
DM 实例故障,即数据库进程 dmserver 出现异常,表现为异常中止,进程存在但无响应或者无法登录的状态,出现此类问题属于比较严重的故障,本文将从数据库连接异常处理,数据守护故障,DSC 故障,Core 文件分析等方面来介绍出现实例故障后该如何排查与处理。
- 数据库连接异常处理
- 数据守护集群故障处理
- DSC 集群故障处理
- Core 文件分析
- core 文件:程序异常时操作系统保留的完整进程的内存镜像文件。
- gdb:用于调试执行程序或者 core 文件的工具。
- 堆栈:程序执行中的运行情况,详细包含了运行时函数调用数据以及数据相关信息。
- dmrdc:DM 数据库提供的自带对 core 文件进行简单分析的小工具,以 core 文件作为输入参数,dmrdc 可以从 core 文件中读出所有异常时活动会话上的 SQL 语句信息。
本文中所涉及内容适用于 DM7 及 DM8 版本数据库产品。
数据库无法登录原因有很多。当出现该类问题时,重要的是先分析原因,再根据原因进行处理。当数据库出现连接异常时,可通过下图所示思路进行排查:
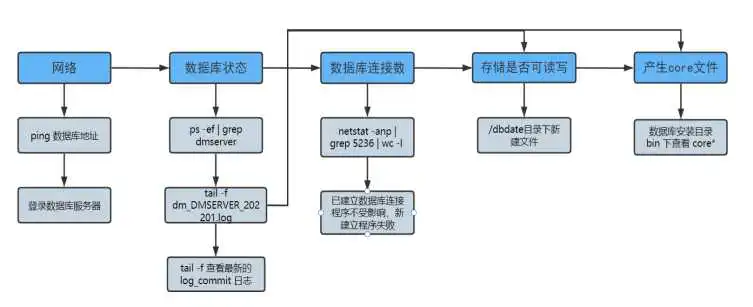
- 检查网络情况。
确定服务器端防火墙关闭的情况下,可以使用 ping 及 telnet 工具测试客户端到数据库服务器的 IP 地址及端口是否能够正常通讯。例如: 或 如果不能正常通信说明网络或端口异常,需要排查网络。如果能够正常通信,需进行下一步排查。
- 检查数据库状态。
如果网络正常,登录数据库服务器检查数据库的状态。执行 命令判断数据库服务进程是否存在。
(1)如果出现下图内容,说明数据库服务进程不在,开始第 3 步。
(2)如果出现下图内容,说明数据库服务进程存在,开始第 4 步。
内容说明:红框表示数据库程序安装目录,绿框表示数据库系统配置文件路径。
- 检查数据库运行日志,例如:dm_DMSERVER_.log
如果发现日志最后为红色框内容,说明数据库被正常停止,其他信息为异常,需要对应处理。
如果发现日志中日志级别为 [ERROR] 或 [FATAL] 标签,则需要具体分析数据库异常停止的原因。
- 登录数据库。进入数据库程序安装路径中执行 数据库用户、密码、IP 和端口号以实际现场为准。如果正常登录说明数据库正常,如果登录失败可以参考步骤 3。
- 查看 core 文件,打印堆栈联系技术人员排查。具体分析方法可查看 core 文件分析章节。
dmserver 进程运行过程中异常中止,进程在进程管理器中无法找到,一般可能由以下几种情况引起。
- 数据库主动停库导致访问异常
- 操作系统将数据库进程终止导致访问异常
数据库实例在运行过程中会实时进行一些检查,比如授权过期信息、文件完整性信息、内存是否污染信息、数据页校验信息等,如果出现一些比较严重的问题被数据库自查到,数据库自身会选择主动停库并给出提示信息,来防止更严重的错误产生。这种情况下导致的进程中止,需要检查数据库运行日志,搜索 Halt 相关的内容,在 Halt 内容附近会记录 Halt 的详细原因,比如授权过期、文件不完整、内存被污染等,根据相关的信息进行对应的处理,一般情况下可以将数据库恢复至正常运行状态,由于 Halt 的内容有非常多种,在此不逐一列举。
虽然有一些 Halt 可以通过简单处理后(比如授权过期),可以立即恢复服务,但有一些特殊情况需要额外留意,例如内存校验失败、数据文件校验失败相关的信息,这种情况一般是数据库在出现内存泄漏或者写溢出等导致,需要结合数据库异常时生成的 core 文件进行分析,才能最终确认问题的症结。
当数据库主动停库导致访问异常时,可以通过以下思路解决:
- 查看数据库的运行日志来确认主动停库的原因。
- 查看 core 文件的堆栈来确认发生异常时相关线程的函数调用顺序。
- 利用 dmrdc 工具分析 core 文件,如果异常发生在 SQL 执行线程上,dmrdc 工具有很大的概率可将导致异常的语句挖掘出来。
一般有以下几种情况可能导致操作系统主动终止数据库进程:
情况一:数据库被 OOM KILL
此为操作系统主动终止数据库进程最常见的情况。数据库的正常运行依赖于能够正常申请操作系统的相关资源,例如当内存不够或内存使用过多时可能发生 OOM 异常,当文件打开数设置的过小可能造成用户无法正常登录数据库,在进行项目实际环境部署时,应该检查这些操作系统资源并进行合理设置。
- data seg size 建议设置为 以上或 unlimited,若此参数过小将导致数据库启动失败。用 vim 打开配置文件 vi /etc/security/limits.conf 在下面加两行。
- file size 建议设置 unlimited (无限制)。若此参数设置过小,则会导致数据库安装或初始化失败,file size 需要在 /etc/security/limits.conf 文件中配置。
- open files 建议设置为 65536 以上或 unlimited。用 vim 打开配置文件 vi /etc/security/limits.conf 在下面加两行。
- virtual memory 建议设置为 以上或 unlimited,此参数过小将导致数据库启动失败。
- max user processes 最大线程数这个参数建议修改为 10240。用 vim 打开配置文件 vi /etc/security/limits.conf 在下面加两行。
或者在 dmserver 的启动脚本中加入 。
- nice 设置优先级,值越小表示进程“优先级”越高。用 vim 打开配置文件 vi /etc/security/limits.conf 在下面加两行。
- 地址空间限制设置为 ulimit 。用 vim 打开配置文件 在下面加两行。
- 内核文件大小建议设置为 ulimit 。 用 vim 打开配置文件 在下面加两行。
注意:通过 systemctl 或者 systemd service 方式设定随机自启动的数据库服务, 其能打开的最大文件描述符、proc 数量等不受 limits.conf 控制,需要修改 /etc/systemd/system.conf 文件,增加类似 DefaultLimitNOFILE=65535 重启服务器生效,如下:
在数据库运行之后,可执行 命令,检查实际资源限制是否生效。
情况二:杀毒软件或者安全软件导致数据库进程异常
系统环境中若存在杀毒软件或者安全软件,可能对数据库的某些线程产生污染,导致线程异常,进而导致数据库进程异常,这种异常在操作系统运行中表现为可以搜索到 DM 相关的信息中包含 Tained 等内容,如果出现这种情况,需要检查环境中是否存在安全软件对 DM 的进程进行监控等动作。
如存在其他异常问题,可通过查询操作系统 /var/log/messages* 等日志搜索 dmserver 进程,查看异常情况。
数据库连接异常问题具体表现:在任务管理器中查看 dmserver 进程能够看到正常的 CPU 活动信息,查看磁盘网络等活动也存在正常的波动,但是新建连接连接数据库会提示网络通讯异常。大多数情况下,连接异常类问题是由于相关配置不正确导致。建议排查连接的 ip 及端口是否正常通信、应用的 url 配置是否正确、应用使用的达梦数据库驱动是否和数据库服务器端的驱动版本一致等。
达梦数据库通过配置系统参数 以及设置单个数据库用户的连接数上限来管控数据库连接数。当客户端向数据库发起连接申请时,首先会占用系统的总会话数,随后再进行用户名密码的验证,并验证是否达到单个用户的连接数上限。一般情况下,当数据库连接数达到 MAX_SESSIONS 后,新建数据库连接会出现【超过最大连接限制】报错。此时仅能再允许一个系统管理员 SYSDBA 用户的登陆,成功建立最后一个 SYSDBA 连接后,数据库连接会达到 MAX_SESSIONS+1。如果此时再新建连接,会返回【网络通信异常】报错。
在遇到数据库连接数达到上限的问题时,为了快速恢复系统,可以参考如下思路进行恢复:
- 从数据库中查找连接数过多的应用,停止应用程序。
- 直接停止不重要程序,快速释放部分连接数,后续可以登录上数据库后,可以通过系统函数踢出数据库空连接或无实际业务操作仅用于探测数据库连接的[例如 select 1]会话或者限制某些 IP 连接数据库。
- 若最终仍无法登录数据库,可选择重启数据库来恢复系统。
- 查看数据库用户资源限制是否设置最大空闲时间。
达梦数据库通过配置系统参数 MAX_SESSION_STATEMENT 来管控数据库单个会话上允许同时打开的语句句柄最大数。一般情况下,当单个会话上句柄数达到 MAX_SESSION_STATEMENT 设置后,会出现【语句句柄个数超上限或系统内存不足】报错。
在遇到该问题时,为了快速恢复系统,可以参考如下思路进行恢复:
- 可以通过调大 dm.ini 文件中的 MAX_SESSION_STATEMENT 参数暂时解决问题。
- 可以通过语句查询各个会话的句柄数量。
该问题一般都是由应用不规范开发导致,若要从根本上解决问题,建议将相关问题反馈给应用开发人员,对代码进行修改、规范,保证会话用完后能够及时关闭。
全局 hash join 满会出现以下报错。
出现该问题一般是由于系统中同一时间有大量工作线程在做 hash join 操作,而全局排序区由参数 HJ_BUF_GLOBAL_SIZE 来控制,所以有以下两种方法进行处理:
方法一:临时处理方法。修改 HJ_BUF_GLOBAL_SIZE 参数,该参数是动态参数,可以通过以下命令修改 ,参数具体设置按照内存大小来确定。
方法二:推荐方法。找到报错的 SQL 语句并进行优化,可将 hash join 优化为 nest loop。
当客户端工具与数据库服务器端版本不匹配时,使用客户端工具连接数据库可能导致如下异常:
- 管理工具连接达梦数据库报错 “argument cannot be null”。
- 管理工具登录后左侧导航栏不显示出来。
- 管理工具登录后报系统错误。
当出现上述情况时,更换使用与服务端版本相同的客户端版本即可正常进行相关操作。
当启动应用并运行一段时间,数据库的实际连接数远低于参数允许的最大会话连接数,但应用却报“网络通信异常”或者“数据库连接关闭”。如下图:
建议从以下方面排查:
- 排查中间件的连接池配置信息。
- 排查中间件的连接池中的泄漏超时时间。
应用抛出“连接已重置”的异常。
建议从以下几个方面尝试排查解决:
- 使用数据库服务器上 $DM_HOME/drivers 目录下的驱动包。
- 查看会话数是否不够。
- 检查是否用户设置了最大空闲时间参数,导致超时断开。
- 长时间执行 ping 命令(从应用服务器到数据库服务器),查看是否为网络波动导致此报错。
- 检查应用的连接池设置,是否设置了断开后自动连接。
- 以上都检查后,可以开启驱动日志进一步分析。
对于主备数据不同步的问题,需要排查以下问题:
- 查看数据库状态是否存在多个主库,是否出现脑裂;
- 通过 dmmonitor 监视器和 dmwatcher 日志,查看主备集群状态,是否分裂;
- 查看 dmwatcher 进程是否正常启动;
- 查看备机 dmserver 实例是否正常进入 open 状态;
- 通过 、 操作系统命令来查看 MAL 系统的网络端口是否通畅;
- 通过 dmrachk 工具查看主库归档是否连续;
- 借助监视器的 命令查看备库不满足 recovery 的原因;
- 查看数据库授权是否支持集群部署选项;
- 查看归档保存路径是否有权限写入归档文件,查看磁盘空间是否充足。
故障自动切换模式下,确认监视器检测到主库故障后,根据收到的主备库 LSN、归档状态、MAL 链路状态等信息,确定一个接管备库,并将其切换为主库。
手动切换模式下,可以通过监视器的 takeover 命令,将备库切换为主库,继续对外提供服务。具体操作如下:
- 使用 SYSDBA 用户登录监视器。
- 使用 命令接管故障主库。
- 执行 命令查看确认。
- 如果执行 命令不成功,主库也无法马上恢复,为了及时恢复数据库服务,DM 提供了 命令,强制将备库切换为主库。但需要由用户确认主库故障前,主库与接管备库的数据是一致的(主库到备库的归档是 Valid 状态),避免引发守护进程组分裂。
同一守护进程组中,不同数据库实例的数据出现不一致,并且无法通过重演 Redo 日志重新同步数据的情况称为组分裂。引发组分裂的原因主要有以下两种:
- 即时归档中,主库在将 Redo 日志写入本地联机 Redo 日志文件之后,发送 Redo 日志到备库之前出现故障,导致主备库数据不一致,为了继续提供服务,执行备库强制接管。此时,当故障主库重启后,就会引发组分裂。
- 故障备库重新完成数据同步之前,主库硬件故障,并且长时间无法恢复,在用户接受丢失部分数据情况下,为了尽快恢复数据库服务,执行备库强制接管,将备库切换为主库。此时,如果故障主库重启,也会造成组分裂。
借助监视器的 命令或者 命令可以查看守护系统中是否发生实例的分裂,对于已发生的分裂,可以借助以下方法找出分裂产生的原因:
(1)查看分裂实例的服务器的 log 日志,查找带有 [!!!] 和 [!!!] 标签的 log 信息,log 信息格式形如 [!!! LOG_INFO !!!]。该 log 信息中记录有实例分裂的详细原因。
(2)根据服务器和监视器的 log 日志,找出历史操作信息,分析产生分裂的原因。
发生分裂后,用户需要选择适当的主库作为最新主库,并重建备库后重新加入集群。
具体重建数据守护步骤如下:(以一个库的数据为准,进行数据库备份)
- 备库重新初始化数据库实例(原数据文件存放目录,在阵列磁盘空间足够的情况下,进行重命名处理)。
- 使用物理备份进行数据库还原。
- 登录备库,修改备库状态。
- 重新配置备库的 dm.ini、dmwatcher.ini 和 dmwatcher.ini 文件,启动 dmwatcher 和 dmmonitor 观察数据同步是否正常。
脑裂指同一个守护进程组中,同时出现两个或者多个活动主库,并且这些主库都接收用户请求,提供完整数据库服务。一旦发生脑裂, 将无法保证数据一致性, 对数据安全造成严重后果。发生脑裂主要有两个原因:网络不稳定或错误的人工干预。
DSC 集群问题排查步骤:
第一步:缩小排查范围,通过监视器看具体故障组件是什么。查看当前 DMCSSMDSC 集群监视器(CSSM)信息,排查各节点状态快速定位异常组件。CSSM 与数据守护监视器(DmMonitor)不同, 不具备节点切换功能。不启动也不影响故障处理。CSSM 与 CSS 相互通信,获取并监控整个集群系统的状态信息。CSSM 提供可手动执行命令来管理、维护集群。
第二步:根据故障组件后台日志进行问题精确定位。在此期间需高度注意 ERROR、FATAL、WARNING 信息,并进行解读。
DMDSC 集群出现数据库实例、或者节点硬件故障时,dmserver 的 Voting disk 心跳信息不再更新,DMCSS 一旦监控到 dmserver 发生故障,会马上启动故障处理,各节点 dmserver 收到故障处理命令后,启动故障处理流程。在 DMDSC 故障处理机制下,一旦产生节点故障,登录到故障节点的所有连接将会断开,所有未提交事务将被强制回滚;活动节点上的用户请求可以继续执行,但是一旦产生节点间信息传递(例如:向故障节点发起 GBS/LBS 请求、或者发起 remote read 请求),当前操作就会被挂起;在 DMDSC 故障处理完成后,这些被挂起的操作可以继续执行。也就是说, DMDSC 产生节点故障时,活动节点上的所有连接会保留,正在执行的事务可能被阻塞一段时间,但最终可以正常完成,不会被强制回滚,也不会影响结果的正确性。
故障问题分析思路:
- 依次查看 dmserver、dmasmsvr、dmcss 的日志,确认故障点发生在哪里,当 css 实例正常时 asmsvr 实例才会正常,当 asmsvr 实例正常时, dmserver 实例才能启动。
- 双节点故障时,可以先搁置一个节点,优先恢复单节点运行,这样也更利于判断故障原因。
- 利用 dmcssm 监视器查看集群状态是监控 DSC 集群最直接有效的手段之一。
DMDSC 集群数据守护功能与单节点数据守护功能一致,支持故障自动切换。DSC 集群各个节点需要分别部署守护进程,DMDSC 集群数据库控制节点的守护进程,称为控制守护进程。如果 DSC 集群的控制节点发生变化,则控制守护进程也会相应变化。守护进程会连接 DMDSC 集群所有实例,但只有控制守护进程会发起 OPEN、故障处理、故障恢复等各种命令。普通守护进程不处理用户命令,但接收其他库的控制守护进程消息。为了方便管理整个 DMDSC 集群,守护进程将 DMDSC 集群看作一个库。
1. DSC 主库 control 节点故障
DSC 集群自动进行故障处理,停止发送日志到备库,控制守护进程降级,并按照一定的原则选取新的控制守护进程,DSC 故障处理完成后,恢复归档日志发送;故障节点恢复启动后自动加入 DSC 集群中,DSC_ERR_EP_ADD 期间停止发送日志到备库,故障节点作为 normal 节点重加入完成后恢复归档日志发送。
2. DSC 主库 normal 节点故障
DSC 集群自动进行故障处理,停止发送日志到备库,控制守护进程不进行切换,DSC 故障处理完成后,恢复归档日志发送。故障节点恢复启动后自动加入到 DSC 集群中,DSC_ERR_EP_ADD 期间停止发送日志到备库,故障节点作为 normal 节点重加入完成后恢复归档日志发送。
(4)单机主库故障可使用备库接管功能,先在监视器上执行 Choose Takeover 命令,选出守护进程组中可以接管的备库,选择 DSC 备机的控制节点进行接管。
通过检查数据库日志和操作系统日志,判断守护环境集群服务器、OS、Network 和 Storage 是否故障。如数据库基础环境故障需要联系相关人员恢复,待基础环境恢复后,检查守护是否恢复,可通过 “check recover 实例名称”命令检查备库是否符合自动恢复条件,且 recovery 过程中要保证 DMDSC 集群启动故障处理或者故障重加入中断当前的 recovery 动作。如果未能恢复,可根据以下步骤进行分析:
判断守护组备机是否分裂。首先在监视器控制台执行 show 和 tip 命令查看当前守护系统的运行状态,然后执行以下 SQL 检查 open 记录包含关系。
- 如果控制打印信息显示分裂和 open 记录中备库已经无法判断包含关系则守护分裂,需要按照《DM8 数据守护与读写分离集群》重建备库。
- 如果守护组备机未分裂,备机备库实例 open,则是 OS、Network 和 Storage 性能问题,导致日志发送速度变慢。
排除 RLOG_SEND_THRESHOLD 参数设置导致的 standby check。
将主库守护进程上记录的这些异常备库的最近一次恢复时修改为当前时间。恢复间隔仍然为 dmwatcher.ini 中配置的 INST_RECOVER_TIME 值。
通知主库修改这些异常备库的归档为 Invalid 无效状态。
守护进程切回 Open 状态。
前置条件说明:
数据库作为系统基础软件,在运行过程中有可能会发生 。当数据库异常终止或崩溃时,将数据库进程此时使用的内存内容拷贝到磁盘文件中进行存储,以方便编程人员调试。注意,上述所说的“异常终止或崩溃”表示数据库可能遇到致命错误,无法按照预定程序逻辑继续执行下去,所以在进程彻底终止之前将其使用的内存区域转存到文件中,有时候可能需要手动生成 core 文件,记录下进程当前的内存信息,以便后续进行问题排查,此时可以通过 或者 手动生成 core 文件。如果要达到上述目的,需要在数据库运行的服务器系统进行一些设置,具体配置方法如下:
关于 core 文件生成路径的说明:
core 文件默认的存储位置与对应的可执行程序在同一目录下,文件名是 core,达梦数据库相同。例如,达梦数据库程序目录为 ,则 core 文件生成的路径在 下,core 文件名生成规则为 core.pid,其中 pid 表示数据库进程 id。也可以手动配置 core 文件的生成路径,需要修改配置文件 ,例如修改生成 core 文件到 /tmp 目录,文件名为 core_pid:
其中 core 文件存储的磁盘空间需要规划好,防止由于磁盘空间不足导致 core 文件被截断。
单个 core 文件的大小上限一般为数据库进程所占用内存。(一般可以参考 top 命令中的 dmserver 进程对应的 virt 列内存)
查看 core 文件的前置条件:
(1)数据库所在操作系统能够正常运行 gdb 工具。
gdb 主要在 linux 系统下进行程序调试使用的。为了确保数据库发生 core dump 时能够正常进行分析和调试,应该确保数据库所在系统能够正常运行 gdb 工具,可以使用 进行验证,当出现 gdb 版本信息时表示当前系统能够正常使用 gdb 工具。
(2)操作系统已打开生成 core 文件的开关。
通过 命令可以查看是否打开生成 core 文件的开关,但返回 0 时表示关闭,当返回数值或 unlimited 时表示已打开。需要注意的是,虽然 ulimit -c 设置具体的数值表示已打开生成 core 文件开关,但是强烈建议达梦数据库服务端设置 core size 设置为 unlimited。
打开生成 core 文件开关:在 /etc/security/limits.conf 应该配置如下内容:
生成 core 文件的文件大小应该根据磁盘空间进行设定。因为数据库是属于相当吃内存的基础软件,如果设置的 ulimit -c 数值过小,例如设置值小于数据库进程发生 core dump 前一刻使用的虚拟内存总量时,则可能仍然不会正常生成 core 文件,所以当磁盘空间十分充裕的情况下,数据库服务器上的 core size 可以设置为 unlimited,如果本地磁盘空间不够,可以选择存储在阵列上。如果数据库进程内存使用过大,而磁盘写入速度性能较差时,会导致生成 core 文件时间非常漫长。考虑到上述因素,core size 应该根据实际情况进行合理设置。
验证生成 core 是否设置成功:
方法一:在上述操作完成后,编写如下 c 代码:
尝试编译运行该测试程序确认能否正常生成 core 文件。
方法二:没有 gcc 编译环境情况下,可以切换到数据库运行用户(dmdba)执行以下操作,建议使用 su – dmdba 方式进行切换,否则 ulimit 配置为当前 shell 配置。
(1)编写 shell 脚本。
(2)运行 shell 脚本。
(3)在其它 shell 窗口将该进程 kill -11。
查看是否能够正常生成 core 文件。
达梦数据库管理系统在运行过程中,会按照预设的程序逻辑正常运行并对外提供服务,可能因某些异常原因导致数据库发生致命问题,从而不得不终止进程。这些异常原因包括但不限于异常 sql、必要的文件丢失或损毁等。当数据库进程发生 core dump 后,自动生成的 core 文件应该在达梦程序目录 bin 下,core 文件名生成规则为 core.pid,其中 pid 表示数据库进程 id。大多数情况下数据库发生 core dump 是因为异常 sql 执行导致,应该使用发生 core dump 对应的 dmserver 版本进行 core 文件信息查看和分析,步骤如下:
- 使用 GDB 命令解析 core 文件。
- 执行 bt 或 where 会显示对应的线程堆栈信息。
- 执行 thread apply all bt 可以显示所有线程的堆栈信息,获得 Thread 1 对应的线程号,即 LWP (light weight process,轻量级进程,可简单理解为子进程)号,具体方法如下:
使用达梦自带的 dmrdc 工具进行 core 文件分析,能够将数据库进程发生 core dump 时刻所有线程正在执行的 sql 语句分析出来。。
在 core_31820.txt 中搜索记录的
补充:当由于配置不当未生成 core 文件时,或没有 gdb 无法分析 core 文件时,可以通过操作系统层日志去定位具体导致程序崩溃的相应进程号即
从上图中可看出 kern 内核日志当中记录了 dmserver 的 dm_sql_thd 线程崩溃,线程号为 9190,在 dmsql 日志中搜索 thrd:9190 即可定位相应 sql 语句。
找到具体的 sql 语句后,如果条件允许,应该搭建一个与生产环境相同(即确保版本相同,参数相同,sql 执行计划相同)的测试环境进行验证(物理备份还原的方式),在测试环境重新执行此 sql 确认是否会导致发生 core dump。
对于达梦数据库服务端进程 core dump 来说,分以下两种情况:
(1)服务端主动 core
这一类 core dump 问题相对来说比较好定位问题,因为服务端主动 core 表示程序因某种资源不够或已知原因而发生的“自杀”行为,一般在达梦数据库运行日志或 core 堆栈中会出现 dm_sys_halt 的信息,这种情况下通过堆栈和日志信息便可以确定发生问题的原因。
(2)因未知异常原因导致的 core
这一类 core dump 相对来说更加隐晦一些,因为这一类是服务端程序被迫发生的,例如内存访问越界、非法指针、堆栈溢出等问题,主要表现为达梦数据库运行日志检查点突然中断,没有任何信息,但这一类问题的原因往往是由某个 sql 语句引发的,只需要找到对应的 sql 语句即可。
例如,对于如下 core 堆栈来说,可以看出,堆栈的当前帧为 dm_sys_halt_low() 表示是数据库服务端主动 core 的,一般对于主动 core 的问题在达梦运行日志中可以找到更为详细的提示信息,可以看到日志中打印的信息为“Redo log try flush over space”表示冲破日志环了。发生这样的情况,一般是数据库在执行一个大事务,而当前可用的 redo log 装不下这个事务的数据变化导致的,我们需要优先考虑减少 BDTA_SIZE 以及增大 RLOG_RESERVE_SIZE,之后才是增加 redo 日志或扩大 redo 日志来解决。
除了可以查看 core 文件的堆栈信息外,也可以获取到数据库在运行过程中的堆栈信息,这里主要有两种方法,一种是使用 pstack 命令(优先推荐使用),另一种是使用 gdb attach 命令。需要注意的是 pstack 属于 gdb 的一部分,如果无法使用 pstack 需要确认系统当前是否支持 gdb。而 gdb 也可以在数据库进程运行时对其进行调试,但是 gdb 工具 attach 进程后会使此子进程(线程)阻塞到当前状态。
方法一:使用 pstack 命令(推荐)。
在数据库进程处于运行状态下,可以使用 dmserver 的属主用户或 root 用户来进行操作,使用方法为 pstack
同样的 pstack 也支持打印某各个线程的堆栈信息,方法为 pstack <thd_id>,例如:
方法二:使用 gdb attach 命令。
下面举例打印一个正在执行 SQL 的线程堆栈:
通过 V$SESSIONS 视图的 THRD_ID 列找出当前会话对应的线程号:
使用 pstack 工具打印其堆栈信息:
使用 gdb 进行打印线程堆栈信息:
使用 gdb 打印正在运行的 dmserver 进程的所有线程信息:
函数调用栈由连续的栈帧组成。每个栈帧记录一个函数调用的信息,这些信息包括函数参数、函数变量和函数运行地址。当程序启动后,栈中只有一个帧,这个帧就是主函数的帧。我们把这个帧叫做初始化帧或者叫做最外层帧,在达梦的堆栈信息中最外层帧为 clone()。每当一个函数被调用,一个新帧将被建立,每当一个函数返回时,函数帧将被剔除。当前执行的函数的帧被称作最深帧,这个帧是现存栈中最近被创建的帧。
由于达梦数据库进程为单进程多线程模式,从运行时堆栈可以看出,对于每一个线程都有对应的堆栈信息,表明当前线程运行到程序代码的什么函数位置。堆栈自底而上的每一行信息表示程序中函数的调用关系,调用方向为自底向上,由下一层调用上一层函数,例如某线程运行堆栈如下图所示,# 0 为栈顶,# 11 为栈底,从函数调用关系来看,最外层函数为 clone(),最内层函数为 aagr2_exec_after_fetch(),各层函数逐级调用。
若以上内容无法解决您的问题,可以在达梦技术社区提问交流。
到此这篇达梦数据库端口(达梦数据库端口5236被占用)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/sjkxydsj/22578.html