
STATA学习笔记:缺漏值的处理
1. 缺漏值的标记
stata中缺漏值默认标记为"."
".“是数值,且是一个大于任何自然数的数值
【注意】
sum、generate等命令,会自动忽略缺漏值
count、keep等命令,会将缺漏值”."视为无穷大的一个数值
2.将其他缺漏值的标记转化为"."
mvdecode命令
常见缺漏值的标记
N.A.
N/A
-99
-97
-9999
import delimited using "D3_miss01.txt" //使用import delimited命令导入txt格式数据 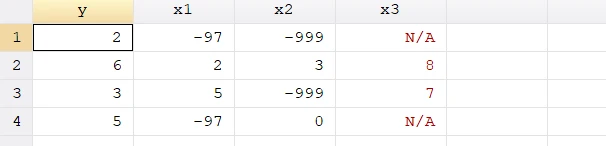
变量x1 x2中含有数值型缺失值
变量x3中含有字符串型缺失值
(1) 数值型数值型缺失值转化为"."
mvdecode x1 x2, mv(-97 -999) (2)字符串型缺失值转化为"."
replace x3 = "." if x3 == "N/A" destring x3, replace 3. 使用不包含缺失值的样本
sysuse nlsw88.dta, clear sum wage industry tenure grade 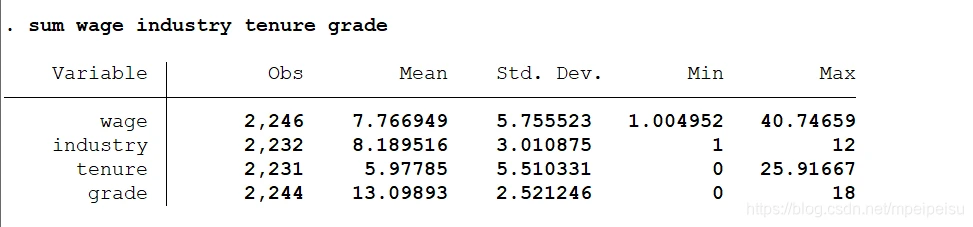
sum 命令的结果显示wage industry tenure grade 变量的观测值个数不同,即每个变量包含了不同个数的缺失值
reg wage industry tenure grade 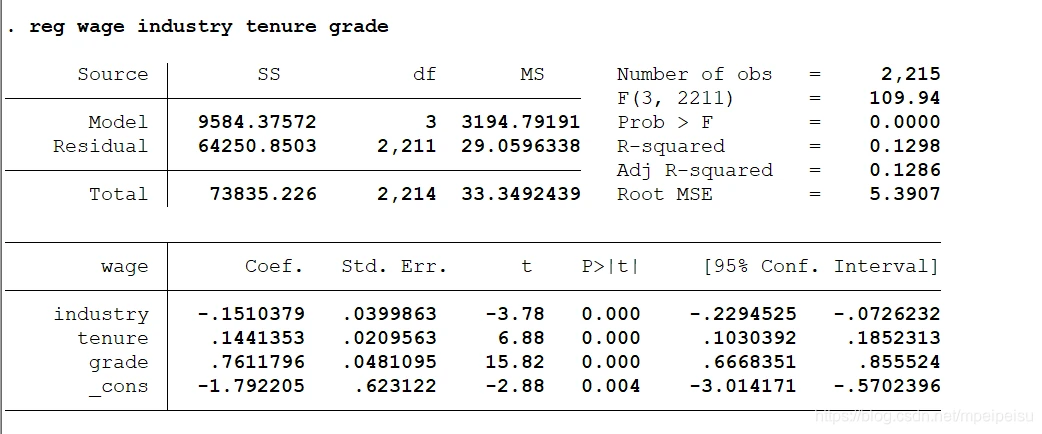
reg 命令结果显示参与回归的观测值只有2215个,回归使用的样本中不包含缺失值
问题是如何筛选出不包含缺失值的样本?
命令 ==ereturn ==
ereturn: Post the estimation results
ereturn list : List e() stored results
ereturn list 函数e(sample)
e(sample)
Description: 1 if the observation is in the estimation subsample and 0 otherwise
sum wage industry tenure grade if e(sample)==1 //e(sample)有两个值:0和1 //1表示对应行观测值参与回归 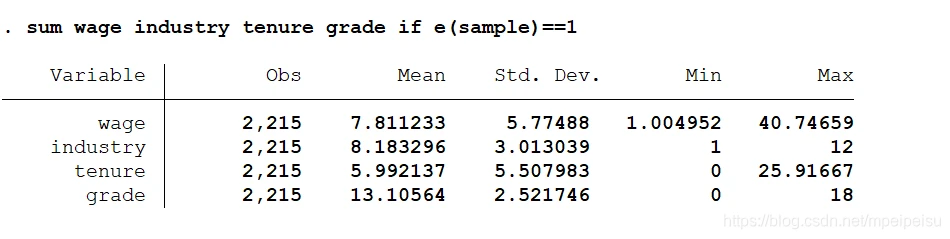
添加if e(sample)==1条件之后,sum命令统计的观测值个数和参与回归的观测值个数一致,即剔除了wage等四个变量中的缺失值
gen yes = e(sample) sort yes browse yes wage industry tenure grade 
4.删除缺失值
keep if yes==1 版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rgzn-sdxx/10325.html