
- 作业①
- 作业②
- 作业③
- 遇到的问题及解决方法
- 总结
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
Gitee文件夹链接
1、代码思路
(1)解析响应:
定义 parse 方法,使用 CSS 选择器提取网页中所有图片的 src 属性。response.css('img::attr(src)').getall() 返回一个包含所有图片 URL 的列表。
(2)处理图片 URL:
遍历提取到的图片 URL 列表。
使用 urljoin 方法将相对 URL 转换为绝对 URL,确保可以访问。
验证 URL 是否以 http 开头,以确认其有效性:
如果是有效的 URL,则创建一个 WeatherItem 对象,将图片 URL 存入该对象,并通过 yield 语句返回该项,供 Scrapy 后续处理。
如果 URL 无效,使用 self.logger.warning 记录一条警告信息,表明该 URL 被跳过。
(3)用户代理:
USER_AGENT:模拟真实的浏览器访问,以避免被网站识别为爬虫。这里使用了 Chrome 浏览器的最新用户代理字符串,以提高访问成功率。
(4)并发请求:
(5)请求延迟:
(6)图片管道:
ITEM_PIPELINES:激活图片处理管道。
'weather_scraper.pipelines.WeatherImagesPipeline': 300 表示图片处理管道的路径和优先级。优先级数值越低,越先执行。
WeatherImagesPipeline 管道可以处理和下载图片,将提取的图片保存到本地。
get_media_requests(self, item, info) 方法用于从爬取的 item 中提取图片 URL,并生成下载请求。
2、重要代码部分
点击查看代码
提取页面上所有图片的 src 属性,转换为绝对 URL,验证其有效性。有效的图片 URL 被存入 WeatherItem 并通过 yield 返回,以便后续处理;无效的 URL 则记录警告信息。
点击查看代码
在settings.py文件中修改多线程设置
3、运行结果
进行爬取时终端输出如下:
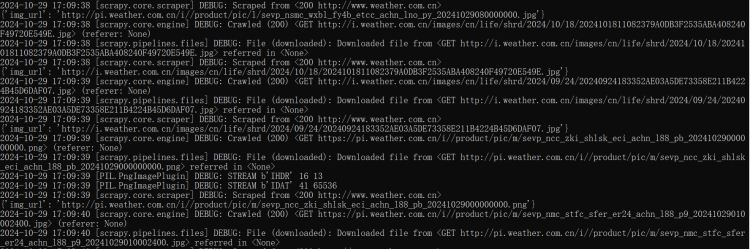
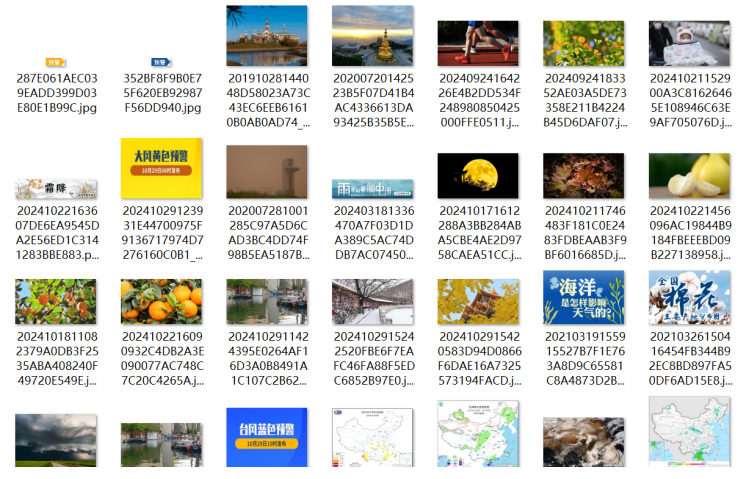
最后图片保存在本地文件夹:
在实现该实验过程中,使用 Scrapy 提供的单线程和多线程设置可以有效控制并发爬取。多线程方式可以显著提高图片下载速度,但应注意设置下载延迟,以避免过多的并发请求对服务器造成压力。
- 熟练掌握scrapy中Item、Pipeline数据的序列化输出方法;
- 掌握Scrapy+XPath+MySQL数据库存储技术路线爬取股票相关信息。
- 东方财富网:https://www.eastmoney.com/
- 新浪股票:http://finance.sina.com.cn/stock/
MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:

1、代码思路
(1)环境准备:
安装 Scrapy 和 MySQL 数据库驱动(如 mysql-connector-python)。
准备一个 MySQL 数据库,并创建相应的表结构以存储爬取的数据。
(2)创建 Scrapy 项目:
使用 scrapy startproject stock_scraper 创建项目。
创建爬虫、items 和 pipelines 文件。
(4)编写爬虫:
在 spiders 目录中创建 stock_spider.py。
使用 Scrapy 提供的选择器(XPath)提取网页中的股票数据,并实现翻页功能。
(5)实现数据存储:
在 pipelines.py 中定义数据处理管道,连接 MySQL 数据库并将爬取到的数据插入数据库表中。
在 settings.py 中配置数据库连接信息。
2、重要代码部分
点击查看代码
解析响应的 JSON 数据,从中提取股票信息列表 stock_list,遍历提取到的股票数据,将所需字段存入 StockItem 实例,并通过 yield 返回给 Scrapy 进行后续处理。
点击查看代码
在爬虫开始时打开与 MySQL 数据库的连接,并根据设置中的信息进行配置,以便后续插入数据。
点击查看代码
在处理每个爬取的股票项时,构造 SQL 插入语句,将股票信息写入数据库,并提交事务以保存更改。
点击查看代码
在爬虫结束时关闭数据库连接,释放资源以防止内存泄漏。
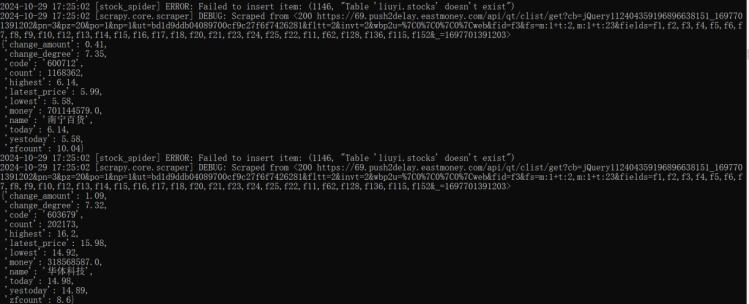
3、运行结果
在终端运行爬虫,并将爬取到的数据保存在一个.json文件:
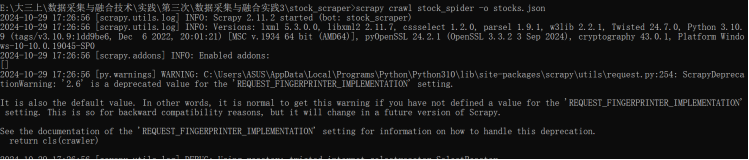
进行爬取时终端输出如下:
在mysql创建数据库
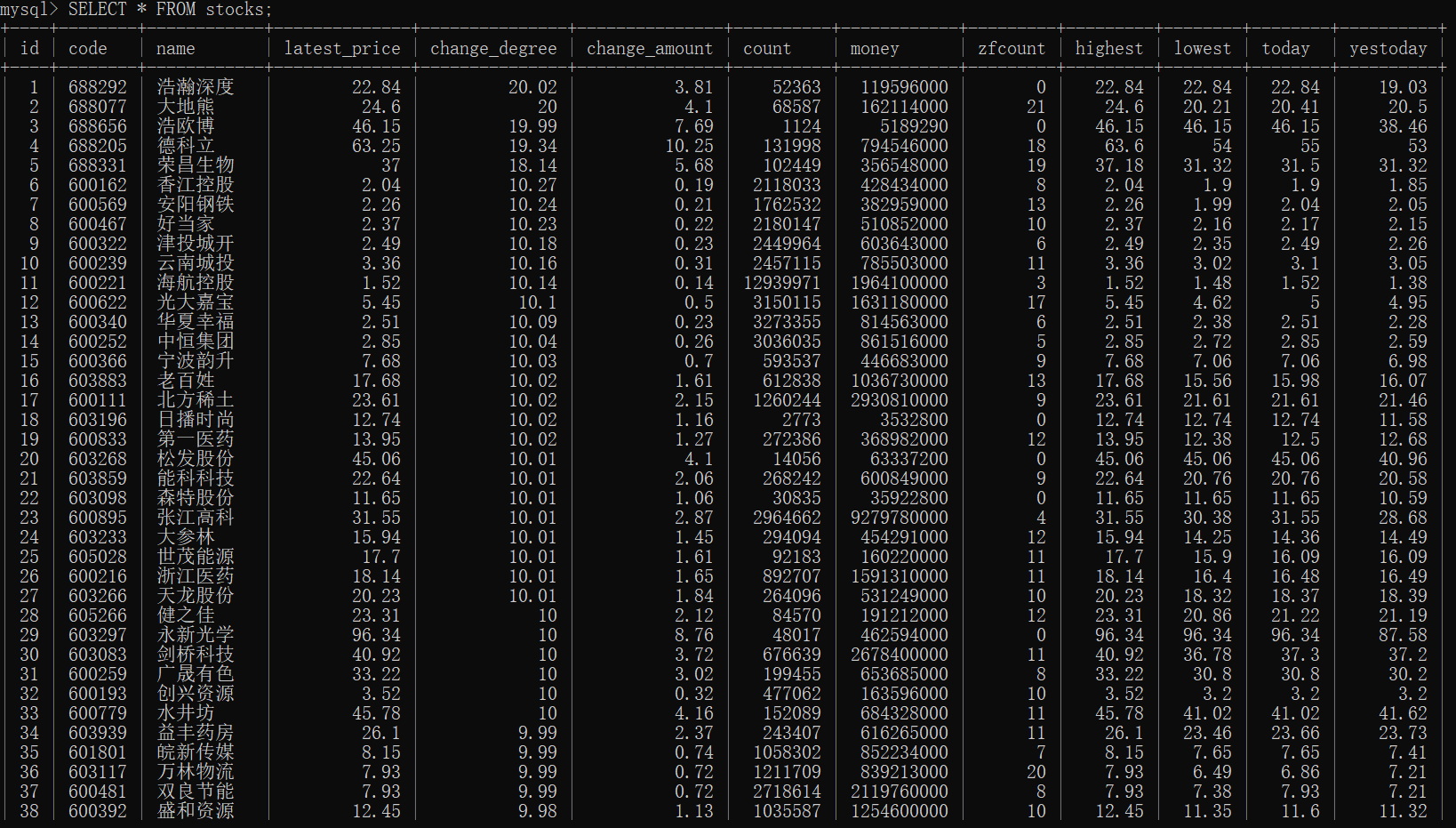
输出数据库内容:
在本实验中,通过 Scrapy 与 MySQL 的结合,实现了数据的持久化存储。使用 XPath 提取股票信息简单有效,但需要处理不同页面结构的问题。MySQL Pipeline 的实现使得数据写入数据库过程更加方便。
- 熟练掌握scrapy中Item、Pipeline数据的序列化输出方法;
- 使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
- 招商银行网:https://www.boc.cn/sourcedb/whpj/
(MySQL数据库存储和输出格式)
1、代码思路
(2)编写爬虫:
创建爬虫类 ExchangeRateSpider,设置 start_urls 为中国银行外汇数据页面。
在 parse 方法中使用 XPath 提取外汇数据,包括货币名称和汇率等。
处理数据后,使用 yield 将 Item 返回给 Pipeline。
(3)设置 Pipeline:
在 pipelines.py 中编写 ExchangeRatePipeline 类,用于将提取的数据存储到 MySQL 数据库。
在 open_spider 方法中建立数据库连接,process_item 方法中执行插入操作,close_spider 方法中关闭连接。
(4)MySQL 数据库准备:
在 MySQL 中创建数据库和表,表结构应包括相应字段以存储外汇数据。
在 Scrapy 设置中配置数据库连接信息(主机、用户、密码、数据库名等)。
2、重要代码部分
点击查看代码
将爬取到的外汇数据插入到forex_rates表中,在处理每个项目时,它将时间字段转换为合适的DATETIME格式,并提交插入操作。
点击查看代码
从目标网址抓取数据,并提取表格中的每一行信息,填充到ForexRateItem中,然后将其传递给数据处理管道。
3、运行结果
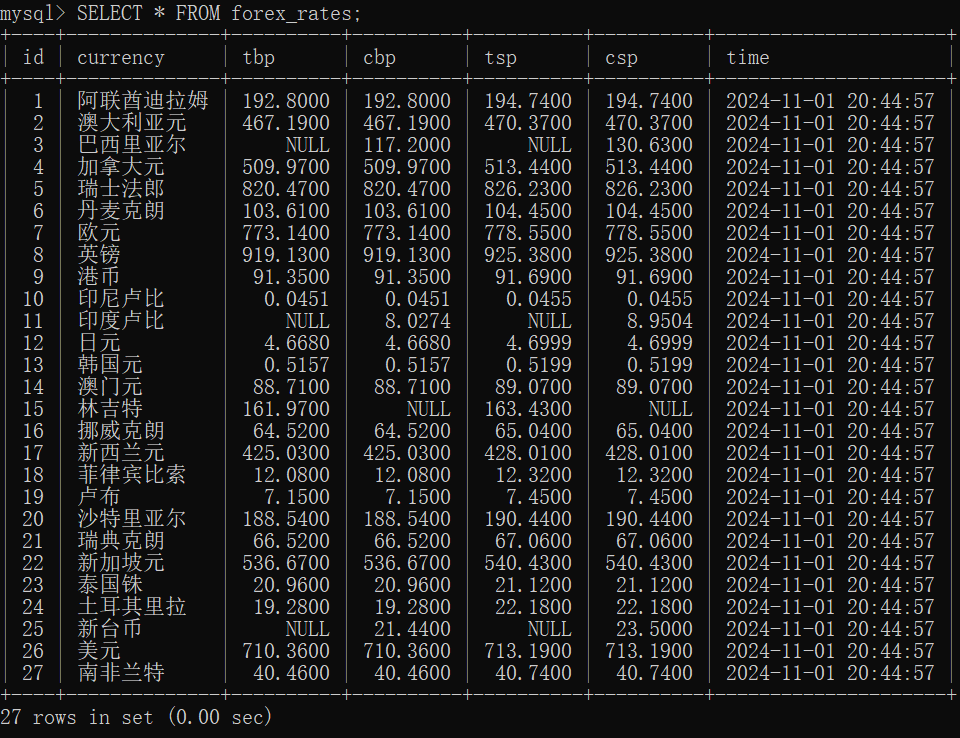
在mysql查看输出的数据:
本实验通过 Scrapy 爬取外汇数据,并将数据保存到 MySQL 数据库中。XPath 用于提取数据非常直观,但对于一些结构较为复杂的页面,需要进行精细调整,以确保数据抓取的准确性和一致性。
在爬取过程中,有些图片的 URL 返回了 404 错误,导致无法下载。
在处理图片 URL 时,添加有效性检查,确保只下载以 http 开头的有效链接。同时,可以记录失败的 URL,并在爬虫结束时输出到日志,以便后续检查和手动处理。
在执行爬虫时,发现有些数据被重复插入到数据库中,导致数据冗余。
在数据库中设置唯一索引,确保每条记录的唯一性。同时,在插入数据前,查询数据库以判断该条记录是否已存在,避免重复插入。
在爬取股票数据时,有时提取到的数据不完整或字段缺失。
检查 XPath 表达式的准确性,确保其匹配目标网页中的元素。使用 scrapy shell 工具调试 XPath 查询,并在提取数据前进行条件判断,确保数据的完整性。可以在提取后进行数据清洗,剔除无效或缺失的项。
在这三个实验中,通过使用 Scrapy 框架实现了对不同网站数据的高效爬取和存储,掌握了爬虫的基本操作流程和数据处理技巧。特别是在处理多线程和数据库存储方面的实践,使我更加熟悉了数据采集的整个过程。
每个实验都让我意识到,合理的配置和调试是成功爬取数据的关键。在处理外部网站时,需要注意遵循爬取礼仪,以免对目标网站造成过大负担。此外,灵活运用 XPath 和 Scrapy 的功能,可以有效提高数据提取的效率和准确性。
通过解决遇到的问题,我也提高了对错误处理和调试的能力,为今后的数据采集工作打下了良好的基础。这些经验不仅加深了对 Scrapy 框架的理解,也为我在实际项目中应用数据抓取技术提供了实用的指导。
到此这篇yarn日志怎么看报错(yarn 日志保留时间)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/51360.html