
Puppeteer是一款专业的 Node.js 库,相当于一个可以用来操控Chrome的API,它可以用到的场景很多,如它具有强大的爬虫功能,有点类似于PhantomJS,用来在网站抓取内容非常不错,有需要的朋友欢迎使用。
Puppeteer核心功能:
利用网页生成PDF、图片
爬取SPA应用,并生成预渲染内容(即“SSR” 服务端渲染)
可以从网站抓取内容
自动化表单提交、UI测试、键盘输入等
帮你创建一个最新的自动化测试环境(chrome),可以直接在此运行测试用例
捕获站点的时间线,以便追踪你的网站,帮助分析网站性能问题
Puppeteer 0.13改变如下:
Chroium 64.0.3264.0 (r)
browser.pages 可用于访问 Chromium 中的所有页面,包括由 window.open 创建的页面。 (32398d1)
browser.close 可用于关闭 Chromium (2b79514)
Puppeteer爬虫教学:
使用puppeteer.launch()运行puppeteer,他会return一个promise,使用then方法获取browser实例,Browser API猛击这里
拿到browser实例后,通过browser.newPage()方法,可以得到一个page实例, 猛戳 Page API
使用page.goto()方法,跳转至ES6标准入门
在page.evaluate()方法中注册回调函数,并分析dom结构,从下图可以进行详细分析,并通过
document.querySelectorAll('ol li a')拿到文章的所有链接
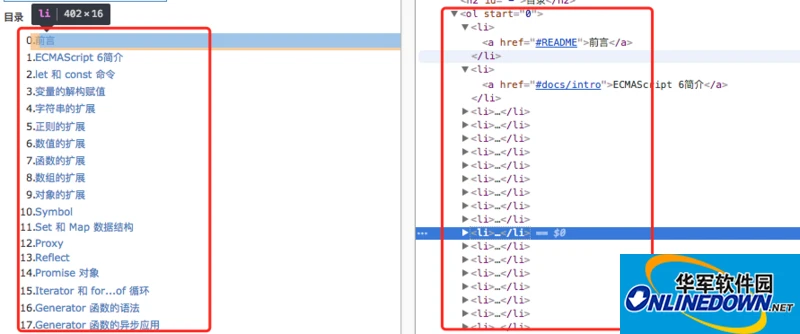
拿到所有链接之后,依次爬取各个页面(也可以promise all同时抓取多个页面),使用page.pdf()方法打印当前页面
核心代码如下:
puppeteer.launch().then(async browser => {
let page = await browser.newPage();
await page.goto('http://es6.ruanyifeng.com/#README');
await timeout(2000);
let aTags = await page.evaluate(() => {
let as = [...document.querySelectorAll('ol li a')];
return as.map((a) =>{
return {
href: a.href.trim(),
name: a.text
}
});
});
await page.pdf({path: `http://www.onlinedown.net/soft/es6-pdf/${aTags[0].name}.pdf`});
page.close()
// 这里也可以使用promise all,但cpu可能吃紧,谨慎操作
for (var i = 1; i < aTags.length; i++) {
page = await browser.newPage()
var a = aTags[i];
await page.goto(a.href);
await timeout(2000);
await page.pdf({path: `http://www.onlinedown.net/soft/es6-pdf/${a.name}.pdf`});
page.close();
}
browser.close();
});
到此这篇hippter官网下载(hipee下载)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/49154.html