
OpenPose首先将数据送入到 VGG-19 的前 10 层卷积中去提取特征,然后,通 过这些特征去找每个位置的置信图(Confidence Map)以及其新定义出来的 Part Affinity Fields(PAFs部分亲和域),然后去通过这两个特征最终得到骨架信息,其流程如图 2.5 所 示。

OpenPose 的网络结构如图 2.6 所示,
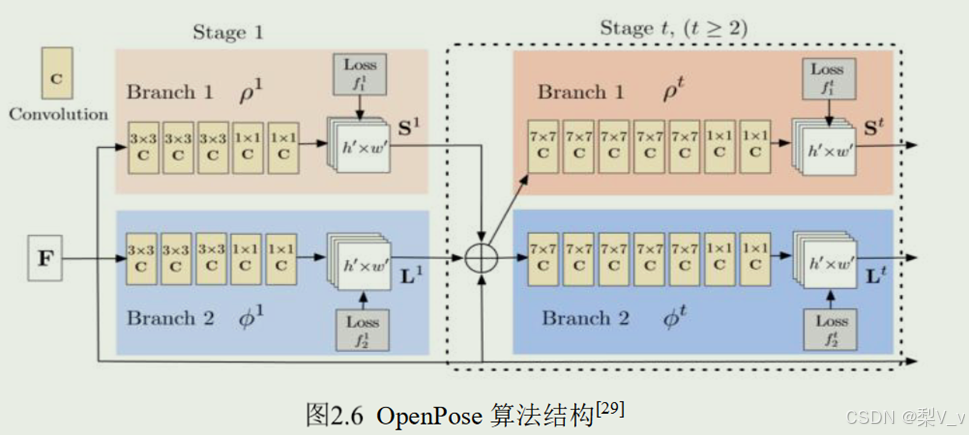
从图中看出,通过多步的迭代,不断提升每步的所预测出关键点与躯干的精度,F 是第一阶段 VGG-19 卷积神经网络的输出, OpenPose 将该特征输出分别送入到两组卷积神经网络中,即图 2.6 中的 Branch1 和 Branch2,
Branch1 用来预测关节点的置信图S = (𝑆1, 𝑆2, ... , 𝑆𝑗),j 代表检测的关节数, 𝑆𝑖代表一个节点的特征图。
而对于 Branch2,就是用来预测 PAFs,即每个支段或关节对的亲和场(PAF), 用L = (𝐿1, 𝐿2, ... , 𝐿𝑐)表示,每个支段用一个二维向量表示, 而𝐿𝑖表示其中一个支段的二维向量
我们用𝐿𝑡表示第 t 个阶段的所预测出的 PAF,𝑆𝑡 则表示第 t 个阶段所预测的置信图,用𝜌𝑡表示第 t 阶段 Branch1 的卷积架构,∅𝑡表示 第 t 阶段 Branch2 的卷积架构,除了第一阶段只有输入 F 外,其余阶段输入为 F,𝑆𝑡−1和𝐿𝑡−1,可用公式(2-2)、( 2-3)表示。
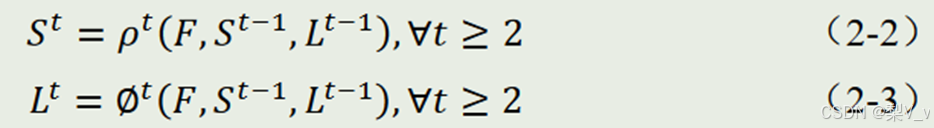
该论文在该网络的每个阶段结束前都会针对每个阶段的 loss 进行计算并反向传播 计算梯度,通过这种方式来防止梯度消失的现象。
个别损失函数 fs 和 fl 如公式(24)、(2-5)所示
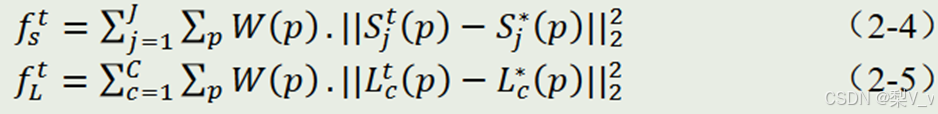
这些参数中,t 代表第 t 个阶段,s 代表是关键点,l 代表 PAF,p 代 表的是在影像上的位置,*代表的是 ground truth,Loss 就是透过卷积架构预测出的结 果与 ground truth 的 L2 正则化,𝑊(𝑝)是一个 0 与 1 之间的数值,用这个参数避免当 ground truth 没有标记,但模型有预测出来时就会使得 Loss 结果很大,使原本参数进 行调整。
关于 ground truth 如何定义,该论文给出了公式(2-6)
S 如前所述关键点的位 置,*代表真值,而 j 与 k 分别代表第 k 个人的第 j 个关键点,p 代表的就是影像上的 每一个像素位置,而𝑥𝑗,𝑘指的就是影像上经过标注的关键点位置,𝜎参数用来定义其他 影像点与关键点在平面上分布的范围,σ越大分布的范围就越窄,最后再取一个赋值代表这个数值最大为 1,也就是说我们预测的与我们的真值距离越近就越靠近 1。
OpenPose 算法提取骨架的效果
到此这篇openpose训练自己的数据集(openpose怎么训练)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/sjkxydsj/60176.html