量减小,所以RMSprop采用了使用指数衰减平均来慢慢丢弃先前的梯度历史。这样一来就能够防止学习率过早地减小。
RMSprop特点
- 其实RMSprop依然依赖于全局学习率
- RMSprop算是Adagrad的一种发展,和Adadelta的变体,效果趋于二者之间
- 适合处理非平稳目标——对于RNN效果很好
更新方式:
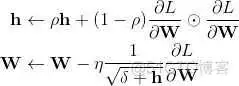
Python实现
8
Adam
Adam方法结合了上述的动量(Momentum)和自适应(Adaptive),同时对梯度和学习率进行动态调整。如果说动量相当于给优化过程增加了惯性,那么自适应过程就像是给优化过程加入了阻力。速度越快,阻力也会越大。
Adam首先计算了梯度的一阶矩估计和二阶矩估计,分别代表了原来的动量和自适应部分
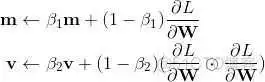
β_1 与 β_2 是两个特有的超参数,一般设为0.9和0.999。
但是,Adam还需要对计算出的矩估计进行修正

其中t是迭代的次数,修正的原因在

这个问题中有非常详细的解释。简单来说就是由于m和v的初始值为0,所以第一轮的时候会非常偏向第二项,那么在后面计算更新值的时候根据β_1 与 β_2的初始值来看就会非常的大,需要将其修正回来。而且由于β_1 与 β_2很接近于1,所以如果不修正,对于最初的几轮迭代会有很严重的影响。
最后就是更新参数值,和AdaGrad几乎一样,只不过是用上了上面计算过的修正的矩估计

Adam特点
- Adam梯度经过偏置校正后,每一次迭代学习率都有一个固定范围,使得参数比较平稳。
- 结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
- 为不同的参数计算不同的自适应学习率
- 也适用于大多非凸优化问题——适用于大数据集和高维空间。
为了使得Python实现更加简洁,将修正矩估计代入原式子,也就是重新表达成只关于m和v的函数,修改如下
python实现
9
算法的表现
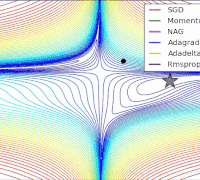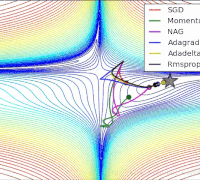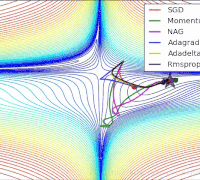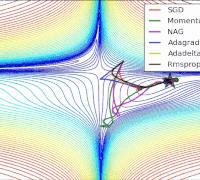
各个算法在等高线的表现,它们都从相同的点出发,走不同的路线达到最小值点。可以看到,Adagrad,Adadelta和RMSprop在正确的方向上很快地转移方向,并且快速地收敛,然而Momentum和NAG先被领到一个偏远的地方,然后才确定正确的方向,NAG比momentum率先更正方向。SGD则是缓缓地朝着最小值点前进。
参考文献
- Juliuszh:一个框架看懂优化算法之异同 SGD/AdaGrad/Adam
- 深度学习中的优化算法(Optimizer)理解与python实现
- 优化算法Optimizer比较和总结
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/33721.html