
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
目录
我的环境
- 语言环境:python3.8.18
- 编译器:jupyter notebook
- 深度学习环境:torch==2.0.1+cu118,torchvision==0.15.2+cu118
随着网络深度的增加,网络能获取的信息量随之增加,而且提取的特征更加丰富。但是在残差结构提出之前,根据实验表明,随着网络层不断的加深,模型的准确率起初会不断的提高,达到最大饱和值,然后随着网络深度的继续增加,模型准确率不但不会继续增加,反而会出现大幅度降低现象,即模型训练过程和测试过程的error比浅层模型更高。这是由于之前的网络模型随着网络层不断加深会造成梯度爆炸和梯度消失的问题。
深度残差网络ResNet(deep residual network)在2015年由何恺明等提出,因为它简单与实用并存,随后很多研究都是建立在ResNet-50或者ResNet-101基础上完成。
ResNet主要解决深度卷积网络在深度加深时候的“退化”问题。在一般的卷积神经网络中,增大网络深度后带来的第一个问题就是梯度消失、爆炸,这个问题Szegedy提出BN层后被顺利解决。BN层能对各层的输出做归一化,这样梯度在反向层层传递后仍能保持大小稳定,不会出现过小或过大的情况。但是作者发现加了BN后再加大深度仍然不容易收敛,其提到了第二个问题--准确率下降问题:层级大到一定程度时准确率就会饱和,然后迅速下降,这种下降即不是梯度消失引起的也不是过拟合造成的,而是由于网络过于复杂,以至于光靠不加约束的放养式的训练很难达到理想的错误率。
准确率下降问题不是网络结构本身的问题,而是现有的训练方式不够理想造成的。当前广泛使用的优化器,无论是SGD,还是RMSProp,或是Adam,都无法在网络深度变大后达到理论上最优的收敛结果。
作者在文中证明了只要有合适的网络结构,更深的网络肯定会比较浅的网络效果要好。证明过程也很简单:假设在一种网络A的后面添加几层形成新的网络B,如果增加的层级只是对A的输出做了个恒等映射(identity mapping),即A的输出经过新增的层级变成B的输出后没有发生变化,这样网络A和网络B的错误率就是相等的,也就证明了加深后的网络不会比加深前的网络效果差。
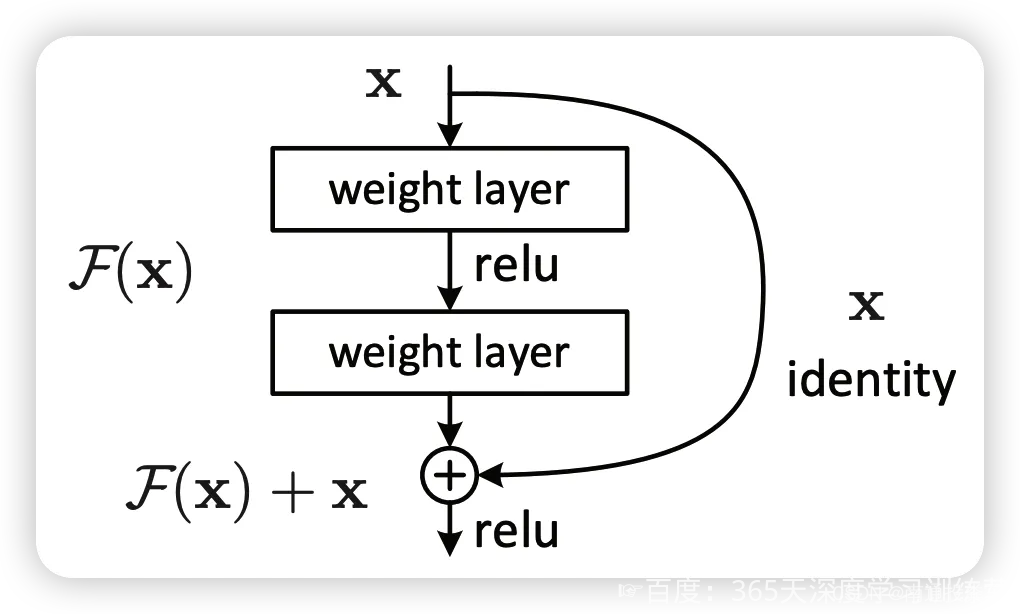
何恺明提出了一种残差结构来实现上述恒等映射(图1):整个模块除了正常的卷积层输出外,还有一个分支把输入直接连到输出上,该分支输出和卷积的输出做算术相加得到最终的输出,用公式表达就是
H(x)=F(x)+x
x是输入,F(x)是卷积分支的输出,H(x)是整个结构的输出。可以证明如果F(x)分支中所有参数都是0,H(x)就是个恒等映射。残差结构人为制造了恒等映射,就能让整个结构朝着恒等映射的方向去收敛,确保最终的错误率不会因为深度的变大而越来越差。如果一个网络通过简单的手工设置参数值就能达到想要的结果,那这种结构就很容易通过训练来收敛到该结果,这是一条设计复杂的网络时通用的规则。
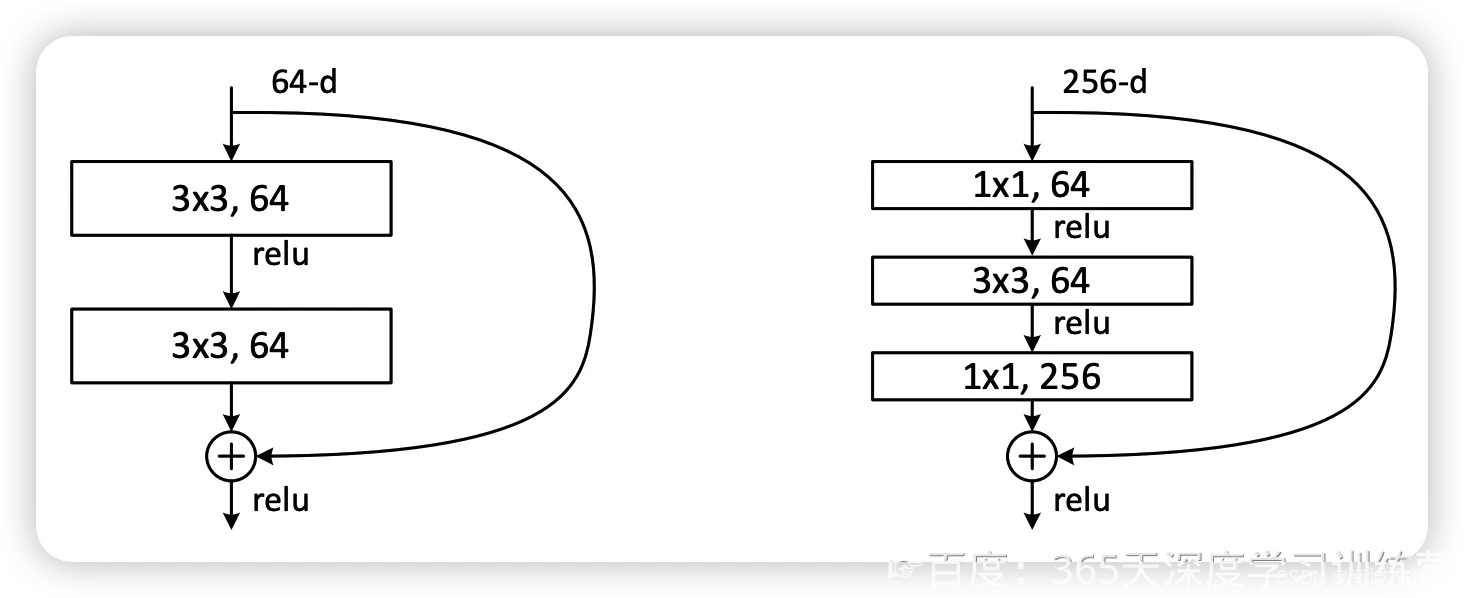
图2左边的单元为 ResNet 两层的残差单元,两层的残差单元包含两个相同输出的通道数的 3x3 卷积,只是用于较浅的 ResNet 网络,对较深的网络主要使用三层的残差单元。三层的残差单元又称为 bottleneck 结构,先用一个 1x1 卷积进行降维,然后 3x3 卷积,最后用 1x1 升维恢复原有的维度。另外,如果有输入输出维度不同的情况,可以对输入做一个线性映射变换维度,再连接后面的层。三层的残差单元对于相同数量的层又减少了参数量,因此可以拓展更深的模型。通过残差单元的组合有经典的 ResNet-50,ResNet-101 等网络结构。



这次是自己写代码,所以出现了一些问题,在训练函数记录acc和loss时,明明只需要记录10次,却记录了100次,应该是没有更新而是把之前的都记录了,呆滞画图的时候频繁报错,解决方法是采用是数据切片取得最后的10个。
到此这篇resnet50作者(resnet50+fpn)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/58765.html