

本节会继续结合一个用户登录接口给大家介绍 Swagger 中的另一个核心注解 - Api注解及所提供的常用属性。
Api 注解和 ApiOperation 注解一样,在 Swagger 中都扮演着非常重要的角色,Api 注解一般都会配合 ApiOperation 注解一起来使用。
希望大家在学习本节过程中能够分清主次,有的放矢。
Api 注解是作用在接口类上面的注解,其主要是用来给接口类定义相关说明。
Api 注解提供了丰富的属性,来允许我们自定义接口类的描述信息,包括对接口类的简单描述,接口类所属的分组等。
下面我们来看一下 Api 注解中都包括哪些主要属性。
定义:
该属性就是描述接口类的作用是什么,即同一类下的接口都是用来干什么的。
使用方法:
在 Api 注解中声明 value 的值即可。例如,对于用户接口类(UserController),我们只需要将 value 的值写为 'user-controller’就好了,这样我们就能很清楚的知道这个接口类下的所有接口都是用来处理和用户相关的请求的,如下代码段所示(现在你不需要理解业务代码代表什么意思,重点看接口类上使用的注解及属性即可,下同)。
代码解释:
第1行,我们在 UserController 用户接口类的上方使用了 @Api 注解的 value 属性来描述该接口类的作用。
显示结果:

可以看到,在 Created by Steafan 下放黑体加粗显示的 user-Controller 就是我们使用 value 属性描述的接口类信息了。
Tips :
- 通过 value 属性来对接口类进行描述的这一行为在实际开发工作中并不常用,各位同学只需要知道有这么一个 value 属性就可以了。
- 在实际开发工作中, value 属性经常被 tags 属性所替代,这也是 Swagger 官方所设定的规则:当 Api 注解的 value 属性和 tags 属性同时存在时,tags 属性的值会替代 value 属性的值,这一点需要同学们注意。
定义:
该属性就是对实现相同业务功能的接口类做一个大型的分组,该分组中包括同业务功能下的所有的接口。
使用方法:
在 Api 注解中声明 tags 的值即可,如果没有描述则默认值为空。例如,就用户接口类而言,该接口类属于用户业务分组,所以我们将 tags 的值描述为'用户’或者'user’,这样我们就能很清楚的看到这个接口类是属于用户业务组的,如下代码段所示。
代码解释:
第1行,我们在 UserController 接口类的上方使用了 @Api 注解的 tags 属性来描述该接口类所属的业务分组。
显示结果:
我们可以看到在 value 属性的值的位置显示了 user ,也就是 tags 里写的 user 了。
上述是 tags 属性和 value 属性单独存在时候的效果,下面我们来看一下 tags 属性和 value 属性同时存在的效果,如下代码段所示:
代码解释:
第1行,我们在 UserController 接口类的上方使用了 @Api 注解的 value 属性和 tags 属性同时来描述该接口类。
显示结果:

我们可以看到显示结果是和只使用 tags 属性来描述接口类时相同的结果,这也证明了 Swagger 官方的设定。
Tips : 在实际项目开发工作中,往往一个业务可能包括多个接口类的实现,这种情况需要我们对接口类进行多个分组,而 tags 属性的类型是字符串类型的数组,可以描述一个或多个值,如存在多值时,应该使用这种方式来描述:@Api(tags = {“user”, “customer”})。
定义:
该属性就是对接口类进行简单概要的描述,通常是描述一些注意的地方,value 属性更多的则是描述接口类的用途,这一点同学们要分清。
使用方法:
在 Api 注解中声明 description 的值即可,如果没有描述则默认值为空。例如,如果我想添加对用户接口类的概要描述信息,那么我可以这样写 description = “所有用户业务接口必须使用post请求”,如下代码段所示。
代码解释:
第1行,我们在 UserController 接口类的上方使用了 @Api 注解的 description 属性来描述用户接口类的一些注意的地方和约定。
显示结果:

在我用红框圈起来的地方我们可以看到使用 description 注解所描述的信息了。
Tips :
- description 属性一般用来对接口类进行一些注意事项和约定的描述,不要将其描述为接口类的用途。
- description 属性在实际开发工作中还是很常用的,所以描述好 description 是体现一个程序员对业务内容是否充分理解的标志。
以上是对 Api 注解中经常使用的三个属性进行的详细介绍,value,tags,description 这三个属性不管是在项目开发中,还是在需求沟通中,使用的都很频繁,所以真正掌握这三个属性,是用好 Api 注解的重要前提。在学习这三个属性时,大家应该结合 ApiOperation 注解来对比并总结它们之间的差异,通过不断的使用来发现它们的使用规律,这一点很重要。
在详细讲解完 Api 重要属性之后,下面我将针对在 Api 注解中,使用频率不是很高,但是有时也会用到的一些属性做概要性讲解,这些属性分别是:consumes、produces、protocols、hidden。
定义:
protocols() 属性就是对接口类中,所有的接口所使用的网络协议进行一个约定,常用的网络协议有:http、https。
hidden() 属性就是控制接口类在 Swagger 界面中的显隐性。
使用方法:
protocols() 属性默认值为空,但是 Swagger 在处理时,会默认获取项目所采用的网络协议,我们可以不用专门设置,如果一定要设置该属性,则只允许设置http协议规定的属性,不能随意设置,http, https 这些都是被允许的。
hidden() 属性允许我们在 Swagger 生成的接口列表界面上,控制接口类是否需要显示,默认值为 false,即接口类显示,为true时则接口类不显示,如下代码段所示。
代码解释:
第1行,我们在 UserController 接口类的上方使用了 @Api 注解的 hidden 属性来隐藏我们的用户接口类。
Tips :
- 接口类的显隐控制应该根据特定安全策略和特定客户需求来决定显隐,不能无故隐藏接口,更不能频繁的切换接口的显隐。
- 在实际工作中,如果需要隐藏接口类则需要和项目组报备情况,说明原因。
以上则是 Api 注解中的辅助使用属性的概要介绍,对于剩下的 produces、consumes 属性在实际项目开发中几乎很少使用,在这里就不再介绍了,如果大家感兴趣可以去 Swagger 的官网查询相关资料来了解。
本小节对 Swagger 中另一个最经常使用的 Api 注解及其该注解的各个属性做了详细的讲解,针对 Api 注解中经常在实际项目开发中使用的属性采用图文并茂的方式进行了重点介绍和应用剖析,对于一些在实际项目开发中使用基本很少的注解做了概要讲解。
在学习 @Api 注解及其属性时,各位同学应该对比 @ApiOperation 注解及其属性之间的使用差异,通过差异比较总结出适合自己的使用规律和使用方法才是最重要的。
本节会继续结合一个用户登录接口给大家介绍 Swagger 中的另一个核心注解 - ApiParam 注解及所提供的常用属性。
ApiParam 注解一般会结合 ApiOperation 注解以及 Api 注解一起来使用。
希望大家在学习本节过程中能够分清主次,有的放矢。
ApiParam 注解,是可以作用在接口方法上面,以及接口方法中的参数位置的注解,其主要是用来给接口中的参数定义相关参数说明,主要是为了,帮助相关人员理解接口中每个参数的含义。
ApiParam 注解同样也提供了丰富的属性,来允许我们对接口中的参数添加描述信息,包括该参数的具体含义、参数是否必须传递等。
下面我们来看一下 ApiParam 注解中都包括哪些主要属性。
定义:
该属性就是描述接口中参数的名称。
使用方法:
在 ApiParam 注解中声明 name 的值即可。例如,对于用户接口而言,在本例中,需要传递的参数是一个 user 对象,所以我们需要将 name 的值写为 'user’就可以了,这样,我们就能很清楚的知道,这个接口方法中传递的参数是一个 user 对象了,如下代码段所示(现在你不需要理解业务代码代表什么意思,重点看接口方法上使用的注解及属性即可,下同)。
代码解释:
第1行,我们在 login 接口方法的上方使用了 @ApiParam 注解的 name 属性来描述该接口中的参数名称。
显示结果:
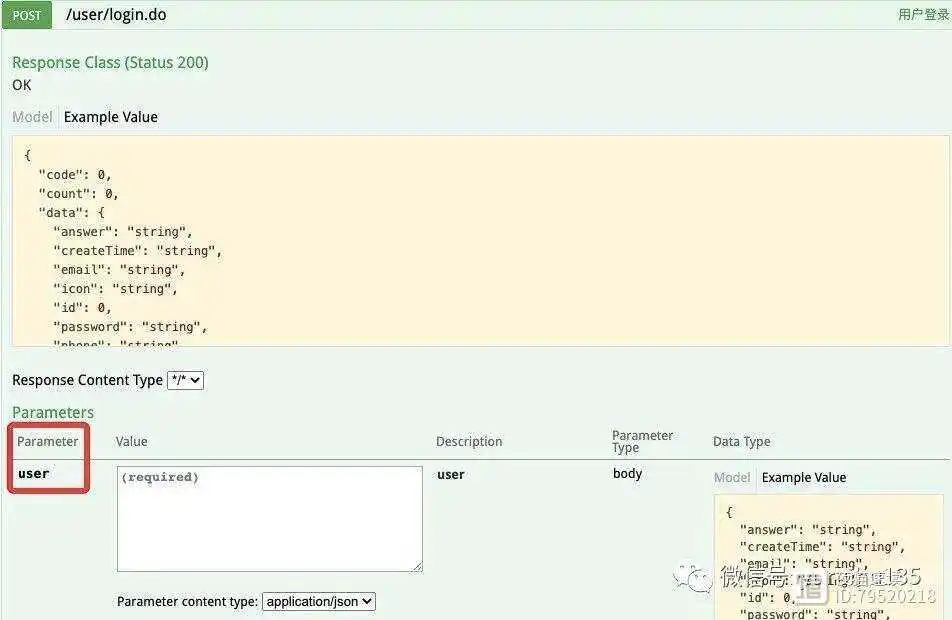
可以看到,在 Parameters 内容区中用红框圈起来的 Parameter 参数的名称就是我们使用 name 属性来描述的接口参数名称。
Tips :
- 在实际开发工作中,name 属性的值一般都是根据接口方法中的形参来描述,即接口方法中默认声明的参数名称,除非有特殊说明才可以描述与形参名称不同的值。
- 如果我们没有使用 name 属性来描述参数的名称,则参数名称默认为接口中自带的参数名称。
定义:
该属性就是对接口中的参数做一个简要的描述,即来说明接口中的参数是用来做什么的。
使用方法:
在 ApiParam 注解中声明 value 的值即可,如果没有描述则默认值为空。例如,就用户接口而言,该接口中的参数是一个用户对象,则我们可以在 value 属性中添加这样的描述:'用户对象,用于用户登录检测,必传’,如下代码段所示。
代码解释:
第1行,我们在 login 方法的上方使用了 @ApiParam 注解的 name 属性和 value 属性来对接口方法中的 user 参数做一个简单必要的说明。
显示结果:
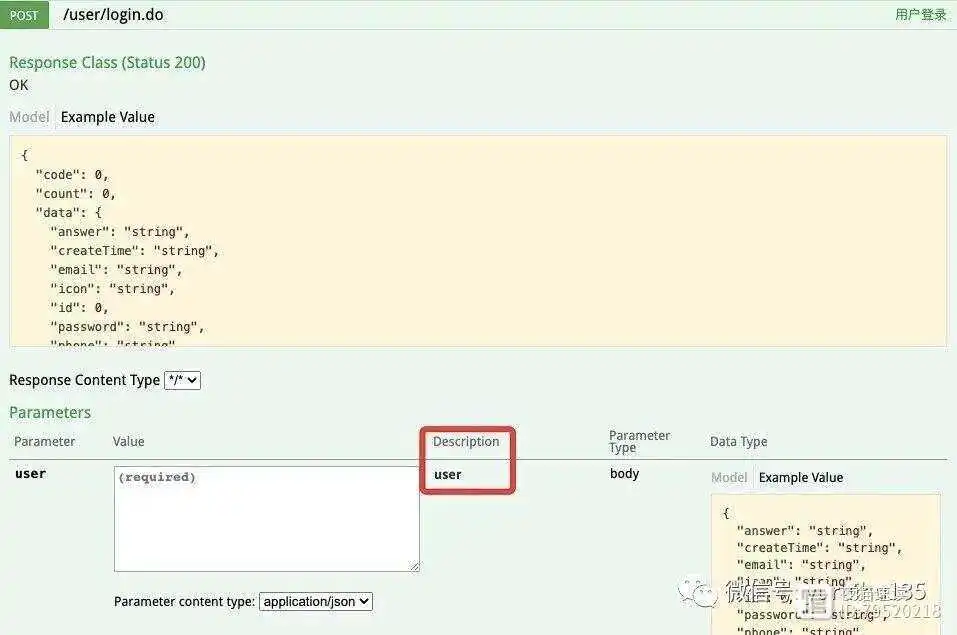
我们可以看到在 Parameters 内容区域的 Description 红框圈起来的地方并没有显示出我们使用 value 属性所描述的信息,从某种意义上(Swagger 源码角度)讲,这是 Swagger-UI 的一个 Bug ,但是从使用角度来讲可能就是我们用错了 @ApiParam 注解。
如果我们想在 Description 中显示我们所描述的信息,我们又该怎么做呢?
在本节的开篇中,就已经说明了 @ApiParame 既可以写在接口方法的上方,也可以写在接口中参数的位置,在上图中我们是把注解写在了接口方法的上方,那么现在我们来看一下,将注解写在接口中参数的位置时又是一种什么效果吧:
代码解释:
第1行,我们修改了 @ApiParam 注解的位置,把注解写到了和接口参数相同的位置,通过这种方式来对 user 参数做一个简单必要的说明。
显示结果:
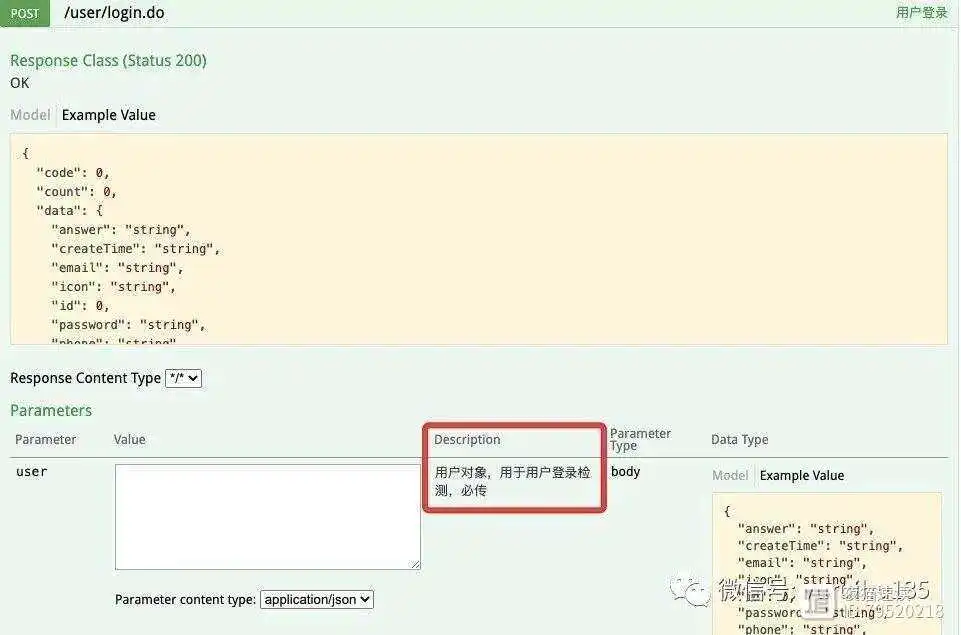
我们可以看到,在 Parameters 内容区域的 Description 位置,已经显示出了我们使用 value 来对 user 参数所描述的信息,上述两种使用 value 的情况请同学们特别注意。
Tips :
- value 属性用于描述接口中字段的说明,一般是一些必要的重要信息,不要描述很长的一段话,如果是一般简单性的描述,那还是不要写出来为好。
- 出于国人习惯的考虑,在描述 value 属性的值时,尽量使用中文来描述,这样可以做到显而易见、通俗易懂。
- 鉴于 value 属性的特殊情况,同学们在使用时应该注意:如果接口的方法参数就一个且该参数很好理解,这种情况就在接口方法的上面描述;如果接口的方法参数不便于理解,这种情况就要在接口的方法位置来描述,请同学们根据情况合理使用。
定义:
该属性就是对接口方法中的参数默认值进行描述,即对接口中存在默认值的参数进行简单的描述。
使用方法:
在 ApiParam 注解中,声明 defaultValue 的值即可,如果没有描述则默认值为空。例如,如果我想对用户接口方法中的 user 对象参数中的一个属性,添加默认值描述,那么我可以这样写 defaultValue = “ admin ”(严格来讲,user 参数的默认值应该是一个 json 串,这里为了演示就简单描述了),如下代码段所示。
代码解释:
第1行,我们在 login 接口方法的上方使用了 @ApiParam 注解的 defaultValue 属性来对用户登录接口中存在默认值的属性进行描述。
defaultValue 属性并没有直接的界面显示效果,这个作用效果可以在使用 swagger-ui 进行接口调试的时候可以很直观的看到。
当我们在传递某一参数时,如果我们没有给该参数填充数据,同时该参数被 defaultValue 属性所描述,此时该参数的数据就会变为 defaultValue 属性所描述的值了。这一点在如何使用 swagger-ui 进行接口调试小节中会详细介绍。
Tips :
- defaultValue 属性不要滥用,其用于对接口方法中存在默认值的参数进行说明,如果在接口方法中不存在有默认值的参数,那就不要使用该属性。
- 如果一个接口方法中存在多个有默认值的参数需要说明,那么请使用 @ApiParam 注解的 defaultValue 属性来对参数分别进行说明。
定义:
该属性就是对接口方法中参数传递的必要性做一个约定,即接口方法中的参数哪些是必须传递的,哪些是非必须传递的。
使用方法:
在 ApiParam 注解中,声明 required 的值即可,如果没有描述则默认值为 false , 即参数为非必须传递。例如,如果我想把用户登录接口方法中的参数描述为必须传递,那么我可以这样写 required = true,如下代码段所示。
代码解释:
第1行,我们在 login 接口方法的上方使用了 @ApiParam 注解的 required 属性来将用户登录接口中的属性描述为必须传递。
如果想要看到 required 属性的作用效果,就需要我们改变浏览器地址栏的路径了:在浏览器地址栏中输入:swagger-ui 访问路径 + /v2/api-docs(至于为什么是这个路径,在后面的文章中会详细说明),在输入完上述 url 之后我们会看到一个由多个 json 串所组成的界面,而这些 json 串的内容正是我们所写的接口。
显示结果:
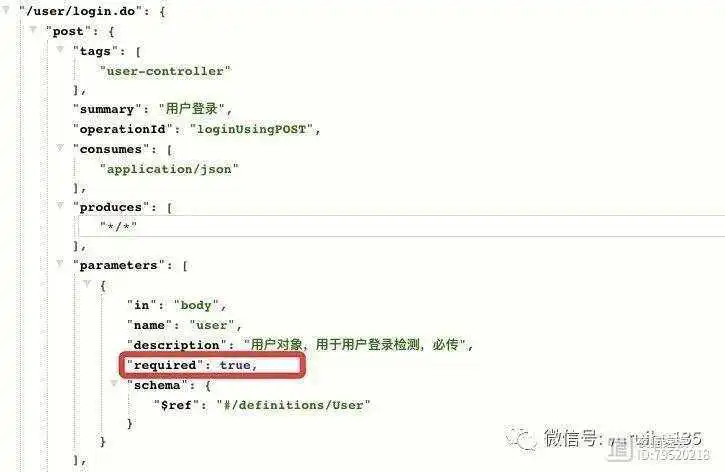
可以看到,我在用户登录接口的 json 串中用红框圈起来的就是我们使用 required 所描述的结果了。
定义:
该属性就是对接口方法中的参数的可取值范围进行描述。
使用方法:
在 ApiParam 注解中,声明 allowableValues 的值即可,如果没有描述则默认值为空,值得注意的是,使用该属性需要遵循特性的描述格式。例如,如果我想把用户登录接口方法中的参数描述为必须传递,那么我可以这样写 required = true,如下代码段所示。
代码解释:
第1行,我们在 getUserInfo 接口方法的上方使用了 @ApiParam 注解的 allowableValues 属性来对用户 id 值的可取范围做一个限制。
当我们以上述接口方法的形式来使用 allowableValues 属性时并不能在 swagger-ui 界面看到任何效果,这应该是 swagger-ui 的一个 bug ,至于使用效果如何,请看后面使用 swagger-ui 进行接口调试小节的内容。
Tips : 在实际项目开发工作中,allowableValues 使用的频率并不是很高,一般都是为了避免参数传递不合法才设置该属性。
以上是对 ApiParam 注解中经常使用的五个属性进行的详细介绍,name , values , defatluValue , required , allowableValues 掌握这五个属性的使用搭配习惯是真正用好 ApiParam 注解的重要前提。在学习这五个属性时,大家应该结合 ApiOperation 注解来对比并总结它们之间的差异,通过不断的使用来发现它们的使用规律,这一点很重要。
在详细讲解完 ApiParam 重要属性之后,下面我将针对,在 ApiParam 注解中使用频率不是很高,但是有时也会用到的一些属性做概要性讲解,这些属性分别是:access、allowMultiple、example、hidden 。
定义:
example() 属性就是描述接口方法中的一个参数的示例值。
hidden() 属性就是控制接口方法中的参数在 Swagger 界面中的显隐性。
使用方法:
example() 属性默认值为空,当我们需要对接口中的方法添加示例值描述时,可以使用该属性进行描述。例如,对于获取用户信息方法而言,需要传递的参数为用户的 id ,则我可以描述一个示例值为 1。
hidden() 属性允许我们在 Swagger 生成的接口列表界面上,控制接口方法中的参数是否需要显示,默认值为 false,即接口方法中的参数显示,为true时则接口方法中的参数不显示,如下代码段所示。
代码解释:
第1行,我们在 getUserInfo 接口方法中对 userId 参数通过 example 属性描述了示例值,对 username 进行了隐藏。
Tips :
- 接口方法中参数的显隐控制应该根据特定安全策略和特定客户需求来决定显隐,不能无故隐藏接口参数,更不能频繁的切换接口参数的显隐。
- 在实际工作中,应该根据业务要求来合理描述接口中参数的示例值,不能随便描述,更不能描述不清楚。
以上则是 ApiParam 注解中的辅助使用属性的概要介绍,对于剩下的 access、allowMultiple 属性在实际项目开发中几乎很少使用,在这里就不再介绍了,如果大家感兴趣可以去 Swagger 的官网查询相关资料来了解。

本小节对 Swagger 中另一个最经常使用的 ApiParam 注解及其该注解的各个属性做了详细的讲解,针对 ApiParam 注解中经常在实际项目开发中使用的属性采用图文并茂的方式进行了重点介绍和应用剖析,对于一些在实际项目开发中使用基本很少的注解做了概要讲解。
在学习 @ApiParam 注解及其属性时,各位同学应该对比 @ApiOperation 注解及其属性之间的使用差异,通过差异比较总结出适合自己的使用规律和使用方法才是最重要的。


大家好,今天我们开始一个新专题 — Swagger。
关于 Swagger 相信我们都在实际项目开发中使用过,它的核心知识点完全可以整理成一组专题来展开介绍,本专题我们重点讲解 Swagger 在基于 Java 生态框架的日常开发过中如何来应用。
本文我们主要先介绍一下 Swagger 是什么?有哪些特性?优缺点在哪?为什么我们需要在项目开发中应用 Swagger ?
什么是 Swagger 呢?在 Swagger 官网中是这么介绍的:
Swagger 就是一种可以帮助我们简化 API 开发过程的工具。 — 官网
我们看到,这里提到了 API 这一术语,在业界,API 一般指的是:通过后端编码而开发出来的,且可以供其他用户所使用的一种专门对外暴露的数据传输接口,即我们可以通过编写 API 来达到和用户交互的目的。俗话说无规矩不成方圆,针对 API 业界也制定了一款标准,那就是 RESTFUL API 规范,下面我们来简单介绍一下什么是 RESTFUL API 规范:
的全称是 Representational State Transfer,即表述性状态转换,或者我们可以通俗的理解为:一组具有约束条件和原则的规范。
也就是说:RESTFUL API 就是经过一组确定好的具有约束行为和统一原则的规范来规定 API 书写规则、命名规则、请求规则、响应规则的一种表述性方式。通过这个方式我们可以很好地理解具体 API 所代表的的业务场景和返回字段的含义。
通过上面的介绍,说白了,Swagger 就是一款可以简化项目 API 开发的工具,用来帮助我们通过最简单的途径来开发 RESTFUL API。
那么我们为什么要使用 Swagger 呢?
如果我们需要在项目中使用 Swagger,那么我们只需要将 Swagger 的依赖集成到项目中去,然后通过一个简单的 Swagger 配置类即可开始使用了,不需要像其他工具那样还要繁琐的去配置 xml,即配置简单,容易上手。这为我们节省了大量的时间,使得我们可以把时间用在集中处理项目业务上,提升我们的开发效率。
Swagger 通过内置 html 解析器的方式来实现将 RESTFUL API 显示在界面上供开发者查看,Swagger 提供的界面样式即简洁又美观,开发者可以很直观地看到自己所编写的 RESTFUL API 的请求方式、请求参数、返回格式以及所属业务组,如下图所示。
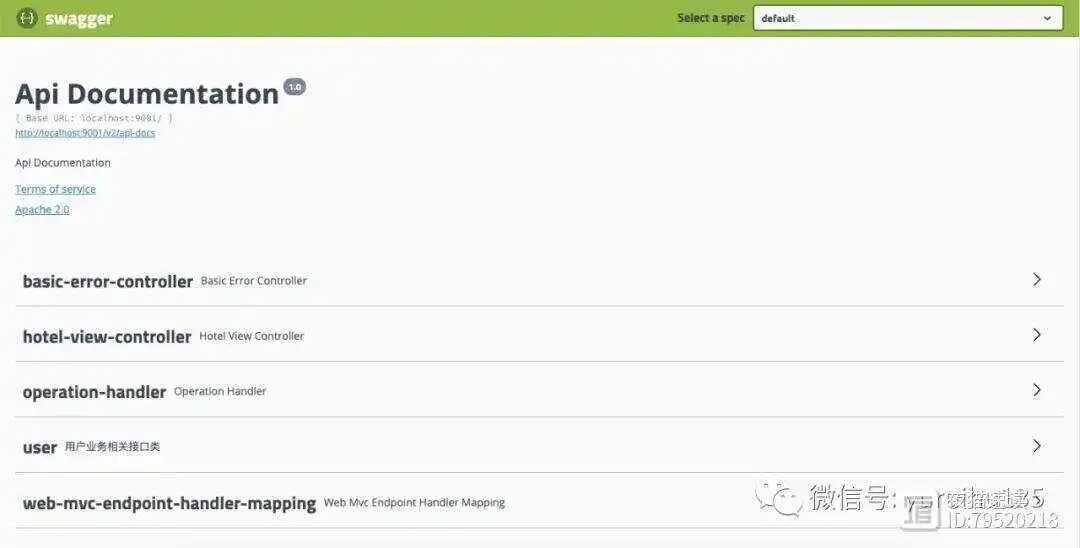
我们在开发 Java 项目的时候,主要的目的就是对外暴露我们的数据传输接口,来实现前后台数据交互的目的。
针对于我们编写的接口,往往我们需要撰写接口文档来说明具体接口所做的业务是什么,以及这个接口如何使用。这样在无形之中就加重了我们的工作内容,而有了 Swagger 之后,我们只需要在相应的地方添加 Swagger 的注解来对接口进行简单的说明,它就会帮助我们生成一份完整的接口说明,见上图。
这样一来我们就不用再编写一份几十页甚至几百页的接口文档了,提升了交互性能,同时也提升了前后台开发者的沟通效率。
总结:
Swagger 它是一个帮助开发人员来简化开发 RESTFUL API 的一款开发工具,其核心是基于 NPM 实现,在 Spring 项目中则是通过封装 SpringFox 依赖来完成对接口请求方式、请求参数、响应数据的加载,最终通过前端界面的方式来展现给用户。Swagger 具有简单、方便、高效的特性,用 Swagger 构建 RESTFUL API 可快速又方便。
Swagger 从 2011 年发布至今已经有 9 个年头,期间已经迭代升级了很多版本,现在最新的版本是 v3.18.3,每个版本都有不同的特性,下面主要介绍一个主要使用的版本和新版本的特性。
- V1.0.1 - 1.0.13: 最初发布版本,基本已经很少使用了。
- V2.X.X: 目前使用较多的版本,也是我们这个课程使用的版本。
- V3.18.3: 目前发布的最新版本,2018 年 8 月 3 日发布的。主要是优化了接口组的使用方法、美化了 RESTFUL API 界面显示效果。最新版本可能会导致部分项目无法正常使用,这个时候需要回退到 2.X.X 版本即可。
- 导出格式灵活 : 支持 Json 和 yml 来编写 API 文档,并且支持导出为 json、yml、markdown 等格式。
- 跨语言支持性 : 只针对 API,而不针对特定语言的 API,很多自动生成 API 的工具基本都是只针对特定的 API。
- 界面清晰易懂 : 界面清晰,无论是 Editor 的实时展示还是 Swagg-UI 界面的展示都十分人性化,简单明了。
- 无法自定义界面 : Swagger-UI 封装好了一套 Html 模板,任何 RESTFUL API 的展示形式只能遵循其格式,不能灵活修改。
- 官方文档不全面 : Swagger 官方针对不同的模块提供了不同的介绍文档,但是缺乏系统的介绍,不利于新人学习。
本节是本套课程的开端,主要介绍了什么是 Swagger ,为什么使用 Swagger ,以及 Swagger 优缺点等。
本套课程主要针对 Swagger-UI 在 SpringBoot 开发框架中的使用,本节内容是学习本套课程的开端。
在本节中将为大家介绍如何使用 SpringBoot 来集成 Swagger-UI ,包括集成 Swagger-UI 的具体详细步骤,以及在集成过程中的一些注意事项。
重点讲解内容:
- SpringBoot 主流开发框架与 Swagger-UI 工具的集成步骤。
- 集成过程中的一些经验和注意事项、Swagger-UI 不同版本与 SpringBoot 框架兼容问题。
我们知道,使用 Maven 来创建的项目会有专门的一个 pom.xml 文件,这个文件是我们项目中所有用到的工具包的一个列表,在 java 中被称作 jar 包。在 Maven 中通过引入不同的 jar 包坐标配置来将相应的工具集成到我们的项目中。
所以当我们需要在项目中集成某种工具时,我们需要将该工具对应的坐标放到 Maven 的 pom.xml 文件中去。
通过访问 Maven 的中央仓库我们可以搜索到 Swagger-UI 对应 SpringBoot 框架适合的坐标数据,如下 Maven 坐标所示:
在上述 Maven 坐标中,第一个 springfox-swagger2 依赖,为 Swagger 2 的核心依赖,即我们如果想使用 Swagger 工具,则必须要在项目中引入该依赖,如果我们没有引入该依赖,那么我们是不能在项目中使用 Swagger 的。
而 springfox-swagger-ui 这一依赖,就是我们本文所介绍的 Swagger-UI 的依赖,如果我们不引入该依赖,我们是不会看到 Swagger 的 API 管理界面的。
在将上述两个 Swagger 的坐标数据放到我们项目的 pom.xml 文件中去之后,我们就完成了集成 Swagger-UI 的准备工作。
这样引入的 Swagger-UI 我们只能使用它的注解,而这时所产生的 Swagger-ui 界面我们是看不懂的,因为我们还没有对界面增加我们的规定,所以接下来让我们完成 Swagger-UI 的一些基本配置。
由于 SpringBoot 框架简化了传统 Spring MVC 框架中繁琐的 xml 文件配置,所以我们在对 Swagger-UI 进行配置时只需要使用两个注解和一个配置类即可完成,SpringBoot 为我们提供了两种配置方法,让我们来看一下吧。
Tips : 在接下来的两种配置方法中,主要介绍 Swagger-UI 的集成注解,而对于配置类我会单独进行详细讲解,请同学们注意。
Swagger-UI 官方针对 SpringBoot 框架推出了很方便的开放 API ,我们在引入了 Swagger-UI 的 Maven 坐标之后,只需要在 SpringBoot 应用的启动类的上方加入开启 Swagger-UI 的注解即可在项目中来使用 Swagger-UI。

在上图中,我添加了 @EnableSwagger2 注解,这正是 Swagger-UI 官方在 SpringBoot 框架中提供的开启使用 Swagger-UI 的注解。
当我们在项目的启动类上方添加了 @EnableSwagger2 注解之后就表示我们可以在项目中来使用 Swagger-UI 了。
Tips : 如果我们只引入了 Swagger-UI 的依赖,没有配置 @EnableSwagger2 注解,那么在项目中我们也是无法使用 Swagger-UI 的,这一点需要同学们特别注意。
对于 Swagger-UI 的配置类来说,我们只需要新建一个配置类并将该配置类通过添加 @Configuration 注解来注入到我们的项目中即可。
以上是配置 Swagger-UI 的第一种方法,即通过 @EnableSwagger2 注解与 @Configuration 注解相分离的方式来配置,这种配置方式相对来说好理解一些。
Tips:
- 各位同学在集成 Swagger-UI 时,依赖的版本请务必和老师保持一致,避免由于版本原因而出现的未知问题。
- SpringBoot 框架版本请选择 SpringBoot 2.0.X.RELEASE 及以上版本或 SpringBoot 的里程碑版本。
- @Configuration 注解贯穿整个 SpringBoot 框架,有不懂的同学请自行了解。
在第一种方式中我们将两个注解进行了分开配置,这种方法通俗易懂,而在本方式中,会将两个注解集中来配置。
我们新建一个类,名为 Swagger2Config ,这个类就是我们后续要讲的 Swagger-UI 配置类了,然后我们在该类的最上方添加上述两个注解:

在上图中,我们通过在启动类中添加 @Configuration 注解的方式将配置类以及 Swagger-UI 的所有注解来一起注入到我们项目中去,这与第一种方式的不同之处在于:
第一种方式, @EnableSwagger2 注解的声明没有通过 @Configuration 注解来处理,而是通过 SpringBoot 应用去自动装配;第二种方式则是将配置类和 Swagger-UI 的所有注解都通过 @Configuration 注解来处理,不通过 SpringBoot 应用去自动装配。
而上述两种方式并不会影响项目的正常运行,所以我们采用任何一种方式都是可取的。
在本部分中,老师将带领大家针对 Swagger-UI 常用的基本配置属性以及其他额外属性进行详细讲解,下面我们来看一下 Swagger-UI 都需要在 SpringBoot 框架中配置哪些属性(所有属性都根据官方配置演变而来)。
创建 Swagger 应用配置:

代码解释:
createRestApi 方法的返回值是一个 Docket 类型,该类型就是返回 Swagger-Documentation 类型的数据,大家不用关心。
在方法内部,使用匿名内部类的方式实例化了一个 Docket 对象并返回,DocumentationType 即文档类型的选择我们需要根据集成的 Swagger 的版本来选择,这里选择 SWAGGER_2 表示使用的 Swagger 是2.X系列版本。
apiInfo() 和 select() 这两个方法是配置 Swagger 应用的必要方法,我们只需要这样理解就可以了:集成必要的 API 信息(apiInfo() 方法)来供我们查询(select() 方法)使用。
apis() 方法里面通过 RequestHandlerSelectors.basePackage() 属性来描述我们的目标包,就是我们项目中接口所在包的完整目录名称,这样 Swagger 就可以扫描到了,如果不配置此项,Swagger 是扫描不到我们项目中的接口的。
paths() 方法就是规定将我们项目中所有接口的请求路径都暴露给 Swagger 来生成 Swagger-UI 界面。
build() 方法就是将我们设置的上述参数都放到返回的 Docket 实例中。
创建 Swagger-UI 界面基本信息配置:
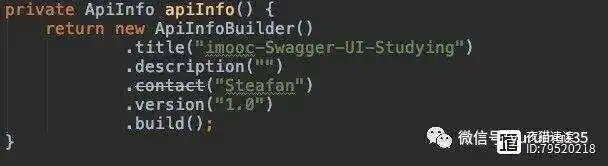
代码解释:
apiInfo 方法返回 Swagger-ApiInfo 类型,大家可以理解为返回 Swagger-UI 界面的基本信息就行了。在方法内部也是通过匿名内部类的方式返回一个 ApiInfo 实例。
title() 方法:就是来规定我们的 Swagger-UI 界面的大标题。
description() 方法:就是来规定对 Swagger-UI 界面的一些简单描述信息。
contact() 方法:就是来规定创建 Swagger-UI 的作者的名称,目前已被废弃。
version() 方法:就是来规定 Swagger-UI 界面上所有接口的版本。
build() 方法:就是将我们设置的上述参数都放到返回的 ApiInfo 实例中。
通过上述两个方法的配置,我们就完成了 Swagger-UI 的基本配置,启动项目之后,在浏览器地址栏中输入访问路径(一般为项目 ip 地址:端口/swagger-ui.html)就可以在浏览器中看到 Swagger-UI 的界面效果了。
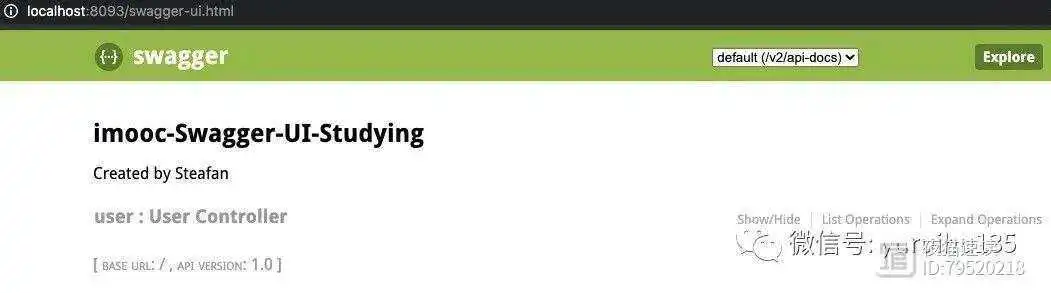
Tips:
- 访问路径中的 swagger-ui.html 为默认固定写法,一般不用修改。
- createRestApi() 方法为 public 方法,即这个方法需要对外暴露才行,而 apiInfo() 方法为 private 私有方法;该方法的用途是配置 Swagger-UI 界面基本信息,只能在项目中进行配置,不能将配置权限暴露出去。
- 在 apiInfo() 方法中我们不需要写太多的信息,因为一些必要的信息都是在接口中来描述的。
本小节从 Swagger-UI 集成准备工作开始,到不同的配置集成方式,再到最后对 Swagger 配置类的详细阐述,从零到一的对 SpringBoot 如何集成 Swagger-UI 进行了详细的讲解,旨在帮助大家能够准确的集成 Swagger-UI ,对于在集成中容易出现的问题,老师也做了相应的提醒和解决建议,希望各位同学都能成功在 SpringBoot 中集成 Swagger-UI。
针对 Swagger-UI 界面上的每一个组成元素在这里就不系统介绍了,后面会有专门的小节来对 Swagger-UI 界面的组成元素以及如何使用 Swagger-UI 进行简单必要的接口调试进行系统性地详细介绍,请各位同学关注。
本节会结合一个用户登录接口给大家介绍 Swagger 中核心注解之一 ApiOperation 及所提供的常用属性。
ApiOperation 注解在 Swagger 中扮演着非常重要的角色,基本上只要使用 Swagger 那就必须要用 ApiOperation 注解。
希望大家在学习本节过程中能够分清主次,有的放矢。
在我们日常工作中,后端小伙伴们经常会写一些接口,为了方便让大家知道这些接口的功能作用,我们就需要给接口添加一些具体的描述信息,为此,在 Swagger 中,我们就需要使用 ApiOperation 注解来描述我们写的接口。
ApiOperation 注解提供了丰富的属性来允许我们自定义接口描述信息,包括接口名称,接口所属分组等。
下面我们来看一下 ApiOperation 注解中都包括哪些主要属性。(注意:我们只介绍还在使用的属性,那些被 Swagger 官方已经废弃的属性不再介绍)。
定义:
该属性就是描述接口的作用是什么,即接口是用来干什么的。
使用方法:
在 ApiOperatio 注解中声明 value 的值即可。例如,就用户登录接口而言,只需要将 value 的值写为 '用户登录’就好了,这样我们就能很清楚的知道这个接口就是来做用户登录用的,如下代码段所示(现在你不需要理解业务代码代表什么意思,重点看方法上使用的注解及属性即可,下同)。
代码解释:
第 1 行,我们在 userLogin 方法的上方使用了 @ApiOperation 的 value 属性来描述接口的作用。
显示结果:
在结果显示界面的右上角就是我们使用 value 属性描述的信息(用户登录)。
Tips : 项目中的接口文档可能需要看的人很多,不只是开发人员看,客户有时候也要看,所以 value 属性值的描述,应该本着通俗易懂的原则进行,一定要根据接口方法实现的具体业务内容来描述,不能随便描述,不能使用表意不清楚的词语来描述,更不能使用专业术语来描述。
定义:
该属性就是对实现相同业务场景的接口做一个分组。
使用方法:
在 ApiOperatio 注解中声明 tags 的值即可,如果没有描述则默认值为空。例如,就用户登录接口而言,该接口属于用户业务分组中,所以我们将 tags 的值描述为'用户’或者'user’,这样我们就能很清楚的看到这个接口是属于用户业务组的,如下代码段所示。
代码解释:
第 1 行,我们在 userLogin 方法的上方使用了 @ApiOperation 注解的 tags 属性来描述接口所属的业务分组。
显示结果:
我们可以看到在顶部有一个 user 字样,这个就是我们规定的分组名称,也就是 tags 里写的 user 了。
Tips:
- 在实际项目开发工作中,往往一个接口可能涉及多个业务,这种情况需要我们对接口进行多个分组,而 tags 属性的类型是字符串类型的数组,可以描述一个或多个值,如存在多值时,应该使用如下方法来描述。
- tags 属性值的描述规则同上述 value 属性。
定义:
该属性就是对接口方法做进一步详细的描述。
使用方法:
在 ApiOperatio 注解中声明 notes 的值即可,如果没有描述则默认值为空。例如,如果我想添加对用户登录接口的详细描述信息,那么我可以这样写 notes = “用户登录接口必须是 post 请求”,这种使用效果会直接显示在接口面板中,当做接口的主要内容进行显示,如下代码段所示。
代码解释:
第 1 行,我们在 userLogin 方法的上方使用了 @ApiOperation 注解的 notes 属性来进一步描述接口的详细信息。
显示结果:
在我用红框圈起来的地方我们可以看到 Implementation Notes 下放就是我们对该接口的进一步详细描述,其显示在了接口的主要内容区域里面。
Tips :
- notes 属性一般用来描述接口的一些必要详细信息,如果是一般的信息则最好不要使用 notes 去描述。
- 使用 notes 属性来进一步详细描述接口这一行为往往在项目开发中不是必须的。
以上是对 ApiOperation 注解中经常使用的三个属性进行的详细介绍,value,tags,notes 这三个属性不管是在项目开发中,还是在需求沟通中,使用的都很频繁,所以,真正掌握这三个属性是用好 Swagger 的重要前提。在学习这三个属性时,大家应该自己对比并总结它们之间的差异,通过不断的使用来发现它们的使用规律,这一点很重要。
在详细讲解完 ApiOperation 重要属性之后,下面我将针对在 ApiOperation 注解中,使用频率不是很高,但是有时也会用到的一些属性做概要性讲解,这些属性分别是:httpMethod、nickname、protoclos、hidden、code。
定义:
httpMethod () 属性就是对接口的请求类型进行一个约定,常用的接口类型有:“GET”, “HEAD”, “POST”, “PUT”, “DELETE”, “OPTIONS”。
nickname () 属性是为接口起一个别名,方便前后端沟通使用。
使用方法:
httpMethod () 属性默认值为空,但是 Swagger 在处理时会默认获取项目所采用的接口请求类型,我们可以不用专门设置,如果一定要设置该属性,则只允许设置 http 协议规定的属性,不能随意设置。
nickname () 属性允许我们为接口设置一个别名,在设置别名之后,我们设置的别名会出现在浏览器地址栏中,如下代码段所示(httpMethod () 属性自动获取值,这里不再演示)。
代码解释:
第 1 行,我们在 userLogin 方法的上方使用了 @ApiOperation 注解的 nickname 属性来为接口起一个别名。
显示结果:
在我用红框圈起来的地方我们可以看到 userLoginNickName 字样,这就是我们为接口所设置的别名。
Tips :
- 不要随意定义接口的别名,要根据特定业务场景来设置。
- 在项目前后端联合测试过程中,给接口起一个别名更方便前后端开发人员的沟通,并没有其他特殊意义。
定义:
protocols () 属性就是对接口所使用的网络协议进行一个约定,常用的网络协议有:http、https。
hidden () 属性就是控制接口在 Swagger 界面中的显隐性。
code () 属性就是控制接口的返回状态,常见的有:200,201,404,500 等。
使用方法:
protocols () 属性默认值为空,但是 Swagger 在处理时会默认获取项目所采用的网络协议,我们可以不用专门设置,如果一定要设置该属性,则只允许设置 http 协议规定的属性,不能随意设置,http, https, ws, wss 这些都是被允许的。
code () 属性一般不用特定设置, Swagger 会自动生成接口返回状态,这里不再演示。
hidden () 属性允许我们在 Swagger 生成的接口列表界面上控制接口是否需要显示,默认值为 false,即接口显示,为 true 时则接口不显示,如下代码段所示。
代码解释:
第 1 行,我们在 userLogin 方法的上方使用了 @ApiOperation 注解的 hidden 属性来隐藏我们的接口。
显示结果:
可以看到在接口列表界面,已经看不到我们的用户登录接口了,这就是当 hidden 属性设置为 true 时所起的作用。
Tips :
- 接口的显隐控制应该根据特定安全策略和特定客户需求来决定显隐,不能无故隐藏接口,更不能频繁的切换接口的显隐。
- 在实际工作中,如果需要隐藏接口则需要和项目组报备情况,说明原因。
以上则是 ApiOperation 注解中的辅助使用属性的概要介绍,对于剩下的 response、responseContainer、responseReference、produces、consumes 属性在实际项目开发中几乎很少使用,在这里就不再介绍了,如果大家感兴趣可以去 Swagger 的官网查询相关资料来了解。
本小节对 Swagger 中最经常使用的 ApiOperation 注解及其该注解的各个属性做了详细的讲解,针对 ApiOperation 注解中经常在实际项目开发中使用的属性采用图文并茂的方式进行了重点介绍和应用剖析,对于一些在实际项目开发中使用基本很少的注解做了概要讲解。通过这样系统的讲解,希望大家从注解属性的定义到具体使用规范全过程中彻底搞懂 ApiOperation 注解及其注解各属性的语义规则、使用场景、注意事项等。


大家好,今天我们这个专题的主角是 — Maven。Maven 作为我们开发当中比较常见的项目管理工具,用来帮助我们构建项目,管理依赖。Maven 目前是 Apache 基金会托管的顶级项目之一,诞生自 2003 年,现在已经 17 岁了。本文当中,我们将介绍 Maven 是什么,Maven 的优缺点有哪些,为什么我们要使用 Maven。
那究竟什么是 Maven 呢,在 Maven 的官网上可以看到如下的解释:
Apache Maven is a software project management and comprehension tool. Based on the concept of a project object model (POM), Maven can manage a project’s build, reporting and documentation from a central piece of information.
翻译过来就是:Maven 是一个软件工程的项目管理工具,基于工程对象模型(POM),Maven 可以从中央信息篇中来构建项目,生成报告和文档。
从上面的介绍中,我们可以看到 Maven 的主要功能是管理项目,构建项目。
关于 Maven 的由来,据其创始人者 Jason Van Zyl 描述,是为了更加便利地建设 Jakarta Turbine 项目而创立的一个项目。在当时,比较流行的项目构建工具是 Ant,但是,在这个阶段中,各种 Java 项目之间是没有什么规范的,新创建项目的时候,就需要重新编写对应的构建脚本。Jason 就相对应设计出一套标准的项目结构,标准的构建方式,用来简化项目的构建。2003 年的时候,Maven 已经是 Apache 基金会的顶级项目了。
很多著名的项目,都是历史的产物。在当时,随着 Java 语言的流行,越来越多的项目开始使用 Java ,但是当时的构建工具并不能简单快速地完成项目构建的流程,在这种背景下,一个简单,方便,标准化的构建工具-- Maven 就产生了。
从 Maven 的官网中我们就可以看到以下几个特点:
- Making the build process easy:意思是简化构建过程,顾名思义,让构建的过程来得更简单;
- Providing a uniform build system:意思是提供统一的构建系统,Maven 提供了一个统一的构建系统。例如:Maven 使用 POM 模型以及一系列的相关插件供开发者来使用;
- Providing quality project information:意思是提供优质的项目信息,在使用 Maven 的过程中,你可以通过 Maven 来获得很多关于项目的信息,例如:已经覆盖的单元测试报告,项目的依赖列表等等;
- Providing guidelines for best practices development:意思是提供最佳实践开发指南,Maven 致力于整合开发过程中的最佳实践,并引导人们朝着这个方法前进。例如:在项目过程中 Release 版本和 snapshot 版本的管理,以及 Maven 项目标准化的项目目录结构。
总之呢,Maven 的核心是约定大于配置,它的初衷就是帮助程序开发者在最短时间内完成项目开发过程中的每个过程,目标就是更简单,更统一,更快速。
- Maven 的整个体系相对庞大,想要完全掌握相对困难;
- 如果项目的依赖过多,在第一次导入项目的时候需要花很长的时间来加载所需要的依赖;
- 由于某种不可抗拒力,国内的开发者在使用 Maven 中央仓库的时候,下载速度过慢。
但是,这些问题都是有可以有解决办法的,我们后续会慢慢一一介绍。
在 Java 开发的世界中,有三大主流的构建工具,分别是 Ant ,Maven ,Gradle。
其中 Ant 出现的世界最早,能够提供编译、测试、打包的功能,但是 Ant 缺乏对依赖的管理,以及标准的项目结构。
后来 Maven 的出现,解决了 Ant 所不能满足的两个问题,从创建项目到构建及发布项目的整个过程定义了一套完整的规范,并且提供中央仓库,对依赖进行管理。
后来,随着 Android 的流行,近年来,以 Gradle 作为项目的构建工具也越来越流行。Gradle 在 Maven 的基础上,使用基于 Groovy 的特定领域语言(DSL)来完成配置声明,相较于 XML 来说,更加灵活。目前,Maven 和 Gradle 基本上算是平分秋色的局面,在实际的开发中,后台项目管理更倾向于使用 Maven,而在移动端开发中,Gradle 的占比更大。当然两者之间也有很多相通的地方,比如依赖管理,一致的项目结构。
Maven 从发布到现在已经经历过很多个版本迭代,目前最新的版本是 2019-11-25 发布的 Maven 3.6.3 版本。
- 1.0-2.x : 官方不再进行维护,也不建议开发者使用;
- 3.0: Maven3.x 的第一个版本,也算是 Maven 的里程碑版本,完全向后兼容 Maven2,增加了 SLF4J 来进行日志管理,并且提高了项目构建效率和插件的扩展性;
- 3.5.0: 该版本显著的变化是 Maven 的控制台支持不同级别日志输出不同颜色;
- 3.6.3: 目前的最新版本,schemaLocations 地址支持 https。在后续的章节中,我们也会用这个版本来进行讲解。
说到这个问题,我们首先要看一下,如果没有 Maven,那么我们的工作是什么样子的呢?
场景一
当我们在开发过程中,当我们开发某个新功能或者修复了某个 Bug,都需要手动进行整个项目编译,运行单元测试,生成项目文档,打包,部署环境这些步骤。一旦需要重新修改代码的时候,便要将上述的操作重复一遍。机械性的重复劳动充斥着整个开发过程;
场景二
由于不同的人可能会有不同的习惯或者说是个人偏好,每当我们新建一个项目的时候,所建出来的项目可能会千奇百怪,这也给后续的维护升级带来了诸多的不便;
场景三
当项目需要依赖某个 jar 包的时候,需要到互联网上去寻找对应的 jar 包,找到 jar 包之后,将这个 jar 包添加到项目的 lib 目录下,项目组里面不同的人可能会找到不同的 jar 包,不同的 jar 包直接可能会存在冲突,这个时候,就需要去手动解决冲突;
看到这里,只想说一句,我太难了。但是,不要慌,Maven 的存在,就是为了帮助解决这些问题。
使用 Maven 之后,只需要执行一个命令就可以完成编译,运行单元测试,打包,部署的整个流程;并且 Maven 以 POM 的形式来管理 jar 包依赖;还有一点就是,使用 Maven 构建出的项目,结构统一,方便后续的维护升级。
本教程当中使用了一些 Java 项目作为例子,所以需要了解简单的 Java 基础。
在本课程中,我们首先会对 Maven 的核心概念进行讲解,并且,通过一些简单的项目,来加深对这些概念的理解,在课程的过程中,如果遇到平时工作时常使用的点,则会穿插一些实际工作中的最佳实践,方便在工作中能够学以致用。
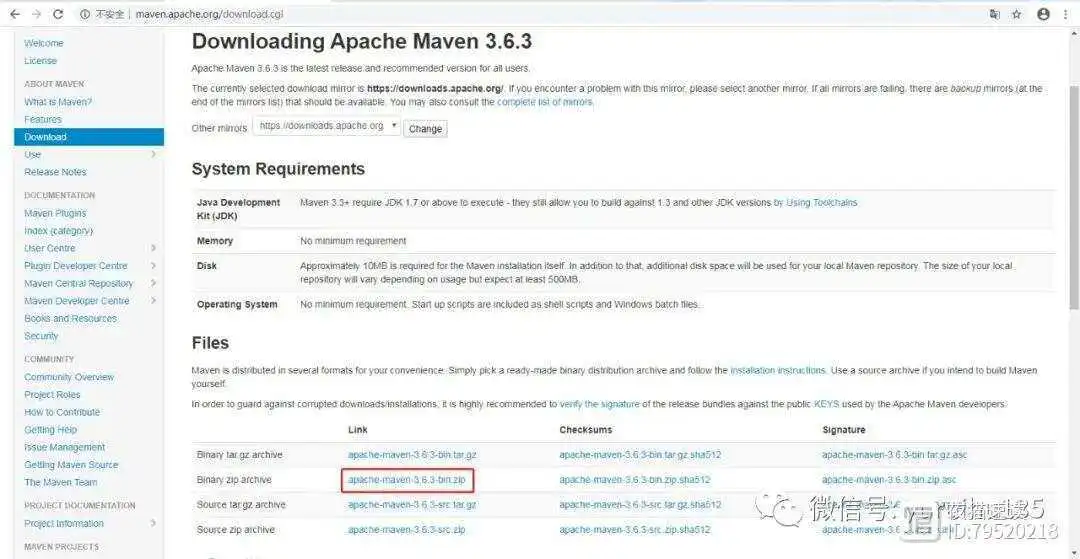
在上一节中,我们对 Maven 有了一个大概的了解,了解到 Maven 有很多优点,那么我们今天就来介绍,如何在 Windows 环境中安装和配置 Maven。在教程中,我们使用的 Maven 版本是 3.6.3 版本,jdk 版本是 1.8。
首先在 Maven 官网上,找到下载地址,并下载该版本apache-maven-3.6.3-bin.zip,如下图所示:
由于 Maven 是使用 Java 开发的工具,因此需要先安装 jdk。Maven3.6.3 版本需要 jdk1.7+ 版本来支持,本教程使用的是 jdk1.8 版本。
Tips:jdk 的安装过程在这里我们就不多赘述了,同学们可以参考下慕课网相关 Wiki 进行安装。
打开 cmd 运行窗口输入:,如下图所示,能够正常查看 Java 版本信息即说明 jdk 安装成功:

将 Maven 的安装包复制到指定目录中,并解压该安装包。解压后在 Maven 的 bin 目录下进入 cmd,输入 mvn -v,可查看 Maven 版本信息。

但是,现在我们只能在 Maven 的 bin 目录下执行 mvn 命令,无法随时随地使用 Maven,因此,我们需要将 Maven 的路径配置到环境变量当中。
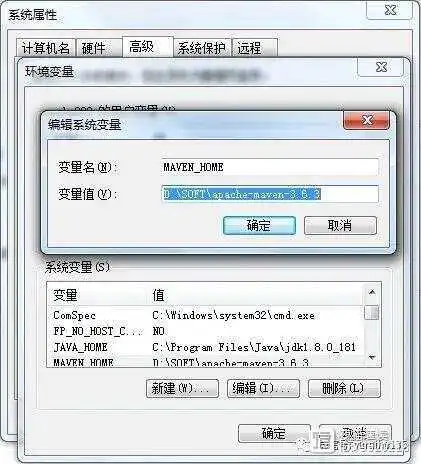
新增了 MAVEN_HOME 之后,需要将 %MAVEN_HOME%bin 追加到 path 当中,需要注意的时候,追加的时候需要在前面加一个 和 path 中之前我们添加的环境变量做一个分割:
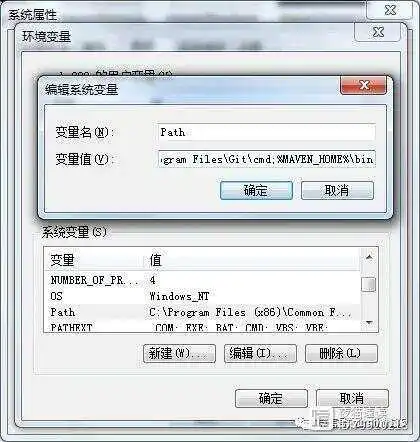
在追加完 path 之后,我们在任意目录下执行 mvn -v 命令,都可以正常查看 Maven 版本信息,即为配置成功。
在 Linux 系统中,需要使用 tar 包来进行安装。我们可以去官网下载对应安装包(apache-maven-3.6.3-bin.tar.gz),也可以使用 Linux 系统中的 wget 工具来进行下载。这里我们使用 wget 工具来进行下载。
我们可以从阿里云的镜像站中下载,速度更快些。
进入到需要下载的目录,我们这里的目录地址是,进入该目录后,执行 wget 命令,。
执行
打开配置文件 在文件的最后添加如下配置:
保存文件后,执行 命令。
此时,切换到任意目录下,执行命令 。可以看到当前 Maven 的版本信息。

在 Mac 环境中安装 Maven 和在 Linux 环境下安装 Maven 的步骤和过程大体是相同的,只不过在 Mac 环境中的环境变量文件位置是 `~/.bash_profile``,所以在这个文件中添加环境变量即可。
我们在将 Maven 安装好之后,为了方便我们后面的使用,可以对 Maven 进行简单的配置。
进入 Maven 路径下的 conf 目录,打开 setting.xml 文件。
在 Maven 的使用过程中,会自动将项目依赖的 jar 包从中央仓库下载到本地仓库,默认本地仓库路径是,这样的话,会占用较多的 C 盘空间,因此,我们可以自定义该路径。

由于 Maven 中央仓库的服务器是架设在国外的,所以由于某种不可抗拒力量,国内用户如果直接使用中央仓库的话,下载速度会受很大的影响。如下图所示,个人用户可以使用阿里云镜像。这里阿里云仓库是作为中央仓库的一个镜像的,镜像库会完全屏蔽被镜像库。
镜像地址:
经过上面的简单配置之后,我们就可以开心地使用 Maven 了。
配置好 Maven 之后,接下来我们就可以使用 Maven 来创建我们的第一个项目了。
在 cmd 中切换到我们存放代码的目录,并执行如下命令:
参数说明:
- -DgourpId: 组织名,一般为公司网址的反写;
- -DartifactId: 项目名-模块名;
- -DarchetypeArtifactId: 用来指定 ArchetypeId,这里用到的是maven-archetype-quickstart,即创建一个简单 Java 应用;
- -DinteractiveMode: 是否使用交互模式。
项目创建好之后,会有如下提示:
Tips:由于是第一个Maven项目,在创建的时候,需要下载 Maven 插件,所以耗时会相对长一点。
接下来,我们将该项目导入到 Idea 中,来查看该项目。
点击运行后,可以正常输出 Hello World!
Your browser does not support the video tag.
Your browser does not support the video tag.
本节,我们主要讲了如何在 Windows 环境下安装 Maven 以及修改简单配置,并且使用 Maven 创建运行了一个 Java 应用。
5. 小结
本节中,我们介绍了 Maven 中的一个重要的概念–依赖,介绍了什么是依赖,以及依赖的几个特性,最后我们也总结了在平时的工作中常常会用到的依赖优化的方式,能够帮助我们更好的管理项目的依赖。
在上一节当中,我们使用 Maven 创建了我们的第一个项目,今天我们来介绍一下 Maven 中重要的概念 POM 模型。
POM(项目对象模型)是 Maven 最基本,也是非常重要的一个概念。通常情况下,我们可以看到 POM 的表现形式是 pom.xml,在这个 XML 文件中定义着关于我们工程的方方面面,当我们想要通过 Maven 命令来进行操作的时候,例如:编译,打包等等,Maven 都会从 pom.xml 文件中来读取工程相关的信息。
我们在 cmd 中打开项目根目录,执行 命令。可以看到如下图的项目结构:
- 每个项目都有一个 pom.xml 文件,该文件中定义本项目的对象模型,描述本项目,配置插件,声明依赖;
- 对于简单的 Maven 项目, 目录放置项目的源码和资源文件,一般情况下,源码放置在 Java 目录下,App.java 就是 Maven Archtype 插件生成的一个简单类,classpath 资源文件放置在resources 目录下。
- 目录下放置我们的测试用例,与 main 目录类似, 目录下放置我们的测试类源码, 则是 Maven Archtype 插件生成的一个简单测试类, 放置测试用到的 classpath 资源文件。
注: 这里 Maven 只是帮我们创建了一个简单的 Maven 项目,其中 resources 目录则需要手动创建。
我们打开项目中的 pom.xml 文件,如下图:
现在看到的这个 pom.xml 是 Maven 项目中最基础的 POM,后面随着项目的慢慢的进行,这个 pom.xml会变得更加复杂,我们可以向其中添加更多的依赖,也可以在里面配置我们需要的插件。
从头开始看:groupId,artifactId,packaging,version 几个元素是 Maven 的坐标,用来唯一标识一个项目。
接下来是 name,url 这两个元素则是用来描述信息,给人更好的可读性。
最后是 dependencies,这里 Maven 默认依赖了 3.8.1 版本的 junit,其中 scope 用来标记该依赖的范围为 test。
接下来我们就重点介绍一下 Maven 的坐标(Coordinates)。
- groupId:groupId 为我们组织的逆向域名,这里的组织可以是公司,团体,小组等等。例如Apache 基金会的项目都是以 org.apache 来作为 groupId 的;
- artifactId:该组织下,项目的唯一标识;
- packaging:项目类型,描述的是项目在打包之后的输出结果,常见的 jar 类型的输出结果是一个jar 包,war 类型则输入 war 包,一般 Web 项目的打包方式为 war。
- version:项目的版本号,用来标记本项目的某一特定版本。SNAPSHOT 则是用来标记项目过程中的快照版本,该版本类型表明本项目不是稳定版本,常见的还有 RELEASE,则表示该版本为本项目的稳定版本。
在我们这个项目的 pom.xml 文件中,只有短短的几行信息,但是这就全部吗?其实不然。
在 Maven 的世界中,存在着一个超级 POM(super POM),所有通过 Maven 创建的项目,其 pom.xml 文件都会继承这个超级 POM。所以在默认情况下,使用 Maven 创建出来的项目基本上都是很类似的。
那么这个超级 POM 在哪呢?长什么样呢?
如下图,先找到指定的 jar 包,路径::
然后我们可以使用解压工具查看该 jar 包,找到对应的 pom.xml。
具体路径:。
对于我们的项目,我们称超级 POM 为父 POM,我们项目中的 POM 为子 POM,一般情况下如果父子 POM 中存在相同的元素或者节点,那么子 POM 会覆盖父 POM 的元素或者节点(有点类似 Java 中的 override),但是,也会有这么几个例外存在:
- dependencies;
- developers 和 contributors;
- plugins;
- resources。
子 POM 在继承这些元素的时候,并不会直接覆盖,而是在其基础上继续追加。
本节中,我们介绍了 Maven 的 POM 模型,查看 Maven 工程的 pom.xml 文件,以及 pom.xml 文件中的坐标,最后我们还介绍了超级 POM,这样,我们就对 Maven 的 POM 模型有了一个基本的认识。
在上一节中,我们重点介绍了 Maven 的项目对象模型(POM),本节我们重点介绍另一个重要概念–依赖。我们会介绍什么是依赖,以及在我们平时的工作中的最佳实践。
依赖即为本项目对其他项目的引用,这里的其他项目可以是外部项目,也可以是内部项目。我们在开发项目的过程中,将其他项目作为依赖引用进来,最终在打包的过程中,依赖会和我们开发的项目打包到一起来运行。
在我们的项目没有使用 Maven 的时候,我们需要手动去管理我们的依赖,例如:添加依赖,删除依赖。在使用了 Maven 之后,我们可以在 pom.xml 文件里面看到我们所有的依赖,并且可以灵活的管理项目的依赖。
Maven 在编译和运行以及执行测试用例的时候,分别会使用不同的 classpath。而 Maven 的依赖范围则是用来控制依赖与不同 classpath 关系的。
Maven 的依赖范围分为以下几种:
- compile: 编译依赖范围。Maven 默认的依赖范围,该范围的依赖对编译,运行,测试不同的classpath 都有效。例如我们项目中的 spring-boot-starter;
- test: 测试依赖范围。该依赖范围只对测试 classpath 有效,在编译项目或者运行项目的时候,是无法使用此类依赖的。例如我们项目中的 spring-boot-starter-test;
- provided: 已提供依赖范围。该 Maven 依赖对于编译和测试的 classpath 有效,但是在运行时无效;
- runtime: 运行时依赖范围。顾名思义,该依赖范围对测试和运行的 classpath 有效,但是在编译时无效;
- system: 系统依赖范围。该依赖范围与 classpath 的关系与 provided 依赖范围是相同的。但是,在使用时需要谨慎注意,因为此类依赖大多数是与本机绑定的,而不是通过Maven仓库解析出来的,切换环境后,可能会导致依赖失效或者依赖错误。
目前我们的项目只引用了两个依赖,spring-boot-starter 和 spring-boot-starter-test,但是是这样子的吗?
为了能够更清晰的看到我们项目依赖的结构,我们可以在 IDEA 里面安装 Maven Helper 插件。
从这里我们就可以看到,其实我们不只是引入了两个包,而是引入了很多个包,这是为什么呢?
答案是因为 Maven 的传递性依赖机制。
在我们这个项目中,我们引入了 spring-boot-starter 依赖,并且该依赖的范围是 compile,但是 spring-boot-starter 作为一个项目也有自己的依赖,在这其中的依赖范围为 compile 的依赖,则会自动转换成我们项目的依赖,例如 spring-boot 依赖,logback-core 依赖。
所以,有了 Maven 的传递性依赖机制之后,我们在使用一个依赖的时候,就不再需要考虑它又依赖了哪些,而是直接使用即可,其他的事情 Maven 会自动帮我们做完。
有了传递性依赖能够大大节省我们在管理依赖时候所耗费的精力。但是,如果传递性依赖出了问题我们应该如何解决呢?首先,我们应该知道的是传递性依赖是从哪条依赖路径引用进来的。
在我们的项目中就存在这样的例子。我们可以看到如下两条不同的引用路径:
1.
2.
这个时候,我们可以看到,两条路径最终引用的 spring-core 版本都是 5.2.5-RELEASE。但是如果引用的 spring-core 版本不同,Maven 会怎么做呢?
使用最短路径原则,路径2中的 spring-core 版本会本引用,这样就不会造成重复依赖的问题产生。
传递性依赖可以帮助我们简化项目依赖的管理,但是同时也会带来其他的不必要的风险,例如:会隐式地引入一些依赖,这些依赖可能并不是我们希望引入的,或者这些隐式引入的依赖是 SNAPSHOT 版本的依赖。依赖的不稳定导致了我们项目的不稳定。
在我们的项目中,spring-boot-starter-test 依赖中排除了 junit-vintage-engine 依赖是由于我们使用的 springboot 版本是 2.2.6-RELEASE,对应的 Junit 版本是 5.x,但 junit-vintage-engine 依赖中包含了 4.x 版本的 Junit,此时我们就可以将该依赖排除。
在 exclusions 标签中,可以有多个 exclusion 标签,用来排除不需要的依赖。
在我们实际的开发过程中,我们可能会需要整合很多第三方框架,在整合这些框架的时候,往往需要在 pom.xml 里面添加多个依赖来完成整合。而这些依赖往往是需要保持相同版本的,在升级框架的时候,都是要统一升级到一个相同的版本。
如下图,我们可以看到,在引入 dubbo 框架的时候,我们需要引入两个相关的依赖,而且版本号是相同的,这个时候,我们就可以把对应的版本号提取出来,放到 properties 标签里面,作为一个全局参数来使用。类似于 Java 语言中抽象的思想。
这时候,我们可以看到,如果在将来的某一天我们需要升级升级 dubbo 框架对应的版本,只需要修改 properties 中的版本号,就能将所有依赖的版本一起升级。
我们再回过头来看一下 Maven Helper 工具所展示的场景
我们在这个工具中可以看到我们项目现在引入的所有的依赖,可以看到哪些是我们用到的,哪些是没有用来的,依赖与依赖之间是否存在冲突。如果出现了上述情况,我们就可以通过删除或者依赖排除的方式来将我们不需要的依赖删除掉,从而使我们的项目更简洁。
本节中,我们介绍了 Maven 中的一个重要的概念–依赖,介绍了什么是依赖,以及依赖的几个特性,最后我们也总结了在平时的工作中常常会用到的依赖优化的方式,能够帮助我们更好的管理项目的依赖。
在之前的章节中,我们分别介绍了 Maven 中的工程对象模型(POM)以及 Maven 的依赖管理,但是,这个时候,我们势必会有一个疑问,当我找到一个依赖的坐标后,只需要将该坐标放入到我项目的 POM 文件当中,这个依赖就算是被引入了,那这个依赖是从哪里来的呢?
在本节中,我们就带着这个疑问来学习 Maven 的仓库,了解如何使用 Maven 仓库。
我们先想象一下,如果没有 Maven,我们在开发不同项目的时候,如果需要依赖同一个 jar 包,那么就需要分别在两个不同项目中将这个 jar 包引入进去,对于一个程序员来说,这样的做法显然是不合理的,不仅需要我们手动到处复制,而且会多占用我们的磁盘空间。
那这个时候,Maven 仓库就出现了。我们通常把依赖称为构件,每一个构件都有自己唯一的坐标,基于这种模式,我们就可以把这些构件存放在一个指定的位置–Maven仓库当中,然后通过其坐标来寻找该构件。
在我们学习或者实际开发过程中,只需要在我们的项目当中声明依赖的坐标,在项目编译的或者打包的过程中,Maven 会自动从仓库中去寻找该构件,这样就不需要我们在本地存储这个依赖了。
对于 Maven 来说,主要的仓库种类可以分为两种,一种是本地仓库,另一种是远程仓库。而在远程仓库当中呢,又可以分为中央仓库,私服和其他的公共仓库。
在我们声明的 MAVEN_HOME 路径下,找到 ,其中可以看到 Maven 的本地仓库路径配置:
从上图我们可以看到,Maven 的默认本地仓库路径是在 ,我们为了方便将其修改为了 。
Maven 中默认配置了中央仓库,我们可以在超级 POM 里面找到对应的配置。
这个仓库是由 Maven 社区来维护的,里面存放了绝大多数开源软件的包,并且是作为 Maven 的默认配置,不需要开发者额外配置。另外为了方便查询,还提供了一个查询地址,开发者可以通过这个地址更快的搜索需要构件的坐标。
有了中央仓库,我们为什么还需要其他的远程仓库呢?
- 我们要找的构件可能不存在于中央仓库中;
- 由于某些原因,访问中央仓库的速度相对较慢。
这种时候,我们就可以选择一个使用起来相对方便的远程仓库来配置,大大提高了我们的开发效率。
国内常用的 Maven 仓库:
阿里云镜像:
阿里巴巴镜像:
repo2 镜像:
我们可以将对应的仓库的镜像配置到 settings.xml 文件中的 mirrors 节点中即可。如下图所示,我们配置了阿里云的镜像。
私服也是属于远程仓库的一种,相对公共仓库而言属于某个公司或者某个开发团队私有的远程仓库。通常部署在某个局域网内,提供局域网的内部用户使用。
那私服有什么好处呢?
- 更快的下载速度:由于是局域网内部的请求,因此下载构件的速度是可以保证的;
- 更稳定的构建:想象一下,如果我们依赖某个外部的远程仓库,当这个仓库出现不可能用的情况,哪怕是网络的波动,都有可能会造成我们的构建失败;
- 部署第三方构件:如果一个公司使用了微服务架构,那么公共仓库是肯定没办法获取这些私有的构件的。
当我们需要一个构件的时候,Maven 会先去请求私服,如果发现私服中,没有该构件,那么就会去配置了的远程仓库中寻找,并且缓存到我们的私服中,为后续的下载请求提供服务。
我们知道了 Maven 通过坐标去仓库中寻找对应的构件,那么这个机制的原理是怎么样的呢?
Maven 在寻找需要的依赖的时候,会遵照下面的顺序:
- 如果构件的依赖范围是 system,Maven 会直接从本地的文件系统来解析该构件;
- 根据配置的依赖坐标,在本地仓库中寻找该构件,如果能够搜索到,则解析成功;
- 如果本地仓库没有搜索到,那么就会去已经配置了的远程仓库中搜索该构件,搜索到后,下载到本地仓库中,提供项目使用;
- 如果依赖的版本是 RELEASE 或 LATEST,那么就会根据更新策略去读取所有远程仓库中的元数据信息(groupId/artifactId/maven-metadata.xml),并且与本地仓库中对应的元数据合并后,计算出真实值,再将其下载到本地仓库中;
- 如果依赖的版本是 SNAPSHOT,那么就会根据更新策略去读取所有远程仓库中的元数据信息(groupId/artifactId/version/maven-metadata.xml),并且与本地仓库中对应的元数据信息合并后,得到最新的快照版本值,根据这个值去寻找对应的依赖;
- 解析出的快照版本一般是带有时间戳的,下载下来后,会将该时间戳删掉,以无时间戳的形式来使用。
在本节中,我们介绍了什么是 Maven 仓库,主要的仓库分类以及不同仓库的特点。最后我们还介绍了从 Maven 仓库中的依赖解析机制。
我们今天带来的是 Maven 的另一个重要概念–生命周期。在学习了 Maven 的生命周期之后,在使用 Maven 的过程中,就能够够好的理解每一步操作的意义。
其实生命周期这个概念并不是 Maven 首创的,因为即使不用 Maven,这些事情也是需要我们去做的。想象一下在没有 Maven 的时候,我们开发完一个项目之后,一般是直接使用 Java 的相关命令进行编译,打包等等工作。
但是这些工作无聊而且繁琐,基本上充斥在开发者每天日常的工作中,无论是开发新功能,还是修改一个 Bug,都需要重复以上操作。当然有聪明的开发者,也会将这些每天重复的事情做成脚本来执行。
那么问题又来了,不同公司的不同项目之间或多或少会存在些许差异,这种时候,可能就需要开发者针对这些差异来定制一些步骤,或者脚本。也就是说,每当我们开始开发一个新项目的时候,或者换到另一个项目组的时候,我们构建项目的步骤或者方式都可能会发生变化。
Maven 的出现,可以说是很大程度上缓解了这种问题的发生。通过吸取很多项目的经验,Maven 定义了一套完整而且统一的生命周期模型。使用这个模型,我们将构建的细节交给 Maven,只需要理解对应生命周期的含义即可完成构建。就好像,人到了青少年的时候,就要去上学,到了青年的时候,就要出来工作类似,我们不需要知道上学或者工作中具体的事情,只需要知道,到了这个阶段,能够做这个事情就可以了。
Maven 的生命周期并非只有一套,而是有三套,并且这三套生命周期之间是没有关系的。一套生命周期包含很多个不同的阶段,这些不同的阶段是有顺序的,有些阶段必须要在某个阶段完成之后,才能进行。Maven 的三套生命周期分别为:clean(清理),default(默认),site(站点)。接下来我们就一一介绍一下这三个生命周期。
clean 生命周期包括:
- pre-clean:清理前的准备工作;
- clean:清理上一次构建的结果;
- post-clean:清理结束后需要完成的工作。
一般情况下,Maven 的构建结果会生成在 target 目录下,我们执行 mvn clean 命令后,这个目录会被清空。
从上图,我们可以看到,对应的 target 目录被清理干净了。
default 生命周期应该算是大多数开发者最为熟悉的生命周期,也是平时在开发过程中最常用的生命周期。
(clean,site 并不属于 default 生命周期)在 default 生命周期中,最常用的几个阶段包括:
- validate:验证阶段。验证项目构建过程中需要的信息的正确性;
- compil:编译阶段;
- test:测试阶段。使用测试框架对项目进行测试,打包过程中,非必要阶段,可以跳过执行。
- package:打包阶段。将编译好的文件打包成 jar 包,war 包或者 ear 包;
- verify:检查阶段。检查打包结果的有效性;
- install:本地部署阶段。将包部署到本地仓库,可以提供给本地开发过程中其他项目使用;
- deploy:远程仓库部署阶段。将最终的包复制到远程仓库,提供给使用该仓库的其他开发者使用。
这里我们介绍的只是在 default 生命周期中最常用的,其实在这些阶段执行的过程中,还会有其他的阶段需要执行,但是并非很常用。另外,不出意外的情况下,在生命周期中,后执行的阶段要等先执行的阶段执行完再执行。
我们试着执行 Maven 的打包命令:。执行完成之后,可以看到其所经过的生命周期。因此,当我们想要构建项目的时候,并不需要分别执行 package 阶段之前的阶段,而是 Maven 自动为我们执行。突然发现,原来构建项目是如此的简单,方便。
很多时候,我们不仅仅需要构建我们的项目,还需要生成项目文档或者站点。site 生命周期则是来帮助我们做这件事情的,它能够根据我们项目中 pom.xml 的信息,来生成一个友好的站点。
跟其他的生命周期一样,site 生命周期也包含不止一个阶段:
- pre-site:准备阶段。在生成站点前所需要做的工作;
- site:生成站点阶段;
- post-site:结束阶段。生成站点结束后所需要做的工作;
- site-deploy:发布阶段。我们可以将上面生成的站点发布到对应服务器中。
其实在 Maven 的世界中,生命周期只是一个抽象的模型,其本身并不会直接去做事情,真正帮我们完成事情的是 Maven 的插件。Maven 的插件也属于构件的一种,也是可以放到 Maven 仓库当中的。
通常情况下,一个插件可以做 A、B、C 等等不止一件事情,但是我们又没有必要为每一个功能都做一个单独的插件。这种时候,我们一般会给这个插件绑定不同的目标,而这些目标则是对应其不同的功能。
当我们使用一个插件的目标的时候,我们可以执行命令:。例如当我们执行插件的 list 目标的时候,我们可以执行命令:。
使用该插件目标,我们可以看到目前我们项目中所有依赖的情况。
我们说 Maven 的生命周期只是抽象的概念,真正帮我们完成事情的是插件,其实更确切的说,应该是生命周期与插件对应的目标绑定,来完成具体的功能。
在本节中,我们详细介绍了 Maven 的生命周期,常用的生命周期,以及其与插件的对应关系,简单的工作原理。学完之后,能够加深 Maven 的理解,减少使用过程中的误解。
本节中,我们来介绍一下 Maven 是如何进行版本管理的。如何在项目的实际开发中,结合 Maven 来推进项目的进行。一个正常的项目的开发周期通常是很长的,这个过程当中,需要发布很多个版本,那这些版本如何表示,而我们又应该如何来管理这些版本呢?
那什么是版本管理呢?首先,版本管理是不同于版本控制的。版本控制通常的概念是在软件开发过程中,管理程序文件,配置文件等文件的变化。更倾向于来追踪一个项目过程中,不同时期项目的变化。但是,版本管理则不同,通常是指一个项目过程中,不同时期版本的演化过程。通俗一点讲,版本管理就像人的成长过程中,从婴儿到少年到青年到中年一直到老年这个演变过程的管理;版本控制则更关注细节,例如这个时期,身高从 160cm 长到了 165cm,或者体重 60kg 变为了 62kg 等等。
我们理解了什么是版本管理,那 Maven 是如何做的呢?
通常情况下,Maven 的版本号约定中包括如下几个部分:
<主版本号>.<次版本号>.<增量版本号>.<里程碑版本号>
- 主版本号:主版本号表示该项目的重大升级。例如:Maven1 到 Maven2;
- 次版本号:表示在该主版本下,较大范围的升级或变化。例如:Maven-3.0 到 Maven-3.1;
- 增量版本号:增量版本通常是用来修复bug的版本。例如:Maven-3.1.1;
- 里程碑版本号:用来标记里程碑版本。例如:Maven-3.0-alpha-3。
由于 Maven 已经维护了将近 20 年,所以,使用 Maven 这个项目的版本演变过程来举例是再合适不过了。我们打开 Maven 的官网,找到 Release Notes,打开便可以看到 Maven 从最开始的版本是如何演变成现在的模样的。(这里由于存在太多版本,所以,我们只截取了其中一部分)
(Maven 版本演变历史列表)
注意: 有的同学可能会问,里程碑版本里面的 alpha,beat 是什么意思?
- alpha 版本: alpha 版本被称为是内测版本。通常会存在比较多 bug,主要是面向测试人员使用;
- beat 版本: 这个版本也是测试版本。会比 alpha 版本新增加一些功能;
- RC 版本: 即将发布的候选版本。这个阶段不会再新增功能,主要用于修复 Bug;
- GA 版本: 正式发布版本,也可以对应于 release 版本。
这些版本号在一些流行的框架的演变过程中非常常见。
通常情况下,我们在进行项目开发的过程中,会使用到版本控制工具,例如 svn 或者 git,这时候就会涉及到主干,分支以及标签的概念,那么这里我们简单介绍一下这三个概念。
- 主干: 通常是项目代码的主体。会存在于整个项目周期中,其他的所有分支都是从这里开始的,一般情况下,项目最新的源代码或者所有的变更记录都可以在这里找到;
- 分支: 从主干中某个节点分离出来的代码。在分支刚刚创建的时候,具有当时主干中所有的源代码。通常分支是为了修改某些 Bug 或者进行一些其他的开发,这些源代码的修改并不会影响主干。一旦这个分支中的代码验证通过后,可以将代码归并到主干中去;
- 标签: 通常用来标记主干或者分支中某个时间节点的状态,
从下面的图中,我们可以比较清晰地看出,主干,分支与标签三者之间的关系:
主干,分支与标签三者关系图
我们在了解了主干以及分支的概念之后,那么我们如何去创建分支呢?通常情况下我们可以使用 Svn 或者 Git 自带的创建分支的方式来创建需要的分支,但是,这个时候会存在一个问题:我们需要手动去修改新创建出的分支的 pom.xml 文件中的内容。既然说到版本管理,那想必 Maven 肯定是可以帮助我们做这件事情的。
那么接下来我们来看一下如何使用 Maven 来创建分支,这里我们使用 Git 配合 Maven 来演示如何创建分支。
我们想要使用 Maven 来帮助我们创建分支,首先我们需要配置 scm ,这样 Maven 就可以来代替 Git 来进行操作。
这里我们在 gitee 上创建一个仓库来放置我们的项目。
1. 将 scm 配置到 pom.xml 文件中:
2. 将 maven-release-plugin 插件配置到 pom.xml 文件中:
3. 执行 命令:
- -DbranchName: 目标分支。这里我们可以根据需要来自定义新分支的命名结构;
- -DupdateBranchVersions: 在分支中更新版本;
- -DupdateWorkingCopyVersions: 在当前分支更新版本。
在执行的时候, Maven 会问 branch version 是否为 1.0.1-SNAPSHOT?这个是我们想要的,直接 enter 即可。
执行完成之后,我们查看 Git 的远程仓库中,可以看到新生成的分支。
4. 执行 命令:
在执行的时候,Maven 会问 release version 是否是 1.0.0?这个是否是我们想要的,直接选择 enter 即可。
紧接着,Maven 会问我们 release tag 是否是1.0.0-SNAPSHOT?这个也是我们想要的,直接 ente r即可。
紧接着,Maven 会问我们新的版本是否是1.0.1-SNAPSHOT?这里输入新版本为1.1.0-SNAPSHOT,然后 enter。
执行成功之后,我们更新一下代码,会发现,主干上的 pom.xml 文件的版本已经升级为1.1.0-SNAPSHOT了。
本节当中,我们着重介绍了在 Maven 的世界中,我们一般是如何来约束版本的,以及这些约束所代表的含义,最后,我们还介绍了如何使用 Maven 来管理这些版本。
通常情况下,我们在实际开发过程中,会对项目进行模块(module)划分,来提供项目的清晰度并且能够更加方便的重用代码。但是,在这种时候,我们在构建项目的时候就需要分别构建不同的模块,Maven 的聚合特性能够将各个不同的模块聚合到一起来进行构建。而继承的特性,则能够帮助我们抽取各个模块公用的依赖、插件等,实现配置统一。
这里我们以一个简单的 mall 项目作为例子。先来看一下这个项目的结构,整个项目包括 mall-core 和 mall-account 两个功能模块和 mall-aggregator 一个聚合模块。其中, mall-core 处理商城项目的核心业务逻辑, mall-account 用于管理商城的账户信息。
项目文件图示
一般来说,对于只有一个模块的项目,我们可以在该模块下直接执行 命令来进行项目构建,但是,对于这样的多模块项目,我们如果要构建不同模块的话,需要分别在对应模块下执行 Maven 的相关命令,这样看起来是非常繁琐的。这个时候,Maven 的聚合特性就能够起到作用。
我们来分析一下这个项目整体的结构,首先,我们看一下 mall-aggregator 模块。这个模块作为整个工程的聚合模块,并没有实际的代码,但是其本身也是一个 Maven 项目,所以,也会存在 pom.xml 文件。那我们首先来看一下这个 pom.xml 文件有什么特点。
mall-aggregator 模块的 pom.xml 文件
我们可以看到这里面也会有相对应的 groupId , artifactId , version ,packaging 信息,其中 packaging 的值必须是 pom,否则聚合项目无法构建。我们从 modules 中可以看到整个项目包含两个模块,分别是 mall-core 和 mall-account 。通常情况下,我们将不同的模块放到聚合模块下,其中 module 的值分别对应不同模块的 artifactId 值。
在这个时候,我们 mall-aggregator 模块下,使用 来进行构建,可以将两个模块同时打包完成。
从这次构建的过程来看,我们可以看出,Maven 会首先解析聚合模块的 pom.xml 文件,分析出有哪些模块需要构建,进而计算出一个反应堆构建顺序(Reactor Build Order),并且根据这个顺序来依次进行模块的构建。
现在我们解决了同时构建不同模块同时构建的问题,但是,对于多模块项目来说,还是会有些其他的问题存在,例如,不同模块间有相同的 groupId,version ;有时候,也会需要引入相同的依赖。这个时候,如果每个模块都重复引入的话,结果就会造成冗余。作为一个遵循面向对象的程序员来讲,这样的做法显然是不合理的。
因此,Maven 也引入了类似的机制来解决这个问题,就是继承的特性。
类似于 Java 中的父类与子类,我们也可以创建一个父模块,让其他的模块作为子模块来继承该模块,从而继承父模块中声明的依赖以及配置。
对于父模块来说,只是作为配置的公共模块,是不需要代码的,而且 pom.xml 文件中的 packaging 方式也是 pom,因此,我们可以将聚合模块同时作为父模块来使用,没有必要再创建一个父模块。(当然,这里也是可以单独创建父模块的)
此时,我们查看 mall-core 或者 mall-account 的 pom.xml 文件。
mall-core 模块的 pom.xml 文件
我们可以看到 mall-core 模块继承了父模块的坐标信息,并重新定义了 artifactId 。这时候,我们在父模块引入一个依赖,然后查看 mall-core 模块的 pom.xml 文件,会发现,在 mall-core 模块中也会引入这个依赖。但是,实际上,我们并没有在 mall-core 模块中显式的声明这个依赖。
其实问题并没有完全解决,并不是所有的子模块都需要引入 fastjson-1.2.49.jar 这个依赖,那要怎么办呢?
在 POM 中,我们可以在父模块中声明 dependencyManagement 元素,让子模块来继承。dependencyManagement 元素并不会实际的引入依赖,但是可以起到很好的约束依赖的作用。
首先,我们在父模块的 pom.xml 文件中声明这个元素,并加入 fastjson-1.2.49.jar 这个依赖。
然后,我们在 mall-core 模块中添加这个依赖,但是我们并不需要再声明version。
这时候,我们分别查看父模块与子模块所引入的依赖,会发现,只有子模块中有引入这个依赖,而父模块中,并没有。
父模块依赖引入情况而子模块中已经引入了这个依赖。
子模块依赖引入情况
我们通过 Maven 继承的特性,来进行依赖管理,可以更好的控制依赖的引入。而 Maven 对于插件的管理,也存在类似的元素可以使用(pluginmanagement 元素),可以做到相同的效果。
反应堆指的是整个项目中所有模块的构建结构。在本节的例子中,整个构建结构包括三个模块。反应堆不仅仅包括模块本身,还包括了这三个模块直接的相互依赖关系。
现在,我们的示例项目中,mall-core 和 mall-account 是不存在依赖关系的。父模块中模块的配置顺序如下:
这里我们稍微做一下调整,用户管理模块可以提供接口给核心业务模块来调用,因此,在 mall-core 模块中引入 mall-account 依赖。重新进行项目构建。
从构建的结果来看,模块的构建顺序并不是按照我们在父模块中配置的顺序进行的,而是 Maven 在经过分析之后,生成反应堆,根据反应堆的构建顺序来进行构建的。
实际上,Maven 会根据模块间继承与依赖的关系来形成一个有向非循环图,并根据图中标记的顺序,来生成反应堆构建顺序,在构建的时候,根据这个顺序来进行构建。本节中的实例项目的有向非循环图如下:
继承与依赖关系的有向非循环图
在这个图中,是不能出现循环的,假如我们在 mall-account 模块中也添加入 mall-core 的依赖,再进行项目构建的时候,Maven 则会报错出来,提示我们这个反应堆中存在循环引用。
在本节的学习中,我们使用一个示例项目演示了 Maven 聚合与继承两个特性,以及两者之间的关系,最后介绍了 Maven 构建项目时候,反应堆构建顺序的生成,以及一些注意事项。
到此这篇swagger2常用注解(swagger2使用教程)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/69624.html