
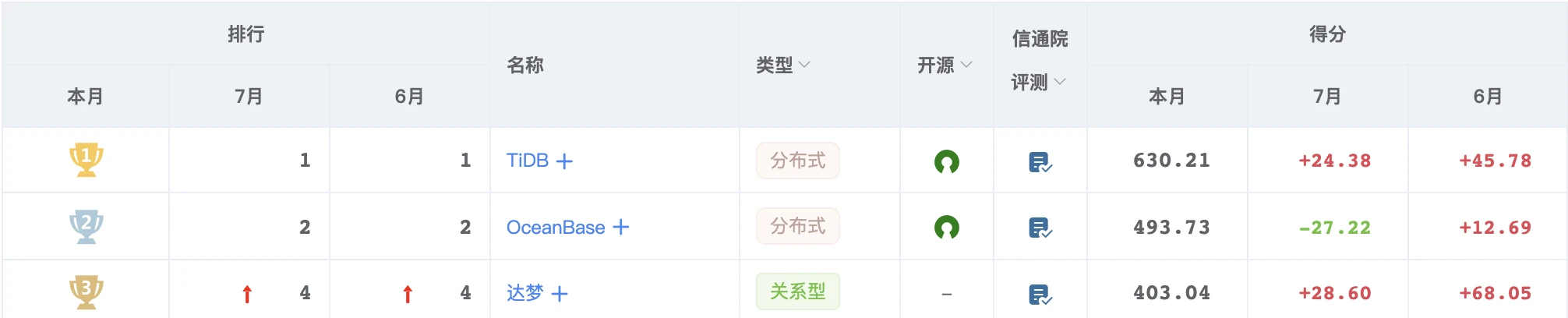
对于常年占据国产数据库排行榜前三的 数据库,早已 “垂涎a已久” (¯﹃¯)!
要想学习一门数据库技术,第一步当然是要安装数据库,然后才能学习使用它,顺便记录下作者的安装初体验!❤️
达梦数据库管理系统(以下简称DM)是基于客户/服务器方式的数据库管理系统,可以安装在多种计算机操作系统平台上,典型的操作系统有:
- Windows(Windows2000/2003/XP/Vista/7/8/10/Server等)
- Linux
- HP-UNIX
- Solaris
- FreeBSD
- AIX
对于不同的系统平台,有不同的安装步骤。
根据不同的应用需求与配置,DM提供了多种不同的产品系列:
- 标准版Standard Edition
- 企业版Enterprise Edition
- 安全版Security Edition
相较于 Oracle 的全英文官方文档来说,达梦的官方文档就显得亲切多了,一眼看去就很喜欢!❤️
作为一款热门的国产数据库,对于平台的支持必然是广泛的。下面👇🏻列出一些安装部署基础要求:
达梦官方提供的最新版本为DM8,可以直接下载:
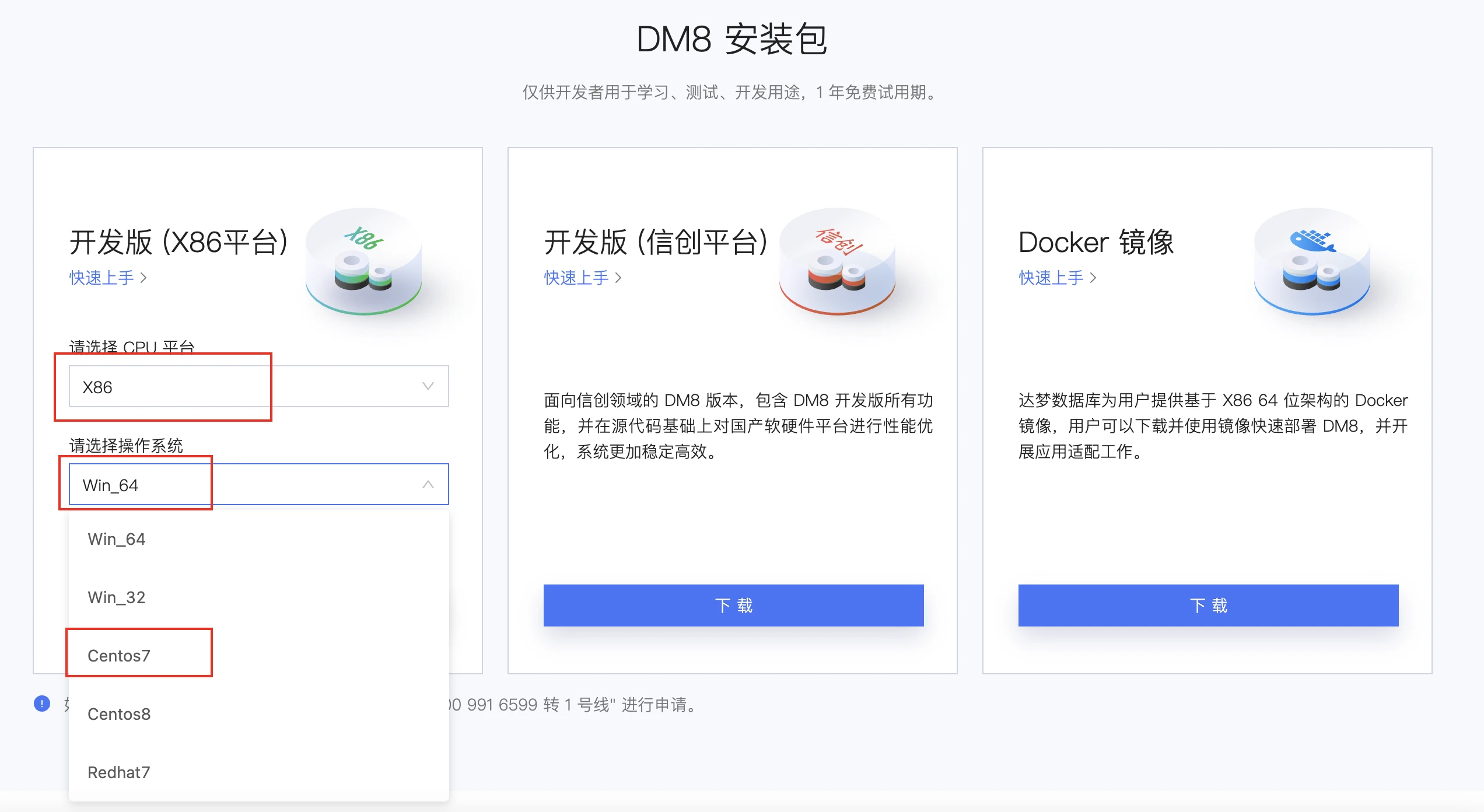
达梦8的数据库安装介质下载地址:https://ecohttp://www.360doc.com/content/21/1210/09/download
Linux操作系统我选择的是 centos7,打算使用 vagrant 进行安装:
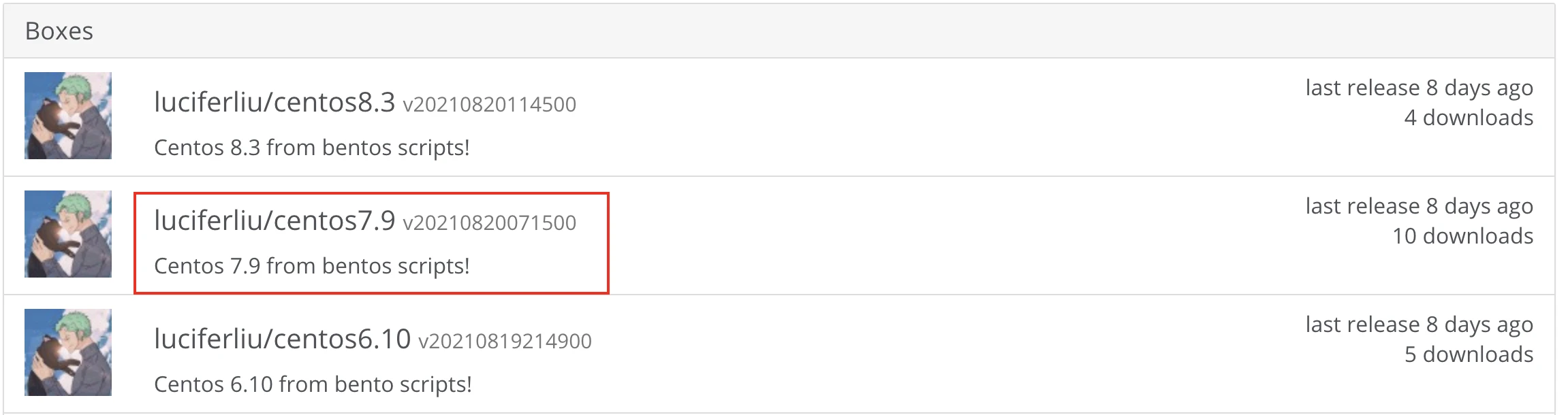
centos7 box镜像下载地址:https://apphttp://www.360doc.com/content/21/1210/09/luciferliu/boxes/centos7.9
至此,安装介质都准备好了!
进入自定义目录启动主机:
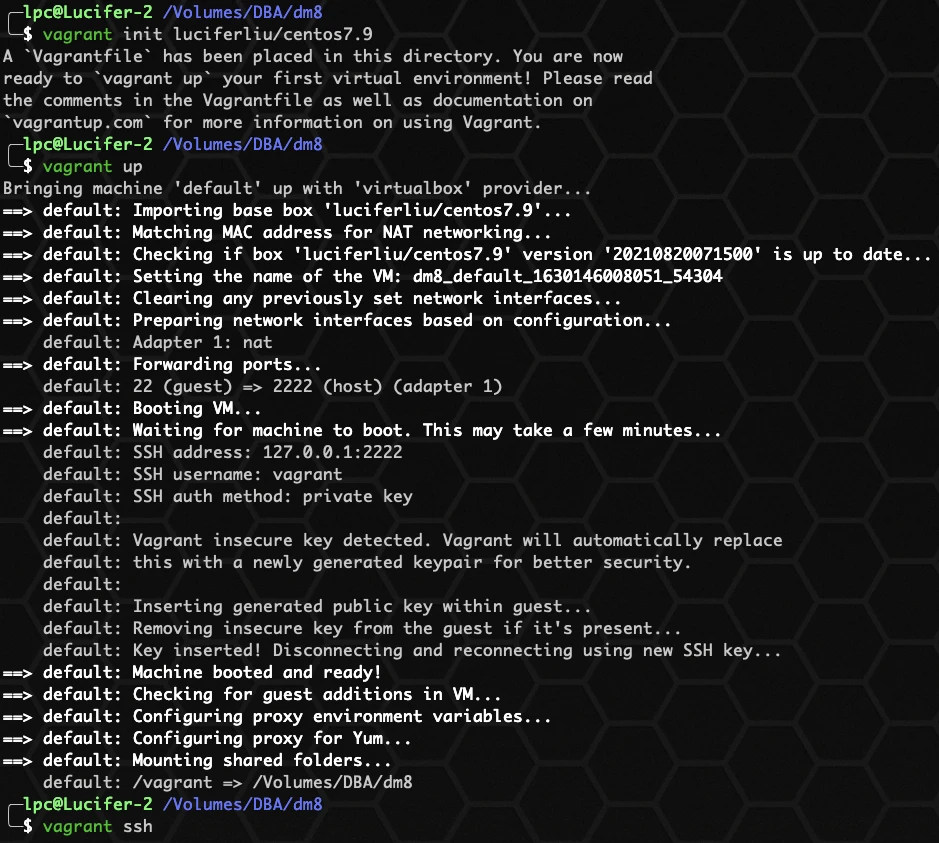
如上图所示,Centos7.9 的主机就已经启动了,下面我们连接并且上传 DM8 安装包。
将 DM8 安装包拷贝到当前 目录下,使用 连接主机:
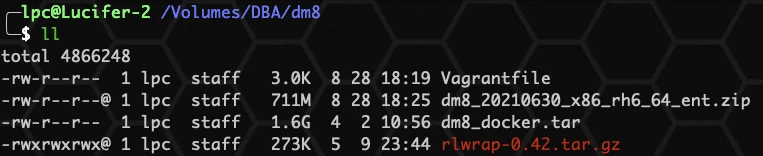
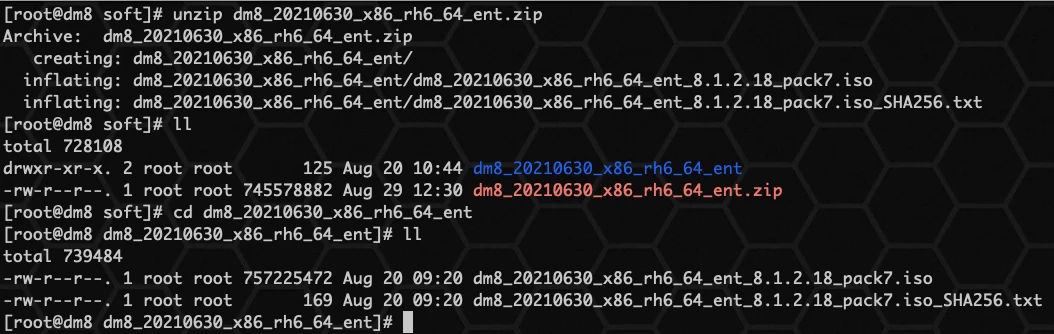
如上图所示,DM8 安装包已解压至至主机 目录下。
用户在安装DM之前需要检查或修改操作系统的配置,以保证 DM 正确安装和运行。

为了减少对操作系统的影响,用户不应该以root系统用户来安装和运行DM。用户可以在安装之前为DM创建一个专用的系统用户。
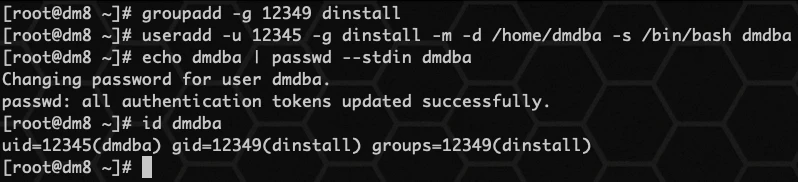
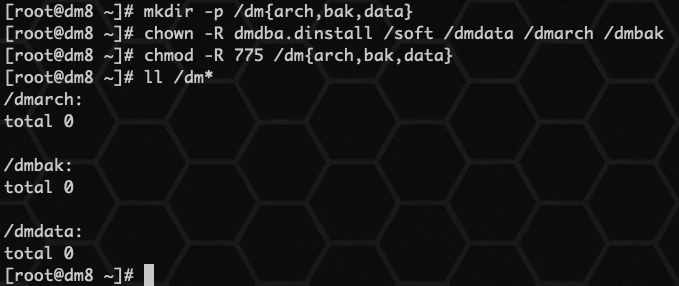

Linux6:
Linux7:
在Linux(Unix)系统中,因为ulimit命令的存在,会对程序使用操作系统资源进行限制。为了使DM能够正常运行,建议用户检查当前安装用户的ulimit参数。
为了保证DM的正确安装和运行,要尽量保证操作系统至少1GB的可用内存(RAM)。如果可用内存过少,可能导致DM安装或启动失败。
DM完全安装需要1GB的存储空间,用户需要提前规划好安装目录,预留足够的存储空间。用户在DM安装前也应该为数据库实例预留足够的存储空间,规划好数据路径和备份路径。
安装同时支持图形化安装,命令行安装,静默安装三种方式。由于我没有安装图形化界面,因此使用 方式进行安装。
用户应登录或切换到安装系统用户,进行以下安装步骤的操作(注:不建议使用root系统用户进行安装)。
官网下载的 DM8 安装包解压下来是一个 ISO 镜像文件,因此需要挂载取出安装文件,才能开始安装。
1、执行安装命令:
2、按需求选择安装语言,默认为中文。本地安装选择【不输入 Key 文件】,选择【默认时区 21】。
3、选择【1-典型安装】,按已规划的安装目录 /dm 完成数据库软件安装,不建议使用默认安装目录。
4、root 用户执行 root 脚本:
使用 dmdba 用户配置实例,使用 dminit 命令初始化实例。
📢 注意:dminit 命令可设置多种参数,可执行如下命令查看可配置参数。
需要注意的是 页大小 (PAGE_SIZE)、簇大小 (EXTENT_SIZE)、大小写敏感 (CASE_SENSITIVE)、字符集 (CHARSET/UNICODE_FLAG)、VARCHAR类型长度(LENGTH_IN_CHAR) 这几个参数,一旦确定无法修改,需谨慎设置。
- EXTENT_SIZE 数据文件使用的簇大小(16),可选值:16, 32, 64,单位:页,缺省使用 16 页。指数据文件使用的簇大小,即每次分配新的段空间时连续的页数。
- PAGE_SIZE 数据页大小(8),可选值:4, 8, 16, 32,单位:K,选择的页大小越大,则 DM 支持的元组长度也越大,但同时空间利用率可能下降,缺省使用 8 KB。
- CASE_SENSITIVE 大小敏感(Y),可选值:Y/N,1/0,默认值为 Y 。当大小写敏感时,小写的标识符应用双引号括起,否则被转换为大写;当大小写不敏感时,系统不自动转换标识符的大小写,在标识符比较时也不区分大小写,只能是 Y、y、N、n、1、0 之一。
- CHARSET/UNICODE_FLAG 字符集(0),可选值:0[GB18030],1[UTF-8],2[EUC-KR];1 代表 UTF-8;2 代表韩文字符集 EUC-KR;取值 0、1 或 2 之一。默认值为 0。
- LENGTH_IN_CHAR VARCHAR类型长度是否以字符为单位(N),可选值:Y/N,1/0。
以下命令设置页大小为 32 KB,簇大小为 32 KB,大小写敏感,字符集为 utf_8,数据库名为 DMDB,实例名为 LUCIFER,端口为 5237。
注册服务需使用 root 用户进行注册。使用 root 用户进入数据库安装目录的 /script/root 下,如下所示:
服务注册成功后,启停数据库,如下所示:
也可以通过以下命令执行:
下载完成后,导入安装包,打开 docker ,使用如下命令:
导入完成后,可以使用 docker images 来查看导入的镜像,命令如下:
查看结果如下:
镜像导入后,使用 docker run 来启动容器,默认的端口 5236 默认的账号密码 ,启动命令如下:
容器启动完成后,使用 docker ps 来查看镜像的启动情况,命令如下:
启动完成后,可以查看日志来查看启动情况,命令如下:
显示内容如下,则表示启动成功。
命令如下:
📢 注意:如果使用docker容器里面的 disql ,进入容器后,先执行 source /etc/profile 防止中文乱码。
用户在安装 DM 数据库前,需要检查当前操作系统的相关信息,确认 DM 数据库安装程序与当前操作系统匹配,以保证 DM 数据库能够正确安装和运行。
用户可以在终端通过 Win+R 打开运行窗口,输入 cmd,打开命令行工具,输入 命令进行查询,如下图所示:
为了保证 DM 数据库的正确安装和运行,要尽量保证操作系统至少 1 GB 以上的可用内存 (RAM)。如果可用内存过少,可能导致 DM 数据库安装或启动失败。
用户可以通过【任务管理器】查看可用内存,如下图所示:
DM 完全安装需要至少 1 GB 以上的存储空间,用户需要提前规划好安装目录,预留足够的存储空间。
用户在 DM 安装前也应该为数据库实例预留足够的存储空间,规划好数据路径和备份路径。
上传安装包,解压挂载,复制出安装文件,开始安装!
双击运行【setup.exe】安装程序,请根据系统配置选择相应语言与时区,点击【确定】按钮继续安装。如下图所示:
点击【下一步】按钮继续安装,如下图所示:
在安装和使用 DM 数据库之前,需要用户阅读并接受许可证协议,如下图所示:
用户可以查看 DM 服务器、客户端等各组件相应的版本信息。
验证 Key 文件环节可跳过,如果没有 Key 文件,点击【下一步】即可。
DM 安装程序提供四种安装方式:“典型安装”、“服务器安装”、“客户端安装”和“自定义安装”,此处建议选择【典型安装】,如下图所示:
- 典型安装包括:服务器、客户端、驱动、用户手册、数据库服务。
- 服务器安装包括:服务器、驱动、用户手册、数据库服务。
- 客户端安装包括:客户端、驱动、用户手册。
- 自定义安装包括:用户根据需求勾选组件,可以是服务器、客户端、驱动、用户手册、数据库服务中的任意组合。
DM 默认安装在 C:dmdbms 目录下,不建议使用默认目录,改为其他任意盘符即可,以 E:dmdbs 为例,如下图所示:
这里我只有一个 C 盘,因此直接默认安装!
📢 注意:安装路径里的目录名由英文字母、数字和下划线等组成,不建议使用包含空格和中文字符的路径等。
显示用户即将进行的数据库安装信息,例如产品名称、版本信息、安装类型、安装目录、可用空间、可用内存等信息,用户检查无误后点击【安装】按钮进行 DM 数据库的安装,如下图所示:
安装过程需耐心等待 1~2 分钟,如下图所示:
数据库安装完成后,请选择【初始化】数据库:
此处建议选择【创建数据库实例】,点击【开始】进入下一步骤,如下图所示:
此处建议选择【一般用途】即可,如下图所示:
本例中数据库安装路径为 C:dmdbs,如下图所示:
输入数据库名称、实例名、端口号等参数,如下图所示:
此处选择默认配置即可,如下图所示:
用户可通过选择或输入确定数据库控制、数据库日志等文件的所在位置,并可通过右侧功能按钮,对文件进行添加或删除。
此处选择默认配置即可,如下图所示:
用户可输入数据库相关参数,如簇大小、页大小、日志文件大小、选择字符集、是否大小写敏感等。
常见参数说明:
- EXTENT_SIZE 数据文件使用的簇大小 (16),可选值: 16、 32、 64,单位:页
- PAGE_SIZE 数据页大小 (8),可选值: 4、 8、 16、 32,单位: KB
- LOG_SIZE 日志文件大小 (256),单位为: MB,范围为: 64 MB~2 GB
- CASE_SENSITIVE 大小敏感 (Y),可选值: Y/N, 1/0
- CHARSET/UNICODE_FLAG 字符集 (0),可选值: 0[GB18030], 1[UTF-8], 2[EUC-KR]
此处选择默认配置即可,默认口令与登录名一致,如下图所示:
用户可输入 SYSDBA,SYSAUDITOR 的密码,对默认口令进行更改,如果安装版本为安全版,将会增加 SYSSSO 用户的密码修改。
此处建议勾选创建示例库 BOOKSHOP 或 DMHR,作为测试环境,如下图所示:
在安装数据库之前,将显示用户通过数据库配置工具设置的相关参数。点击【完成】进行数据库实例的初始化工作,如下图所示:
安装完成后将弹出数据库相关参数及文件位置。点击【完成】即可,如下图所示:
数据库安装路径下 tool 目录,双击运行 dmservice.exe 程序可以查看到对应服务,选择【启动】或【停止】服务。如下图所示:
当然,也可以通过 cmd 命令行进行启动:
达梦8 数据库安装总体来说,还算简单。但是有一说一,官方文档确实比较简单,不够细致,有待改进!
SQL语言有40多年的历史,从它被应用至今几乎无处不在。我们消费的每一笔支付记录,收集的每一条用户信息,发出去的每一条消息,都会使用数据库或与其相关的产品来存储,而操纵数据库的语言正是 SQL !

SQL 对于现在的互联网公司生产研发等岗位几乎是一个必备技能,如果不会 SQL 的话,可能什么都做不了。你可以把 SQL 当做是一种工具,利用它可以帮助你完成你的工作,创造价值。

文章结尾有 SQL 小测验哦!看看你能得几分?
⭐️
SQL 是用于访问和处理数据库的标准的计算机语言。
- SQL 指结构化查询语言
- SQL 使我们有能力访问数据库
- SQL 是一种 ANSI 的标准计算机语言

SQL 可与数据库程序协同工作,比如 MS Access、DB2、Informix、MS SQL Server、Oracle、Sybase 以及其他数据库系统。但是由于各种各样的数据库出现,导致很多不同版本的 SQL 语言,为了与 ANSI 标准相兼容,它们必须以相似的方式共同地来支持一些主要的关键词(比如 SELECT、UPDATE、DELETE、INSERT、WHERE 等等),这些就是我们要学习的SQL基础。
可以把 SQL 分为两个部分:数据操作语言 (DML) 和 数据定义语言 (DDL)。
- 数据查询语言(DQL: Data Query Language)
- 数据操纵语言(DML:Data Manipulation Language)
SQL 是一门 ANSI 的标准计算机语言,用来访问和操作数据库系统。SQL 语句用于取回和更新数据库中的数据。
- SQL 面向数据库执行查询
- SQL 可从数据库取回数据
- SQL 可在数据库中插入新的记录
- SQL 可更新数据库中的数据
- SQL 可从数据库删除记录
- SQL 可创建新数据库
- SQL 可在数据库中创建新表
- SQL 可在数据库中创建存储过程
- SQL 可在数据库中创建视图
- SQL 可以设置表、存储过程和视图的权限
顾名思义,你可以理解为数据库是用来存放数据的一个容器。
打个比方,每个人家里都会有冰箱,冰箱是用来干什么的?冰箱是用来存放食物的地方。

同样的,数据库是存放数据的地方。正是因为有了数据库后,我们可以直接查找数据。例如你每天使用余额宝查看自己的账户收益,就是从数据库读取数据后给你的。
最常见的数据库类型是关系型数据库管理系统(RDBMS):
RDBMS 是 SQL 的基础,同样也是所有现代数据库系统的基础,比如 MS SQL Server, IBM DB2, Oracle, MySQL 以及 Microsoft Access等等。
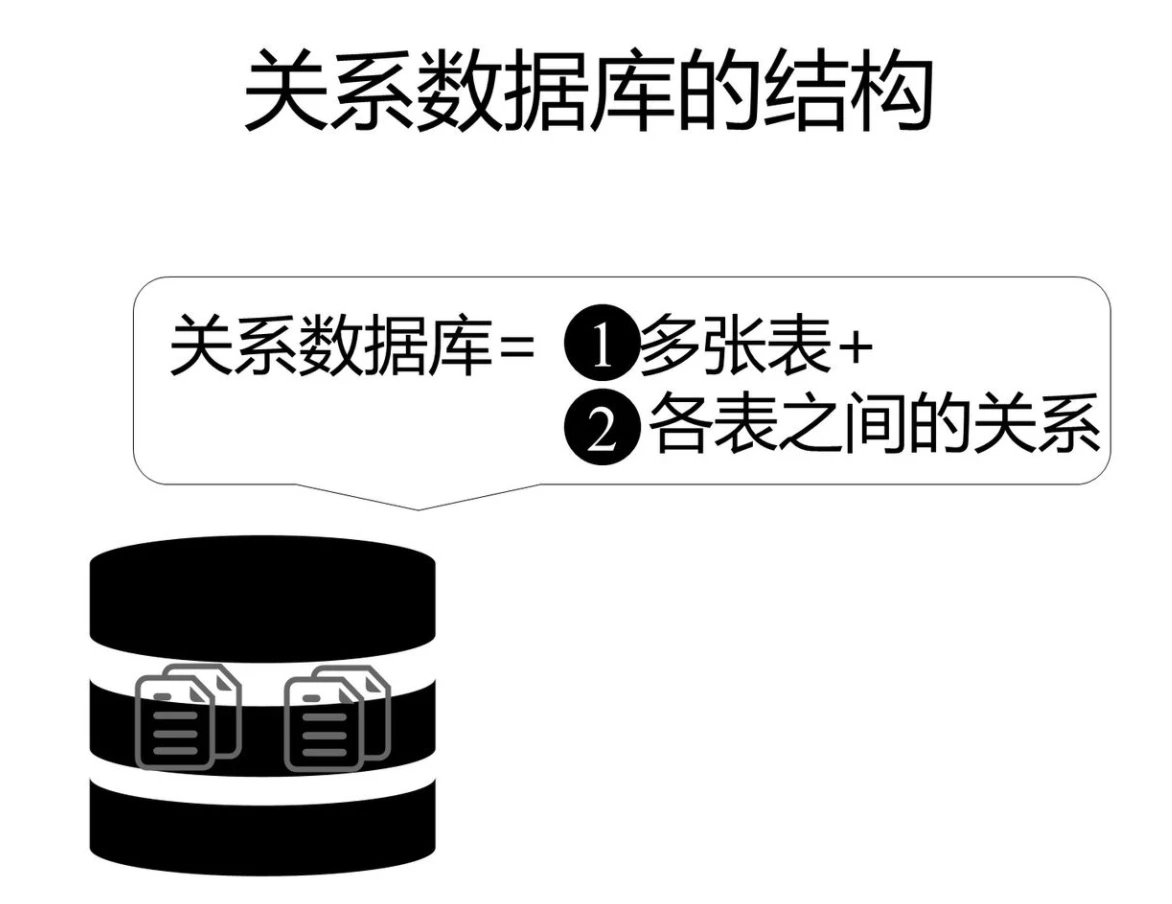
中的数据存储在被称为表(tables)的数据库对象中。 是相关的数据项的集合,它由列和行组成。
由于本文主要讲解 SQL 基础,因此对数据库不做过多解释,只需要大概了解即可。咱们直接开始学习SQL!
在了解 SQL 基础语句使用之前,我们先讲一下 是什么?
一个数据库通常包含一个或多个表。每个表由一个名字标识(例如“客户”或者“订单”)。表包含带有数据的记录(行)。
下面的例子是一个名为 “Persons” 的表:
上面的表包含三条记录(每一条对应一个人)和五个列(Id、姓、名、地址和城市)。
有表才能查询,那么如何创建这样一个表?
CREATE TABLE 语句用于创建数据库中的表。
语法:
数据类型(data_type)规定了列可容纳何种数据类型。下面的表格包含了SQL中最常用的数据类型:
实例:
本例演示如何创建名为 “Persons” 的表。
该表包含 5 个列,列名分别是:“Id_P”、“LastName”、“FirstName”、“Address” 以及 “City”:
Id_P 列的数据类型是 int,包含整数。其余 4 列的数据类型是 varchar,最大长度为 255 个字符。
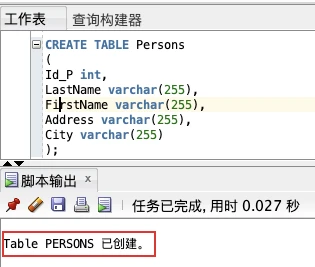

空的 “Persons” 表类似这样:

可使用 INSERT INTO 语句向空表写入数据。
INSERT INTO 语句用于向表格中插入新的行。
语法:
我们也可以指定所要插入数据的列:
实例:
本例演示 “Persons” 表插入记录的两种方式:
1、插入新的行
2、在指定的列中插入数据
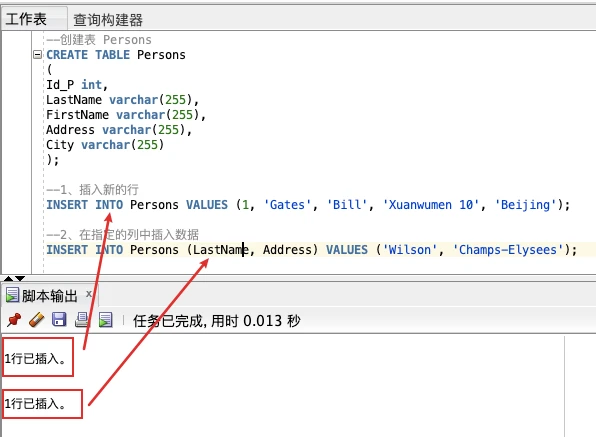
插入成功后,数据如下:

这个数据插入之后,是通过 语句进行查询出来的,别急马上讲!
SELECT 语句用于从表中选取数据,结果被存储在一个结果表中(称为结果集)。
语法:
我们也可以指定所要查询数据的列:
📢 注意: SQL 语句对大小写不敏感,SELECT 等效于 select。
实例:
SQL SELECT * 实例:
📢 注意: 星号(*)是选取所有列的快捷方式。
如需获取名为 “LastName” 和 “FirstName” 的列的内容(从名为 “Persons” 的数据库表),请使用类似这样的 SELECT 语句:
如果一张表中有多行重复数据,如何去重显示呢?可以了解下 。
语法:
实例:
如果要从 “LASTNAME” 列中选取所有的值,我们需要使用 语句:
可以发现,在结果集中,Wilson 被列出了多次。
如需从 “LASTNAME” 列中仅选取唯一不同的值,我们需要使用 SELECT DISTINCT 语句:
通过上述查询,结果集中只显示了一列 Wilson,显然已经去除了重复列。
如果需要从表中选取指定的数据,可将 WHERE 子句添加到 SELECT 语句。
语法:
下面的运算符可在 WHERE 子句中使用:
📢 注意: 在某些版本的 SQL 中,操作符 <> 可以写为 !=。
实例:
如果只希望选取居住在城市 “Beijing” 中的人,我们需要向 SELECT 语句添加 WHERE 子句:
📢 注意: SQL 使用单引号来环绕文本值(大部分数据库系统也接受双引号)。如果是数值,请不要使用引号。
AND 和 OR 可在 WHERE 子语句中把两个或多个条件结合起来。
- 如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。
- 如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
语法:
AND 运算符实例:
OR 运算符实例:
实例:
由于 Persons 表数据太少,因此增加几条记录:
AND 运算符实例:
使用 AND 来显示所有姓为 “Carter” 并且名为 “Thomas” 的人:
OR 运算符实例:
使用 OR 来显示所有姓为 “Carter” 或者名为 “Thomas” 的人:
结合 AND 和 OR 运算符:
我们也可以把 AND 和 OR 结合起来(使用圆括号来组成复杂的表达式):
ORDER BY 语句用于根据指定的列对结果集进行排序,默认按照升序对记录进行排序,如果您希望按照降序对记录进行排序,可以使用 DESC 关键字。
语法:
默认排序为 ASC 升序,DESC 代表降序。
实例:
以字母顺序显示 名称:
空值(NULL)默认排序在有值行之后。
以数字顺序显示,并以字母顺序显示 名称:
以数字降序显示:
📢 注意: 在第一列中有相同的值时,第二列是以升序排列的。如果第一列中有些值为 null 时,情况也是这样的。
Update 语句用于修改表中的数据。
语法:
实例:
更新某一行中的一个列:
目前 表有很多字段为 的数据,可以通过 为 LASTNAME 是 “Wilson” 的人添加FIRSTNAME:
更新某一行中的若干列:
DELETE 语句用于删除表中的行。
语法:
实例:
删除某行:
删除 表中 LastName 为 “Fred Wilson” 的行:
删除所有行:
可以在不删除表的情况下删除所有的行。这意味着表的结构、属性和索引都是完整的:
如果我们仅仅需要除去表内的数据,但并不删除表本身,那么我们该如何做呢?
可以使用 TRUNCATE TABLE 命令(仅仅删除表格中的数据):
语法:
实例:
本例演示如何删除名为 “Persons” 的表。
DROP TABLE 语句用于删除表(表的结构、属性以及索引也会被删除)。
语法:
实例:
本例演示如何删除名为 “Persons” 的表。
从上图可以看出,第一次执行删除时,成功删除了表 ,第二次执行删除时,报错找不到表 ,说明表已经被删除了。
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
语法:
实例:
表插入数据:
1、现在,我们希望从上面的 “Persons” 表中选取居住在以 “N” 开头的城市里的人:
2、接下来,我们希望从 “Persons” 表中选取居住在以 “g” 结尾的城市里的人:
3、接下来,我们希望从 “Persons” 表中选取居住在包含 “lon” 的城市里的人:
4、通过使用 NOT 关键字,我们可以从 “Persons” 表中选取居住在不包含 “lon” 的城市里的人:
📢注意: “%” 可用于定义通配符(模式中缺少的字母)。
IN 操作符允许我们在 WHERE 子句中规定多个值。
语法:
实例:
现在,我们希望从 表中选取姓氏为 Adams 和 Carter 的人:
操作符 BETWEEN … AND 会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
语法:
实例:
1、查询以字母顺序显示介于 “Adams”(包括)和 “Carter”(不包括)之间的人:
2、查询上述结果相反的结果,可以使用 NOT:
📢 注意: 不同的数据库对 BETWEEN…AND 操作符的处理方式是有差异的。
某些数据库会列出介于 “Adams” 和 “Carter” 之间的人,但不包括 “Adams” 和 “Carter” ;某些数据库会列出介于 “Adams” 和 “Carter” 之间并包括 “Adams” 和 “Carter” 的人;而另一些数据库会列出介于 “Adams” 和 “Carter” 之间的人,包括 “Adams” ,但不包括 “Carter” 。
所以,请检查你的数据库是如何处理 BETWEEN…AND 操作符的!
通过使用 SQL,可以为列名称和表名称指定别名(Alias),别名使查询程序更易阅读和书写。
语法:
表别名:
列别名:
实例:
使用表名称别名:
使用列名别名:
📢 注意: 实际应用时,这个 可以省略,但是列别名需要加上 。
用于根据两个或多个表中的列之间的关系,从这些表中查询数据。
有时为了得到完整的结果,我们需要从两个或更多的表中获取结果。我们就需要执行 。
数据库中的表可通过键将彼此联系起来。主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的。在表中,每个主键的值都是唯一的。这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。
如图,“Id_P” 列是 Persons 表中的的主键。这意味着没有两行能够拥有相同的 Id_P。即使两个人的姓名完全相同,Id_P 也可以区分他们。
❤️ 为了下面实验的继续,我们需要再创建一个表:Orders。
如图,“Id_O” 列是 Orders 表中的的主键,同时,“Orders” 表中的 “Id_P” 列用于引用 “Persons” 表中的人,而无需使用他们的确切姓名。
可以看到,“Id_P” 列把上面的两个表联系了起来。
语法:
不同的 SQL JOIN:
下面列出了您可以使用的 JOIN 类型,以及它们之间的差异。
- JOIN: 如果表中有至少一个匹配,则返回行
- INNER JOIN: 内部连接,返回两表中匹配的行
- LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN: 只要其中一个表中存在匹配,就返回行
实例:
如果我们希望列出所有人的定购,可以使用下面的 SELECT 语句:
操作符用于合并两个或多个 SELECT 语句的结果集。
UNION 语法:
📢注意: UNION 操作符默认为选取不同的值。如果查询结果需要显示重复的值,请使用 。
UNION ALL 语法:
另外,UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
为了实验所需,创建 Person_b 表:
实例:
使用 UNION 命令:
列出 persons 和 persons_b 中不同的人:
📢注意: UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
约束强制列不接受 NULL 值。
NOT NULL 约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录。
语法:
如上,创建一个表,设置列值不能为空。
实例:
📢 注意: 如果插入 值,则会报错 提示无法插入!
⭐️ 拓展小知识: 也可以用于查询条件:
同理, 也可:
感兴趣的朋友,可以自己尝试一下!
在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表。
视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。我们可以向视图添加 SQL 函数、WHERE 以及 JOIN 语句,我们也可以提交数据,就像这些来自于某个单一的表。
语法:
📢 注意: 视图总是显示最近的数据。每当用户查询视图时,数据库引擎通过使用 SQL 语句来重建数据。
实例:
下面,我们将 Persons 表中住在 Beijing 的人筛选出来创建视图:
查询上面这个视图:
如果需要更新视图中的列或者其他信息,无需删除,使用 选项:
实例:
现在需要筛选出,LASTNAME 为 Gates 的记录:
删除视图就比较简单,跟表差不多,使用 即可:
❤️ 本章要讲的高级语言就先到此为止,不宜一次性介绍太多~
SQL 拥有很多可用于计数和计算的内建函数。
函数的使用语法:
❤️ 下面就来看看有哪些常用的函数!
AVG 函数返回数值列的平均值。NULL 值不包括在计算中。
语法:
实例:
计算 “orderno” 字段的平均值。
当然,也可以用在查询条件中,例如查询低于平均值的记录:
COUNT() 函数返回匹配指定条件的行数。
语法:
中可以有不同的语法:
- COUNT(*) :返回表中的记录数。
- COUNT(DISTINCT 列名) :返回指定列的不同值的数目。
- COUNT(列名) :返回指定列的值的数目(NULL 不计入)。
实例:
COUNT(*) :
COUNT(DISTINCT 列名) :
COUNT(列名) :
函数返回一列中的最大值。NULL 值不包括在计算中。
语法:
MIN 和 MAX 也可用于文本列,以获得按字母顺序排列的最高或最低值。
实例:
函数返回一列中的最小值。NULL 值不包括在计算中。
语法:
实例:
函数返回数值列的总数(总额)。
语法:
实例:
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
语法:
实例:
获取 Persons 表中住在北京的总人数,根据 LASTNAME 分组:
如果不加 则会报错:
也就是常见的 不是单组分组函数的错误。
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
语法:
实例:
获取 Persons 表中住在北京的总人数大于1的 LASTNAME,根据 LASTNAME 分组:
函数把字段的值转换为大写。
语法:
实例:
选取 “LastName” 和 “FirstName” 列的内容,然后把 “LastName” 列转换为大写:
函数把字段的值转换为小写。
语法:
实例:
选取 “LastName” 和 “FirstName” 列的内容,然后把 “LastName” 列转换为小写:
函数返回文本字段中值的长度。
语法:
实例:
获取 LASTNAME 的值字符长度:
函数用于把数值字段舍入为指定的小数位数。
语法:
实例:
保留2位:
📢 注意: 取舍是 四舍五入 的!
取整:
函数返回当前的日期和时间。
语法:
实例:
获取当前时间:
📢 注意: 如果您在使用 Sql Server 数据库,请使用 函数来获得当前的日期时间。
上述如果都学完了的话,可以来做个小测验:SQL 测验,看看掌握的怎么样!
❤️ 测验会被记分:
每道题的分值是 1 分。在您完成全部的20道题之后,系统会为您的测验打分,并提供您做错的题目的正确答案。其中,绿色为正确答案,而红色为错误答案。
☞ 现在就开始测验! 祝您好运。
到此这篇docker 版本查询(查看docker0)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/59996.html