
论文:Deep Residual Learning for Image Recognition
ResNet网络中的亮点:
- 超深的网络结构(突破1000层)
- 提出residual模块
- 使用Batch Normalization加速训练(丢弃dropout)
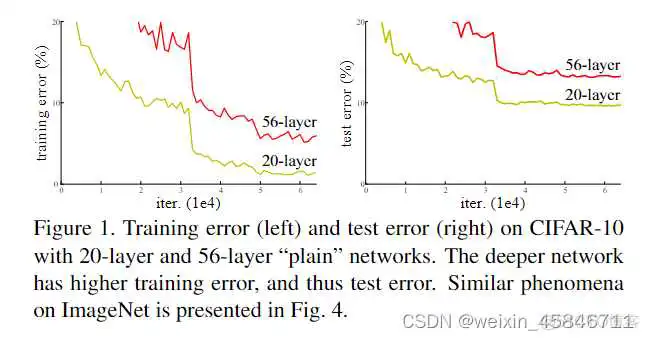
论文中提到,简单的堆叠卷积层与池化层并不能降低错误率,通过堆叠卷积层与池化层,会带来梯度消失或梯度爆炸、退化问题。
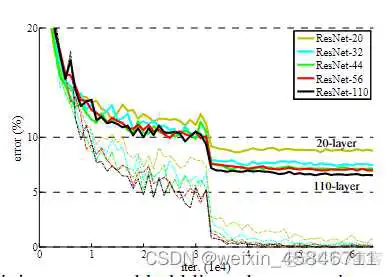
ResNet不同的网络结构的错误率如下所示:
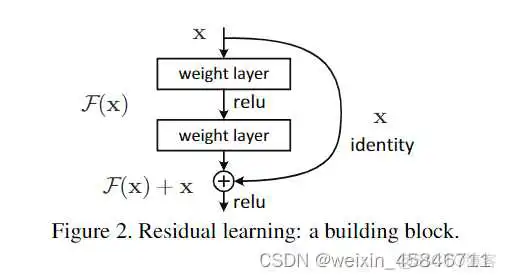
网络中残差结构如下所示:
主分支与shortcut的输出特征矩阵shape必须相同。
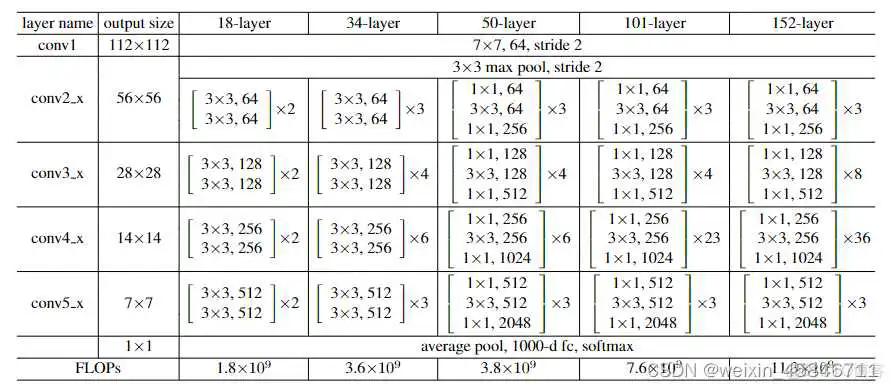
不同层数的ResNet网络结构对比如下:
Batch Normalization
Batch Normalization的目的是使一批(Batch)feature map满足均值为0,方差为1的分布规律。它可以加速网络的训练,还可以提升准确率。
使用BN时需要注意的问题:
(1)训练时要将training参数设置为True,验证时将training参数设置为False,在pytorch中可以通过创建模型的model.train()和model.eval()控制。
(2)batch.size尽可能大,设置的越大求得均值和方差越接近整个训练集的均值和方差。
(3)建议将BN层放到卷积层与激活层之间,且卷积层不要使用bias。
迁移学习:
使用迁移学习的优势:
(1)能够快速的训练出一个理想的效果
(2)当数据集较小时,也能训练出理想的效果
常见的迁移学习的方式:
(1)载入权重后训练所有参数
(2)载入权重后只训练最后几层参数
(3)载入权重后在原网络基础上再添加一层全连接层,仅训练最后一个全连接层
论文:Aggregated Residual Transformations for Deep Neural Networks
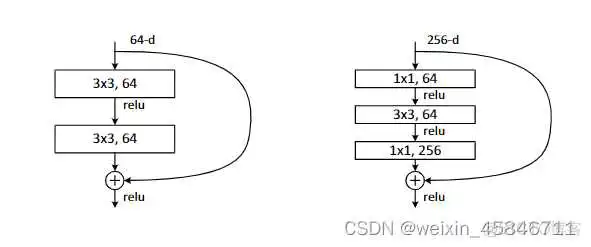
ResNeXt相比于ResNet来说,更新了block。
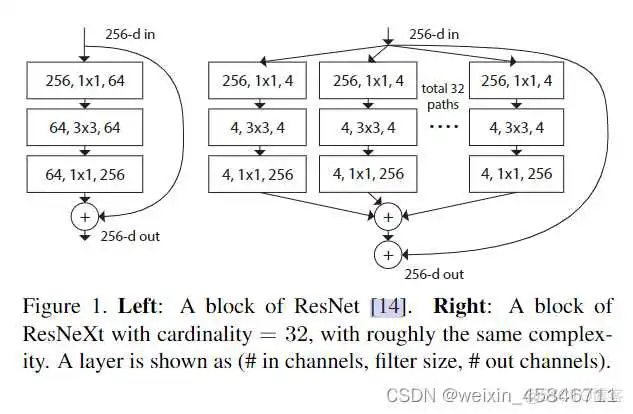
左图是ResNet中的一个block,右图是ResNeXt中的block。ResNeXt中使用Group Convolution,使用的参数量更小。
ResNeXt在计算量相同的情况下,错误率更低。
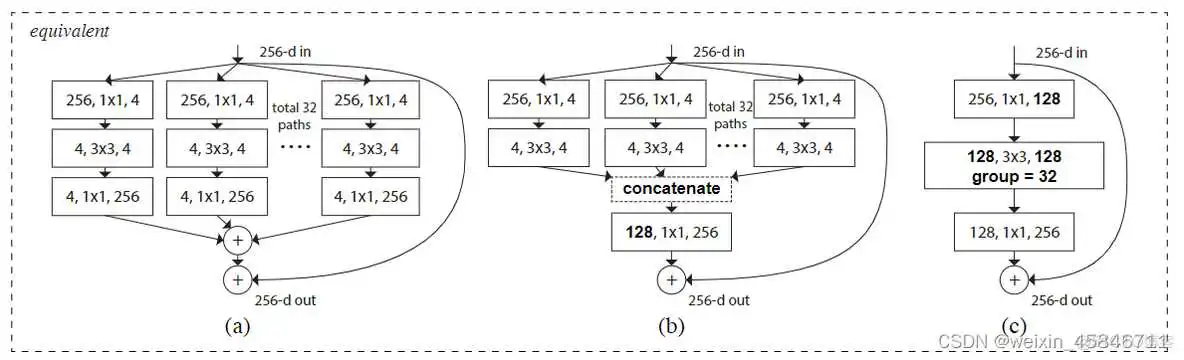
上面这三种结构在数学计算上是等价的。
不过分组卷积并不是分组数量越多越好。
首先使用LeNet网络进行训练。
由于数据集比较大,训练时间比较长,本次采用了老师之前博客里提供的2000张训练图片的小数据集。
首先加载数据集:

引入必要的库

添加训练图片和测试图片的路径

创建数据集

定义网络

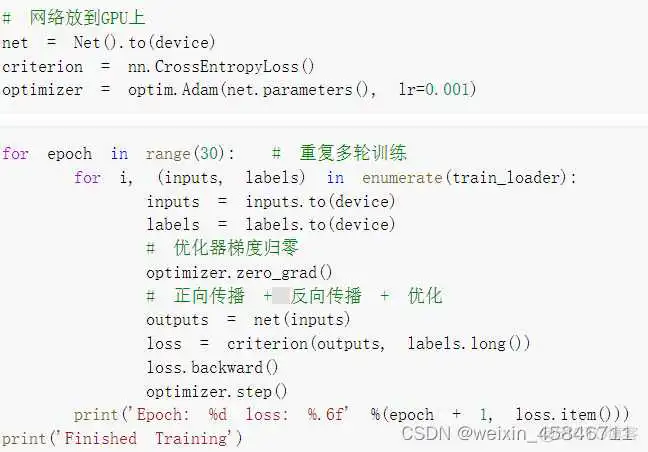
把网络放到GPU上开始训练
进行测试并导出结果文件
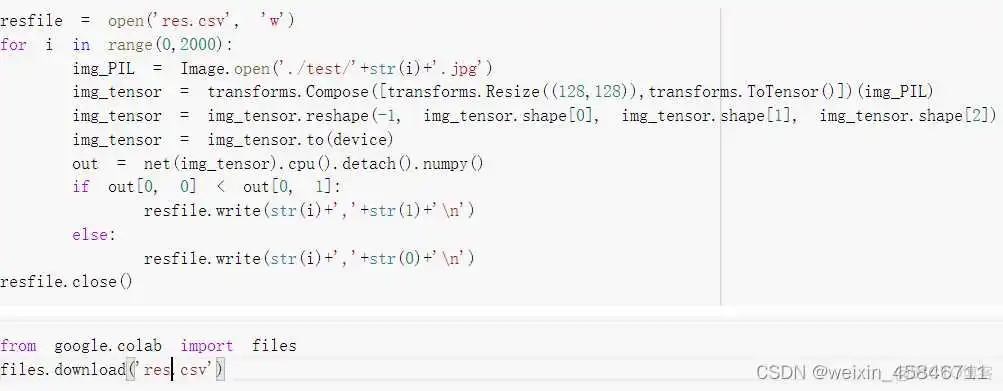
提交结果为:

将网络结构改为ResNet,这里使用了ResNet18:

提交结果为:

可以看出,ResNet网络在分类问题上具有明显优势。
到此这篇resnet模型的优缺点(resnet网络模型)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/47730.html