
前面我们说了Yarn 是一个资源调度平台,负责为运算程序提供服务器计算资源,方便我们编写的 Spark、flink、MapReduce 这些应用在它上面运行。如果还不知道它是什么的,请移步《Apache Hadoop YARN 的架构与运行流程》。
那么我们有木有办法看到 Yarn机器有多少资源呢?内存呀,CPU呀什么的。 我们提交到 Yarn的这些应用,它们的运行状态是什么样子的,占用了多少资源,到底哪些机器在为他们跑任务呢?
答案是肯定的,不止命令行,还有可视化的 UI 页面。下面我们就来看看到底长什么样子,都有什么。
about 菜单里面可以看到 Yarn 的 ResourceManager 的状态,是否是HA,它的版本和Hadoop 的版本信息。
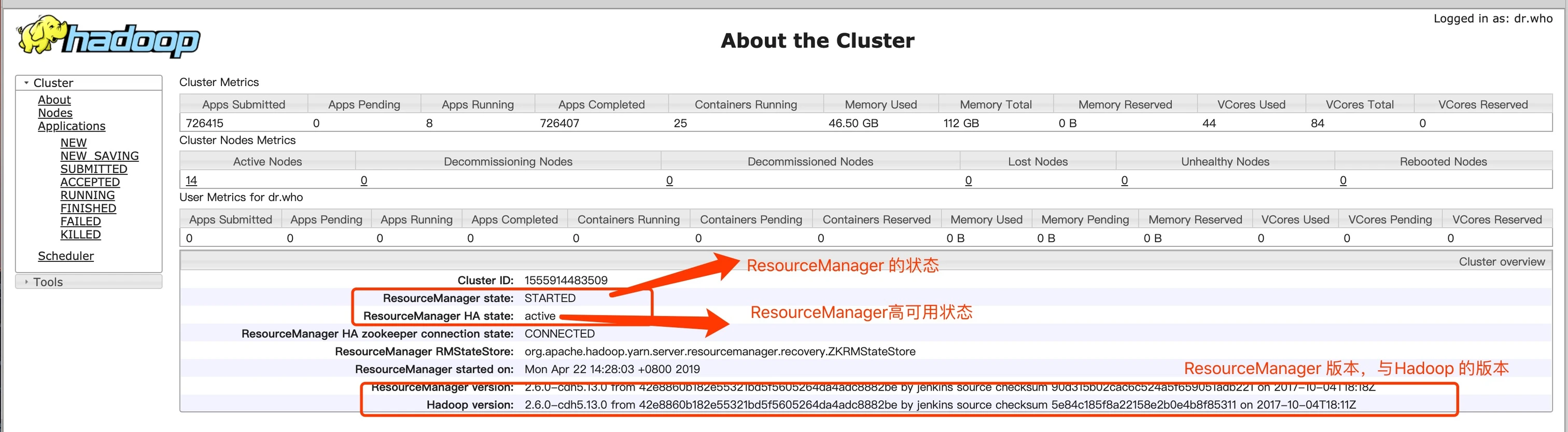
记得之前自己在搭建 Hadoop 集群的时候,把 Yarn 这个页面整出来的时候不知道有多兴奋,其实就长这样子。
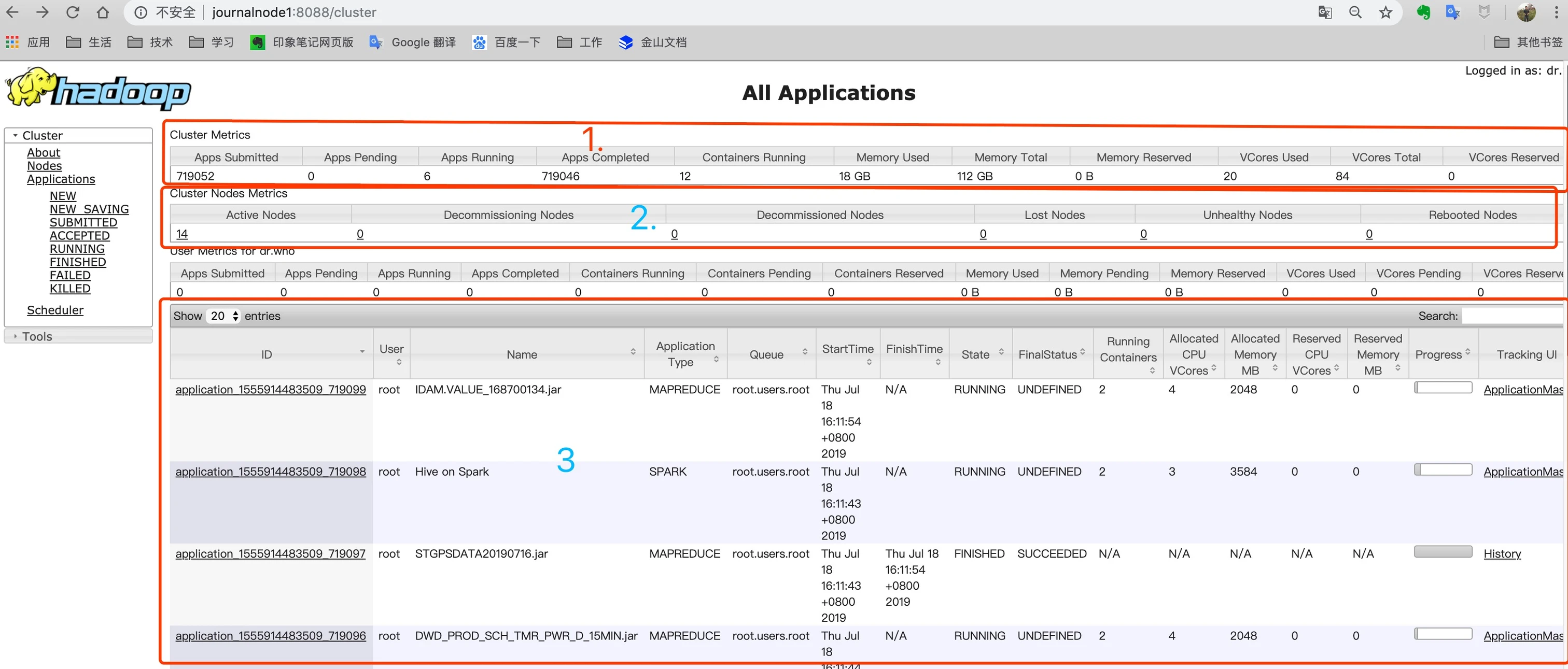
第一块区域,是整个集群的监控信息:
- Apps Submitted:已提交的应用,我们这里是71万多
- Apps Completed:已完成的应用
- Apps Running:正在运行的应用
- Containers Running:正在运行的容器
- Memory Total:集群总内存
- Memory Used:已使用内存
- VCores Total:集群 CPU 总核数
- VCores Used:已使用的 CPU 核数
- Memory Reserved:预留的内存
- VCores Reserved:预留的 CPU 核数
说明:
- Containers Running:正在运行的容器,为什么会有这个说法,是因为 Yarn 在运行任务之前,会先创建一个容器来跑。具体的原理,请看上面链接的文章。
- VCores Reserved 和 Memory Reserved: 为什么会存在预留的情况?是因为 Yarn 为了防止在分配一个容器到 NodeManager 的时候,,NodeManager当前还不能满足,那么 现在 NodeManager 已经有的资源将被冻结,以达到 容器需要的标准,然后分给那个容器。关于这个问答可以看这篇文章What is Memory reserved on Yarn
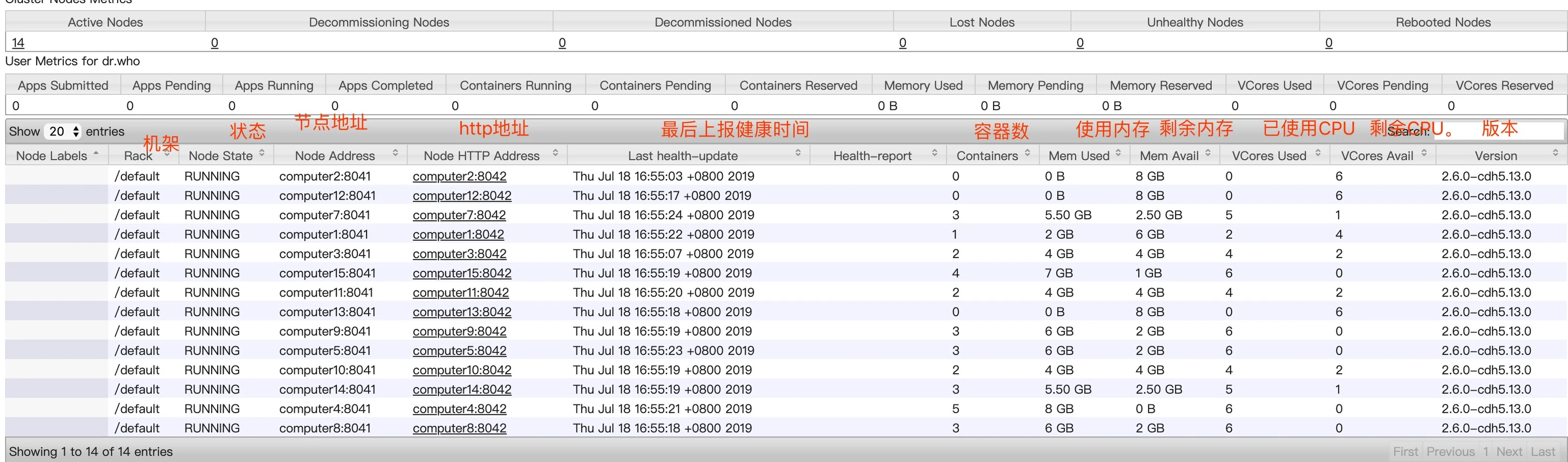
第二块区域是 Yarn 的集群节点的情况,从 Active Nodes 下面的数字点击进去,可以看到具体的节点列表信息。里面包含了所在机架、运行状态、节点地址、最后健康上报上报时间、运行的容器个数、使用内存CPU 等信息,还有版本号。如下图。
第三块内容是在 Yarn 上的任务执行情况列表:
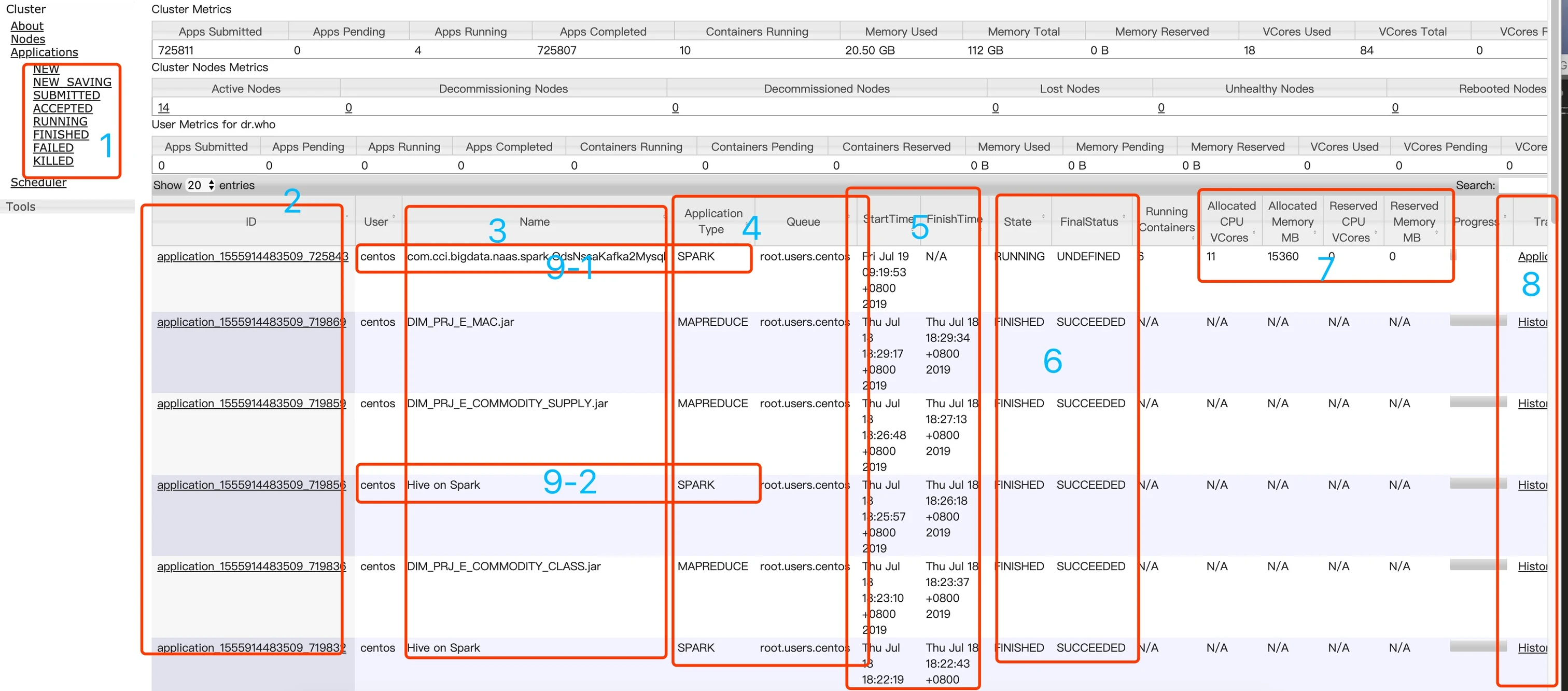
包括以下内容:
- 第一块,可以根据任务的不同状态去筛选,上图是筛选正在运行的任务。一搬来说,我们就看正在运行(RUNNING)的,和已经运行完成的(FINISHED)。如果你发现没你的任务了,那么可能在已接受( ACCEPTED)还没有运行的状态中,如果还找不到不到,那么恭喜你,可能有问题,跑失败了在失败(FAILED)里面,这时候,你就可点击任务ID,去详情页里面,找到日志入口去查看日志了,找问题了。
- 第二块,是任务的ID,这没什么好说的,你可以细心的看一下他的生成规则。
- 第三块,是任务的名字,可以看到图中有按类名的,他是我们自己提交的spark 任务的主类名。另外一类是 hive on spark ,这类的名称其实是跑的 hive 的脚本,知识我们 hive 的执行引擎是 spark。还有一类是 MapReduce 任务,这里的 MapReduce 任务,可不是我们真正用 MapReduce 去写的代码哈,只是我们有用 sqoop 进行数据的抽取。它底层是 MapReduce 。还有一类是 Flink 任务,会显示 Flink session cluster,只是我们现在还没有用。
- 第四块是应用的类型和所在队列,常见的类型有 spark 、mapreduce和Apache Flink 。所在队列,大家可以回想一下在说 yarn 的架构的时候,我们提交到 yarn 的任务,他会放到队列里面去,这个队列有默认的,有可以自己在提交时通过 --queue 进行指定的。如果我们没有制定,那么它会以你提交任务的时候使用的那个账户来进行提交,比如我这里就是 centos 的用户,显示则显示成 root.users.centos。
- 第五块,是任务的开始和结束时间。
- 第六块是任务当前的状态和最终状态。
- 第七块是任务占用的相关资源。
- 第八块是任务的应用类型主页。如果是 spark 任务的话,显示的是 spark 的 ui 页面。
在任务列表,点击 app ID 会来到这个应用的详情页:
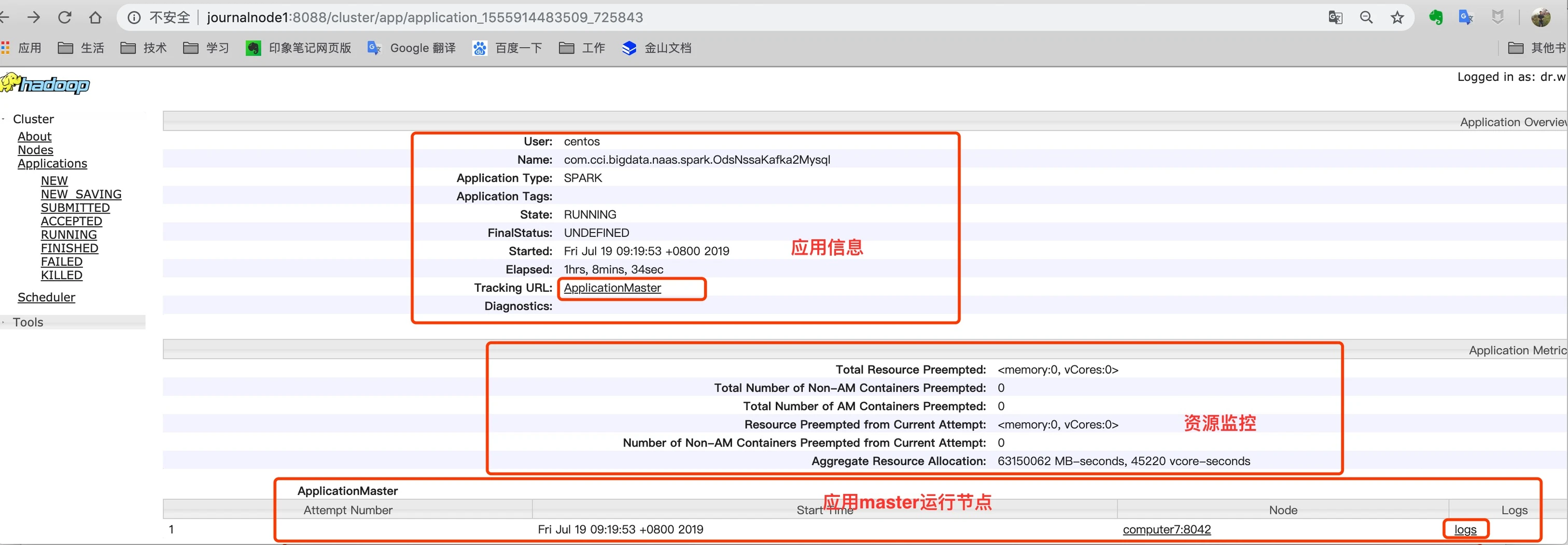
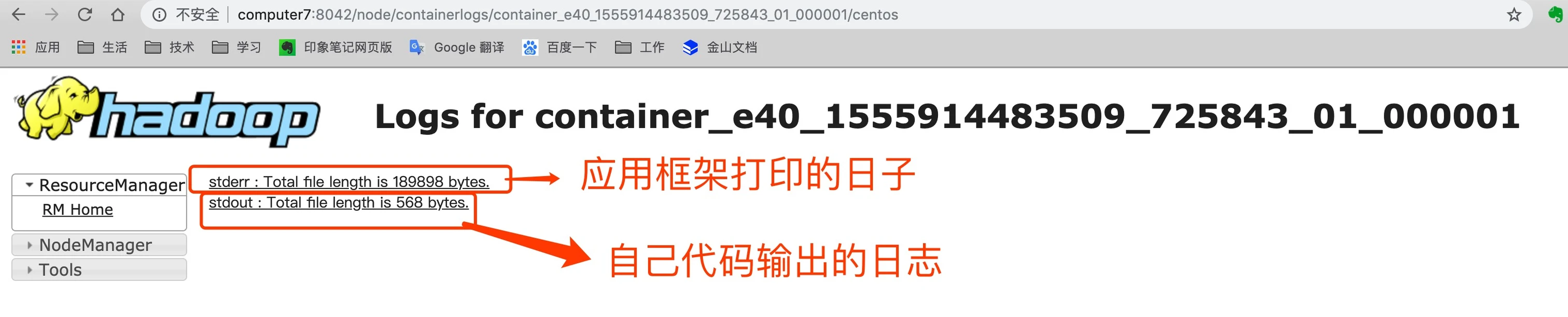
从应用详情页 ApplicationMaster 中,点击 最右边 log ,可以进入到应用的日志页面,日志记录了两部分,一部分是你的应用运行框架打印的日志,比如spark ,另外一部分是你编写的代码中打印的日志。point 打印的日志都会记录。如下图:
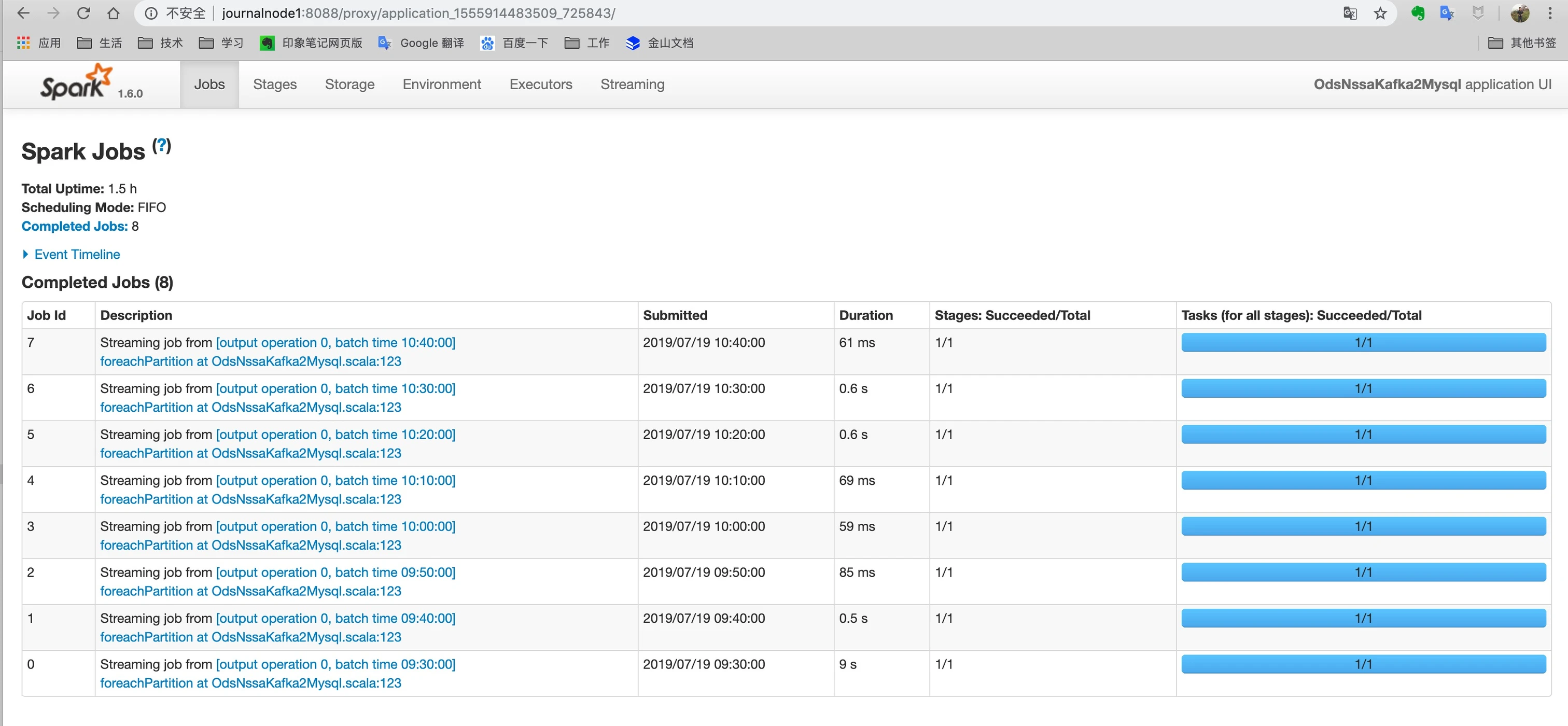
在详情页中,可以点击 Tracking URL 中提供 ApplicationMaster 链接,或者在在应用列表也中也可以,进入到 任务的运行框架UI页面,下面以spark 为例:
在主页还有一个调度(Scheduler)的菜单,里面可以看到 yarn 的队列信息。包含了有哪些队列、每个队列的资源使用情况、哪些任务运行在这个队列中等等。

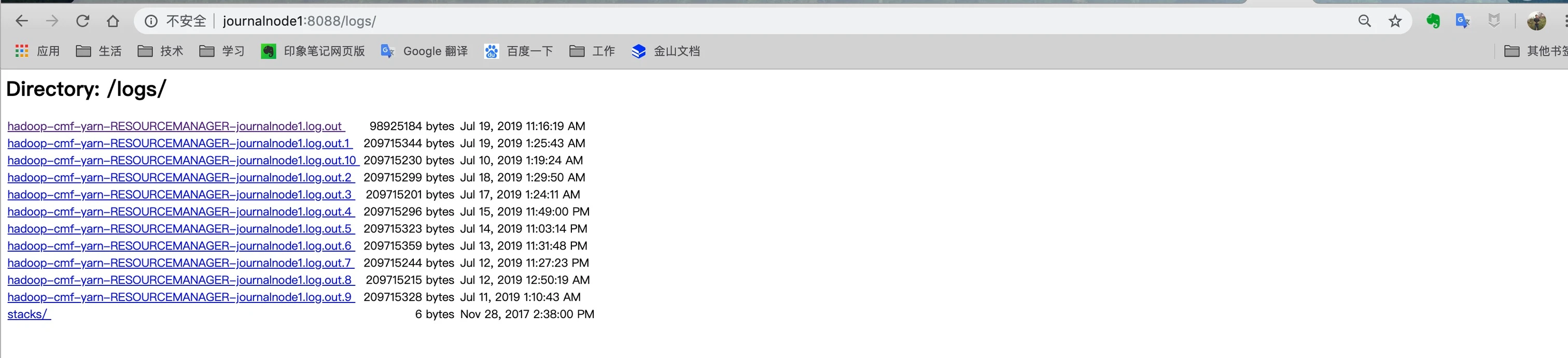
平常如果我们发现Yarn 有些问题,那么我们可以去看到 Yarn 的日志,在 左侧菜单 Tools->Local logs 里面我们可以看到 Yarn 的日志信息:
在CDH 中其实是对Yarn 有资源监控的,如果你没有使用CDH 这些,只有自己搭建的 Yarn 集群,那么 Yarn 也提供了监控时间获取方式,在左侧菜单 Tools -> Server metrics 里面,我们可以看到 如下数据,只是是 Json 数据。访问地址:http://journalnode1:8088/jmx?qry=Hadoop:*
拿到这个数据,你也可以写一个页面来可视化的展示它,给大家看一下 CDH 对于Yarn 的部分监控:

在 Tools 菜单栏中还有 Yarn 的配置信息和 服务当前的堆栈信息,有兴趣的去研究一下。
以上,是Yarn 的UI 界面的介绍,后面给大家带来平常我们使用 Yarn 的运维命令和它提供的 RestAPI。
到此这篇查询yarn上运行的任务(yarn查看历史任务列表)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/69597.html