
所谓“埋点”,是数据采集领域(尤其是用户行为数据采集领域)的术语,指的是针对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程。
埋点的技术实质,是先监听软件应用运行过程中的事件,当需要关注的事件发生时进行判断和捕获,然后获取必要的上下文信息,最后将信息整理后发送至服务器端。所监听的事件,通常由操作系统、浏览器、APP框架等平台提供,也可以在基础事件之上进行触发条件的自定义(如点击某一个特定按钮)。一般情况下,埋点可以通过监测分析工具提供的SDK来进行编程实现。
埋点的业务意义显而易见,即帮助定义和获取分析人员真正需要的业务数据及其附带信息。在不同场景下,业务人员关注的信息和角度可能不同。典型的应用场景有面向数字营销领域的分析,以及面向产品运营领域的分析。前者注重来源渠道和广告效果,后者更在意产品本身流程和体验的优化。两者各有侧重,也可以有一些交叉。所以,对于不同的项目和分析目的,应当设计不同的埋点方案。
近年来,埋点的方法论上也出现了一些业界新趋势,如“无埋点”技术。所谓“无埋点”,是指不再使用笨拙的采集代码编程来定义行为采集的触发条件和后续行为,而是通过后端配置或前端可视化圈选等方式来完成关键事件的定义和捕获,可以大幅提升埋点工作的效率和易用性。在“无埋点”的场景下,数据监测工具一般倾向于在监测时捕获和发送尽可能多的事件和信息,而在数据处理后端进行触发条件匹配和统计计算等工作,以较好地支持关注点变更和历史数据回溯。当然,即便是“无埋点”技术,也仍然需要部署数据采集基础SDK(又称基础代码),这一点需要注意,容易产生误区。
如果需要了解更多关于埋点的详细信息,可以阅读宋星的文章:
http://www.chinawebanalytics.cn/auto-event-tracking-good-bad-ugly/
By 何恺铎
作者:大头鱼
链接:https://zhuanlan.zhihu.com/p/25
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
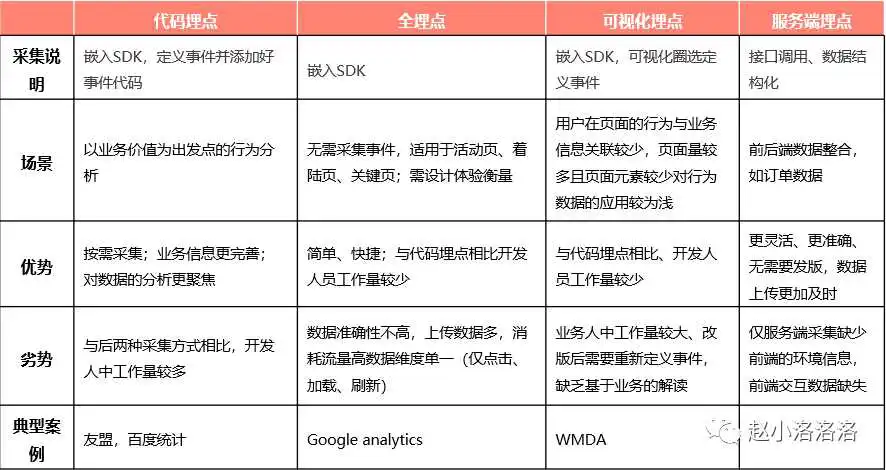
数据埋点的方式
- 第一种:自己公司研发在产品中注入代码统计,并搭建起相应的后台查询。
- 第二种:第三方统计工具,如友盟、神策、Talkingdata、GrowingIO等。
关键指标
- 访问与访客
访问次数(Visits)与访问人数(Vistors)是几乎所有应用都需要统计的指标,这也是最基础的指标。
对于应用的统计来说,经常看到的DAU,MAU,UV等指标都是指统计访客(Vistors)。访问(Visits)是指会话层,用户打开应用花一段时间浏览又离开,从指标定义(访问次数)来说这被称之为统计会话(Session)数。
一次会话(Session 或 Visit)是打开应用的第一个请求(打开应用)和最后一个请求决定的。如果用户打开应用然后放下手机或是离开电脑,并在接下来30分钟内没有任何动作,此次会话自动结束,通常也算作一次访问或会话期(30分钟是早起网页版应用约定俗成的会话数定义,目前用户停留在应用的时长变长,30分钟的限定也可能随之不同,总之是能代表一次用户访问的时长)。
在计算访问人数(Vistors)时,埋点上报的数据是尽可能接近真实访客的人数。对于有需要统计独立访客这个指标的场景,这里还是需要强调一下,访问人数(Vistors)并不是真实独立的人,因此收集数据时必须知道访问人数虽然能够很好的反映使用应用的真实访问者的数量,但不等于使用应用的真实人数。(原因是,重复安装的应用,或是手机参数被修改都会使得独立访客的指标收到影响。计算访问人数的埋点都是依赖Cookie,用户打开应用,应用都会在此人的终端创建一个独立Cookie, Cookie会被保留,但还是难免会被用户手动清理或是Cookie被禁用导致同一用户使用应用Cookie不一致,所以独立访客只能高度接近于使用应用的真实人数。)
- 停留时长
停留时长用来衡量用户在应用的某一个页面或是一次访问(会话)所停留的时间。
页面停留时长,表示在每个页面所花费的时间;例如:首页就是进入首页(10:00)到离开首页进入下一个页面(10:01)的时长,首页停留时长计算为1分钟。页面A是2分钟。停留时长的数据并不都是一定采集得到的,比如页面B进入时间(10:03),离开出现异常或是退出时间没有记录,这时候计算就是0 (所以指标计算时需要了解埋点的状况,剔除这样的无效数据)。
应用的停留时长,表示一次访问(会话)所停留的时间,计算起来就是所有页面的访问时长,同样是上一个流程,应用的停留时长就是4分钟。
- 跳出率
跳出率的计算方法现在在各个公司还是很多种,最经常被使用的是:用户只访问了一个页面所占的会话比例(原因是:假设这种场景,用户来了访问了一个页面就离开了,想想用户使用的心里画面应该是:打开应用,心想什么鬼,然后关闭应用甚至卸载了。这个场景多可怕,这也是为什么跳出率指标被如此关注)
跳出率可以分解到两个层次:一是整个应用的跳出率,二是重点的着陆页的跳出率,甚至是搜索关键词的跳出率。跳出率的指标可操作性非常强,通过统计跳出率可以直接发现页面的问题发现关键词的问题。
- 退出率
退出率是针对页面的,这个指标的目标很简单,就是在针对某个页面有多少用户离开了应用,主要用户反映用户从应用离开的情况。哪些页面需要被改进最快的方式被发掘。(注意:退出率高不一定是坏事。例如:预测流程的最终节点的退出率就应该是高的)
- 转化率
我们在产品上投入这么多,不就是为了衡量产出么?所以对于电商类应用,还有比转化率更值得关注的指标吗?转化率的计算方法是某种产出除以独立访客或是访问量,对于电商产品来说,就是提交订单用户数除以独立访客。
转化率的计算看起来想到那简单,但却是埋点中最贴近业务的数据收集。这也是最体现埋点技巧的指标,需要结合业务特点制定计算方法。提交订单量/访客数是最基本的转化率,转化率还可以分层次,指定用户路径的,如:完成某条路径的提交订单数/访客数。
试着找一条路径,想想转化率的数据怎么得来的吧,埋点都收集了什么样的数据吧?
- 参与度
参与度并不是一个指标,而是一系列的指标的统称,例如访问深度,访问频次,针对电商的下单次数,针对内容服务商的播放次数,及用户行为序列这些都可以是衡量参与度的指标。之所以把参与度列为一个指标,是希望大家明白把指标结合业务,产生化学反应,活学活用去发现事物的本质。
埋点的内容
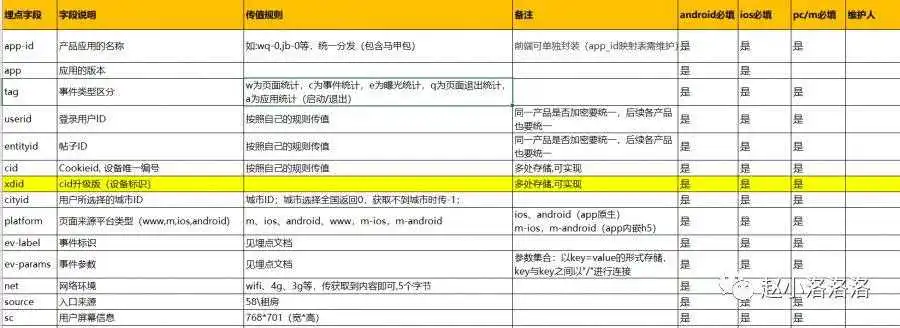
为了统计到所需要的指标,应用中的所有页面,事件都被唯一标记,用户的信息,设备的信息,时间参数以及符合业务需要的参数具体内容被附加上报,就是埋点。
关于埋点的数据的注意事项
关于埋点数据有一点至关重要,埋点是为了更好地使用数据,不要试图得到精准的数据要得到的是高质量的埋点数据,前面讨论跳出率就是这个例子,得到能得到的数据,用不完美的数据来达成下一步的行动,追求的是高质量而不是精确。这是很多数据产品容易入坑的地,要经常提醒自己。
数据埋点是为了采集业务数据(包括用户数据)做的技术层面的工作。
常见的埋点有“全埋点”和“代码埋点”两种,这两种埋点方式相比而言所采集的数据范围和深度是不一样的。“代码埋点”采集数据的准确度和深度优于“全埋点”,像服务器、数据库的数据只有“代码埋点”才能准确采集,而“全埋点”只能采集前端数据。
设置埋点的意义很重要,开始分析数据之前必须要采集到数据,而埋点就是为实现数据采集的技术手段,针对数据采集与埋点的方法和介绍你可以看一下 原文【数据采集与埋点】,里面讲了数据采集的原则、前端埋点技术、后端埋点技术,可以深入了解一下。
数据生产-数据采集-数据处理-数据分析和挖掘-数据驱动/用户反馈-产品优化/迭代。
数据采集,顾名思义采集相应的数据,是整个数据流的起点,采集的全不全、对不对,直接决定数据广度和质量,影响后续所有的环节。
在数据采集失效性、完整性不好的公司,经常会有业务方发现数据发生的大幅度变化,追其所以时发现是数据采集的问。而另一方面,采集什么数据才能有效的得到数据分析结论,才能有效的进行推荐,就需要提前规划埋点。
当前数据采集普遍遇到的几个问题:
- 实时性,对于工具性产品在无网条件下的数据,无法实时上报;
- 完整性,由于用户隐私协议&欧盟通用数据保护条例的,部分数据无法采集;
- 异常,android_id、idfa、idfv 随版本升级变化或无法获取。
接下来用5w2h的思路来看埋点。
所谓“埋点”,是数据采集领域(尤其是用户行为数据采集领域)的术语,指的是针对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程。比如用户某个icon点击次数、观看某个视频的时长等等。
埋点的技术实质,是先监听软件应用运行过程中的事件,当需要关注的事件发生时进行判断和捕获。
特别注意需要明确事件发生时间点、判别条件,这里如果遇到不清楚的,需要和开发沟通清楚,避免采集数据与理想存在差异。例如:期望采集某个app的某个广告的有效曝光数,有效曝光的判别条件是停留时长超过1秒且有效加载出广告内容。
现在公司通常都会有数据产品经理或业务线数据分析师,结合版本迭代过程进行埋点规划。如果是代码埋点,还需要开发完成相应的埋点代码。
埋点是目的导向。
在产品规划时就要思考数据埋点问题,如果在产品外发后再考虑怎么埋点,就会导致前期版本用户的数据无法收集,想要看某个数据时就会非常无奈,只有等到新版本完善来弥补。
思考要埋哪些点、埋点的形式,需要紧密结合产品迭代的方向、运营需求,并和数据开发等进行充分沟通以确认:
- 埋点能够得到想要的数据解决/支持;
- 能够得到当前版本的复盘情况;
- 后续版本的数据支撑。
通常的沟通过程以 埋点文档为载体;数据埋点评审为终结。
当前版本的复盘情况:
- 新版本功能使用情况,是否符合预期;
- 新功能上线后对其他功能点的影响?是否为整体均有积极作用;
- 版本运营活动目标群体的特征获取;
- 新增商业化目标的监测……
后续版本的数据支撑:
- 规划方向的用户行为分析
- 画像特征分析
4.1 埋点技术:代码埋点、可视化埋点、无埋点
接着第一节:埋点是什么?来看下埋点技术层面的区分:代码埋点、可视化埋点和无埋点。
(1)代码埋点
以为需要监测网站上/app上用户的行为,是需要在网页/app中加上一些代码的,当用户触发相应行为时,进行数据上报,也就是代码埋点。这样的代码,在网站上叫监测代码,在app中叫SDK(Software Development Kit)。市场上的第三方数据采集均支持代码埋点,GA, GrowingIO,神策等。
- 优点:可以详细的设置某一个事件自定义属性;
- 缺点:时间、人力成本大,数据传输的时效性。
(2)可视化埋点
利用可视化交互手段,数据产品/数据分析师可以通过可视化界面(管理后台连接设备) 配置事件,如下是腾讯移动分析的可视化埋点界面。可视化埋点仍需要先配置相关事件,再采集。
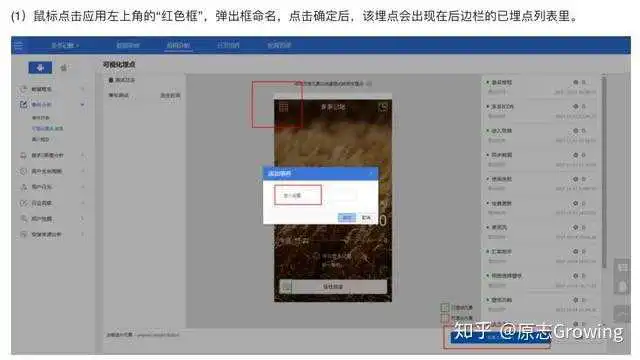
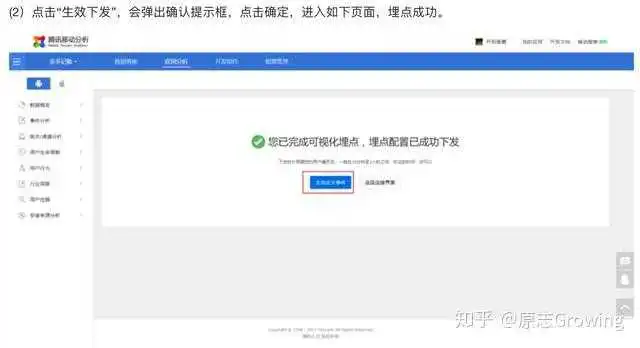
- 优点:埋点只需业务同学接入,无需开发支持;
- 缺点:仅支持客户端行为。
(3)无埋点
无埋点是指开发人员集成采集 SDK 后,SDK 便直接开始捕捉和监测用户在应用里的所有行为,并全部上报,不需要开发人员添加额外代码。
数据分析师/数据产品 通过管理后台的圈选功能来选出自己关注的用户行为,并给出事件命名。之后就可以结合时间属性、用户属性、事件进行分析了。所以无埋点并不是真的不用埋点了。目前市场第三方工具GrowingIO支持无埋点全量行为数据抓取
 https://www.zhihu.com/video/
https://www.zhihu.com/video/
优点:
- 无需开发,业务人员埋点即可;
- 支持先上报数据,后进行埋点。
无埋点和可视化埋点均不需要开发支持,仅数据业务同学进行设置即可。但两者数据上报-埋点设置存在加大的差异:无埋点支持在数据上报之后再进行埋点设置,因而数据采集/上报的量远大于可视化埋点。
4、各种埋点场景&埋点建议
- 客户端数据:页面点击数据,比如:tab栏的点击,某个icon的点击(各入口点击对比使用情况,统计页面点击行为的转化漏斗)。
- 服务端数据:安装数据,下载后安装情况;内容数据,比如某个视频内容 曝光/展示/播放数据;搜索内容。
以视频产品为例的一次埋点过程:
1. 明确产品动态,梳理数据需求;
当前为一个视频社区软件,增加了舞蹈跟拍功能,用户可以根据不用的舞蹈来进行拍摄(运营同学对舞蹈进行了分类,主打几个舞蹈),目的是为了给用户提供低成本创造视频内容的方式。
基于上述的产品目的,期望能了解:
a.该功能的使用情况(uv,pv,使用过程漏斗);
b.生产的视频情况(视频数,视频的互动情况),是否能实现促进内容生产带动社区氛围的目标。
2. 数据需求转化为指标&埋点,并与数据开发进行讨论;
a.功能使用uv、pv;
b.对其他拍摄功能的影响;
a,b:可以服务端打点,也可以客户端打点,但因为视频社区的基于内容的互动行为基本都在服务端,所以建议服务端打点。
c.拍摄流程的转化漏斗;拍摄流程主要是页面的点击过程,故使用客户端埋点,并记录uv,pv。
d.跟拍视频的播放、点赞、评论、分享、关注、二次被跟拍的情况;
f.跟拍舞蹈的类型,明确用户是否偏向于某个类型的舞蹈跟拍;
d,f服务端,基于内容的互动行为基本都在服务端。
3. 版本上线;
4. 按照预期进行数据分析,产品迭代复盘。数据分析过程,注意查看是否与预期相符,是否有优化点。
欢迎加入 GrowingIO 增长社群
2000+ TOP 公司增⻓相关工作者聚集地,全年干货分享,大咖参与话题讨论。欢迎正在研究「增长」的市场、产品和运营朋友一起加入!
加群方式:联系作者微信,备注“社群”,审核通过后即可免费加入增长社群
点击此处立即获取GrowingIO双倍体验时间
数据采集是数据分析的基础,而埋点是最主要的采集方式。那么数据埋点采集到底都是哪些事呢?我们主要从三个方面来看:什么是埋点,埋点怎么设计,以及埋点的应用。
一、数据采集以及常见数据问题
1.数据采集
做任何事都要有个目的与目标,数据分析也不例外。在开展数据分析之前,我们需要思考为什么要开展数据分析?希望通过这次数据分析解决企业什么问题?
数据采集有多种方式,埋点采集是其中非常重要的一部分,不论对c端还是b端产品都是主要的采集方式,数据采集,顾名思义就是采集相应的数据,是整个数据流的起点,采集的全不全,对不对,直接决定数据的广度和质量,影响后续所有的环节。在数据采集有效性,完整性不好的公司,经常会有业务发现数据发生大幅度变化。
数据的处理通常由以下5步构成:

2.常见数据问题
大体知道数据采集及其架构之后,我们看看工作中遇到的问题,有多少是跟数据采集环节有关的:
(1)数据和后台差距很大,数据不准确-统计口径不一样、埋点定义不一样、采集方式带来误差;
(2)想用的时候,没有我想要的数据-没有提数据采集需求、埋点不正确不完整;
(3)事件太多,不清楚含义-埋点设计的方式、埋点更新迭代的规则和维护;
(4)分析数据不知道看哪些数据和指标-数据定义不清楚,缺乏分析思路
我们需要根源性解决问题:把采集当成独立的研发业务来对待,而不是产品研发中的附属品。

二、埋点是什么
1.埋点是什么
所谓埋点,就是数据采集领域的术语。它的学名应该叫做事件追踪,对应的英文是Event Tracking 指的是针对特定用户行为或事件进行捕获,处理和发送的相关技术及其实施过程。
数据埋点是数据分析师,数据产品经理和数据运营,基于业务需求或者产品需求对用户行为的每一个事件对应位置进行开发埋点,并通过SDK上报埋点的数据结果,记录汇总数据后进行分析,推动产品优化和指导运营。
流程伴随着规范,通过定义我们看到,特定用户行为和事件是我们的采集重点,还需要处理和发送相关技术及实施过程;数据埋点是服务于产品,又来源于产品中,所以跟产品息息相关,埋点在于具体的实战过程,跟每个人对数据底层的理解程度有关。
2.为什么要做埋点
埋点就是为了对产品进行全方位的持续追踪,通过数据分析不断指导优化产品。数据埋点的质量直接影响到数据,产品,运营等质量。
(1)数据驱动-埋点将分析的深度下钻到流量分布和流动层面,通过统计分析,对宏观指标进行深入剖析,发现指标背后的问题,洞察用户行为与提升价值之间的潜在关联。
(2)产品优化-对产品来说,用户在产品里做了什么,停留多久,有什么异常都需要关注,这些问题都可以通过埋点的方式实现。
(3)精细化运营-埋点可以贯彻整个产品的生命周期,流量质量和不同来源的分布,人群的行为特点和关系,洞察用户行为与提升业务价值之间的潜在关联。
3.埋点的方式
埋点的方式都有哪些呢,当前大多数公司都是客户端,服务端相结合的方式。
准确性:代码埋点>可视化埋点>全埋点
三、埋点的框架和设计
1.埋点采集的顶层设计
所谓的顶层设计就是想清楚怎么做埋点,用什么方式,上传机制是什么,具体怎么定义,具体怎么落地等等;我们遵循唯一性,可扩展性,一致性等的基础上,我们要设计一些通用字段及生成机制,比如:cid, idfa,idfv等。
用户识别:用户识别机制的混乱会导致两个结果:一是数据不准确,比如UV数据对不上;二是涉及到漏斗分析环节出现异常。因此应该做到:a.严格规范ID的本身识别机制;b.跨平台用户识别。
同类抽象:同类抽象包括事件抽象和属性抽象。事件抽象即浏览事件,点击事件的聚合;属性抽象,即多数复用的场景来进行合并,增加来源区分。
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;埋点的制定过程本身就是规范底层数据的过程,所以一致性是特别重要,只有这样才能真正的用起来。
渠道配置:渠道主要指的是推广渠道,落地页,网页推广页面,APP推广页面等,这个落地页的配置要有统一规范和标准
2. 埋点采集事件及属性设计
在设计属性和事件的时候,我们要知道哪些经常变,哪些不变,哪些是业务行为,哪些是基本属性。基于基本属性事件,我们认为属性是必须采集项,只是属性里面的事件属性根据业务不同有所调整而已,因此,我们可以把埋点采集分为协议层和业务层埋点。
业务分解:梳理确认业务流程、操作路径和不同细分场景、定义用户行为路径分析指标:对特定的事件进行定义、核心业务指标需要的数据事件设计:APP启动,退出、页面浏览、事件曝光点击属性设计:用户属性、事件属性、对象属性、环境属性
3. 数据采集事件及属性设计
Ev事件的命名,也遵循一些规则,同一类功能在不同页面或位置出现时,按照功能名称命名,页面和位置在ev参数中进行区分。仅是按钮点击时,按照按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标识和ev参数之间用“#”连接(一级连接符)
ev参数和ev参数之间用“/”来连接(二级连接符)
ev参数使用key=value的结构,当一个key对应多个value值时,value1与value2之间用“,”连接(三级连接符)
当埋点仅有ev标识没有ev参数的时候,不需要带#
备注:
ev标识:作为埋点的唯一标识,用来区分埋点的位置和属性,不可变,不可修改。
ev参数:埋点需要回传的参数,ev参数顺序可变,可修改
app埋点调整的时,ev标识不变,只修改后面的埋点参数(参数取值变化或者增加参数类型)
一般埋点文档中所包含的sheet名称以及作用:
A、曝光埋点汇总;
B、点击和浏览埋点汇总;
C、失效埋点汇总:一般会记录埋点失效版本或时间;
D、PC和M端页面埋点所对应的pageid;
E、各版本上线时间记录;
埋点文档中,所有包含的列名及功能:

4.基于埋点的数据统计
用埋点统计数据怎么查找埋点ev事件:
(1)明确埋点类型(点击/曝光/浏览)——筛选type字段
(2)明确按钮埋点所属页面(页面或功能)——筛选功能模块字段
(3)明确埋点事件名称——筛选名称字段
(4)知道ev标识,可直接用ev来进行筛选
根据ev事件怎么进行查询统计:当查询按钮点击统计时,可直接用ev标识进行查询,当有所区分可限定埋点参数取值。因为ev参数的顺序不做要求可变,所以查询统计时,不能按照参数的顺序进行限定。
四、应用-数据流程的基础
1.指标体系
体系化的指标可以综合不同的指标不同的维度串联起来进行全面的分析,会更快的发现目前产品和业务流程存在的问题。
2.可视化
人对图像信息的解释效率比文字更高,可视化对数据分析极为重要,利用数据可视化可以揭示出数据内在的错综复杂的关系。
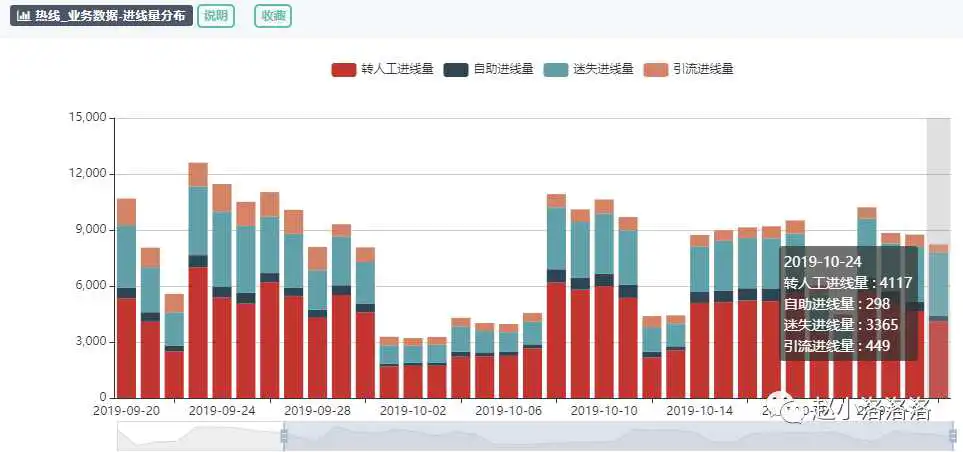
3.埋点元信息api提供
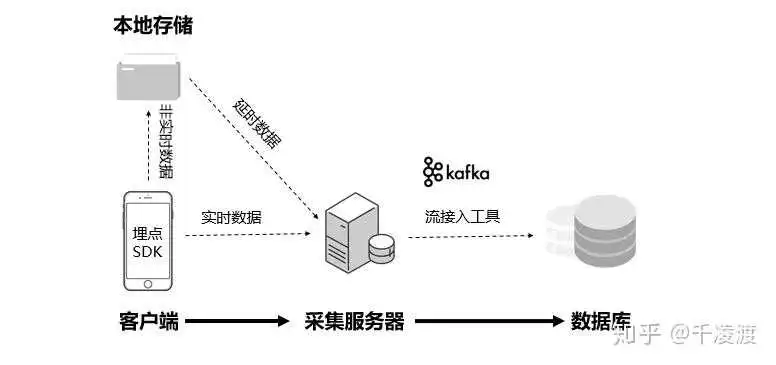
数据采集服务会对采集到的埋点写入到 Kafka 中,对于各个业务的实时数据消费需求,我们为每个业务提供了单独的 Kafka,流量分发模块会定期读取埋点管理平台提供的元信息,将流量实时分发的各业务 Kafka 中。
数据采集犹如设计产品,不能过度。不仅要留出扩展余地,更要经常思考数据有没有,全不全,细不细,稳不稳,快不快。
作为服务过上千家企业的数据分析公司,让我们来好好回答一下这个问题!对于新手来说,除了埋点外,还有更好的选择 —— 无埋点。
1.1 什么是埋点?
一种非常传统、非常普遍的方式就是通过写代码去定义这个事件。在网站需要监测用户行为数据的地方加载一段代码,比如说注册按钮、下单按钮等。加载了监测代码,我们才能知道用户是否点击了注册按钮、用户下了什么订单。
所有这些通过写代码来详细描述事件和属性的方式,国内都统称为“埋点”。这是一种非常耗费人力的工程,并且过程非常繁琐重复,但是大部分互联网公司仍然雇佣了大批埋点团队。
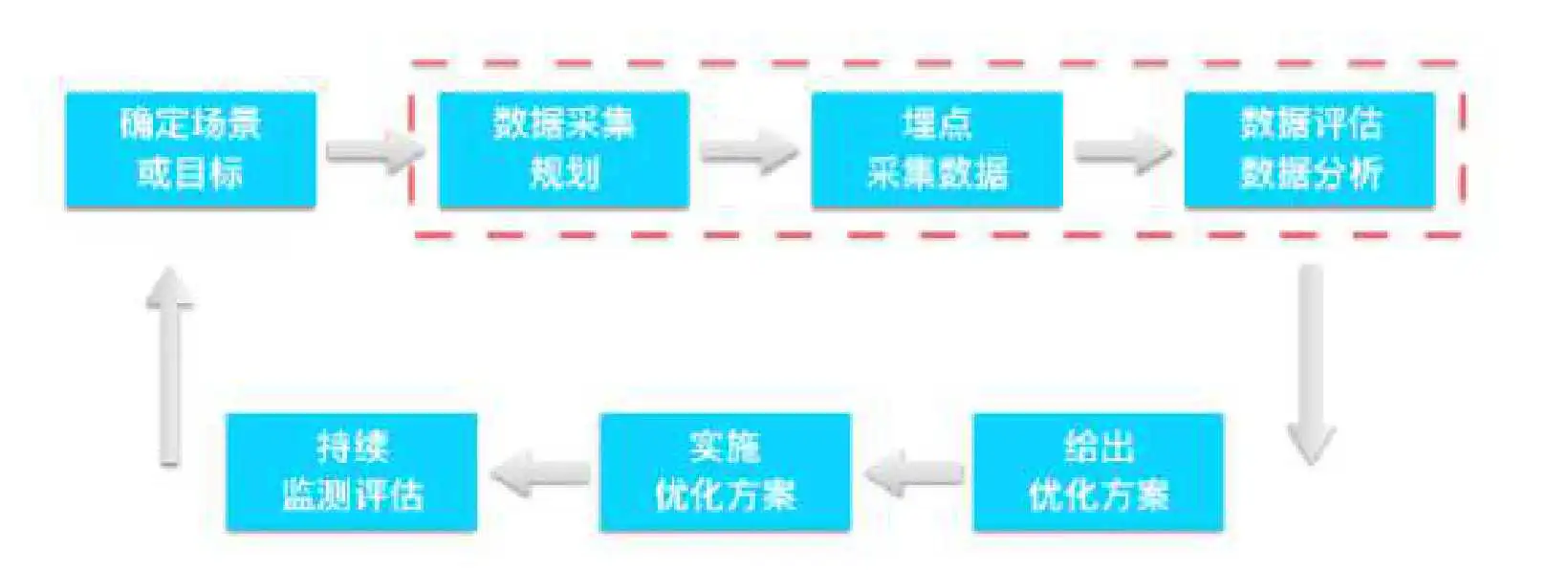
1.2 埋点采集的 7 个步骤
那么,埋点采集数据的过程又是怎样的呢?一般可以分成以下七个步骤。
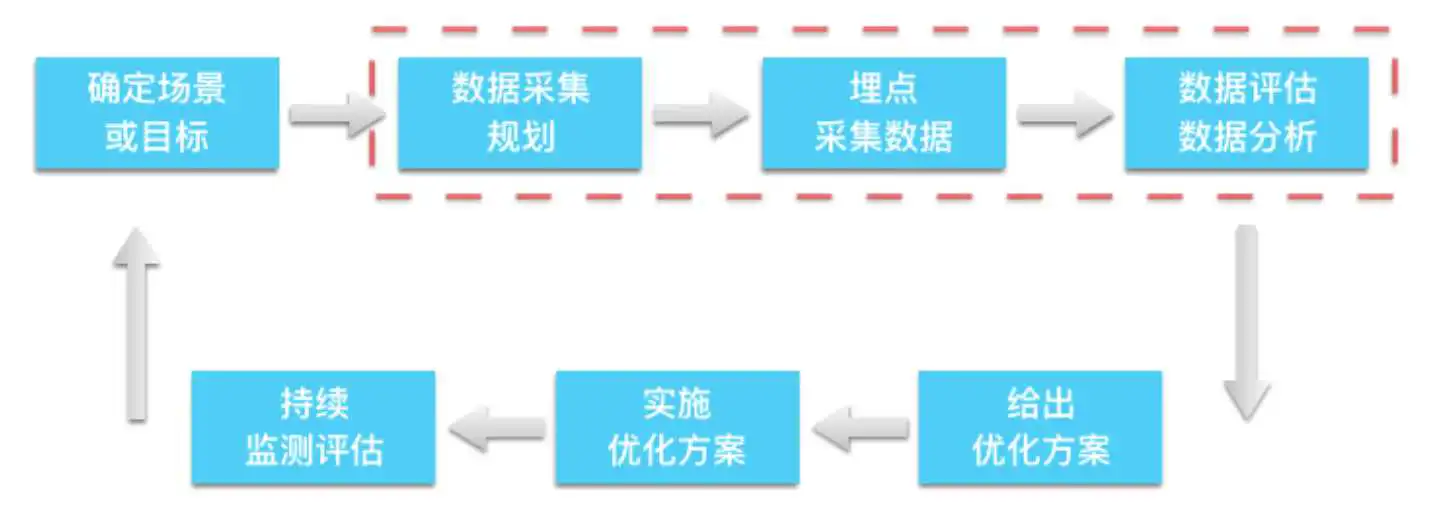
(1)确定场景或目标
确定一个场景,或者一个目标。比如,我们发现很多用户访问了注册页面,但是最终完成注册的很少。那么我们的目标就是提高注册转化率,了解为什么用户没有完成注册,是哪一个步骤挡住用户了。
(2)数据采集规划
思考哪些数据我们需要了解,帮助我们实现这个目标。比如对于之前的目标,我们需要拆解从进入注册页面到完成注册的每一个步骤的数据,每一次输入的数据,同时,完成或者未成为这些步骤的人的特征数据。
(3)埋点采集数据
我们需要确定谁来负责收集数据?这个一般是工程师,有些企业有专门的数据工程师,负责埋点采集数据。
(4)数据评估和数据分析
收集上来的数据质量如何,又该如何分析呢?
(5)给出优化方案
发现问题后,怎么来出解决方案。比如,是否在设计上改进,或者是否是工程上的 bug。
(6)实施优化方案
谁负责实现解决方案。确定方案的实施责任人。
(7)如何评估解决方案的效果?
下一轮数据采集和分析,回到第一步继续迭代。
知易行难。这整个流程里,第 2 步到第 4 步是关键。目前传统的服务商比如 Google Analytics 、Mixpanel、友盟所采用的方式我们称之为 Capture 模式。通过在客户端埋下确定的点,采集相关数据到云端,最终在云端做呈现。
1.3 埋点采集数据的 4 个缺点
Capture 模式采集到的数据非常精准,对于非探索式分析来说是一个非常行之有效的方法。同时,对参与整个流程的人也提出了非常高的要求。
- 依赖经验导向
Capture 模式非常依赖人的经验和直觉,采集哪些指标和维度的数据,这都需要提前想好。不是说经验和直觉不好,而是有时我们自己也不知道到底什么是好的。经验反而会成为一个先入为主的负担,我们需要用数据来测试来证明。
- 沟通成本高
一个有效的分析结果,依赖于数据的完整性和完备性。在跟不少企业沟通后,我发现不少的吐槽都跟数据格式有关,比如 “连日志格式都统一不了,更别提后续分析了“。这不是具体人的问题,更多是协作沟通的问题。参与人越多,产品经理、分析师、工程师、运营等等,每个人的专业领域又各不相同,出现误解太正常了。
- 大量时间数据清洗
另外,由于需求的多变性、埋点分成多次加入、缺乏统筹设计和统一管理,结果代码自然是无比混乱。所以我们数据工程师还有个很大的工作是数据清洗,手动跑 ETL 出报表。根据统计,绝大多数分析工作,百分之七十到八十的时间是在做数据清洗和手动 ETL,只有百分之二十左右在做真正有业务价值的事情
- 数据漏采错采
如果说上面的缺点很让你头疼,那么接下里的问题就更让人抓狂。很多时候埋点监测代码上线后,发现数据采集错了或者漏了;修正后,又得重新跑一遍流程,这样一个星期两个星期有过去了。这也是为什么,数据分析工作是如此耗时一般以月计的原因,非常低效。
在经历了无数个痛苦的夜晚以后,我们决定要换个思路思考了,希望能最大限度的降低人为的错误。我们称之为 Record 模式,这也就是现在的“无埋点”数据采集方案。
区别于 Capture 模式,Record 模式是用机器来替代人的经验;在数据分析产品 GrowingIO 中,无需手动一个一个埋点;只需在第一次使用时加载一段 SDK( Software Development Kit,软件开发工具包 )代码,即可采集全量、实时的用户行为数据。
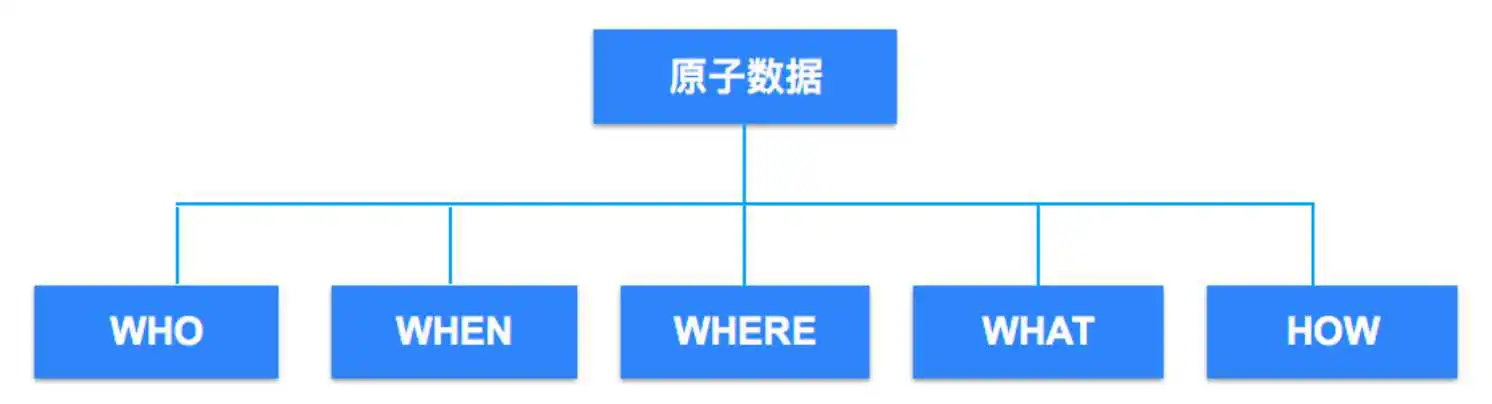
因为自动化,我们从分析流程的源头开始就控制了数据的格式。所有数据,从业务角度出发,划分为 5 种维度: Who,行为背后的人,具有哪些属性;When,什么时候触发的这个行为;Where,城市地区浏览器甚至 GPS 等;What,也就是内容;How,是怎样完成的。
基于对信息的解构,保证了数据从源头就是干净的,再在此基础上面,我们完全可以把 ETL 自动化,需要什么数据可以随时回溯。
1.4 无埋点的技术优势
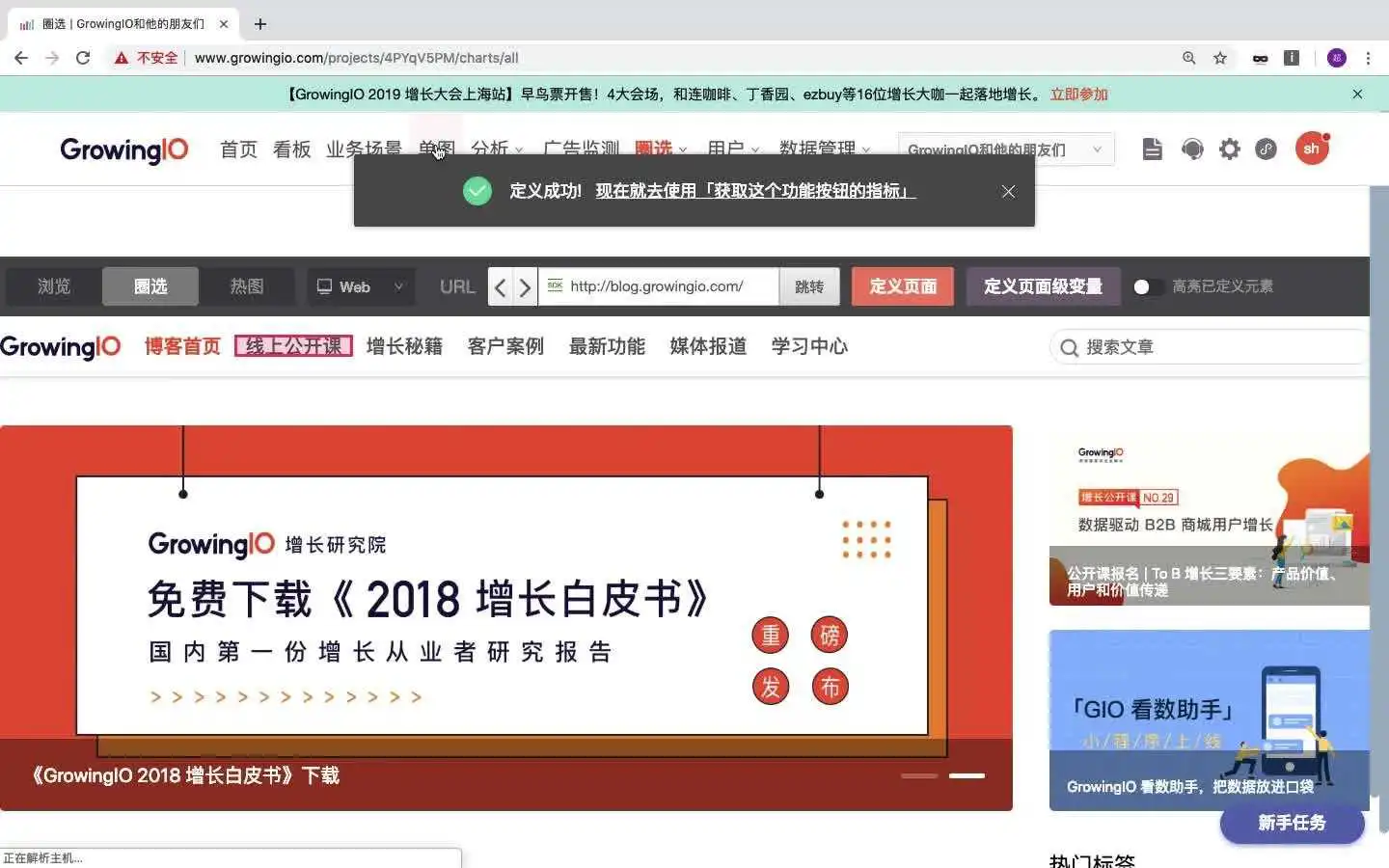
回顾上面埋点采集数据的 7 个步骤,无埋点很好地解决了第二、三、四步的需求,将原来的多方参与减少到基本就一方了。无论是产品经理、分析师还是运营人员,都可以使用可视化工具来查询和分析数据,真正做到所见即所得。不仅是 PC,还支持 iOS、Android 和 Hybrid,可以进行跨屏的用户分析。
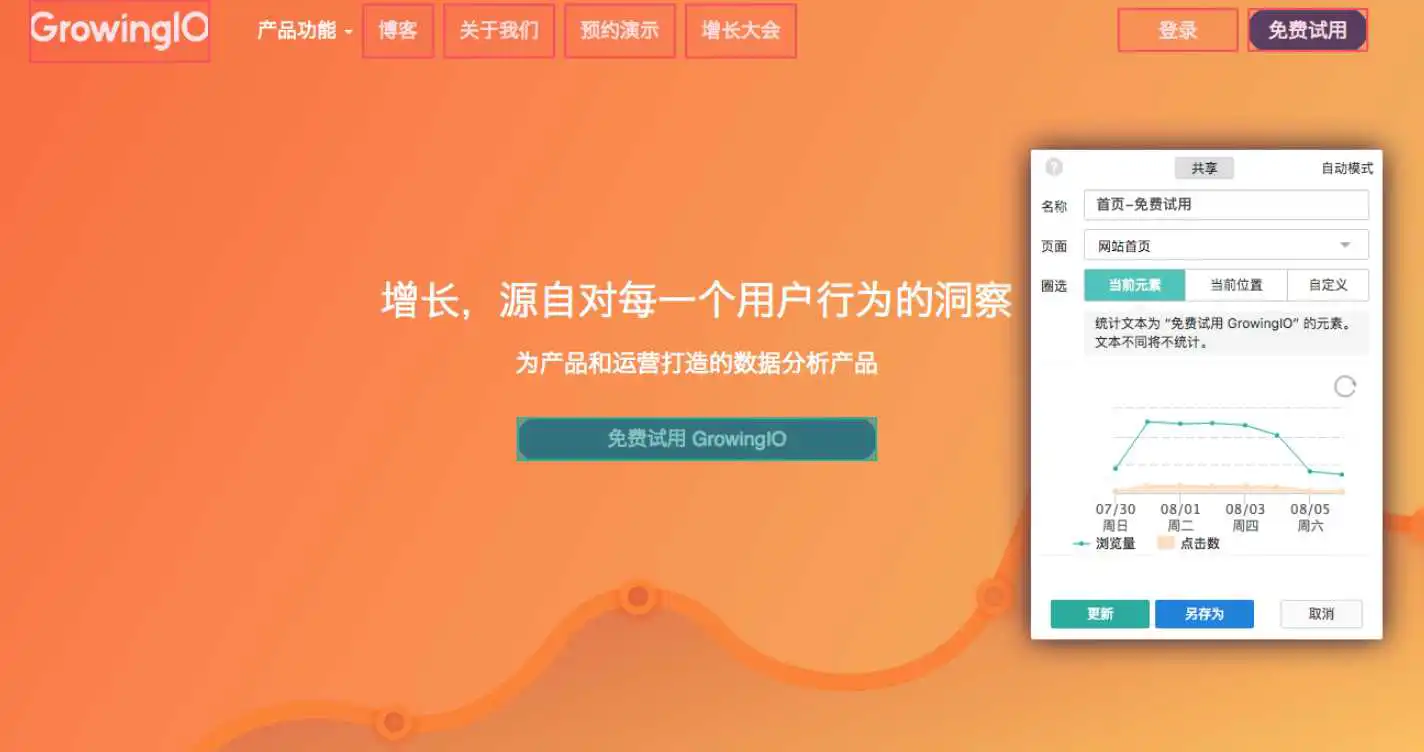
我们以自己的官网( www.growingio.com )为例,加载了我们自己的监测代码后;无需一个一个写埋点代码,只需要用鼠标圈选对应元素,即可获得数据。上图中,如果市场部门员工想知道每天有多少人点击了【免费试用 GrowingIO 】按钮,只需用在 GrowingIO 产品内用鼠标圈选该按钮,即可获得该按钮的点击量和浏览量。原来埋点方式需要花费产品和工程几天的时间,现在业务端同事可以自己几秒钟就解决。
用户行为数据采集的目的是通过了解用户过去做的行为,用来预测未来发生的事情。无需埋点,随时回溯数据,让一个人就可以搞定用户行为分析的全部流程。这样一个简单、迅速和规模化的数据分析产品,能极大地简化分析流程,提交效率,直达业务。
不论是采用无埋点还是埋点的方式,都需要能够将用户的每一次线上的访问过程用数据描述清楚;这个是 数据采集的基本目标,也是 GrowingIO 的初衷。
2.1 “埋点+无埋点”的数据采集原理
我们以一个加载了 GrowingIO 无埋点 SDK 的电商 App 为例:顾客打开 App,在首页搜索关键词,然后在结果页挑选喜欢的商品加入购物车;接着给购物车的商品下订单,并且完成支付。那么在这个过程中,有哪些数据需要采集,又该怎么去采集呢?
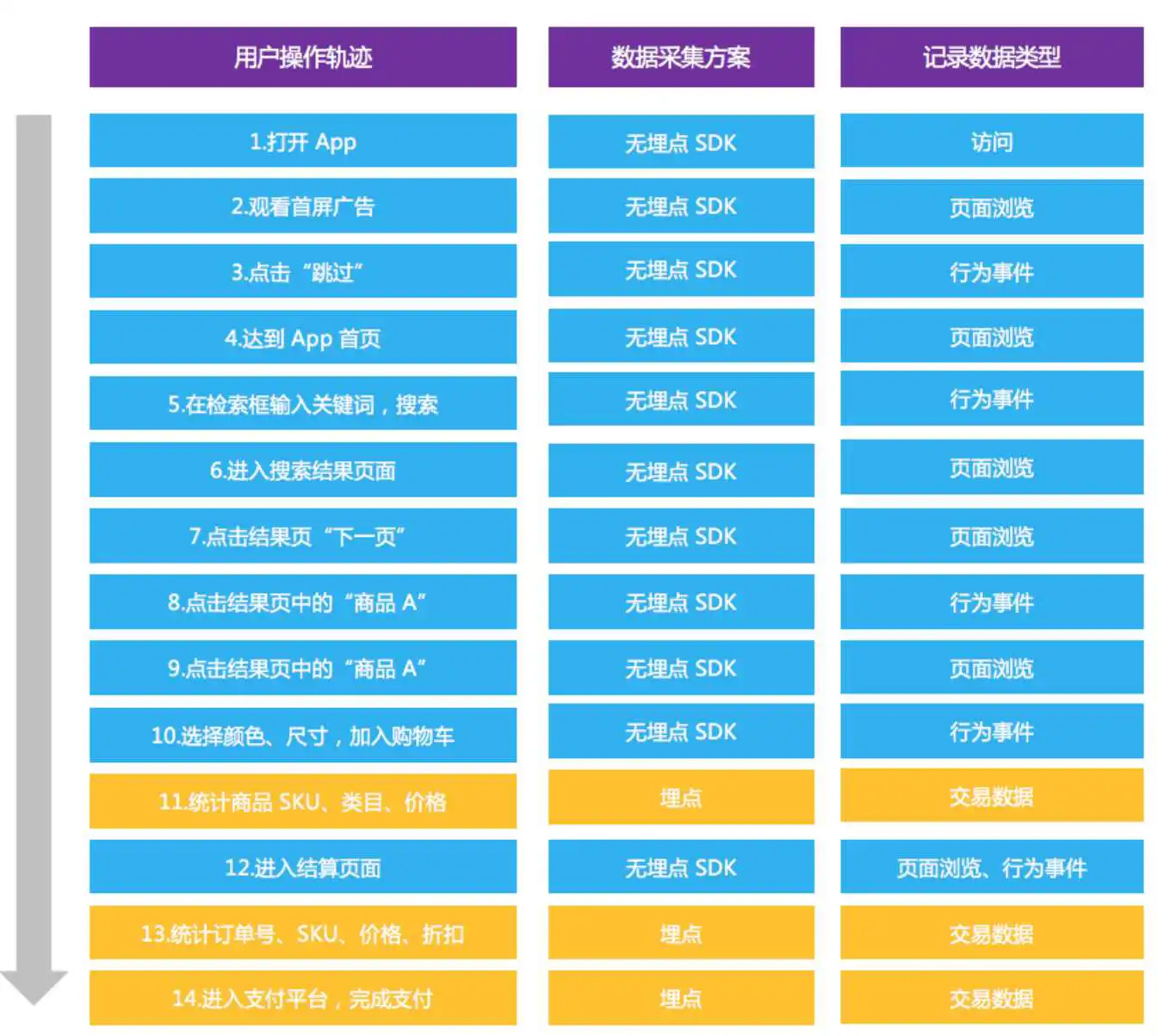
用户从 “打开 App” – “观看首屏广告” – “搜索关键词” – “进入结果页” – “加入购物车” 再到 “支付完成”,整个过程中既有用户行为数据(过程型数据),又有交易数据(结果型数据)。在上图中,GrowingIO 的无埋点 SDK 会自动采集用户在这个 App 上的所有行为数据,包括访问、页面浏览和行为事件。同时,GrowingIO 的数据对接埋点方案可以采集更多的交易数据,这里面包括商品 SKU、价格、折扣、支付等信息。
这样我们就可以将一个完整的线上购物行为,用无埋点和埋点相结合的方式采集下来了,用数据来完整的来描述和分析用户的购物历程。其实不论什么线上的业务场景,我们都希望能够采集到完整的用户的行为数据和业务数据。而且要把用户行为数据和业务数据打通。
2.2 “埋点+无埋点”的数据采集优势
那么为什么需要要无埋点和埋点相结合的方式去采集数据呢?
第一,因为无埋点的方法本身效率比较高。经过实践我们发现,无埋点产生的数据指标是埋点产生的数据指标的 100 倍甚至更多。
第二,无埋点数据采集成本低,App 发版/网站上线,都不影响数据自动采集。
第三,埋点采集的优势是可以更加详细的描述每个事件的属性,特别针对结果数据。
用无埋点采集的用户行为数据是用户产生最后结果的“前因”数据,用埋点采集的业务数据是结果数据是“后果”。无埋点和埋点相结合的解决方案提高了工作效率,同时记录了“前因”和“后果”数据,帮助市场、产品和运营分析获客、转化和留存,实现用户的快速增长。
2.3 如何选择埋点或无埋点
新的无埋点虽然简单便捷,但也有它自身的局限性。同时,我们离不开业务数据维度,所以传统埋点也不能放弃。
埋点和无埋点各有优势,面对不同的场景,我们需要明确目的、结合具体情况综合判断,选择数据采集的最优方式。
我们整理出了以下表格,方便大家更好的理解和选择:

总之,埋点技术灵活、稳定、局限性低、精度高,适合跟踪关键节点,隐藏程序逻辑搭配业务维度观察的数据。
无埋点技术确定快,有历史数据,有预定义维度加持,适合快速查看某些趋势型或流程型数据。
当我们选择无埋点还是埋点时,只需要关注:该行为非核心指标且存在预定义无埋点指标中。
如果存在该预定义指标(即无埋点),且预定义维度也满足需求,那么,我们就要针对该无埋点的指标和维度进行观察,可放心选择无埋点。如果不存在或预定义维度无法满足观察该指标的角度,则需要通过埋点指标进行上报。
以上就是针对该问题的回答,希望能对大家有所帮助
知友福利:点击申请 GrowingIO 数据指标体系搭建方案
数据指标体系搭建方案 | GrowingIO - 硅谷新一代无埋点用户行为数据分析产品
GrowingIO 数据指标体系搭建方案,提供“埋点+无埋点”双模式高效采集数据,可视化数据看板指导业务增长。我们拥有国内外专业的商务数据分析师团队,帮助客户梳理数据指标体系,提出解决方案,切实找到可落地的数据增长点。

我从数据采集的两大方式(埋点和无埋点)开始,再通过一个典型案例来分享。希望我的回答能对问主有帮助。
数据采集可以说是落地整个数据驱动增长最基础、也是最关键的一步。因为只有采集的数据足够准确,我们才能通过数据分析做出正确的决策,进而促进活动、产品及公司的整体增长,意义是十分重大的!
数据采集分为两种方式,一种是埋点,一种是无埋点。我们需要了解什么场景下使用无埋点事件,什么场景下使用埋点事件,以便于满足业务的分析诉求。在了解场景之前,我们更需要了解数据采集方式的特性和边界,才能扬长避短,充分发挥两种采集方式的优势。
埋点,也有称打点, 顾名思义就是借助埋点(写代码)来采集数据,在需要监测用户行为数据的地方加上一段代码。我们可以称之为 Capture 模式,通过在客户端/服务端埋下确定的点,采集相关数据到云端,最终在云端做呈现。
经过数据校验后的埋点数据非常准确,稳定性高,适合监控和分析,对于非探索式分析来说是一个非常行之有效的方法;且埋点往往可以添加较多的业务属性,方便产品经理对事件进行业务属性拆解和下钻分析,能很好地从业务逻辑切入行为分析,理解行为背后的业务思路。
无埋点,事实上并不是真正的不需要写代码,而是前端自动采集全部事件并上报所有的数据,并通过「圈选」来获取需要使用的事件。区别于上文埋点中提到的 Capture 模式,无埋点采用的是 Record 模式,用机器来替代人的经验。
作为拥有业内领先无埋点技术的 GrowingIO,我们在 GrowingIO 产品中,无需手动一个一个埋点;只需在首次使用时加载一段 SDK( Software Development Kit,软件开发工具包 )代码,即可采集全量、实时的用户行为数据。
一个用无埋点采集方式就能解决的问题,若使用埋点,既不能立刻看到数据,也会浪费公司工程资源;一个用埋点采集才能解决的问题,用了无埋点可能会导致数据不稳定,业务维度少等问题。
所以这就需要我们能基于不同的业务场景,选取不同的数据采集方式,高效高质的完成数据采集。
为了方便大家更好的理解,这里我们总结了一张埋点和无埋点优劣势及其不同适用场景的对比图:
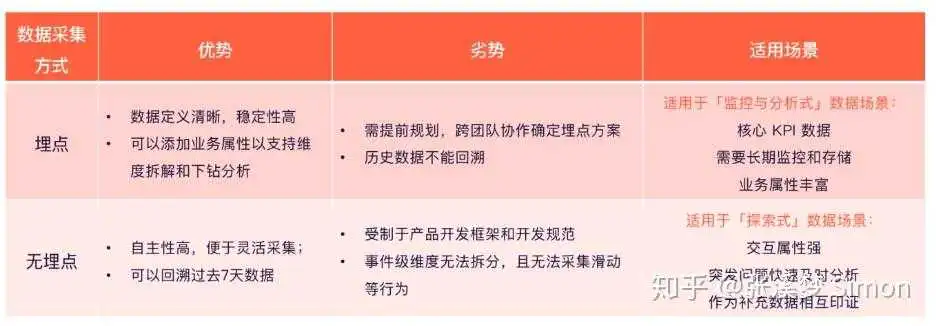
埋点和无埋点各自有自己的优势和劣势,因此有着不同的适用场景。
接下来,我们以某 App 的注册流程为例,帮助大家更好的理解,不同场景下如何选择埋点和无埋点。

如图所示,该 App 注册的流程大致为:注册首页填写手机号——注册验证输入短信验证码—注册信息 A、B、C——进入 App 首页。
(1)应该选择无埋点的场景
在这个场景中,业务方的需求是:快速分析现有注册流各个步骤间的转化率,从而找到流失较大的环节进行优化。
可见,业务方关心的是该流程间步骤的转化流程,那么我们就要关注用户的浏览行为动作,可以把指标定义为各个步骤间的页面。
具体来讲,登录动作从登录首页到进入登录后的首页共 6 步,而且我们的关注角度如机型、地区、国家等不属于业务范畴,都在预定义维度中,这就很符合我们无埋点指标的定义规则。
所以我们就可以快速定义出 6 个浏览页面指标,通过 GrowingIO 的无埋点圈选功能,即可完成对于数据的分析。如下图所示,我们完成圈选后,就可以在 GrowingIO 内看到各个步骤的人数和转化情况。
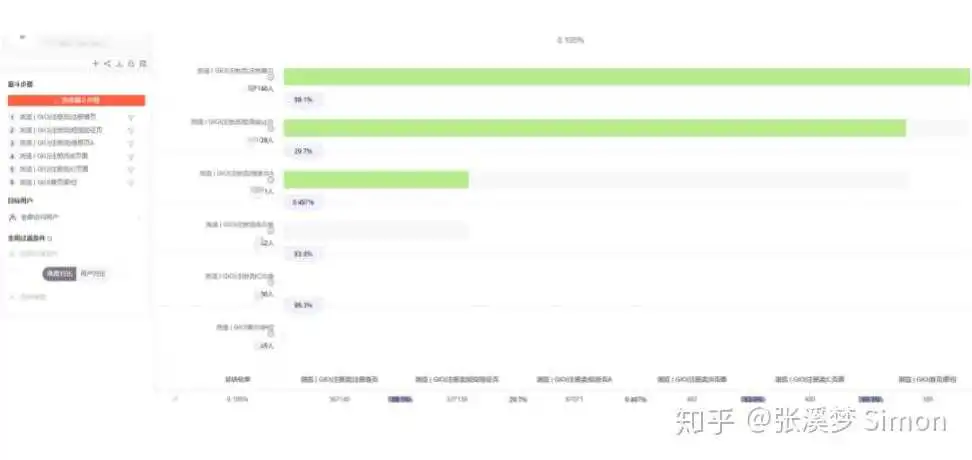
根据观察,注册验证——注册信息 A——注册信息 B 这 3 个页面间的流失率高,我们就需要在这些环节进行相应的优化。
这就是无埋点的快速定义,我们不需要等待下次发版,就可以实时观察数据、分析事件。
(2)应该选择埋点的场景
在这个场景中,业务方的需求是:查看完成注册的用户中,填写行业和性别的分布情况。可见,业务方关心的是需要长期监控和储存的数据,这就需要我们使用埋点去解决。
根据完整埋点方案设计的四要素,我们应逐一确认:
▪ 事件:注册完成;
▪ 维度:行业、性别;
▪ 采用无埋点还是埋点指标:很明显,行业和性别是与业务相关的指标,我们需要通过埋点采集相关数据;
▪ 埋点的触发时机:在注册完成的回调中拿到性别及行业信息;
▪ 确认命名:事件——registerSuccess 注册完成;维度——practiceVocation 行业、sex 性别。
根据呈现出来的埋点方案文档,我们无需反复沟通,程序员便可以快速地明确业务需求,进行埋点操作。
以上就是我对这个问题的回答,希望能对大家有所帮助
福利一:GrowingIO 数据指标体系搭建方案 ⬇⬇⬇
GrowingIO 数据指标体系搭建方案,提供“埋点+无埋点”双模式高效采集数据,可视化数据看板指导业务增长。我们拥有国内外专业的商务数据分析师团队,帮助客户梳理数据指标体系,提出解决方案,切实找到可落地的数据增长点。
数据指标体系搭建方案 | GrowingIO - 硅谷新一代无埋点用户行为数据分析产品
福利二:《指标体系与数据采集》电子书 ⬇⬇⬇
我们结合 5 年来服务上千家客户的经验,融合经典方法论与成功实践,推出这本电子书。围绕「数据指标体系搭建」展开,共计 69 页,详细介绍了如何运用模型规划、如何选择采集方式、如何管理数据指标等一系列知识框架与经典案例
电子书获取


数据埋点是开启数据分析的第一步。但埋点过程本身,涉及产品、运营、技术等多环节多职能。即使在互联网公司,很多运营人对埋点也是一头雾水,对埋点规划、埋点与数据分析的关系、典型场景埋点方案,都是在摸索中前行。
我们请到了友盟+数据培训专家张跃,和我们聊聊埋点的那些事。

数据埋点是一种常用的数据采集方法,方便产品/运营系统性的统计分析复杂的用户数据。我们在App端所设置的自定义事件,就是通过数据埋点的方式,实现对用户行为的追踪,以及记录行为发生的具体细节。
通常情况下,我们会对一些关键节点、关键按钮进行监测,比如关键路径的转化率。另外,还可以通过埋点统计核心业务数据。以电商类App为例,在提交订单环节,将用户购买的商品名称、类别、价格等明细数据进行上报,便于后续分析用户行为与洞察用户偏好。
目前国内主流的数据埋点方式有四类:全埋点、可视化埋点、代码埋点、后端埋点。每种方式都有优缺点,需要根据业务需求评估选择。
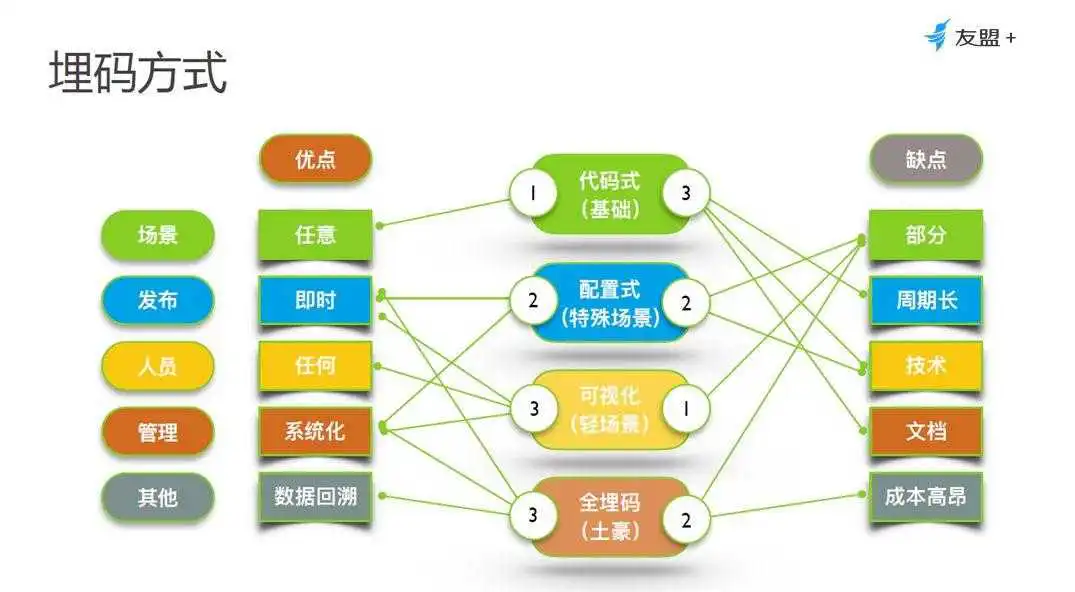
总体来说,全埋点和可视化埋点更侧重结果的展现,对过程追溯少,更适合产品经理分析基础的产品功能流畅度、用户体验、产品路径设置等。
代码埋点和后端埋点,不仅能展现结果,也会记录用户行为过程,支持深度的行为分析和偏好洞察,还可将行为数据与业务数据打通,适合产品和运营人员深度使用。
01点全埋
定义:从名字就可以看出,全埋点会自动采集所有的数据点位,是土豪的埋码方式。
- 优点:几乎可以监测和分析用户在App端的所有行为数据,并且可追溯。
- 缺点:数据存储、计算、分析成本高昂,对用户在前端的加载也有影响。主流App几乎都不会采取此种方式。
02可视化埋点
定义:通过点击交互,在产品界面上直接进行埋点。先分析,再圈选,是一种所见即所得的埋点方式。
- 优点:跳过技术部署,集成简单,小白也能很快上手;能够监测产品前端用户交互数据
- 缺点:所采集的数据,属于前端浅层数据,而侧重属性的数据带不回来。例如,对于新闻类App,能监测到用户点击标题的行为,但作者、细分标签、发布时间等数据无法采集,且无法进行数据追溯。
03代码埋点
定义:通过技术代码在App接口中进行埋点,需产品、技术、运营的通力配合。
- 优点:代码埋点可以采集到你想要的所有数据(服务端、客户端);前期需要系统性规划,数据分析会更贴合业务场景;且数据维度更丰富和深入,适合精细化分析和用户行为洞察。
- 缺点:前期工作量会稍大,包括埋点规划和技术实施。产品新增功能后,需要技术埋点并且发布App后才能统计到数据。
04后端埋点
定义:通过导入工具或系统,将数据(通常是后端日志)直接进行上报。从经验上判断,后端采集适合结合深度业务数据的挖掘,而前端采集适合基于用户行为的产品运营。
- 优点:做为“独立”的上报通道,其安全性、准确性较高。(前端通过用户层面的上报,可能会因为各种环境丢失数据、可能在传输途中被劫持);可结合相关业务数据,将整个业务过程进行更全面的描述;同质化的采集,使用后端替代前端采集,可提升因前端采集带来的性能流失,给用户带来更好的体验。
- 缺点:有些纯前端的行为,没有记录对应的后端日志,这部分数据无法采集和获知。
特别强调:无论采用哪种埋点方式,都应该根据业务场景和产品阶段,梳理和构建数据分析体系。埋点规划混乱、数据采集无序、数据分析断层,最终将会让企业陷入“有数据而无价值”的境地。
全埋点和可视化埋点,产品经理和运营人员就可以操作实现。代码埋点和后端埋点则需要技术同学配合完成。友盟+支持代码埋点,为开发者提供API接口,通过技术层面实现数据上报。
极简埋点的3步骤:
1、需求梳理,埋点目的是什么,有哪些业务场景,需要哪些维度的数据,如何构建数据分析体系。
2、需求落地,埋点不是越多越好,需要与技术讨论埋点的合理性和可行性,大致一致之后,再开始行动。
3、开始埋点,在App端埋点后,与第三方平台API对接。上传相应的事件ID与事件名称,与代码中的ID与名称一致。
1、埋点和数据分析是因与果的关系
只有前期将埋点规划好,后期才可能做用户行为分析,而且埋点的分层做的越细致,可分析的维度也就越细致。要统计的数据庞大时,建议分阶段分版本进行埋点,先对主要事件关键路径进行埋点,一步一步完善。
2、 产品技术运营的多方协同
埋点一定是需求方提出的(产品和运营为主),业务场景和需求整理、制定埋点方案,与技术团队对接埋点规划、测试上线。另外,埋点由专人维护,如果这个环节出现问题,就会造成埋点混乱,结果就是采集到的数据都不知道是什么,数据价值下降。
3、 区分测试数据与正式环境
切记先测试,数据无误后再正式发版,且不要将测试数据混淆统计。
4、数据点命名规范
建立一套内部的数据埋点规范,每个点都有专属ID,防止后期数据量大而对应不到具体点位。
一个埋点规划原则:将相同属性的事件进行归类;事件下的属性拆分的越丰富,用户分析的维度也就越详细。
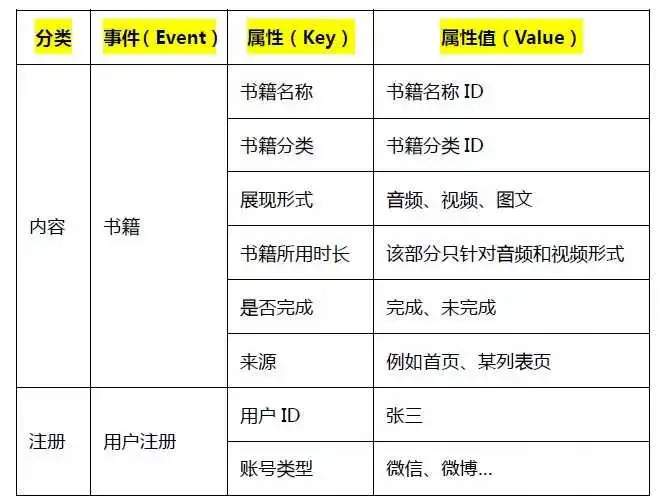
在U-App AI版中,我们将事件分为3级:事件(Event)、属性(Key)、属性值(Value)。
01事件(Event)
定义:对用户使用产品过程中的互动行为的描述,比如说新手注册、加入购物车、购买或播放音乐等。
应用示例:对某事件进行分组查看,如查看不同渠道中“购买”事件的触发情况;查找符合某类筛选条件的事件,如找到触发“播放”事件且触发次数>5次用户。
02属性(Key)
应用示例:如“加入沟通车”这个行为,事件名是“加入购物车”,那么这个事件的属性可以细分出“产品名称、产品类别、金额”等。
以“播放”事件为例,事件名称是“播放”,那么这个事件的属性可以细分出“播放内容、播放类型”等。
03属性值(Value)
定义:属性值是一个变量,需要根据用户真实触发的内容进行上报,如把某产品加入了购物车,针对“产品名称”这个属性,属性值需要上报的就是用户点击过产品的真实名称。
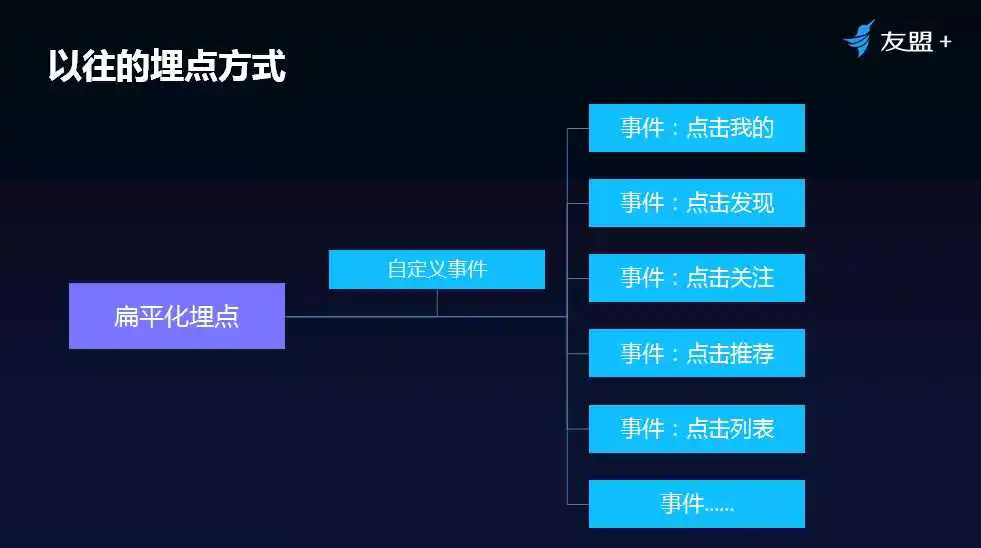
特别注意:
以前开发者做埋点多是平铺式,没有利用属性来针对事件做结构化处理。
以“用户点击按钮”这个事件为例,大多数开发者会把每个按钮当做一个事件来统计,这样做看似直观,可以直接看到按钮A、按钮B分别被点击的次数与人数。但弊端也非常明显,不容易做归类分析。例如,当分析首页所有按钮被点击情况时,只能一个一个事件去相加。
如果在前期埋点时做结构化处理,很容易通过U-App AI版的事件功能做归类分析。
1、扁平化埋点示意图:
2、结构化的事件埋点示意图:
将一类行为当做一个事件,通过属性进行拆分,既能看事件整体,也能拆分细分维度。
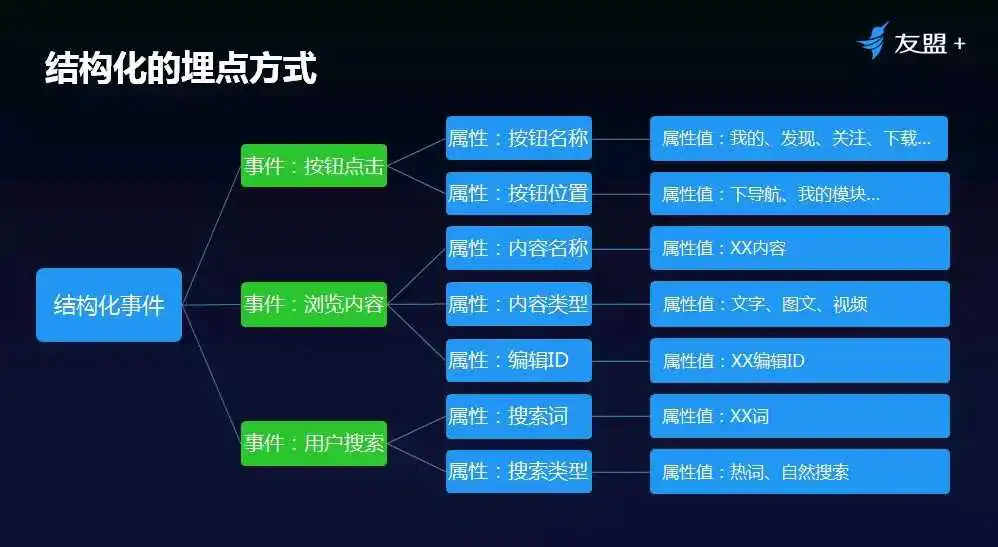
注:属性值需根据实际情况动态获取。
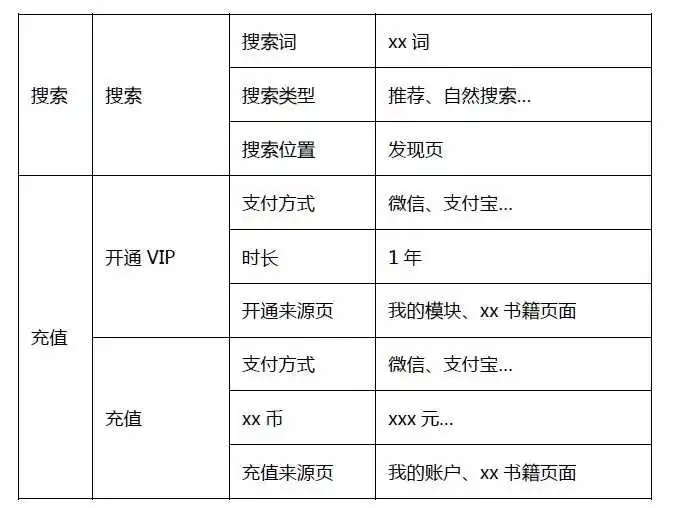
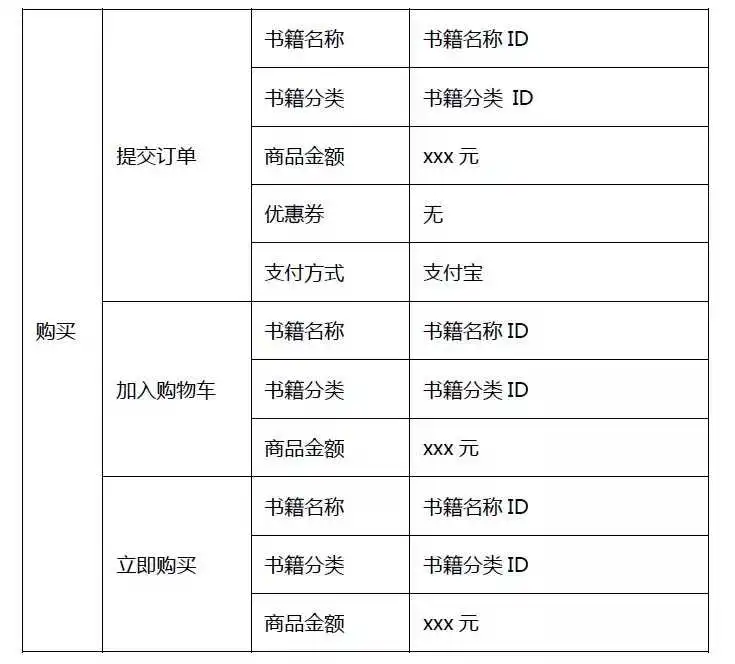
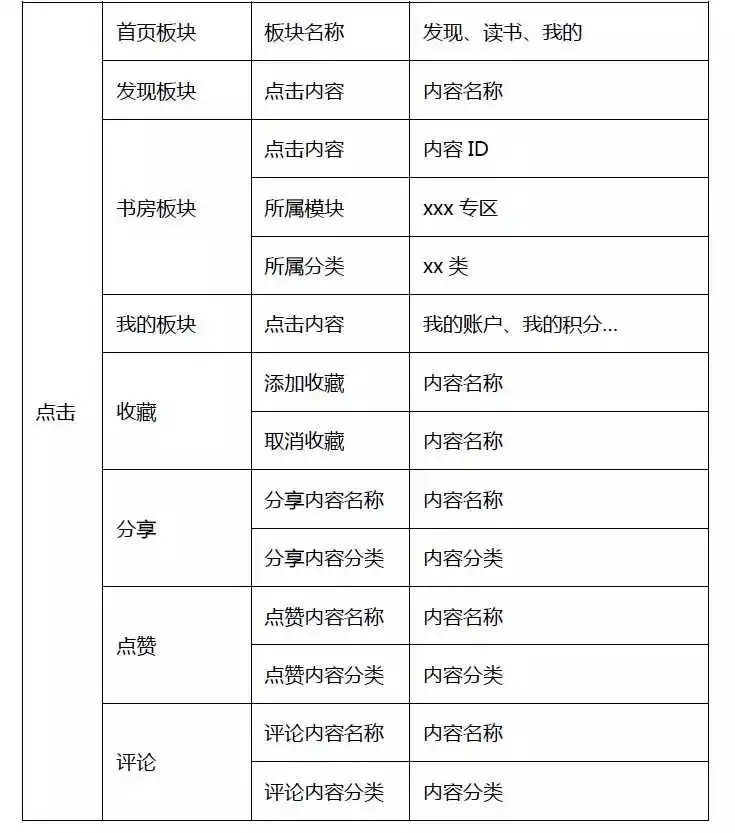
我们以听书类App为例,拆解出通用的埋点样例。在做埋点规划时,我们将有相同属性的事件进行归类。
事件结构分为6块:内容、注册、搜索、充值、购买和点击。
例如,将“阅读数据”拆分出6组属性,帮助App分析用户对哪些类型的书籍感兴趣、用那种形式了解内容、从那个入口获取到的内容等。这样归类的好处是不仅看到整体书籍被阅读的情况,也能细分出用户对内容的偏好和兴趣。
进行以上埋点之后,就可以在U-App AI版中进行数据分析了。
以上,感谢阅读!
如果你想获取更多运营知识,还可以看看这些问答。↓↓↓
- 结构化埋点:移动应用如何埋点收集什么数据以便于统计分析?
- 小程序推广:小程序怎么做运营推广?营销该怎么玩?
- 数据分析:怎么培养数据分析的能力?
- 消息推送:消息推送(push)对app运营的影响有哪些?
❤看后三件事❤
如果你觉得这篇文章对你挺有启发,希望你可以帮我三个小忙:
1、关注 @友盟全域数据, 让我们成为长期关系;
2、点赞,让更多的人也能看到这篇内容(收藏不点赞,都是耍流氓 -_-);
3、评论,让我第一时间了解你的真实想法;
谢谢你的支持!
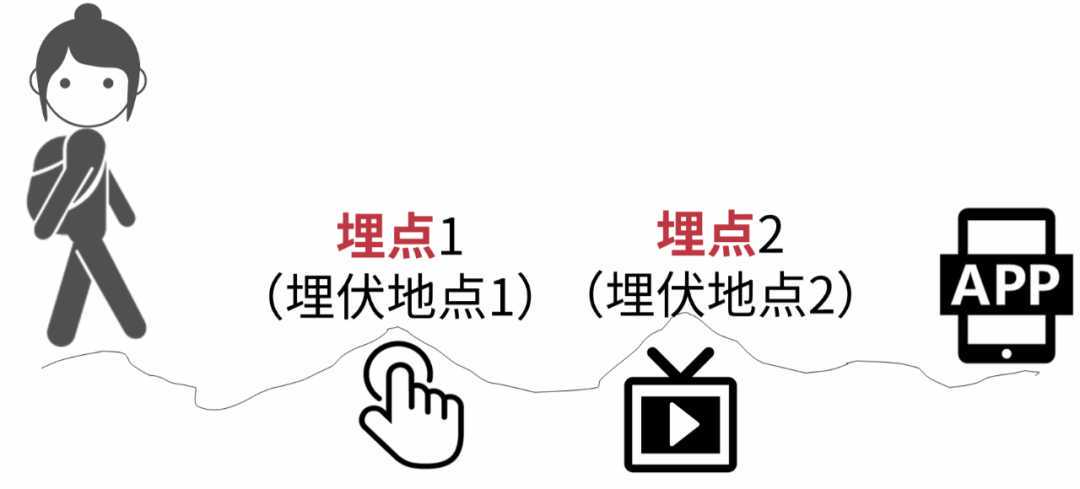
1.什么是埋点?
小时候,为了让喜欢的小姐姐注意到我们几个小伙伴,我和几个小伙伴会先摸熟她每天的回家路线,然后提前埋伏在这条路线上的几个地点,然后突然出现,假装偶遇。

这里的埋伏地点和埋点有什么关系呢?
数据分析的前提是要有数据,那么问题就来了,数据从哪里来?
这就需要进行数据采集,采集哪些数据呢?就需要提前规划好采集数据的地点。
我们把小姐姐回家路线看作一款产品(网站或者App)。为了采集到用户数据,比如用户点击某个按钮的次数、观看视频的时长等(为了让小姐姐看到我),需要在产品中提前埋伏好。
也就是在产品中哪个地方想获取到用户数据(我和小伙伴在路线上提前选好几个地点埋伏)。这就是埋点(也就是埋伏地点)。
了解了什么是埋点,下面来说如何埋点。觉得文字看起来麻烦的话,也可以看视频,我结合自己在IBM的数据分析经历和一些大厂的一线业务案例设计了一套数据分析课程,讲解模型结构+逻辑框架,帮助大家搭建数据分析思维,多维度拆解分析方法等也用案例进行讲解,并带大家实践练习。课程为期3天,直播讲解+学习社群的形式。
这个课程对于0基础、想转行的人也非常合适,能让小白短时间内掌握职场上常用的工具操作、分析技巧方法、和数据思维,解决常见的数据分析问题是没有问题的。
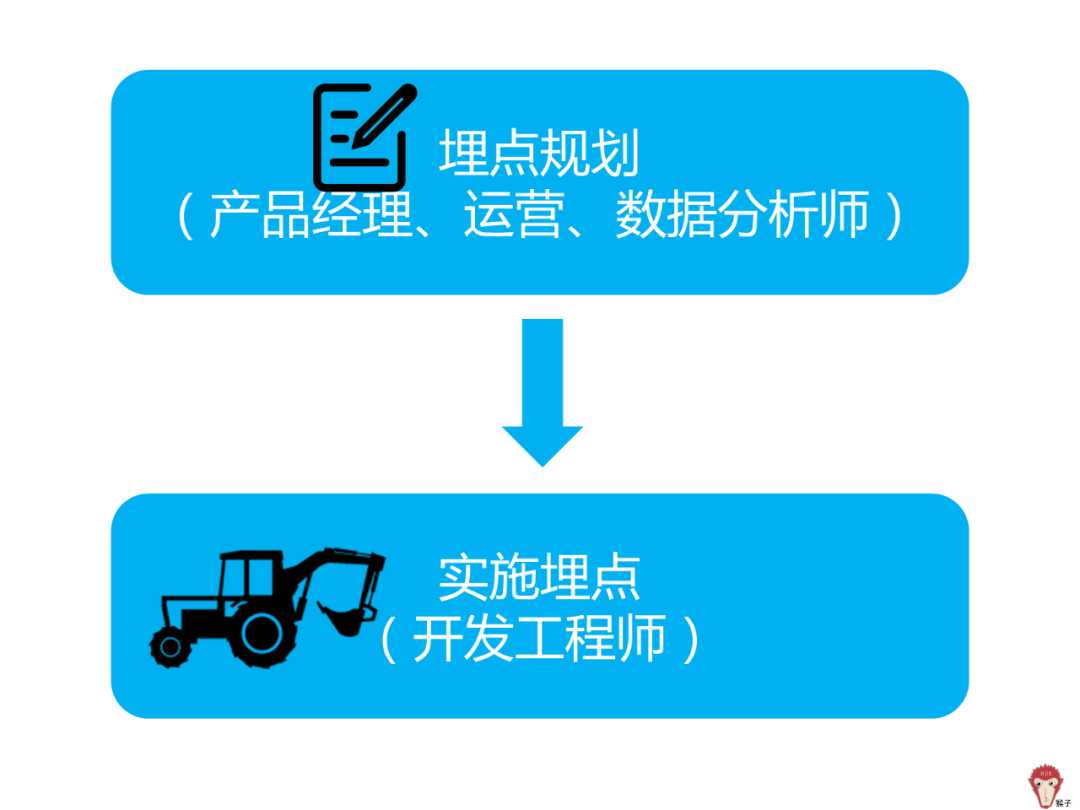
2.如何埋点?
实现埋点的技术有两种:
(1)使用第三方工具实现。比如GrowingIO、Talkingdata、友盟、神策等。
(2)有些公司对数据安全要求高或者业务复杂,就自己开发来实现。也就是公司开发人员在产品的某些地方加上(“埋伏”)代码来统计用户行为数据,然后有一个后台可以查看这些采集到的数据,方便日后分析。
3.埋点是谁的工作呢?
通常是产品经理、运营或者数据分析师提前做好埋点规划(也就是想要采集什么数据),然后由开发工程师来根据规划去实施埋点。当然,有的公司职责划分没这么清楚,会使用第三方工具又一个人完成。
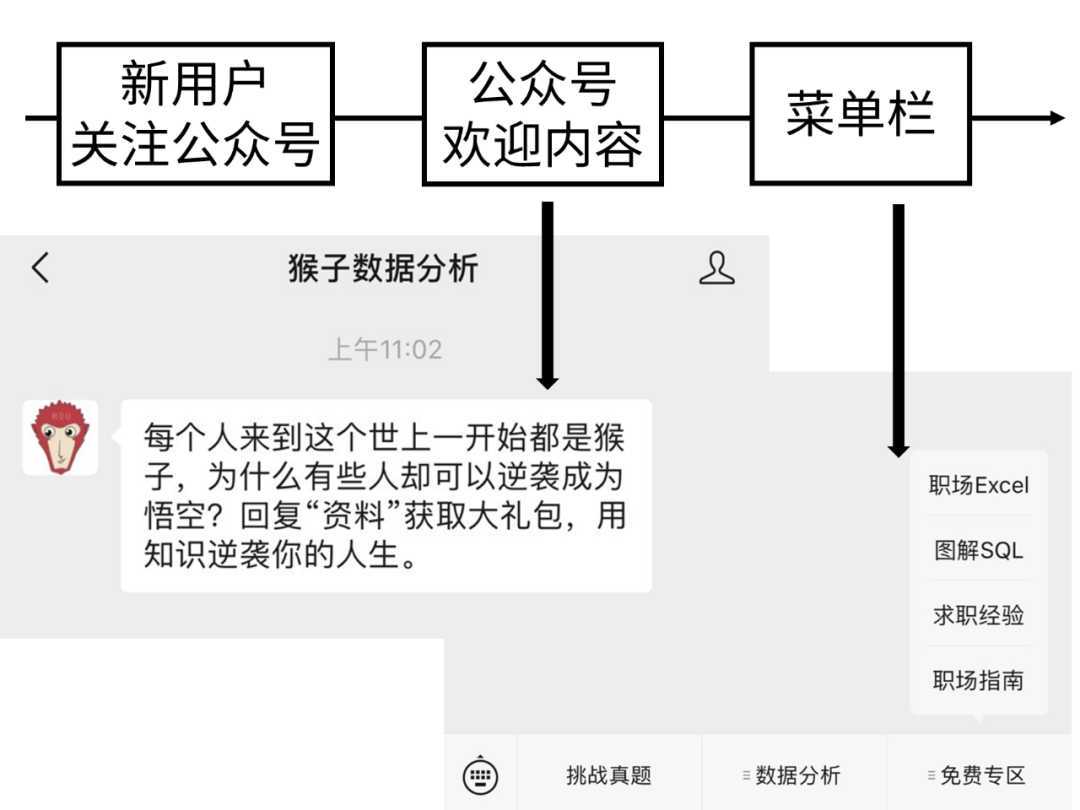
4.如何进行埋点规划?
(1)业务流程是什么?
想知道埋伏在哪里才能和放学回家的小姐姐偶遇,就要提前摸清楚她回家的路线。同样的,想要知道在哪埋点,就要知道产品的业务流程。
(2)分析目标是什么?
埋伏在小姐姐放学回家路上的目标是为了偶遇。同样的,埋点的目标是为了方便分析,所以要清楚分析目标是什么。
例如,分析目标是想知道公众号菜单栏的人均点击次数。
人均点击次数=菜单点击次数/菜单点击人数。所以,需要采集的数据是:菜单点击次数、菜单点击人数。
(3)采集哪些数据?
根据前面的分析目标知道要采集哪些数据,然后才能在产品对应的地方埋点。本案例要采集的数据是菜单点击次数、菜单点击人数。
假设完成了上面埋点规划,实施埋点后,采集到了下面的数据。
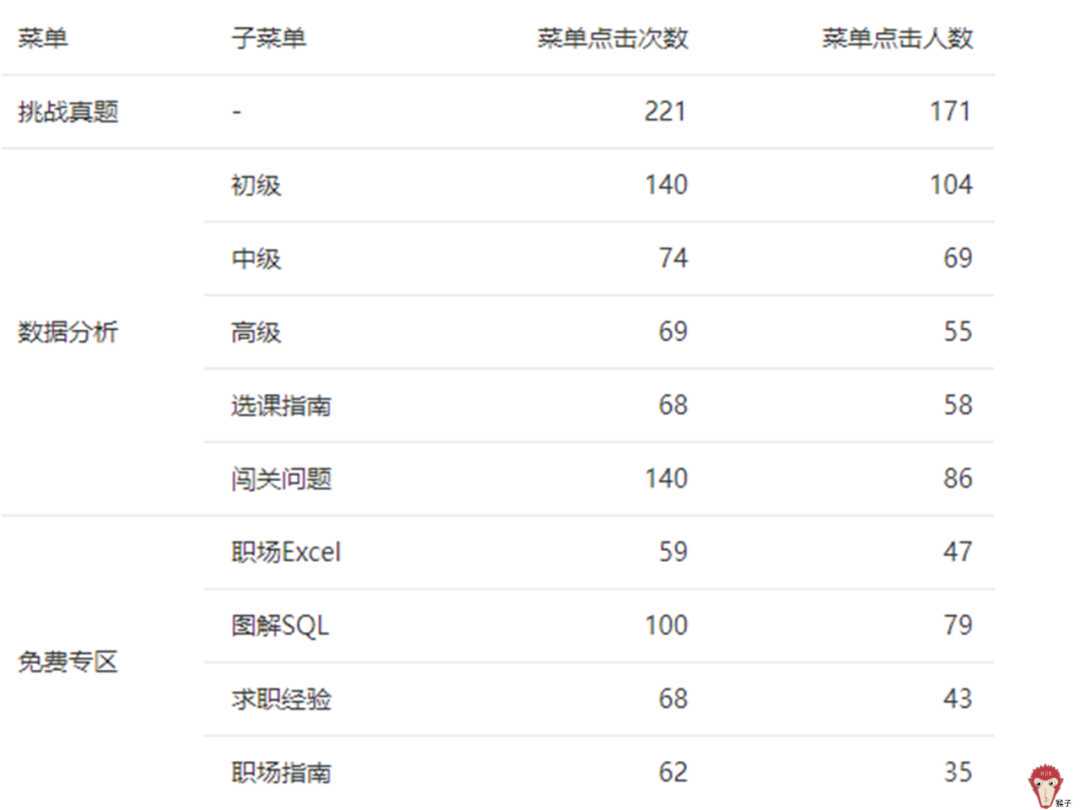
然后,就可以根据采集到的数据,分析出每个菜单的人均点击次数。通过分析可以知道用户喜欢产品的哪个按钮,然后根据分析结果,不断优化菜单里的内容。
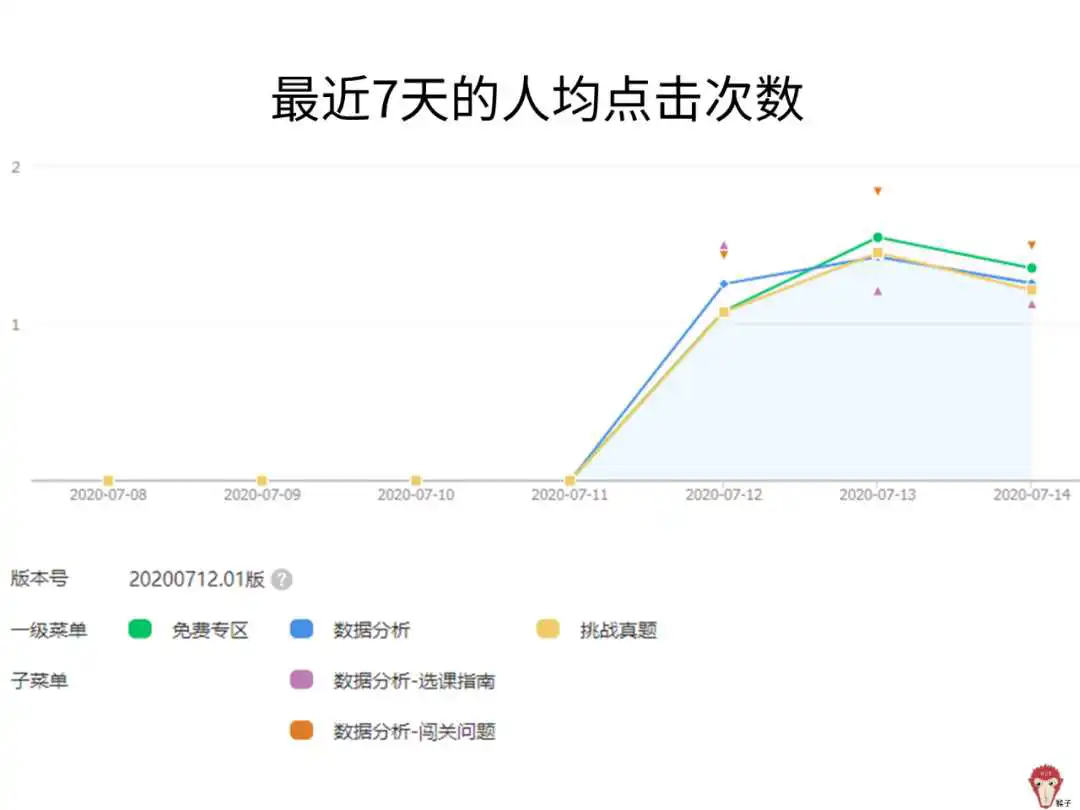
5.总结
(1)什么是埋点?
埋点就是为了采集数据,在产品的某些地方提前埋伏好,来获取数据。
(2)如何进行埋点规划?
通过三步进行:业务流程是什么?->分析目标是什么?->采集哪些数据?
下面这个例子理解埋点也不错
在日常工作中,还有很多像埋点这样的数据分析需求,大到项目管理,营销策略等事关公司盈利的大问题,小到一个表格的快速整理和查漏补缺,只是有时候我们也许意识不到这是数据分析。也因此,现在数据分析成了一个学习热点,我在知乎知学堂的数据分析课程也是针对这样的需求,无论你是想成为数据分析师,还是用数据分析提高工作效率,都是很实用:

数据仓库系列文章(持续更新)
1. 数仓架构发展史 - 等待下一个秋
2. 数据仓库建模方法论 - 等待下一个秋
3. 数仓建模分层理论
4. 数仓建模-宽表的设计 - 等待下一个秋
5. 数仓建模-指标体系 - 等待下一个秋
6. 一文搞懂ETL和ELT的区别
7. 数据湖是谁?那数据仓库又算什么? - 等待下一个秋
8. 技术选型 | OLAP大数据技术哪家强?
9. [数仓相关面试题](https://mp.weixin..com/s/Yu3pWkcJBpH23628bThxGw)
10. 从 0 到 1 学习 Presto,这一篇就够了!
11. 元数据管理在数据仓库的实践应用
12. [做中台2年多了,中台到底是什么呢?万字长文来聊一聊中台](做中台2年多了,中台到底是什么呢?万字长文来聊一聊中台)
13. 数据仓库之拉链表 - 等待下一个秋
开始之前我们先看一下我们为什么要收集埋点数据,埋点都可以做什么,埋点主要用于记录用户行为,几乎是应用必不可少的功能.埋点的作用包括但不限于
分析用户转化以及存留 例如下载的用户数量,注册的用户数量,一段时间之后的存留用户数量;
分析用户偏好 例如通过用户行为的分析,可以对用户的偏好做一定的概括,便于投其所好针对特性的用户推送特定的服务,甚至开发不同的用户体验;
收集市场反馈 例如针对新功能的用户行为进行统计,就可以分析出功能的市场反馈,为是否保留功能或者改良方向提供依据;
保障用户数据安全 例如用户的地理位置数据在短时间内突然发生了异常变更,这一秒在南京,下一秒突然就在东京登陆了,那就说明账号发生了异常,需要对账号身份进行验证,以确保用户数据的安全.
定位异常 例如特定的数据(比如注册)在某一段时间内数据突然无缘由发生持续性异常,说明该功能可能存在异常,需要及时做排查.
其他作用 例如当某一个较早机型占比降低到某一个阀值时,就可以在下一个版本中去掉对该设备的支持.
数据进入数仓之前我们就需要设计好数仓表,埋点的表的数据有几个特点,所以我们在设计的时候需要考虑到
- 数据量非常大,可能是所有数据集成渠道里面,流量最大的了
- 数据不存在更新,这是埋点表的数据特点
面对这两个特点,我们需要做一些设计,当然还有一些其他设计方面的点需要注意一下,首先因为量大,而且我们往往关注的是昨天的数据,所以我们的表肯定是分区表,其次因为我们使用的特点,例如关注的是页面浏览或者是按钮点击,所以我们在时间分区的基础上按照事件进行分区。这样我们可以在数据查询的时候过滤掉大量的数据从而提高查询的性能。
其次就是埋点表的作为数据报表的数据来源的时候,可能会大概率遇到计算延迟,或者是一些其他问题,所以在宽表的设计或者是报表展示中,请尽量地将集成进行后延,从而更好的保证稳定性和可用性。关于这一点,请参考数仓建模—宽表的设计
这里是我们公司小程序端的埋点表

下面是web 端的埋点表

埋点:在期望的点位,埋设一个记录的标记。这个点位,一般多是指用户与产品进行一次次交互的接触点,从而可以在用户和产品交互的时候,将用户的数据进行上报。
通过收集这些标记点的数据,可以帮助产品运营及开发同学了解功能的整体使用、运行情况,并通过数据基础上做出下一步调整或优化的方向。遇事不拍脑袋,而是用数据说话,这是数据埋点最大的价值。
在AB测试的场景下,数据埋点为实验组的效果提供数据支持,其本质也是数据决策的基础。
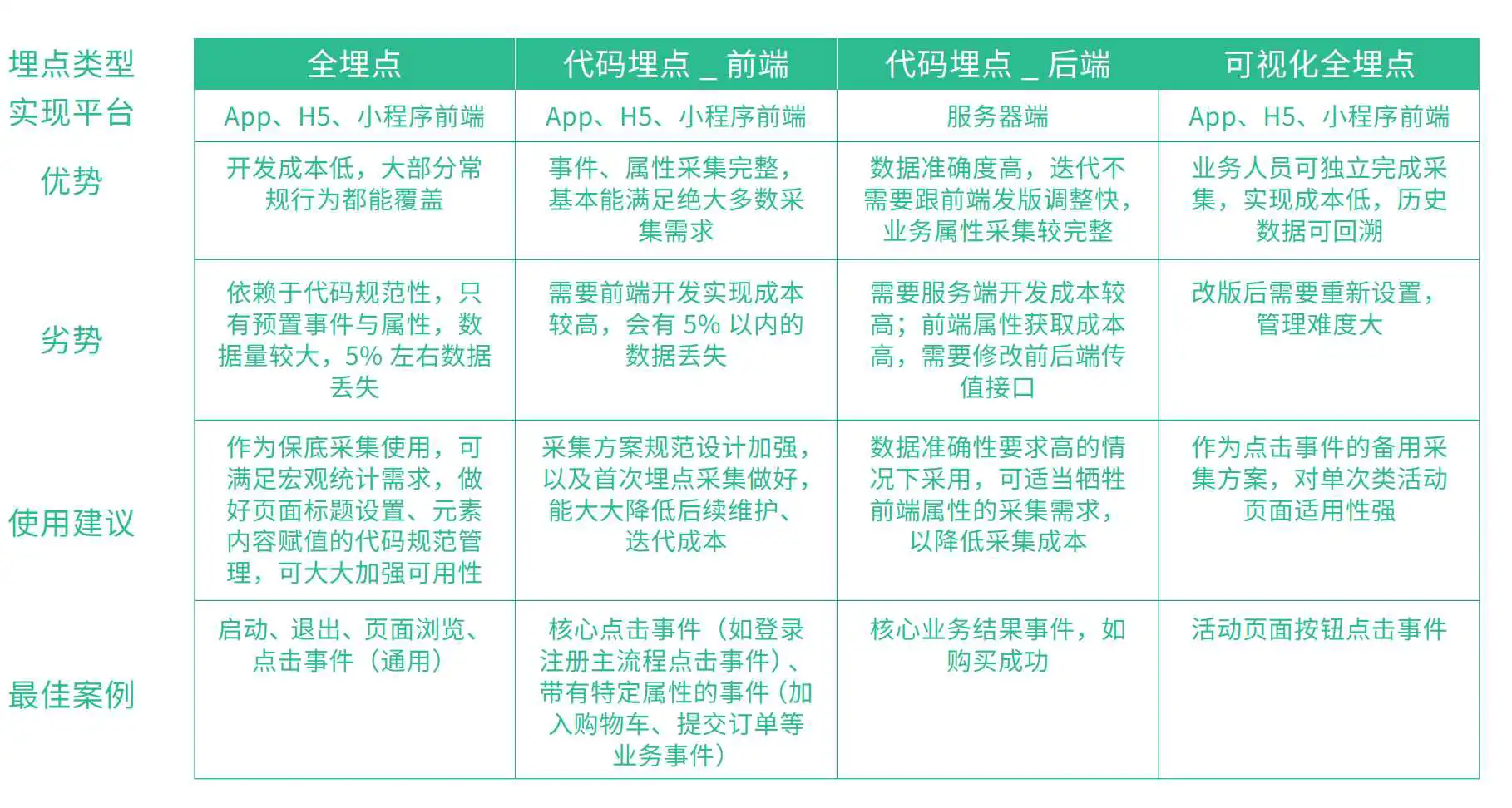
根据目前常见的数据埋点形式,可以将数据埋点分为全埋点、代码埋点(自定义埋点),当然我们也可以按照产品的类型划分为,APP埋点、web 埋点、小程序埋点
全埋点的逻辑,是指数据采集sdk无区别的对待所有事件的,将所有事件(页面的加载成功事件、控件的浏览和点击事件)全部获取后先存下来,到使用的时候,再根据具体的页面路径和控件名称,去捞取相应的数据。
基于此,可视化埋点是指,在全埋点部署成功、已经可以获得全量数据的基础上,以可视化的方式,然后进行数据选择。
这种方案的弊端之一是耗流量和存储空间,全埋点采集的数据一般会根据情况设定一个销毁时限,比如7天。即:全采集过来的数据,如果7天之内没有被使用,则会删除。而一旦对圈选数据做了圈选定义之后,则被定义的页面数据、控件数据,则会一直采集,且不会删除。
全埋点,其优势和特点是功能上线时,不需要开发做额外的埋点定义工作,用的时候再根据需求去获取对应的数据,因此也叫无埋点。
全埋点的缺点:
- 耗用户流量、占存储空间;
- 一旦版本迭代,对页面的路径做修改,或者控件位置、文案有修改,原来的圈选数据可能就会出错,需要重新圈选,之前利用圈选指标设定的分析模型都要替换;
- 圈选指标无法区分细部参数,比如:商品详情页,无法通过圈选数据来区分是哪一个商品或哪一个类目;
- 对web的页面数据处理一直不好,尤其是涉及到APP的内嵌H5页时,非常痛苦。
因此,全埋点适用于业务多变、经常调整,且分析诉求比较轻量的场景。对于通用的功能,形态相对比较固定,且对数据分析颗粒度、下钻深度、聚合程度要求比较高,那就需要用到代码埋点
代码埋点也叫自定义埋点,从字面上即可理解:是针对想要的点位单独定义,并可以通过变量丰富埋点的信息,以支持上下游分析。
代码埋点分为前端埋点和后端埋点。
前端埋点,包括但不限于APP客户端、H5、微信小程序、PC网页,是指对具体的功能场景(如加载成功、浏览、点击等)进行明确的定义,由前端触发,采集上来的数据相比于全埋点,更准确、稳定,且通过变量字段,能够实现更细颗粒度数据的拆分、聚合和下钻。
后端埋点,指触发了服务端接口调用(如:接口回调成功触发)的事件埋点,如最典型的注册成功事件、付费成功事件。后端埋点对数据的准确度要求更高,同时也可以通过变量字段的扩展支持数据拆分、聚合和下钻。需要强调的是,后端事件一般采集的是已登录状态下的用户行为,如果想使用后端埋点事件作为流程分析的其中一环(如漏斗分析),则可能出现未登录的用户会漏掉的情况。
综合以上,几种埋点类型的比较
对于一个埋点方案来说,数据上报有两个点需要着重考虑:
- 对跨域做特殊处理。
- 页面销毁后,如何还能够将未上传的埋点数据成功上报
参考 https://juejin.cn/post/
有下面几点优势:
- 没有跨域问题,一般这种上报数据,代码要写通用的,img 天然支持跨域;(排除 ajax)
- 不会阻塞页面加载,影响用户的体验,只要 new Image 对象就好了, 通过它的onerror和onload事件来检测发送状态;(排 除 JS/CSS 文件资源方式上报)
- 在所有图片中,简单、安全、相比PNG/JPG体积最小;(比较 PNG/JPG)(tip:最小的BMP文件需要74个字节,PNG需要67个字节,而合法的GIF,只需要43个字
这种使用方式也存在缺陷。首先对于src 中的URL内容是有大小限制的,太大的数据量不适用。详细看这里。其次,在页面卸载的时候,若存在数据未发送的情况,会先将对应的数据发送完,再执行页面卸载。这种情况下,会在体验上给使用者带来不方便。
GET把参数包含在URL中,也就是说我们的上报的数据是在一个url 参数中或者是几个参数中,例如 ?data=XXXX 这里的data 就是我们上报的数据
GET 请求 最大的特点就是简单,但是同时也带来了很多其他的问题,首先是安全问题因为GET 请求参数被暴露在IURL 中,GET请求只能进行url编码,而POST支持多种编码方式,其次GET请求在URL中传送的参数是有长度限制的,也就是如果你上报的数据内容比较多,可能会被截断。
POST 请求 相比GET 请求首先就是更加安全,其次是支持多种编码,而且所能发送的数据量也更大,看起来是个不错的选择,但是还是不如图片请求好
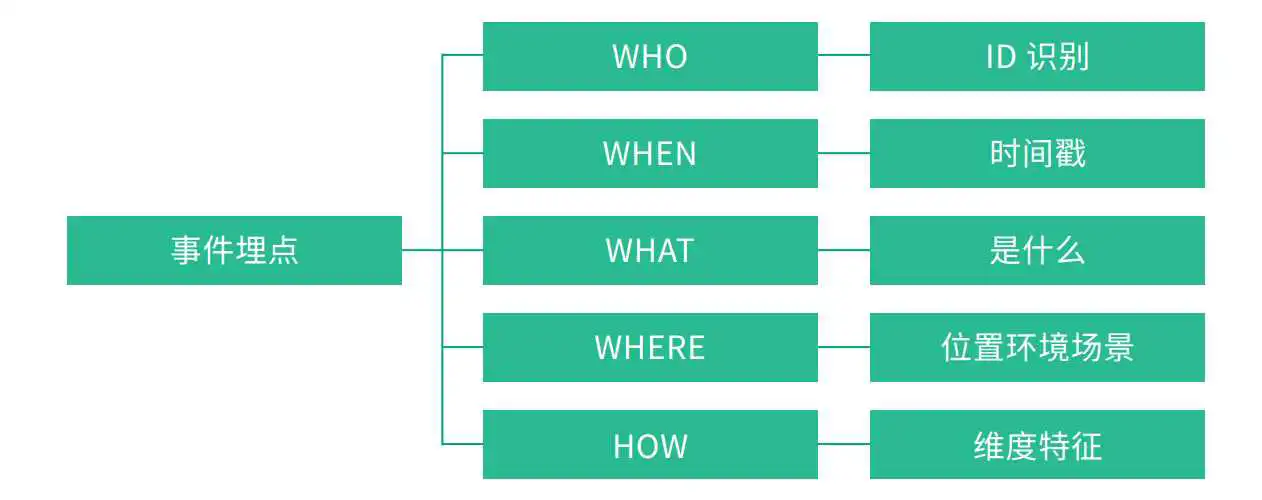
整个埋点的事件我们可以使用4W1H 进行表示
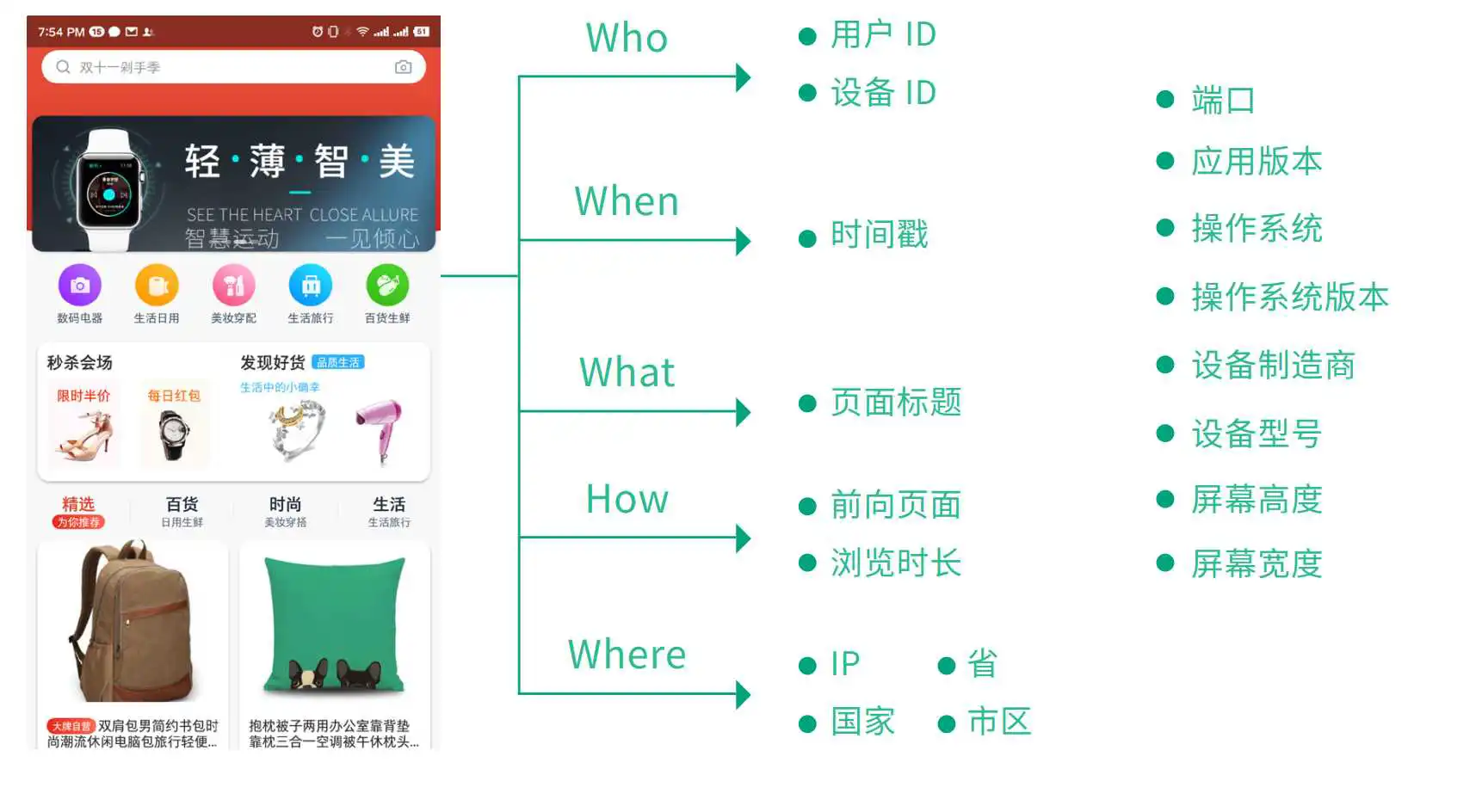
下面是APP 端的一个例子
我们使用“事件模型( Event 模型)”来描述用户的各种行为,事件模型包括事件( Event )和用户( User )两个核心实体。整个埋点的属性,我们可以分为两大类,第一类是事件属性,第二类是用户属性。
为什么这两个实体结合在一起就可以清晰地描述清楚用户行为?实际上,我们在描述用户行为时,往往只需要描述清楚几个要点,即可将整个行为描述清楚,要点包括:是谁、什么时间、什么地点、以什么方式、干了什么。而事件( Event )和用户( User )这两个实体结合在一起就可以达到这一目的。下面分别介绍一下这两个实体。
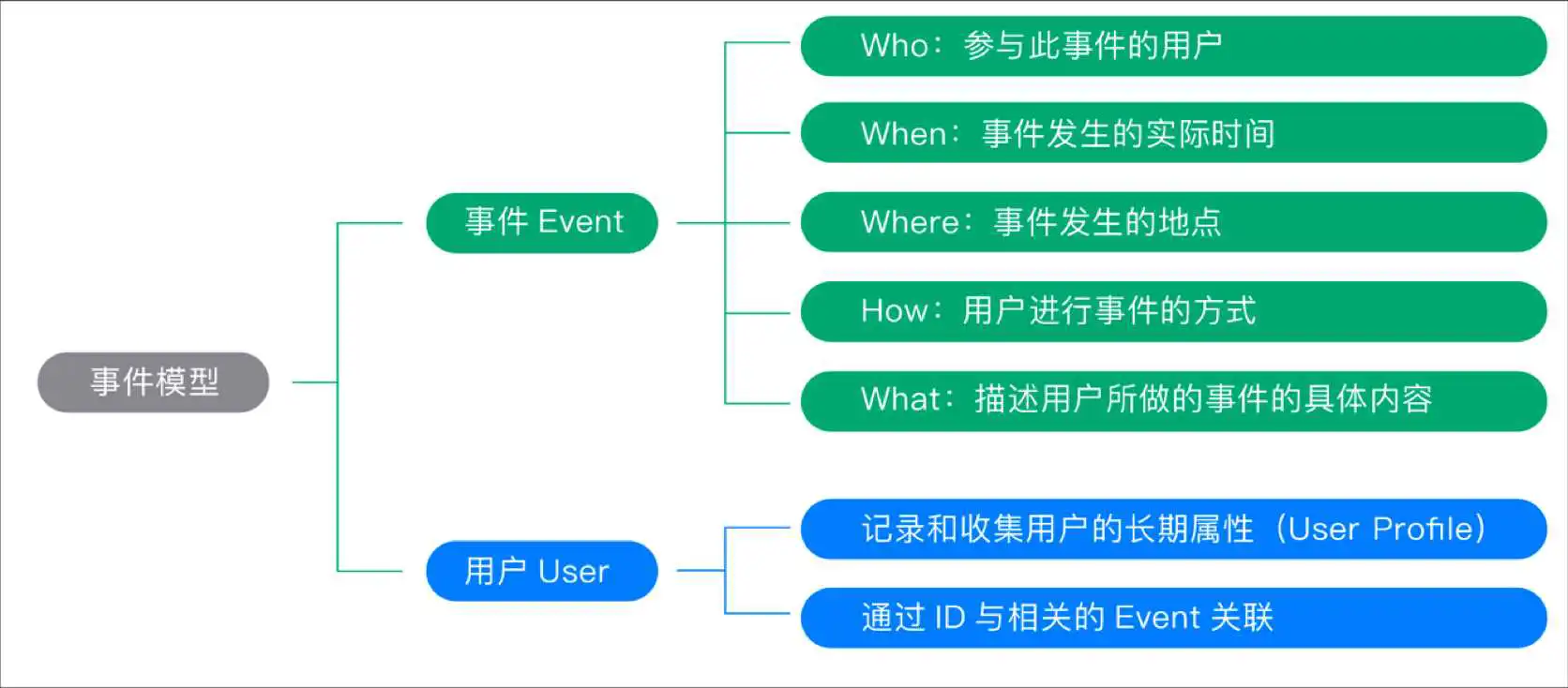
一个完整的事件( Event ),包含如下的几个关键因素:
Who:即参与这个事件的用户是谁。
When:即这个事件发生的实际时间。
Where:即事件发生的地点。
How:即用户从事这个事件的方式。这个概念就比较广了,包括用户使用的设备、使用的浏览器、使用的 App 版本、操作系统版本、进入的渠道、跳转过来时的 referer 等。
What:以字段的方式记录用户所做的事件的具体内容。不同的事件需要记录的信息不同,下面给出一些典型的例子:
对于一个“购买”类型的事件,则可能需要记录的字段有:商品名称、商品类型、购买数量、购买金额、 付款方式等;
对于一个“搜索”类型的事件,则可能需要记录的字段有:搜索关键词、搜索类型等;
对于一个“点击”类型的事件,则可能需要记录的字段有:点击 URL、点击 title、点击位置等;
对于一个“用户注册”类型的事件,则可能需要记录的字段有:注册渠道、注册邀请码等;
对于一个“用户投诉”类型的事件,则可能需要记录的字段有:投诉内容、投诉对象、投诉渠道、投诉方式等;
对于一个“申请退货”类型的事件,则可能需要记录的字段有:退货金额、退货原因、退货方式等。
描述事件的任意一个字段,都是一个事件属性。应该采集哪些事件,以及每个事件采集哪些事件属性,完全取决于产品形态以及分析需求。
下面分别是 H5、APP 、小程序 端埋点的一个设计
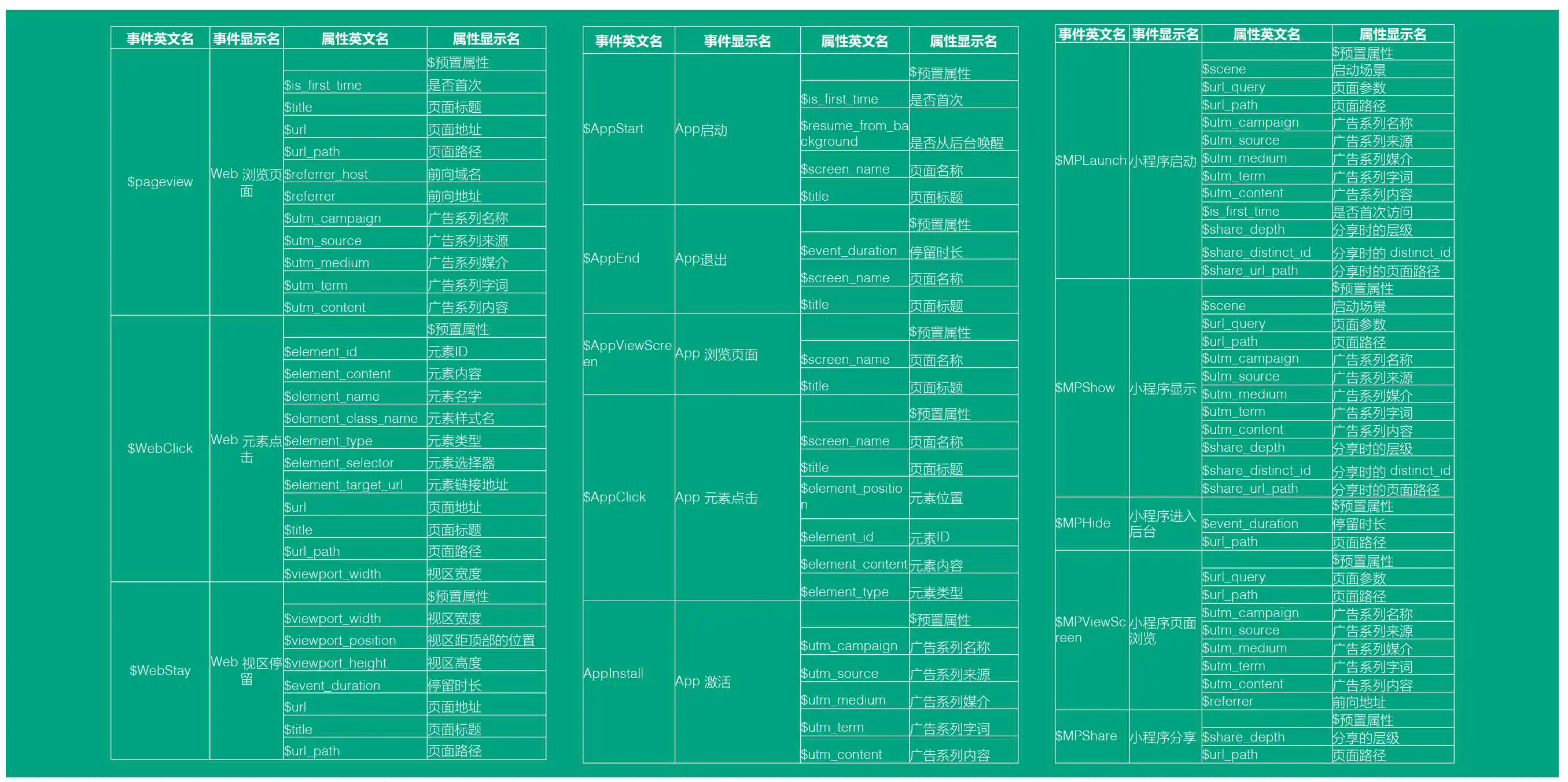
基本规范
我们在设计的时候要注意一些基本的规范,例如我们属性的命名,这样才能可以更好的维护
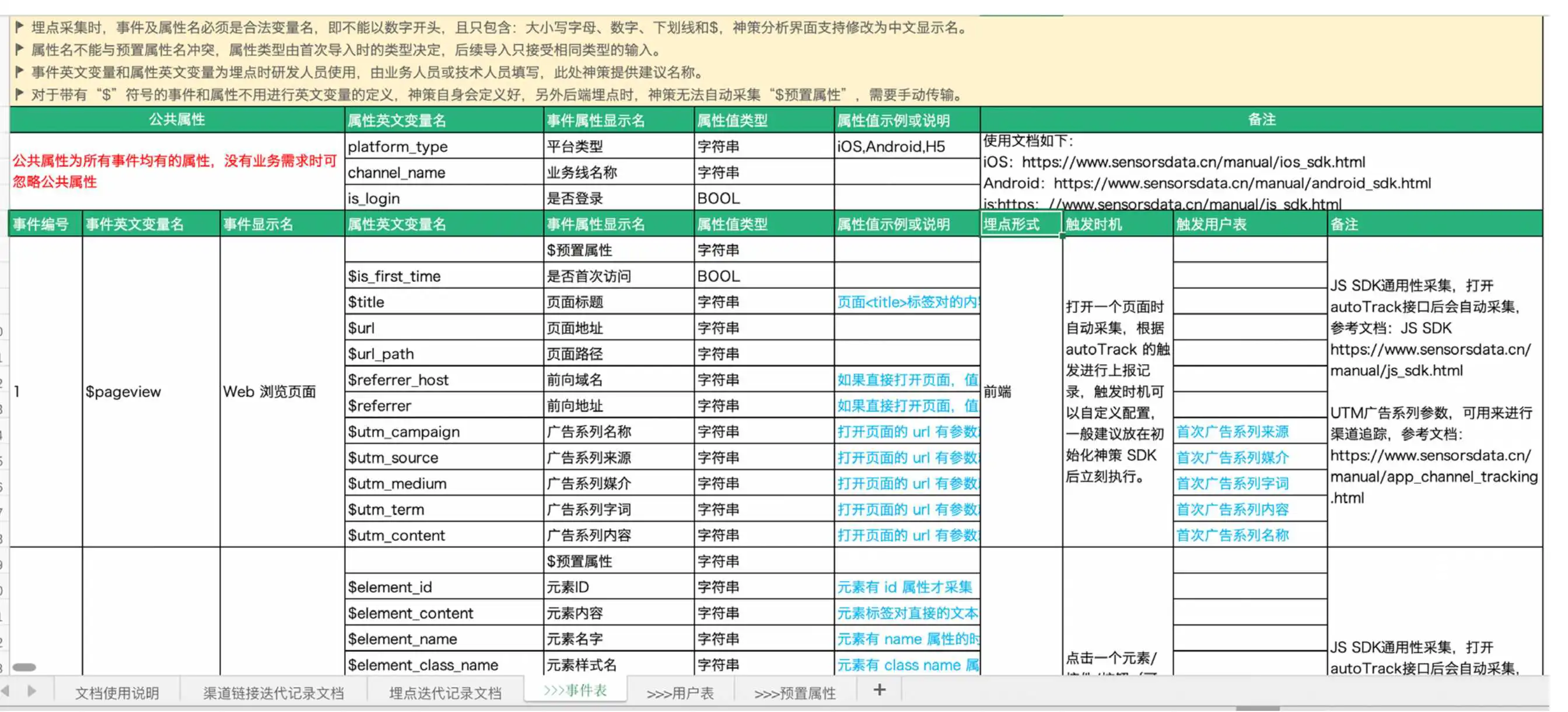
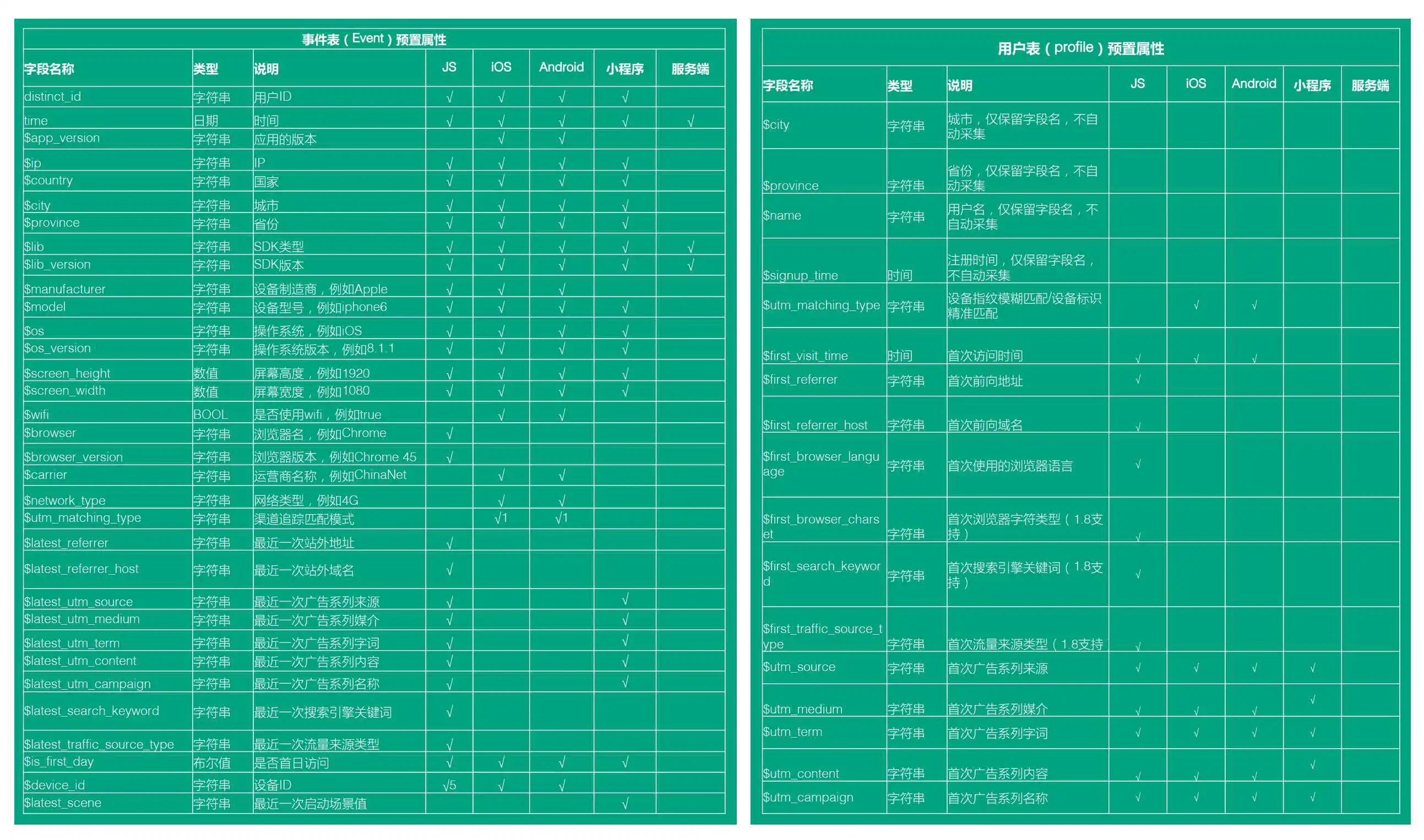
预置属性
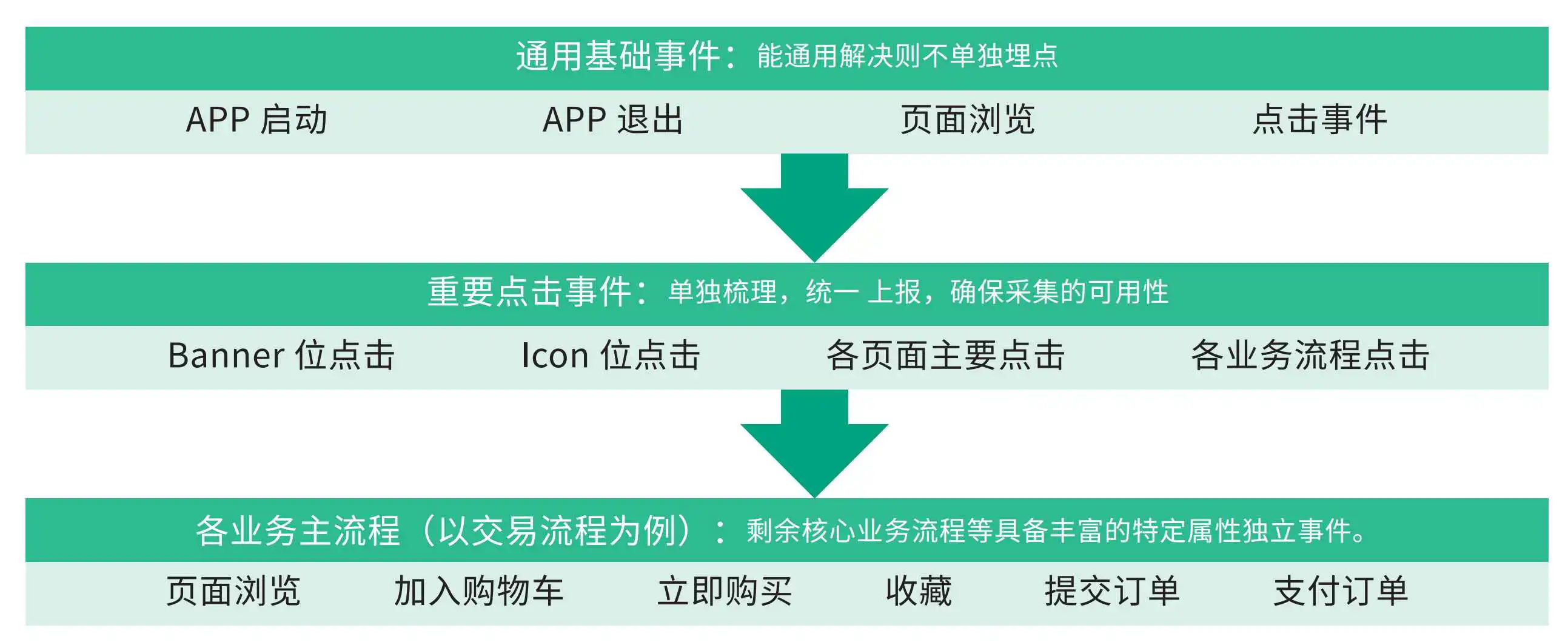
整个埋点的设计我们应该遵循一下几个原则,从而可以更好的维护和管理整个埋点系统
通用基础事件
埋点时间能通用则不单独埋点,不是说单独埋点越多越好,我们应该尽可能的从上层设计比较通用的事件,这样方便复用。
重要事件
重要事件单独处理,统一上报,保证采集的可用性
业务主流程
对于主要的业务流程,我们可以设计独立的事件,从而方便更好的分析
其实所有的事件都是自定义事件,但是我们为什么还是要区分自定义事件呢?
这是因为我们在一开始定义可很多通用的事件,所以我们的自定义事件是相对我们的通用事件而言的,但是我们怎么去定义一个自定义事件吗,其实还要考虑到通用的属性,因为这样我们可以复用通用事件的一些属性的定义,而不是完全重新设计一套东西。
举例来说,一个电商产品可能包含如下事件:用户注册、浏览商品、添加购物车、支付订单等,这里我们就那用户注册事件来说吧,其实它应该是一个点击事件,但是和点击事件不一样的是,我们需要添加一些新的属性,所以我们可以在点击事件的基础上去添加属性,有点类似编程语言的继承,但是有的时候我们也可以去组合多个事件的属性,其实这个是不常见的。
确定一个场景,或者一个目标。比如,我们发现很多用户访问了注册页面,但是最终完成注册的很少。那么我们的目标就是提高注册转化率,了解为什么用户没有完成注册,是哪一个步骤挡住用户了。
思考哪些数据我们需要了解,以帮助我们实现这个目标。比如对于之前的目标,我们需要拆解从进入注册页面到完成注册的每一个步骤的数据,每一次输入的数据,同时,还有完成或者未完成这些步骤的人的特征数据。
我们需要确定谁来负责收集数据,一般是工程师,有些企业有专门的数据工
程师,负责埋点采集数据。
发现问题后,怎么给出解决方案。比如,是否需要在设计上改进,或者是否是工程上的 bug。
谁负责实现解决方案,需要确定方案的实施责任人。
进行下一轮数据采集和分析,回到第一步继续迭代。
知易行难。这整个流程里,第 2 步到第 4 步是关键。目前传统的服务商
比如 Google Analytics、百度统计、友盟所采用的方式称作 Capture 模
式。通过在客户端埋下确定的点,采集相关数据到云端,最终在云端做呈
现。
首先是基于一定的需求出发,然后产品/业务/分析师 对需求进行评审,主要就是需求同步,信息对齐,接下来就是埋点的开发与测试,埋点上线之后,数据同学开始进行数据需求开发在此过程中对埋点进行验收,最后对数据需求进行交付
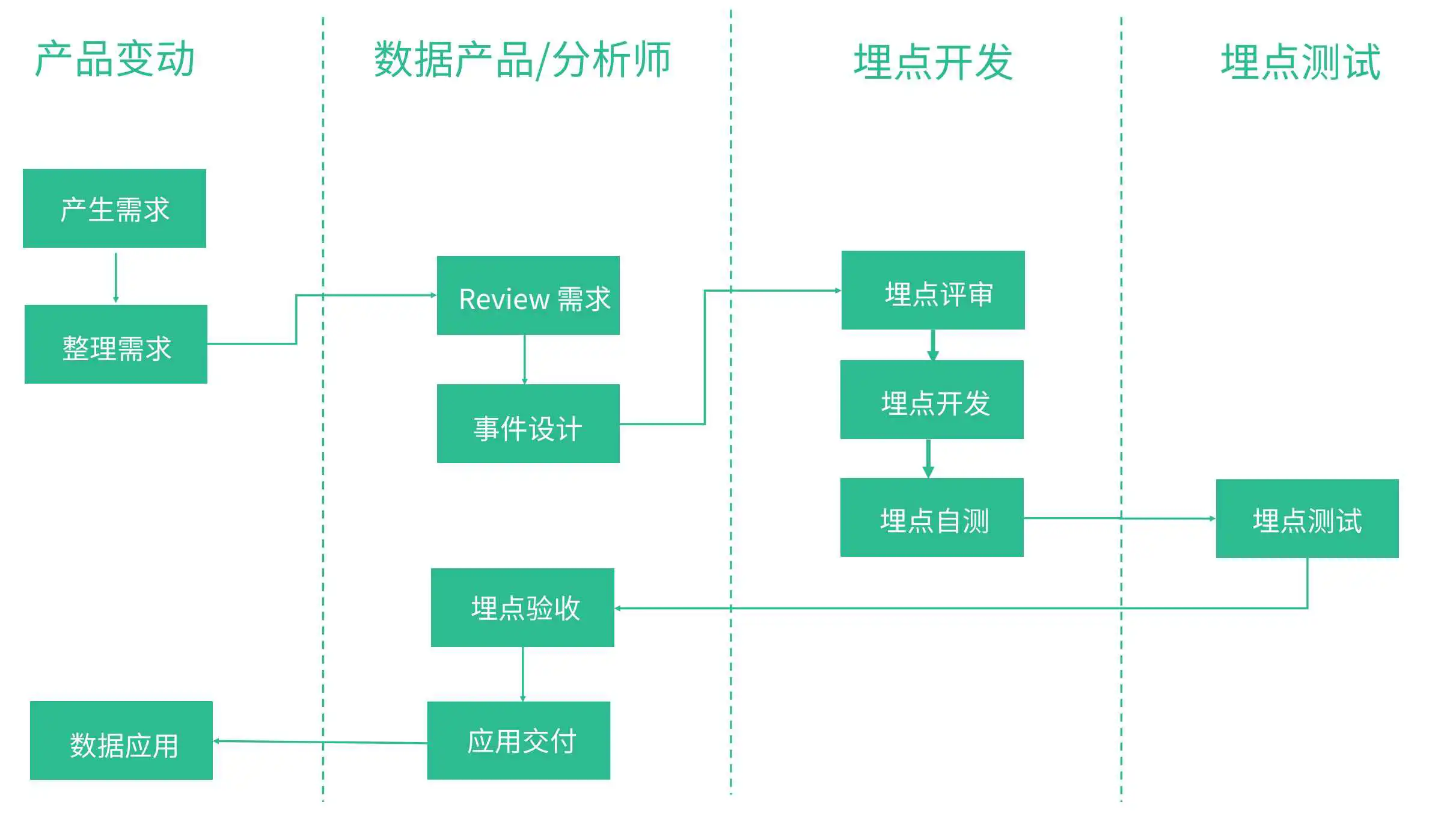
这个过程,需要专门投入专人去做这个事情,企业需要定制顶层的业务规范,上面的流程中有一个环节是没有的,那就是埋点的下线。
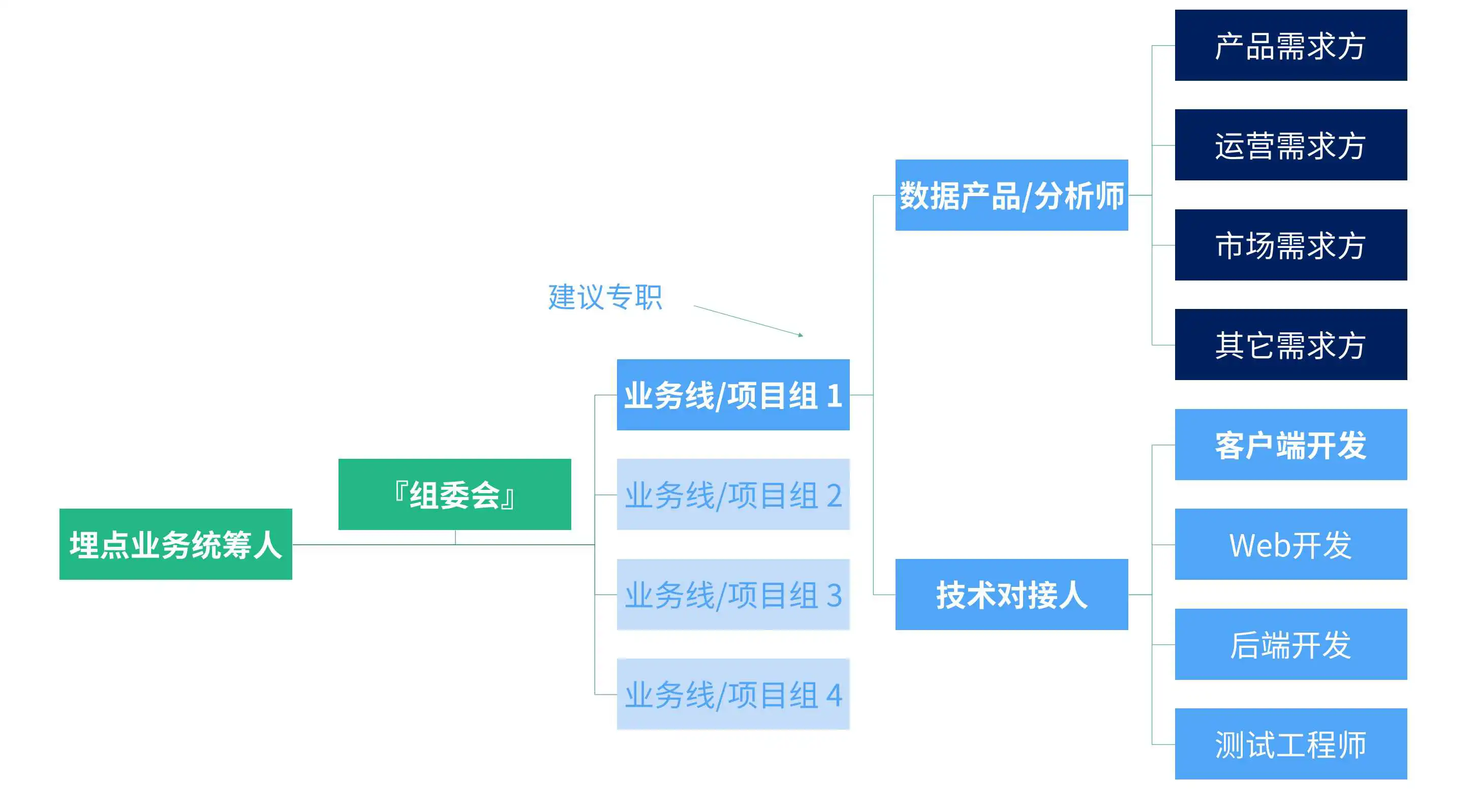
数据产品和数据分析师不仅要考虑到业务需求和数据分析的工作,还要站在业务线数据体系和数据应用负责人的角度,对埋点实施、管理、迭代、文档、交付、支持进行掌控和维护
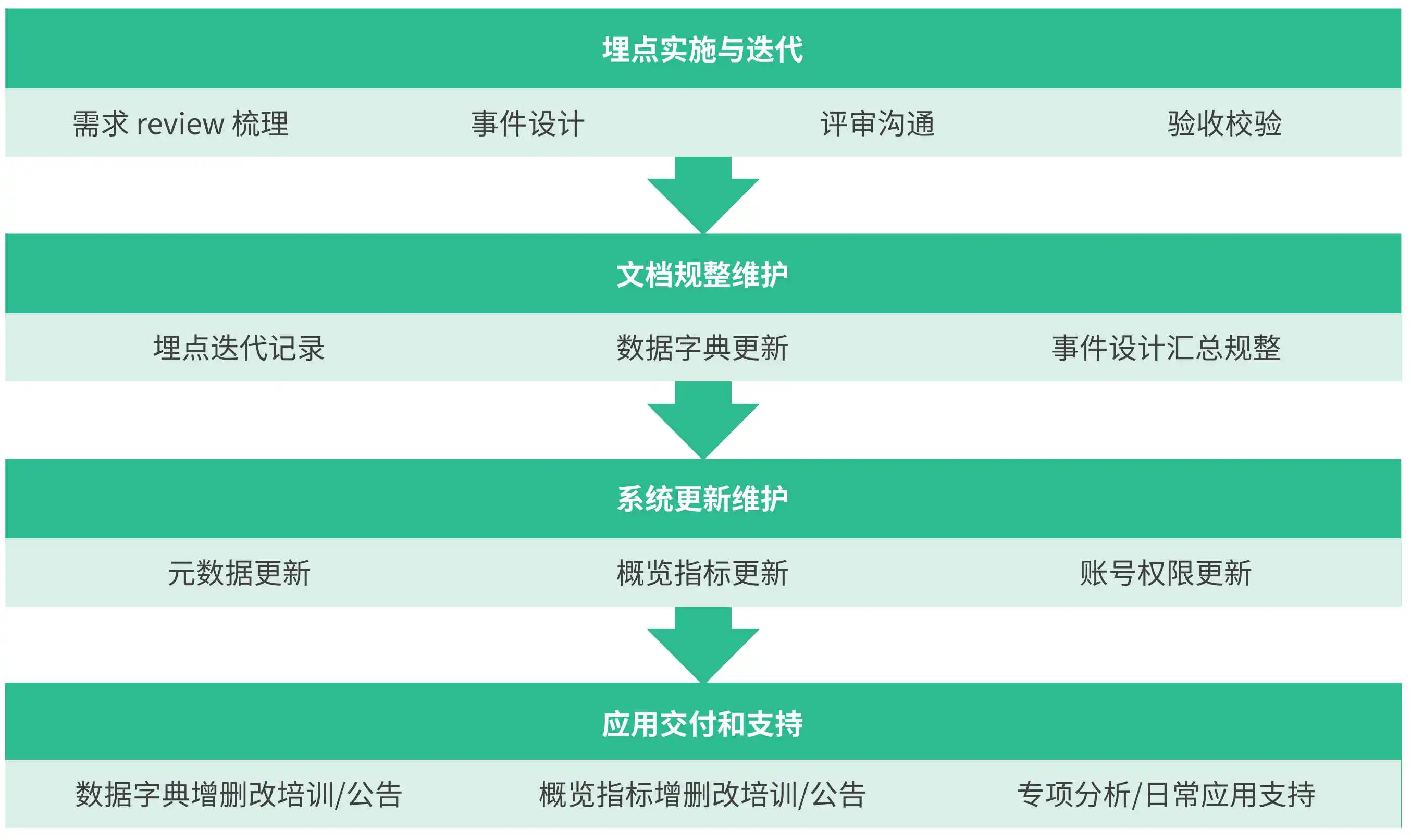
其实很多公司针对埋点会维护单独的一个系统,这个系统主要维护了公司的全部埋点,其实你可以将其理解为和jira 类似的一套系统。下面我们看系统的核心
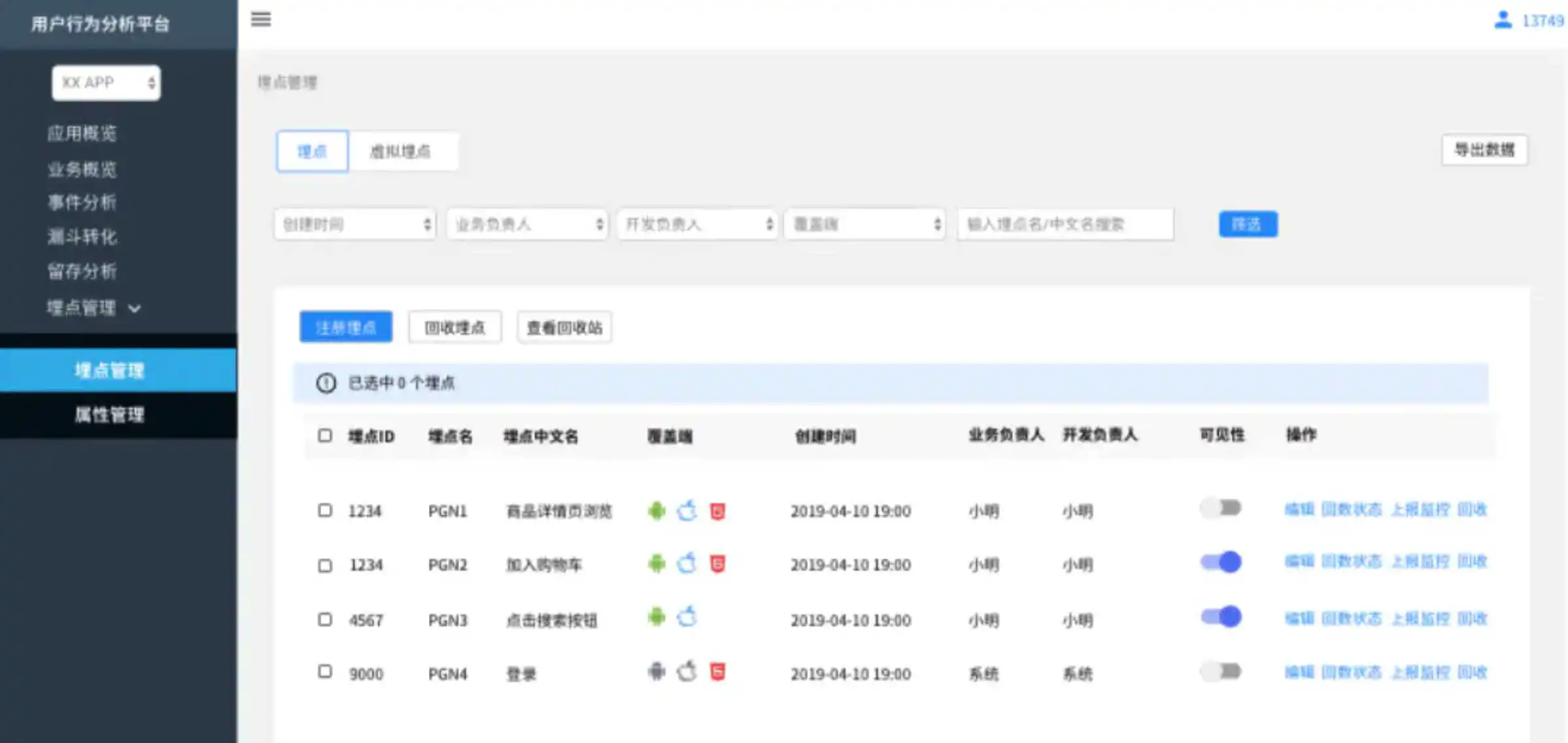
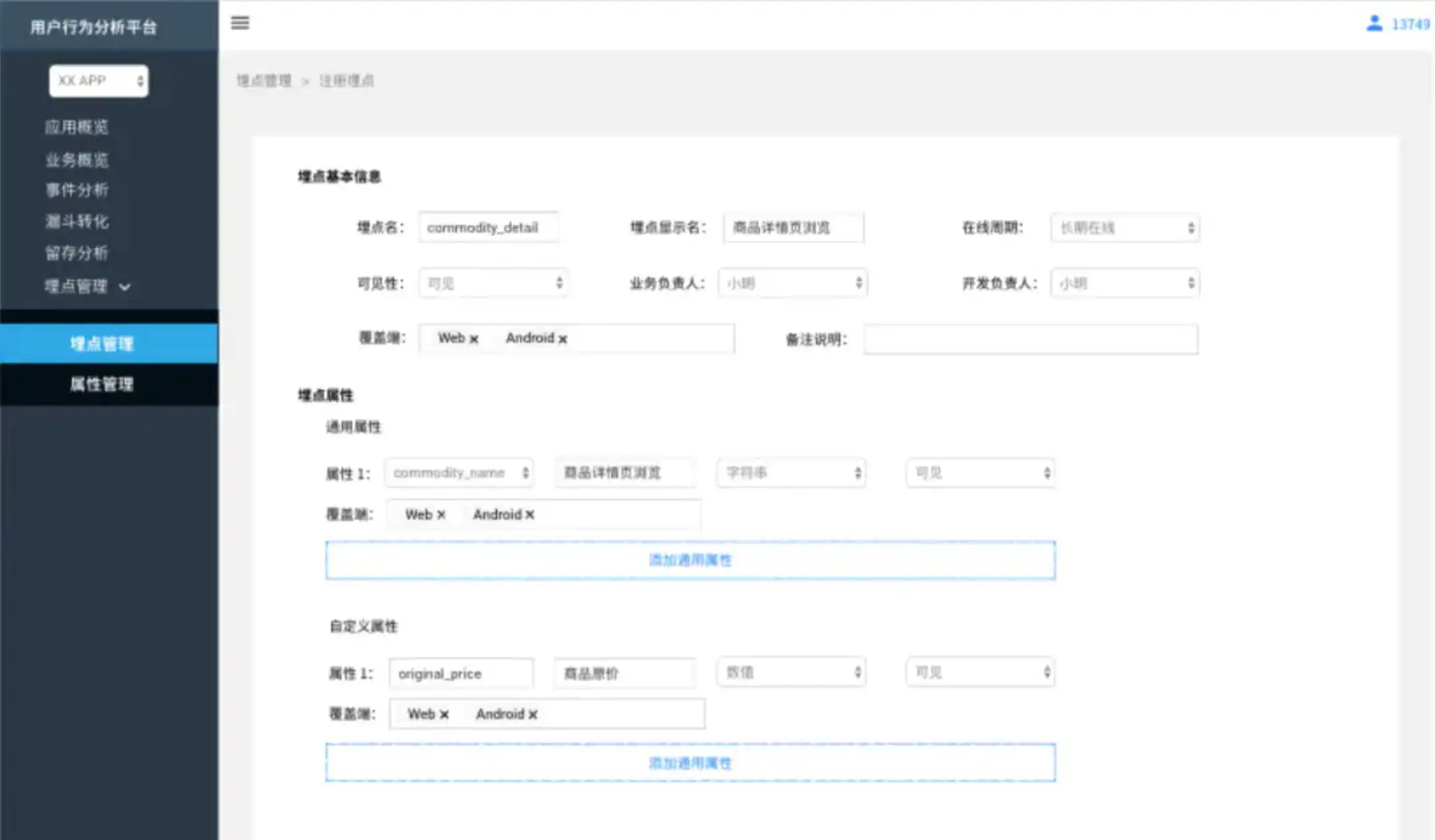
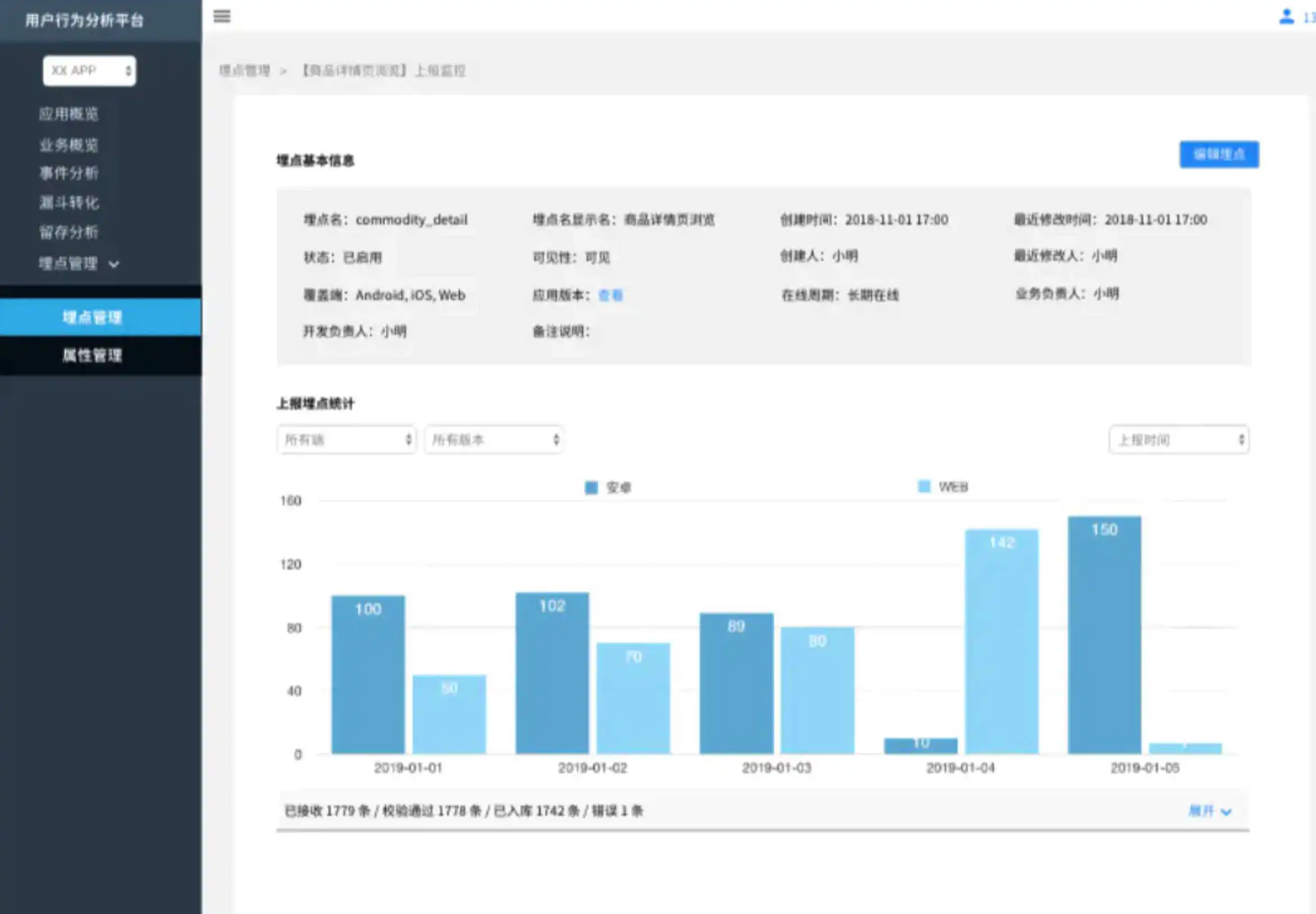
主要提供关于埋点的基本信息和统计信息
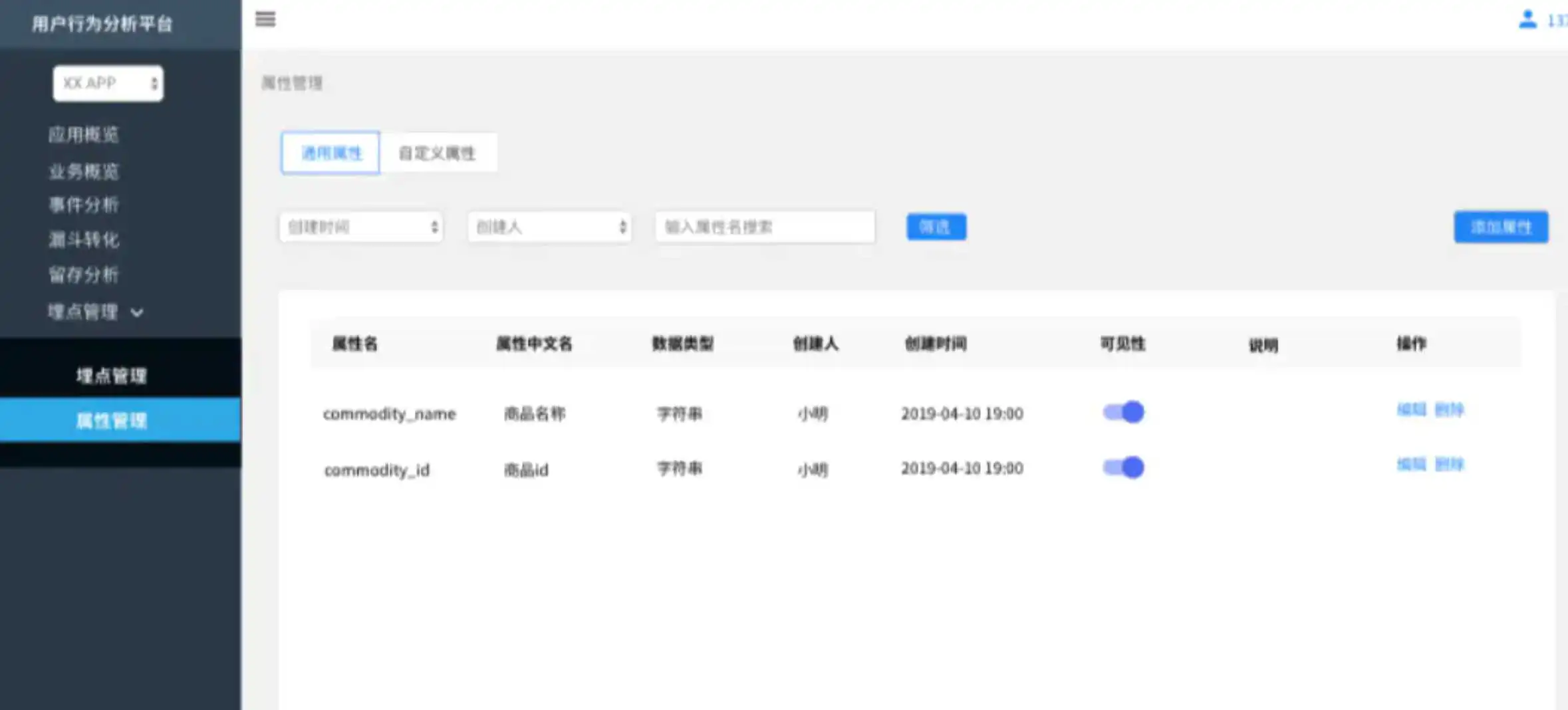
在埋点元数据中维护产品/业务层面的通用属性,由数据团队统一维护,所有可见的属性,都可以在注册/编辑埋点是添加属性时搜索到。自定义属性相对于通用属性,是某个事件下特有的属性,由业务方根据埋点方案维护
| 字段名称 | 备注 |
|---|
主要的就是上面这些,我们需要做的就是将这些进行前端展示和前端录入。
首先我们还是先看一下一个架构图,从而理解一下数据流转,下面就是数据流转的一个大致方向

最后面的maxcompute 是我们的计算引擎,你可以将其当作是hive/spark ,具体是啥不重要,我们的数据通过前端(APP/web)前端上报,但是我们需要一个后端服务用来接收数据,然后后端获取到数据之后进入消息队列,最后我们再通过数据同步工具/数据消工具 把数据同步到大数据平台,从而开始数据计算和建模。
这里有一个问题就是我们上报上来的数据可能是加密的,或者是我们的消息队列是支持schema的(kafka 不支持),这种情况下我们的数据要不要解析呢?直接说结论吧,最好不要解析,将解析的工作放在计算引擎中做,原因很多,下面陈述两点:
- 后端服务在这里扮演的角色其实和消息队列差不多,如果这个过程有逻辑越多,耦合就越高,可扩展性就差,例如前端上报的数据格式变了,或者是有其他的一些升级,这个时候后端也要做对应的操作,然后重新发布。
- 后端服务如果在这里有大量的逻辑的话,对性能也不好,因为埋点的数据量很大,如果这里出现瓶颈的话,就会出现服务不稳定,从而导致数据丢失
其实我看到有的人可能将IP 解析放在这里做,其实这也是不合理的,因为做IP 解析之前你需要先做数据解密、JSON 解析,然后数据推送到消息队列之前还要做数据加密,可以看出这里的加解密想当于白做了。
但是凡事也有例外,你也可以在后端这里做一些数据过滤,这样可以减少后面数据处理的压力,毕竟相比CPU ,网络才是最慢的。
这里我们主要关注前端—>后端—> 消息队列的这个环节的消息丢失,我们认为消息只要成功投递就不会发生消息丢失,关于这一点很多消息队列都可以保证,我们不做过多讨论,可以参考: https://blog.csdn.net/king14bhhb/article/details/
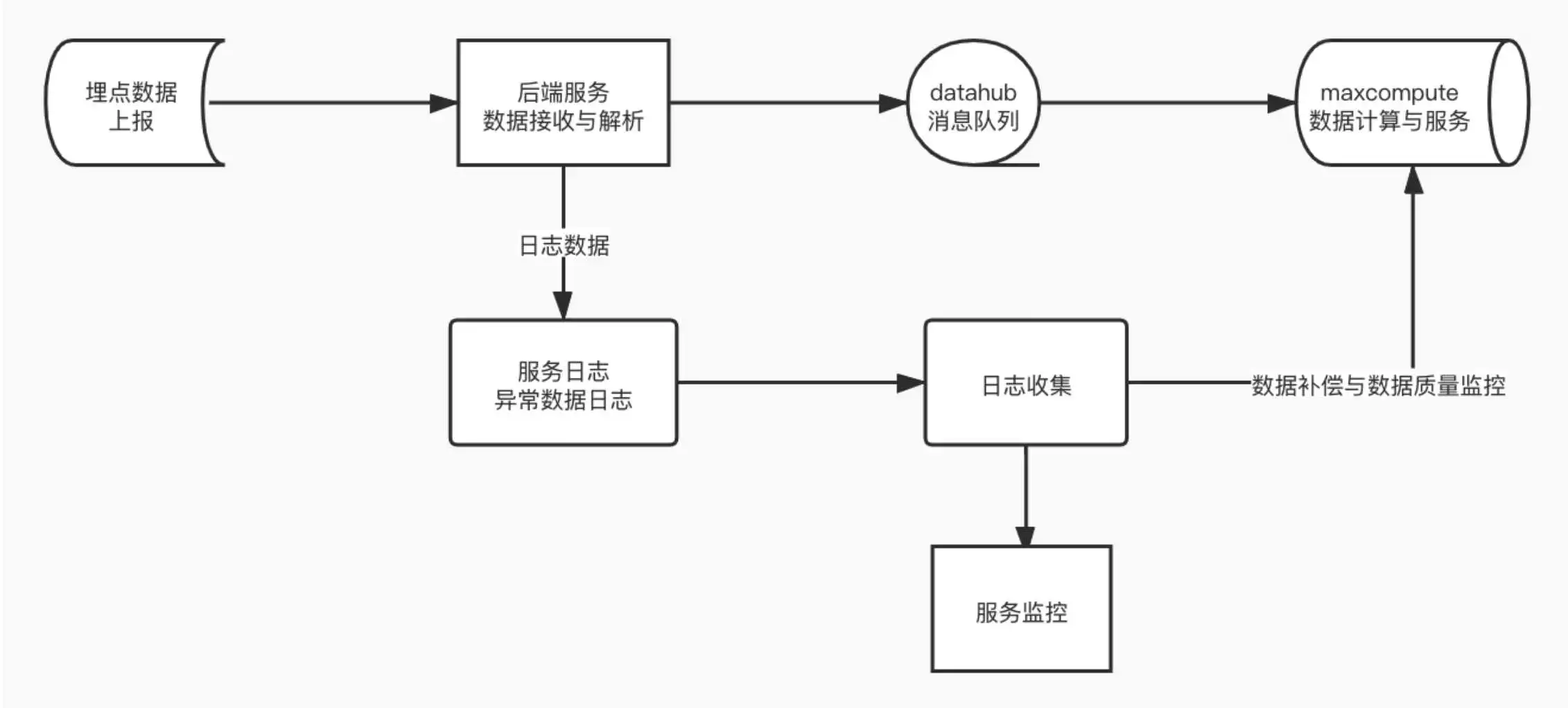
所以我们的消息丢失主要在后端这一块,当然这里丢失的原因,我们可以分为两类
- 后端服务不稳定,前端请求得不到影响,数据丢失,我们可以认为是前端数据丢失
- 消息队列服务不稳定,后端消息不能成功投递,导致消息丢失,我们可以认为是后端数据丢失
可以看出来,这里后端是关键,所以我们采取的措施是日志补偿的方式,也就是对于投递失败的消息,我们可以将其追加到特定的日志文件,然后再将抽取到大数据计算平台,这里有一个问题就是最好监控,如果有大量的消息投递失败,我们一定要及时修复,防止日志文件过大。
对于后端服务的不稳定导致前端数据投递失败,我们需要做的就是做好监控和高可用,以及自动扩容,因为很多时候是因为流量急剧增加导致后端服务压力太大,从而导致不稳定。
- 埋点是数据平台很重要的一部分,如果只有业务数据没有埋点数据,那么用户在我们平台上的一切行为对我们来说都是黑盒,所以我们想要做到精细化运营埋点是必须的。
- 由于埋点的数据从产生到使用链路很长,而且很复杂,这就需要我们做好设计和管理工作。
数据仓库系列文章
1. [数仓架构发展史](数仓架构发展史 - 等待下一个秋)
2. [数仓建模方法论](数据仓库建模方法论 - 等待下一个秋)
3. [数仓建模分层理论](https://www.ikeguang.com/?p=1559)
4. [数仓建模—宽表的设计](数仓建模-宽表的设计 - 等待下一个秋)
5. [数仓建模—指标体系](数仓建模-指标体系 - 等待下一个秋)
6. [一文搞懂ETL和ELT的区别](一文搞懂ETL和ELT的区别)
7. [数据湖知识点](数据湖是谁?那数据仓库又算什么? - 等待下一个秋)
8. [技术选型 | OLAP大数据技术哪家强?](技术选型 | OLAP大数据技术哪家强?)
9. [数仓相关面试题](https://mp.weixin..com/s/Yu3pWkcJBpH23628bThxGw)
10. [从 0 到 1 学习 Presto,这一篇就够了!](从 0 到 1 学习 Presto,这一篇就够了!)
11. [元数据管理在数据仓库的实践应用](元数据管理在数据仓库的实践应用)
12. [做中台2年多了,中台到底是什么呢?万字长文来聊一聊中台](做中台2年多了,中台到底是什么呢?万字长文来聊一聊中台)
13. [数据仓库之拉链表](数据仓库之拉链表 - 等待下一个秋)
14. [sqoop用法之mysql与hive数据导入导出](sqoop用法之mysql与hive数据导入导出 - 等待下一个秋)
今日分享 / 字节跳动埋点数据流建设与治理实践
文 / 刘石伟 字节跳动 埋点数据流技术负责人
学习PPT:https://pan.baidu.com/s/1Of1CyD0gguEJdpWTG4M7Lw
埋点数据是数据分析、推荐、运营的基础,低延时、稳定、高效的埋点数据流对提高用户体验有着非常重要的作用。而随着流量的增大,埋点的增多,在大流量场景下,埋点数据流的建设和治理也面临不同的挑战。本文将介绍字节跳动在埋点数据流业务场景遇到的需求和挑战,以及为了应对这些需求和挑战在建设和治理过程中的具体实践。
埋点数据流主要处理的数据是埋点,埋点也叫Event Tracking,是数据和业务之间的桥梁,也是数据分析、推荐、运营的基石。
用户在使用 App 、小程序、 Web 等各种线上应用时产生的行为数据主要通过埋点的形式进行采集上报,按不同的来源可以分为:
① 客户端埋点
② Web端埋点
③ 服务端埋点

埋点通过埋点收集服务接收到MQ,经过一系列的Flink实时ETL对埋点进行数据标准化、数据清洗、数据字段扩充、实时风控反作弊等处理,最终分发到不同的下游。下游主要包括推荐、广告、ABTest、行为分析系统、实时数仓、离线数仓等。因为埋点数据流处在整个数据处理链路的最上游,所以决定了“稳定性”是埋点数据流最为关注的一点。
字节跳动埋点数据流的规模比较大,体现在以下几个方面:
① 接入的业务数量很多,包括抖音、今日头条、西瓜视频、番茄小说在内的多个大大小小的App和服务,都接入了埋点数据流。
② 流量很大,当前字节跳动埋点数据流峰值流量超过1亿每秒,每天处理超过万亿量级埋点,PB级数据存储增量。
③ ETL任务规模体量较大,在多个机房部署了超过1000个Flink任务和超过1000个MQ Topic,使用了超过50万Core CPU资源,单个任务最大超过12万Core CPU,单个MQ Topic最大达到10000个partition。
在这么巨大的流量和任务规模下,埋点数据流主要处理的是哪些问题?我们来看几个具体的业务场景。
在推荐场景中,由于埋点种类多、流量巨大,而推荐只关注其中部分埋点,因此需要通过UserAction ETL对埋点流进行处理,对这个场景来说有两个需求点:
① 数据流的时效性
② ETL规则动态更新
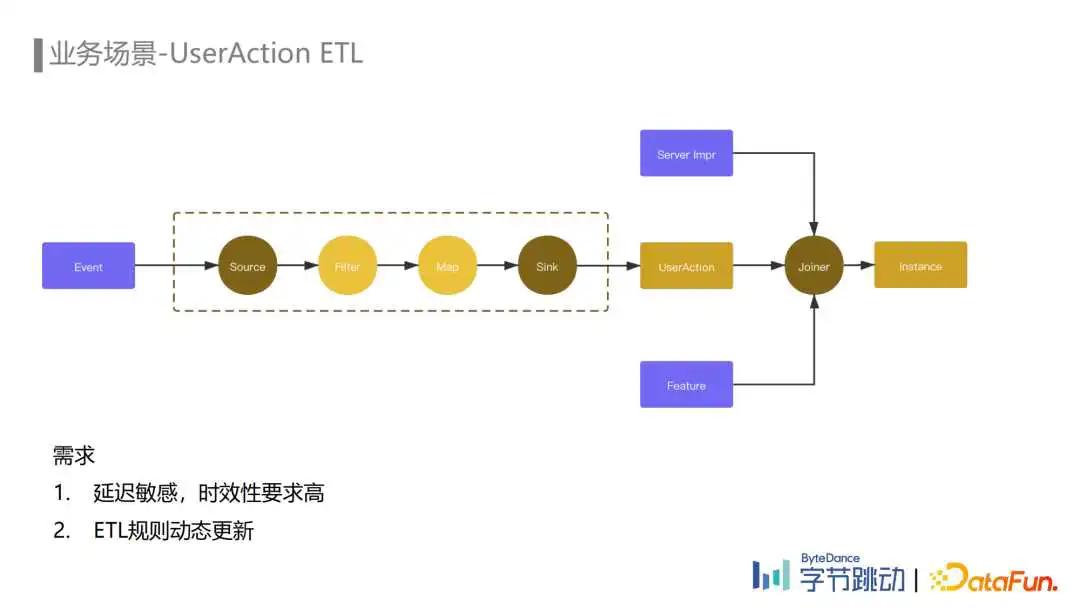
为了提升下流推荐系统的处理效率,我们在数据流配置ETL规则对推荐关注的埋点进行过滤,并对字段进行删减、映射、标准化等清洗处理,将埋点打上不同的动作类型标识,处理之后的埋点内部一般称为UserAction。UserAction与服务端展现、Feature等数据会在推荐Joiner任务的分钟级窗口中进行拼接处理,产出instance训练样本。
举个例子:一个客户端的文章点赞埋点,描述了一个用户在某一个时间点对某一篇文章进行了点赞操作,这个埋点经过埋点收集服务进入ETL链路,通过UserAction ETL处理后,实时地进入推荐Joiner任务中拼接生成样本,更新推荐模型,从而提升用户的使用体验。
如果产出UserAction数据的ETL链路出现比较大的延迟,就不能在拼接窗口内及时地完成训练样本的拼接,可能会导致用户体验下降。因此,对于推荐来说,数据流的时效性是比较强的需求。而推荐模型的迭代和产品埋点的变动都可能导致UserAction ETL规则的变动,如果我们把这个ETL规则硬编码在代码中,每次修改都需要升级代码并重启相关的Flink ETL任务,这样会影响数据流的稳定性和数据的时效性,因此这个场景的另一个需求是ETL规则的动态更新。
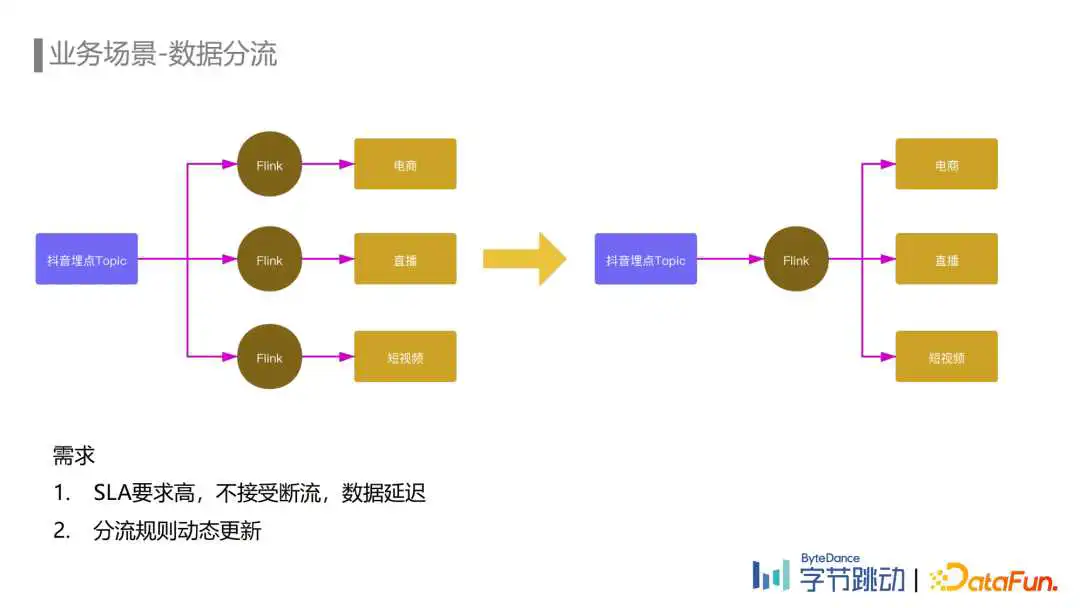
抖音的埋点Topic晚高峰超过一亿每秒,而下游电商、直播、短视频等不同业务关注的埋点都只是其中一部分。如果每个业务都分别使用一个Flink任务去消费抖音的全量埋点去过滤出自己关注的埋点,会消耗大量的计算资源,同时也会造成MQ集群带宽扇出非常严重,影响MQ集群的稳定性。
因此我们提供了数据分流服务。如何实现?我们使用一个Flink任务去消费上游埋点Topic,通过在任务中配置分流规则的方式,将各个业务关注的埋点分流到下游的小Topic中提供给各业务消费,减少不必要的资源开销,同时也降低了MQ集群出带宽。
分流需求大多对SLA有一定要求,断流和数据延迟可能会影响下流的推荐效果、广告收入以及数据报表更新等。另外随着业务的发展,实时数据需求日益增加,分流规则新增和修改变得非常频繁,如果每次规则变动都需要修改代码和重启任务会对下游造成较大影响,因此在数据分流这个场景,规则的动态更新也是比较强的需求。
另一个场景是容灾降级。数据流容灾首先考虑的是防止单个机房级别的故障导致埋点数据流完全不可用,因此埋点数据流需要支持多机房的容灾部署。其次当出现机房级别的故障时,需要将故障机房的流量快速调度到可用机房实现服务的容灾恢复,因此需要埋点数据流具备机房间快速切流的能力。
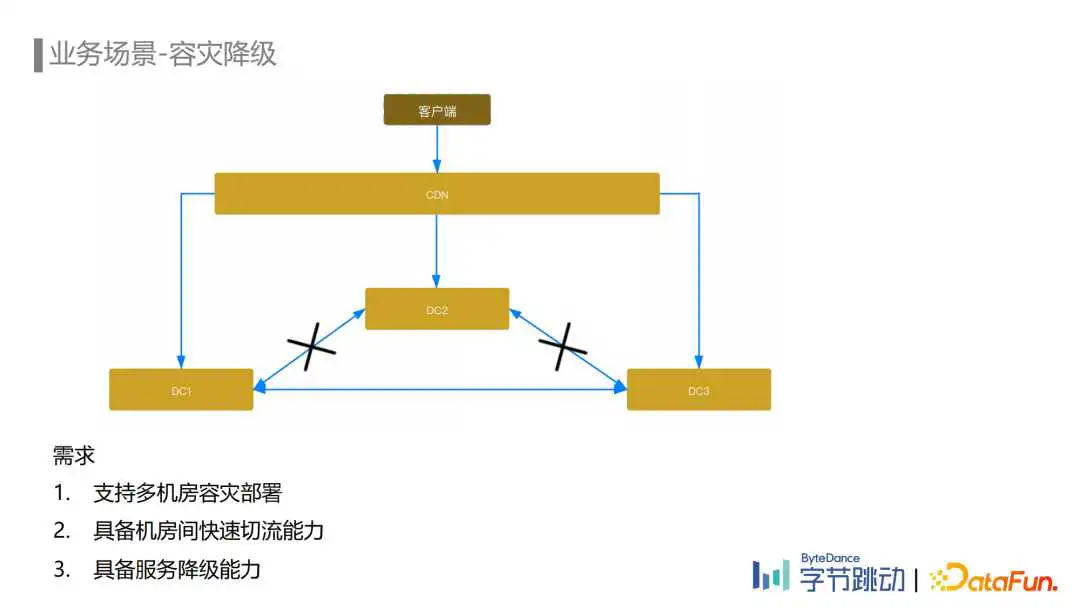
而数据流降级主要考虑的是埋点数据流容量不足以承载全部流量的场景,比如春晚活动、电商大促这类有较大突发流量的场景。为了保障链路的稳定性和可用性,需要服务具备主动或者被动的降级能力。
挑战主要是流量大和业务多导致的。流量大服务规模就大,不仅会导致成本治理的问题,还会带来单机故障多、性能瓶颈等因素引发的稳定性问题。而下游业务多、需求变化频繁,推荐、广告、实时数仓等下游业务对稳定性和实时性都有比较高的要求。
在流量大、业务多这样的背景下,如何保障埋点数据流稳定性的同时降低成本、提高效率,是埋点数据流稳定性治理和成本治理面对的挑战。

上文我们了解了埋点数据流的业务场景和面对的挑战,接下来会介绍埋点数据流在ETL链路建设和容灾与降级能力上的一些实践。
埋点数据流ETL链路发展到现在主要经历了三个阶段。
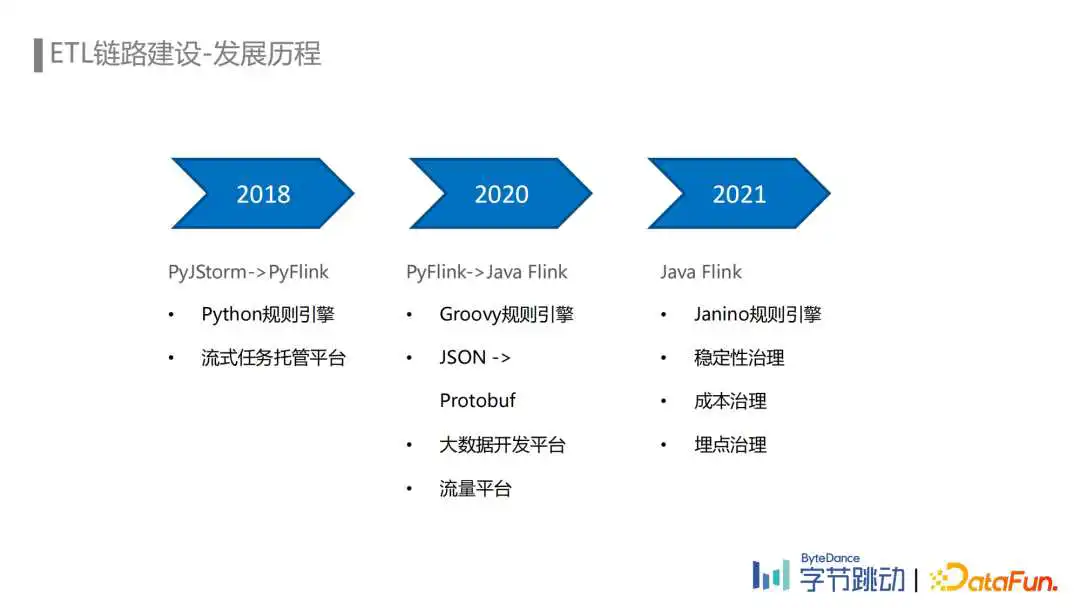
第一个阶段是2018年以前,业务需求快速迭代的早期阶段。那时我们主要使用PyJStorm与基于Python的规则引擎构建主要的流式处理链路。特点是比较灵活,可以快速支持业务的各种需求,伴随着埋点量的快速上涨,PyJStorm暴露出很多稳定性和运维上的问题,性能也不足以支撑业务增长。2018年内部开始大力推广Flink,并且针对大量旧任务使用PyJStorm的情况提供了PyJStorm到PyFlink的兼容适配,流式任务托管平台的建设一定程度上也解决了流式任务运维管理问题,数据流ETL链路也在2018年全面迁移到了PyFlink,进入到Flink流式计算的新时代。
第二个阶段是2018年到2020年,随着流量的进一步上涨,PyFlink和kafka的性能瓶颈以及当时使用的JSON数据格式带来的性能和数据质量问题纷纷显现出来。与此同时,下流业务对数据延迟、数据质量的敏感程度与日俱增。我们不仅对一些痛点进行了针对性优化,还花费一年多的时间将整个ETL链路从PyFlink切换到Java Flink,使用基于Groovy的规则引擎替换了基于Python的规则引擎,使用Protobuf替代了JSON,新链路相比旧链路性能提升了数倍。同时大数据开发平台和流量平台的建设提升了埋点数据流在任务开发、ETL规则管理、埋点管理、多机房容灾降级等多方面的能力。
第三个阶段是从2021年开始至今,进一步提升数据流ETL链路的性能和稳定性,在满足流量增长和需求增长的同时,降低资源成本和运维成本是这一阶段的主要目标。我们主要从三个方面进行了优化。
① 优化了引擎性能,随着流量和ETL规则的不断增加,我们基于Groovy的规则引擎使用的资源也在不断增加,所以基于Janino对规则引擎进行了重构,引擎的性能得到了十倍的提升。
② 基于流量平台建设了一套比较完善的埋点治理体系,通过埋点下线、埋点管控、埋点采样等手段降低埋点成本。
③ 将链路进行了分级,不同的等级的链路保障不同的SLA,在资源不足的情况下,优先保障高优链路。
接下来是我们2018至2020年之间埋点数据流ETL链路建设的一些具体实践。
在介绍业务场景时,提到我们一个主要的需求是ETL规则的动态更新,那么我们来看一下埋点数据流Flink ETL任务是如何基于规则引擎支持动态更新的,如何在不重启任务的情况下,实时地更新上下游的Schema信息、规则的处理逻辑以及修改路由拓扑。
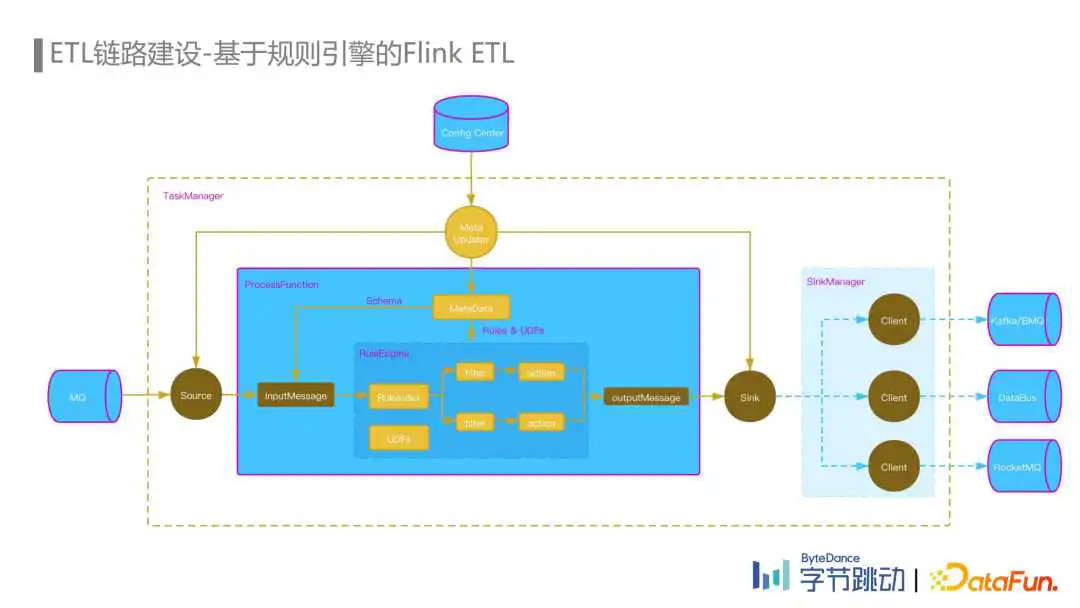
首先,我们在流量平台上配置了上下游数据集的拓扑关系、Schema和ETL规则,然后通过ConfigCenter将这些元数据发送给Flink ETL Job,每个Flink ETL Job的TaskManager都有一个Meta Updater更新线程,更新线程每分钟通过RPC请求从流量平台拉取并更新相关的元数据,Source operator从MQ Topic中消费到的数据传入ProcessFunction,根据MQ Topic对应的Schema信息反序列化为InputMessage,然后进入到规则引擎中,通过规则索引算法匹配出需要运行的规则,每条规则我们抽象为一个Filter模块和一个Action模块,Fliter和Action都支持UDF,Filter筛选命中后,会通过Action模块对数据进行字段的映射和清洗,然后输出到OutputMessage中,每条规则也指定了对应的下游数据集,路由信息也会一并写出。
当OutputMessage输出到Slink后,Slink根据其中的路由信息将数据发送到SlinkManager管理的不同的Client中,然后由对应的Client发送到下游的MQ中。
规则引擎为埋点数据流ETL链路提供了动态更新规则的能力,而埋点数据流Flink ETL Job使用的规则引擎也经历了从Python到Groovy再到Janino的迭代。
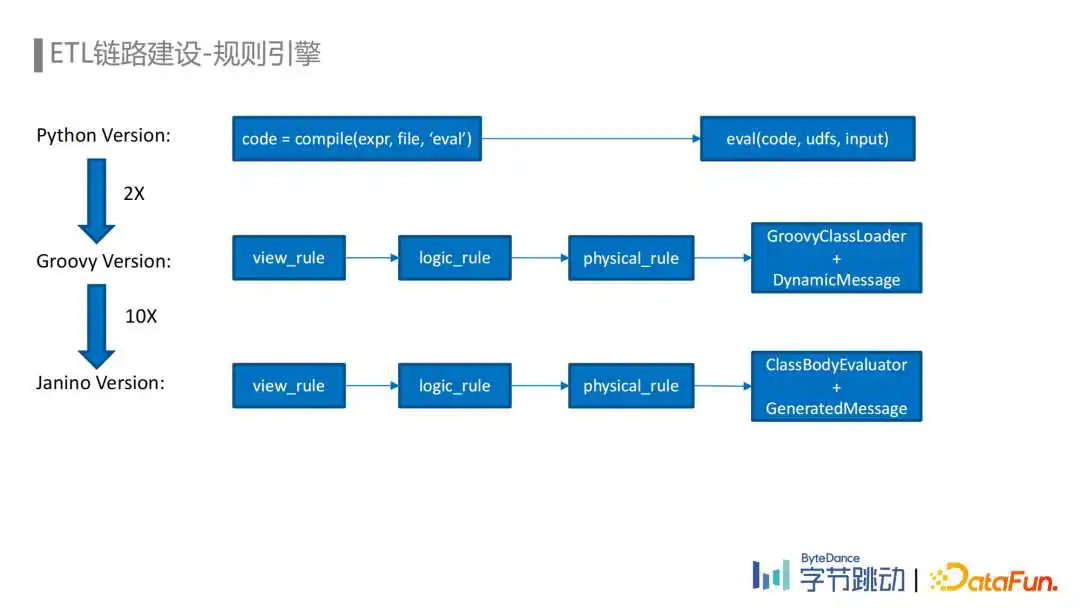
由于Python脚本语言本身的灵活性,基于Python实现动态加载规则比较简单。通过Compile函数可以将一段代码片段编译成字节代码,再通过eval函数进行调用就可以实现。但Python规则引擎存在性能较弱、规则缺乏管理等问题。
迁移到Java Flink后,在流量平台上统一管理运维ETL规则以及schema、数据集等元数据,用户在流量平台编辑相应的ETL规则,从前端发送到后端,经过一系列的校验最终保存为逻辑规则。引擎会将这个逻辑规则编译为实际执行的物理规则,基于Groovy的引擎通过GroovyClassLoader动态加载规则和对应的UDF。虽然Groovy引擎性能比Python引擎提升了多倍,但Groovy本身也存在额外的性能开销,因此我们又借助Janino可以动态高效地编译Java代码直接执行的能力,将Groovy替换成了Janino,同时也将处理Protobuf数据时使用的DynamicMessage替换成了GeneratedMessage,整体性能提升了10倍。
除了规则引擎的迭代,我们在平台侧的测试发布和监控方面也做了很多建设。测试发布环节支持了规则的线下测试、线上调试,以及灰度发布的功能。监控环节支持了字段、规则、任务等不同粒度的异常监控,如规则的流量波动报警、任务的资源报警等。
规则引擎的应用解决了埋点数据流ETL链路如何快速响应业务需求的问题,实现了ETL规则的动态更新,从而修改ETL规则不需要修改代码和重启任务。
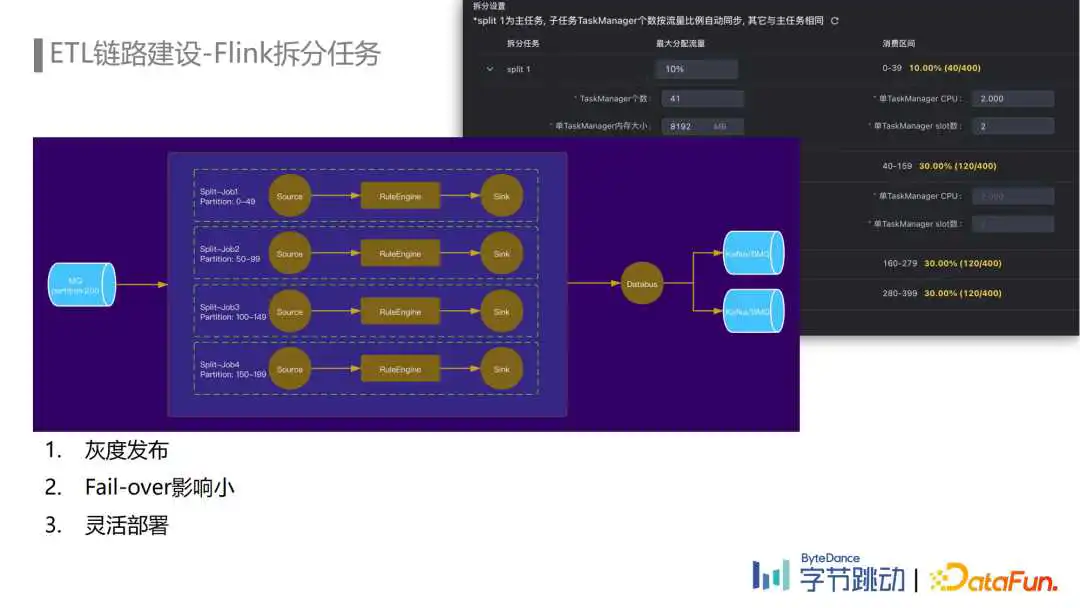
但规则引擎本身的迭代、流量增长导致的资源扩容等场景,还是需要升级重启Flink任务,导致下游断流。
除了重启断流外,大任务还可能在重启时遇到启动慢、队列资源不足或者资源碎片导致起不来等情况。
针对这些痛点我们上线了Flink拆分任务,本质上是将一个大任务拆分为一组子任务,每个子任务按比例去消费上游Topic的部分Partition,按相同的逻辑处理后再分别写出到下游Topic。
举个例子:上游Topic有200个Partition,我们在一站式开发平台上去配置Flink拆分任务时只需要指定每个子任务的流量比例,每个子任务就能自动计算出它需要消费的topic partition区间,其余参数也支持按流量比例自动调整。
拆分任务的应用使得数据流除了规则粒度的灰度发布能力之外,还具备了Job粒度的灰度发布能力,升级扩容的时候不会发生断流,上线的风险更可控。同时由于拆分任务的各子任务是独立的,因此单个子任务出现反压、Failover对下游的影响更小。另一个优点是,单个子任务的资源使用量更小,资源可以同时在多个队列进行灵活的部署。
说到ETL链路建设,埋点数据流在容灾与降级能力建设方面也进行了一些实践。
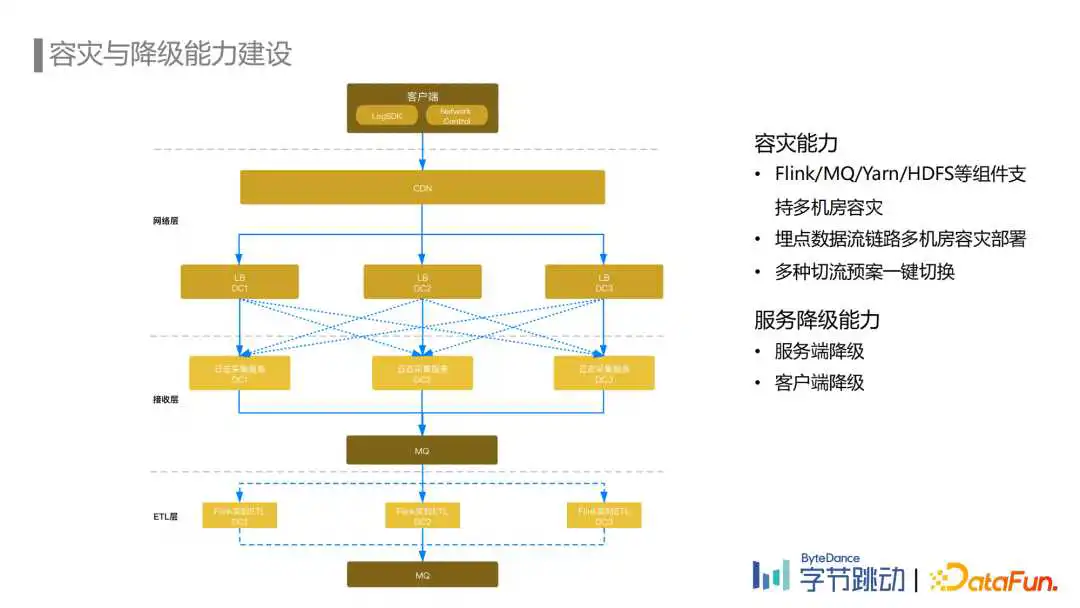
首先是容灾能力的建设,埋点数据流在Flink, MQ, Yarn, HDFS等组件支持多机房容灾的基础上完成了多机房容灾部署,并准备了多种流量调度的预案。
正常情况下流量会均匀打到多个机房,MQ在多个机房间同步,Flink ETL Job默认从本地MQ进行消费,如果某个机房出现故障,我们根据情况可以选择通过配置下发的方式从客户端将流量调度到其他非受灾机房,也可以在CDN侧将流量调度到其他非受灾机房。埋点数据流ETL链路可以分钟级地进入容灾模式,迅速将故障机房的Flink Job切换到可用的机房。
其次是服务降级能力的建设,主要包含服务端降级策略和客户端降级策略。服务端降级策略主要通过LB限流、客户端进行退避重试的机制来实现,客户端降级策略通过配置下发可以降低埋点的上报频率。
举个例子:在春晚活动中参与的用户很多,口播期间更是有着非常巨大的流量洪峰,2021年春晚活动期间为了应对口播期间的流量洪峰,埋点数据流开启了客户端的降级策略,动态降低了一定比例用户的埋点上报频率,在口播期间不上报,口播结束后迅速恢复上报。在降级场景下,下游的指标计算是通过消费未降级用户上报的埋点去估算整体指标。目前我们在此基础上进行了优化,客户端目前的降级策略可以更近一步地根据埋点的分级信息去保障高优的埋点不降级,这样可以在活动场景下保障活动相关的埋点不降级的上报,支持下游指标的准确计算。
介绍完埋点数据流建设的实践,接下来给大家分享的是埋点数据流治理方面的一些实践。埋点数据流治理包含多个治理领域,比如稳定性、成本、埋点质量等,每个治理领域下面又有很多具体的治理项目。

比如在稳定性治理中我们通过优化减少了由于单机问题、MQ性能问题和混布问题等导致的各种稳定性问题;
成本治理方面,我们通过组件选型、性能优化、埋点治理等方式取得了显著降本增效的成果;
埋点质量治理方面,我们对脏数据问题、埋点字段类型错误问题和埋点数据的丢失重复问题进行了监控和治理。
这次我们主要选取了其中部分治理项目和大家分享。
Yarn单机问题导致Flink任务Failover、反压、消费能力下降是比较常见的case。
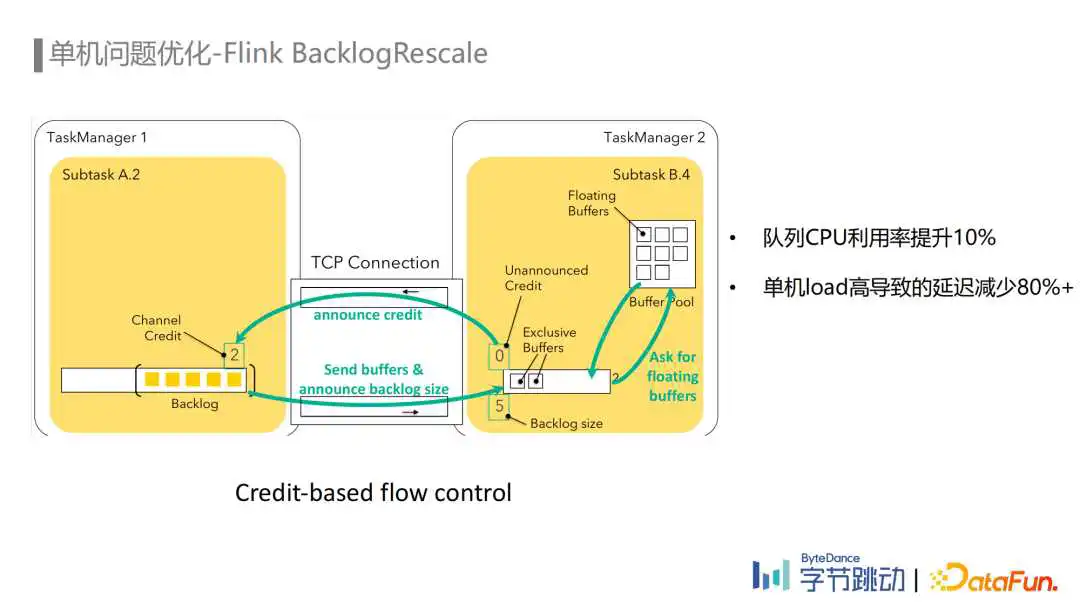
单机问题的类型有很多:队列负载不均、单机load高或者其他进程导致CPU负载高,以及一些硬件故障都可能导致Yarn单机问题。针对Yarn单机问题,我们从Flink和Yarn两个层面分别进行了优化,最终使单机load高导致的数据延迟减少了80%以上。
首先是Flink层面的优化,在埋点数据流ETL场景中,为了减少不必要的网络传输,我们的Partitioner主要采用的是Rescale Partitioner,而Rescale Partitioner会使用Round-Robin的方式发送数据到下游Channel中。由于单机问题可能导致下游个别Task反压或者处理延迟从而引起反压,而实际上在这个场景里面,数据从上游task发送到任何一个下游的Task都是可以的,合理的策略应该是根据下游的Task的处理能力去发送数据,而不是用Round-Robin方式。
另一方面我们注意到Flink Credit-Based flow control反压机制中,可以用backlog size去判断下游Task的处理负载,我们也就可以将Round Robin的发送方式修改为根据Channel的Backlog size信息,去选择负载更低的下游Channel进行发送。这个Feature上线后,队列的负载变得更加均衡,CPU的使用率也提升了10%。
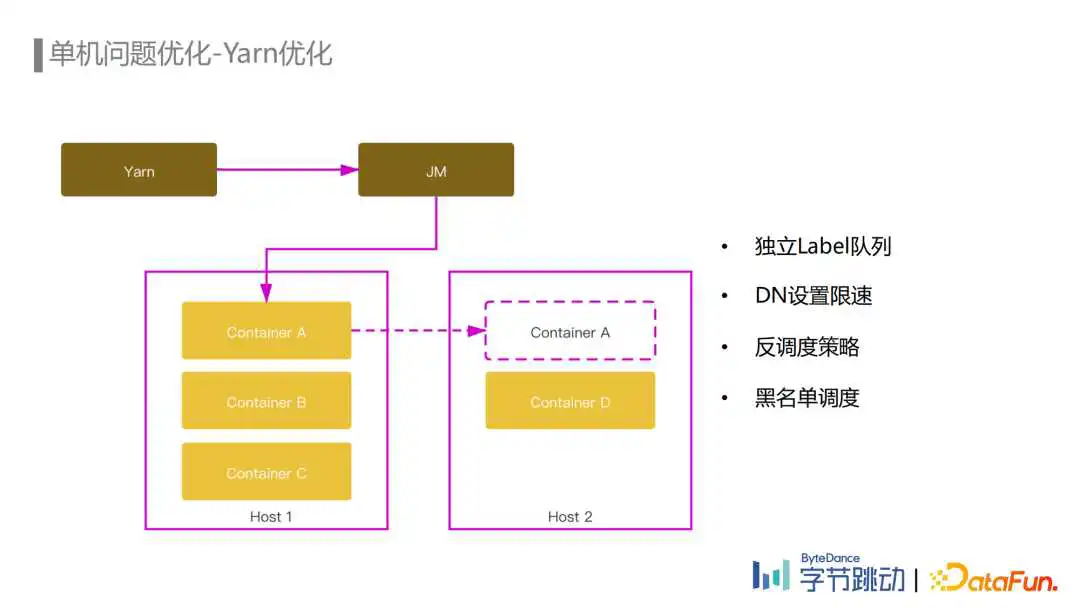
Yarn层面的优化,第一个是队列资源层面,我们使用独立的Label队列可以避免高峰期被其他低优任务影响。
第二个是对于Yarn节点上的DataNode把带宽打满或者CPU使用比较高影响节点上埋点数据流Flink任务稳定性的情况,通过给DataNode进行网络限速,CPU绑核等操作,避免了DataNode对Flink进程的影响。
第三个是Yarn反调度的策略,目前字节跳动Flink使用的Yarn Gang Scheduler会按条件约束选择性地分配Yarn资源,在任务启动时均衡的放置Container,但是由于时间的推移,流量的变化等各种因素,队列还是会出现负载不均衡的情况,所以反调度策略就是为了解决这种负载不均衡而生的二次调度机制。
反调度策略中,Yarn会定期检查不满足原有约束的Container,并在这些Container所在节点上筛选出需要重新调度的Container返还给Flink Job Manager,然后Flink会重新调度这些Container,重新调度会按照原有的约束条件尝试申请等量的可用资源,申请成功后再进行迁移。
另外,我们会针对一些频繁出问题的节点把它们加入调度的黑名单,在调度的时候避免将container调度到这些节点。
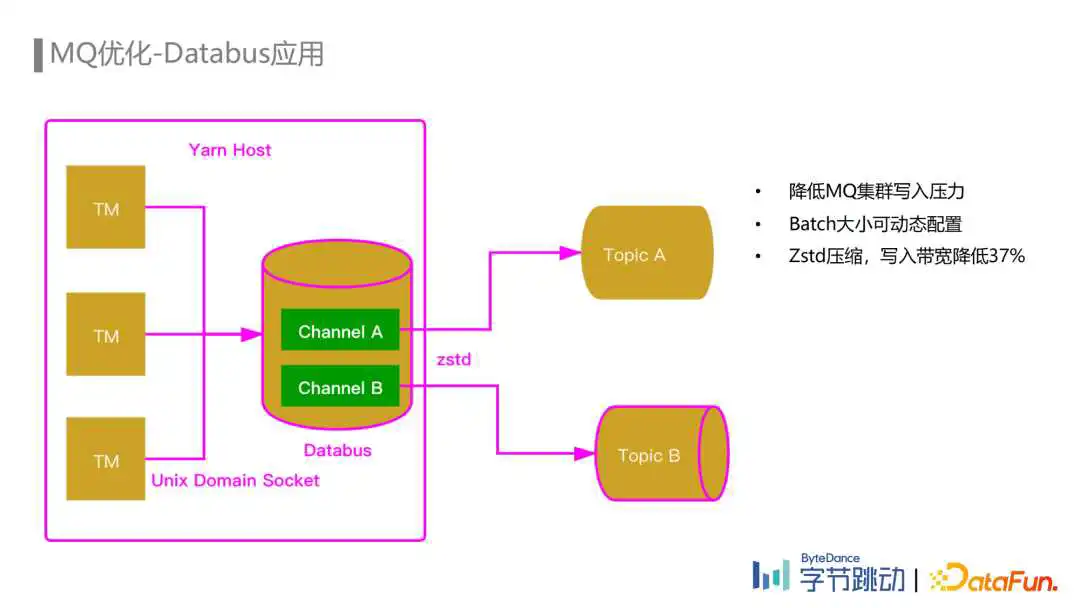
在流量迅速增长的阶段,埋点数据流Flink任务一开始是通过Kafka Connecter直接写入Kafka。但由于任务处理的流量非常大,Flink任务中Sink并发比较多,导致批量发送的效率不高,Kafka集群写入的请求量非常大。并且,由于每个Sink一个或多个Client,Client与Kafka之间建立的连接数也非常多,而Kafka由于Controller的性能瓶颈无法继续扩容,所以为了缓解Kafka集群的压力,埋点数据流的Flink任务引入了Databus组件。
Databus是一种以Agent方式部署在各个节点上的MQ写入组件。Databus Agent可以配置多个Channel,每个Channel对应一个Kafka的Topic。Flink Job每个Task Manager里面的Sink会通过Unix Domain Socket的方式将数据发送到节点上Databus Agent的Channel里面,再由Databus将数据批量地发送到对应的Kafka Topic。由于一个节点上会有多个Task Manager,每个Task Manager都会先把数据发送到节点上的Databus Agent,Databus Agent中的每个Channel实际上聚合了节点上所有Task Manager写往同一个Topic数据,因此批量发送的效率非常高,极大地降低了Kafka集群的写入请求量,并且与Kafka集群之间建立的连接数也更少,通过Agent也能方便地设置数据压缩算法,由于批量发送的原因压缩效率比较高。在我们开启了Zstd压缩后,Kafka集群的写入带宽降低了37%,极大地缓解了Kafka集群的压力。
在埋点数据流这种大流量场景下使用Kafka,会经常遇到Broker或者磁盘负载不均、磁盘坏掉等情况导致的稳定性问题,以及Kafka扩容、Broker替换等运维操作也会影响集群任务正常的读写性能,除此之外Kafka还有controller性能瓶颈、多机房容灾部署成本高等缺点。
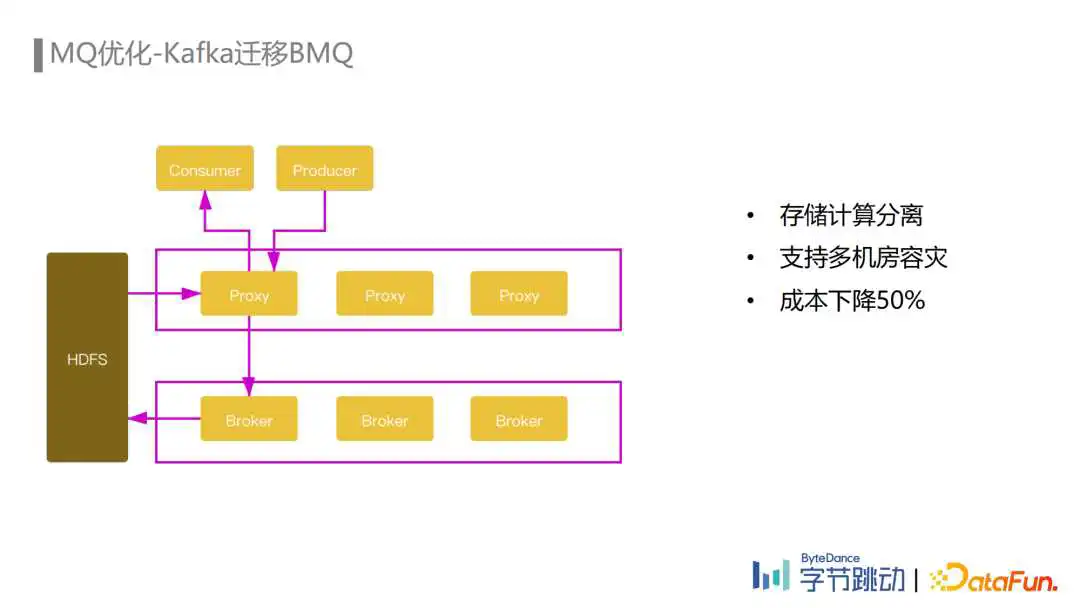
为了优化这些问题,BMQ这款字节跳动自研的存储计算分离的MQ应运而生。BMQ的数据存储使用了HDFS分布式存储,每个Partition的数据切分为多个segment,每个segment对应一个HDFS文件,Proxy和Broker都是无状态的,因此可以支持快速的扩缩容,并且由于没有数据拷贝所以扩缩容操作也不会影响读写性能。
受益于HDFS已经建设得比较完善的多机房容灾能力,BMQ多机房容灾部署就变得非常简单,数据同时写入所有容灾机房后再返回成功即可保障多机房容灾。数据消费是在每个机房读取本地的HDFS进行消费,减少了跨机房带宽。除此之外,由于基于多机房HDFS存储比Kafka集群多机房部署所需的副本更少,所以最终实现了单GB流量成本对比Kafka下降了50%的资源收益。
在埋点治理方面,通过对流量平台的建设,提供了从埋点设计、埋点注册、埋点验证、埋点上报、埋点采样、流式ETL处理,再到埋点下线的埋点全生命周期的管理能力。
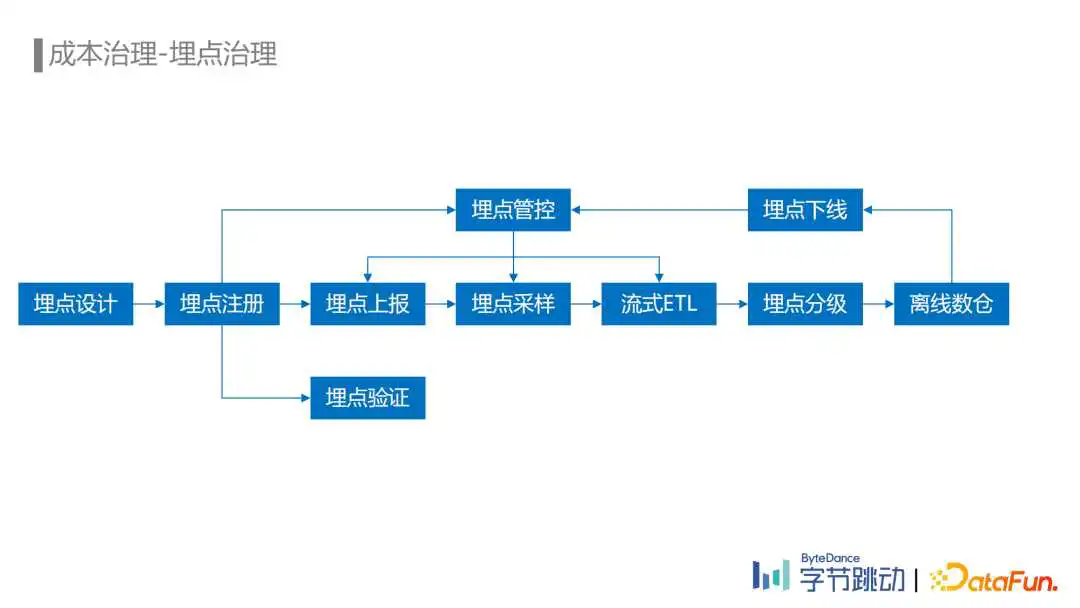
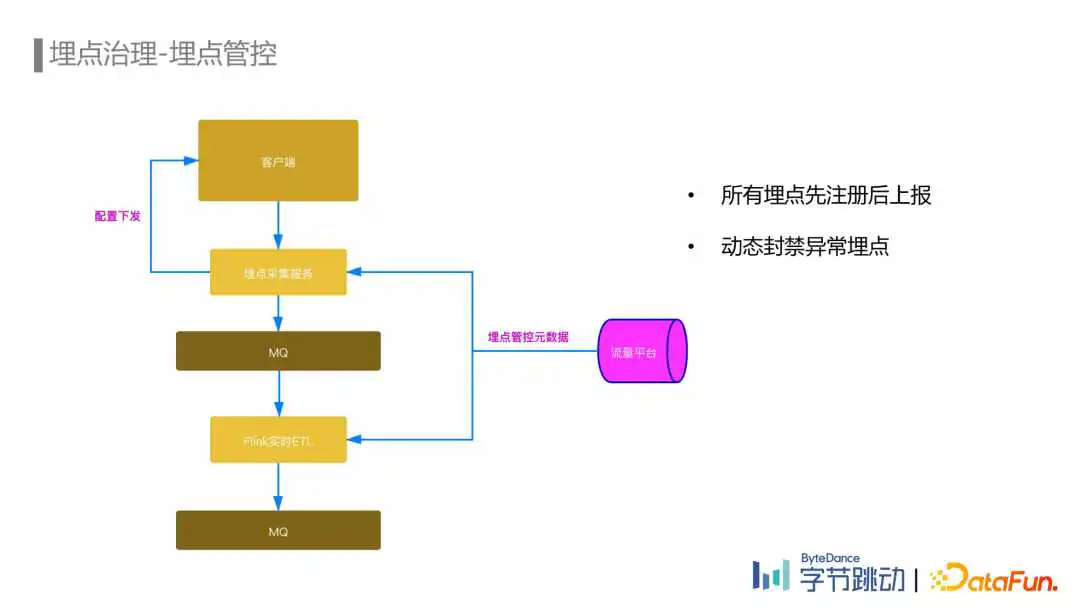
目前字节跳动所有的产品都开启了埋点管控。所有的埋点都需要在我们的流量平台上注册埋点元数据之后才能上报。而我们的埋点数据流ETL也只会处理已经注册的埋点,这是从埋点接入流程上进行的管控。
在埋点上报环节,通过在流量平台配置埋点的采样率对指定的埋点进行采样上报,在一些不需要统计全量埋点的场景能显著地降低埋点的上报量。
对于已经上报的埋点,通过埋点血缘统计出已经没有在使用的埋点,自动通知埋点负责人在流量平台进行自助下线。埋点下线流程完成后会通过服务端动态下发配置到埋点SDK以及埋点数据流ETL任务中,确保未注册的埋点在上报或者ETL环节被丢弃掉。还支持通过埋点黑名单的方式对一些异常的埋点进行动态的封禁。
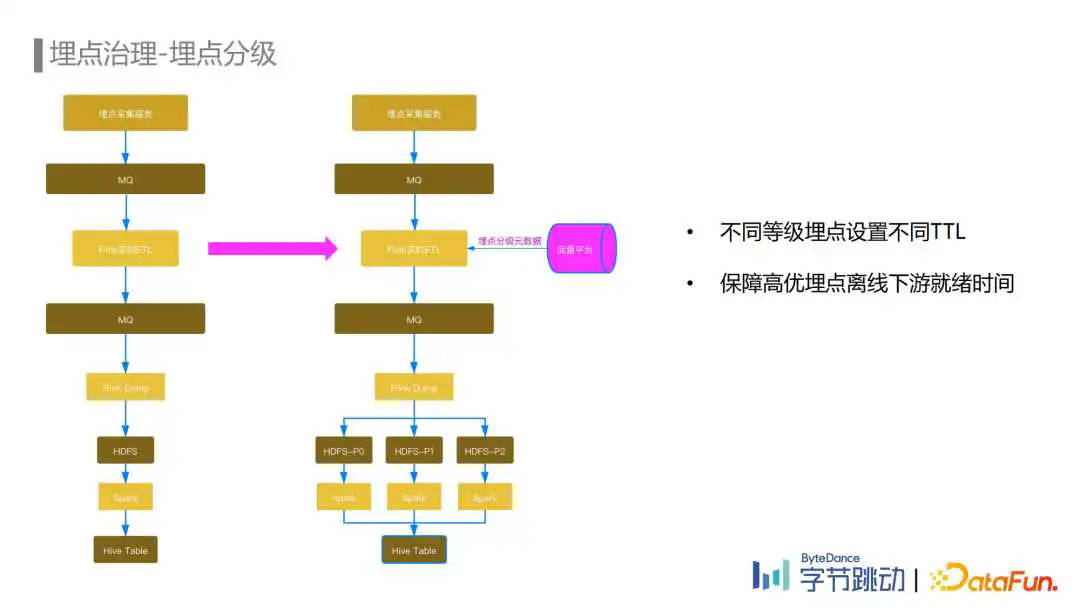
埋点分级主要是针对离线存储成本进行优化,首先在流量平台上对埋点进行分级,埋点数据流ETL任务会将分级信息写入到埋点数据中。埋点数据在从MQ Dump到HDFS这个阶段根据这些分级的信息将埋点数据写入不同的HDFS分区路径下。然后通过不同的Spark任务消费不同分级分区的HDFS数据写入Hive Table。不同等级的分区可以优先保障高优埋点的产出,另外不同分区也可以配置不同的TTL,通过缩减低优数据的TTL节省了大量的存储资源。
目前Flink能做到计算层面的流批一体,但计算和存储的流批一体还在探索阶段,接下来我们也会继续关注社区的进展。另外我们会尝试探索一些云原生的实时数据处理框架,尝试解决资源动态rescale的问题,以此来提升资源利用率。最后是在一些高优链路上,我们希望保障更高的SLA,比如端到端的exactly-once语义。

相关技术实践已经通过火山引擎数据中台产品对外输出,大家感兴趣的话也可以登陆火山引擎的官网进行了解。
Q:业务方查不到自己的埋点数据或者和业务系统的埋点数据对比UV不对,字节跳动是否会遇到这种情况,你们排查的思路是怎样的?
A:在埋点治理环节有讲到,在字节跳动我们把埋点的整个生命周期都管理起来了,从埋点设计开始,到埋点先注册后上报的管控流程。在埋点上报之前需要通过平台提供的埋点验证功能验证埋点是否上报成功以及埋点字段跟它注册的元数据是否是匹配的。我们通过这样的流程可以很大程度上减少埋点上报缺失和埋点质量问题。
Q:中间队列用MQ不用Kafka是出于什么样的考虑?
A:如果是问我们为什么从Kafka切换到BMQ,可以了解一下Kafka和一些存储计算分离MQ的对比如Apache Pulsar,通常来说存储计算分离架构的MQ会具备更好的伸缩性以及不会因为数据复制带来读写性能的下降,成本也会更低,会更贴近云原生的形态。
Q:埋点的数据质量治理还有什么好的例子吗?
A:我们现在做的比较多的是埋点上报前的埋点质量治理,比如刚才提到了在上报前通过注册埋点的信息开发完埋点后用验证工具去做自动化测试以保障埋点开发的准确性和质量,上报后我们也会用一些离线工具对埋点质量进行监控,但从我们的经验上来看,上报前埋点质量的把控会解决大部分的问题,上报后的埋点质量治理目前主要是离线的,也能解决一些场景的问题。
Q:埋点数据准确性怎么保障的?埋点数据处理的过程中是给到一个什么样级别的保障?
A:目前我们的处理链路是基于Flink实现的,大多数场景是没有开启checkpoint,原因是我们的下游需求很多样化,有的下游不接受数据的大量重复,有的下游不接受数据延迟,如果开checkpoint,会在任务Failover过程中有大量的数据重复和延迟,这个是下游没有办法接受的。我们通过SLA数据质量监控指标是可以观测出整个链路各个环节的数据丢失率和重复率,通过SLA指标来反映和保障数据准确性。
过去两年,深入“甲方”(之前乙方),啥也没干,专注埋点管理,睁眼埋点、闭眼埋点,对内发布了《XXXX用户行为数据采集标准规范v1.0》,总结了一些自己的实践,也希望与各位大佬互通一下有无。至此,总算写完了一版:
埋点有很多种,需求文档怎么写,首先取决于公司所采用的埋点技术手段(这是大前提)。
一是像GrowingIO、友盟、神策所用的埋点方法,通过主动编码,定义一个点位,再通过属性key去采集维度信息,形成“事件-属性-值”的点位结构;(说明:事件(Event)即我们常说的点位)
缺点:需要维护编码,后期需要有编码系统支撑;
优点:一维即可定位,可自定义关联属性,支持多维数据分析。
二是直接通过点位的多维度信息定义一个点位,比如点位所在父页面、所在模块、自定义坑位(比如1、2、3、1-2、1-3等形式代表第一个第二个第三个,第一排第一个,第一排第三个)共同定位一个点位(也可以通过父页面和点位所在位置二维定位,总之至少需要二维)。
缺点:需要多维度定位唯一性,点位知识复杂度上升(特别是埋点的需求人员是业务人员或产品,那点位的链接、父页面等信息需要与开发确定),页面的属性信息无法通过事件关联上报,而业务维度是日常分析的核心;
优点:不需要单独编码与编码管理。
总体来说,第一种方法的优势更大,点位可复用性更高、点位质量也更高、整体管理成本低,为目前的主流方法,所以推荐第一种。
有个基础理解,接下来我们再讨论如何开展埋点这项工作:
开篇已经讲过了,以之前看过到过的美团的方法为例,通过页面、模块、坑位共三个维度来定义一个点位的唯一性。
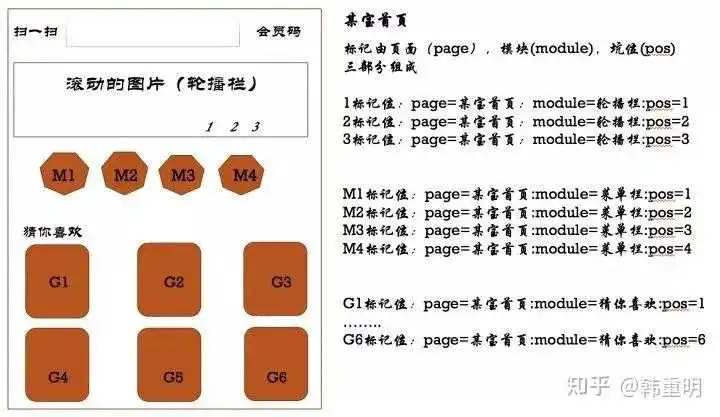
最早在为某企业提供咨询服务时,采用的埋点结构是通过父页面(F列)和页面/交互点标记(B列)二维定位一个点位的唯一性,如果一个资源位能挂10个轮播图,那就需要预留10个点位,与美团的方法类似,如下图:
但现在主流的埋点都已经开始采用神策、GIO、包括诸葛io的埋点方法。因为同一个埋点信息除了支撑业务做统计分析,可能还有更多的应用场景,比如构建行为路径做分析、用作推荐系统的数据源,毫无疑问,方法一在计算层效率更高~
中文语义下,点位需要有中文名称,故会有事件名称和事件ID的对应,事件ID全局唯一,即事件名称也全局唯一。
(tips:GrowingIO、神策、友盟都需要在需求文档中定义事件ID和事件名称,诸葛io只需要定义事件名称,埋点追踪代码直接写中文名称,ID会由算法自动随机生成一个唯一标识符)
事件ID:
强烈建议:不!要!用!全!英!文!
无论是编码管理、代码维护、内部沟通协作,数字都是信息传达最高效的方法。
特别是如果企业内业务类型比较多,涉及的平台比较多,可以通过编码来
用“纯数字”或“字母+数字”,如: 或 MBZH,MB代表移动端,ZH这两位代表应用名称(此处如知乎),故结构即 【平台&应用&6位数字编码】(只是个参考,可根据实际自定义)
点位命名规范:
为体现点位的唯一性,且分析人员做分析也是阅读中文,所以中文命名非常重要。
建议:页面/父页面-动作&元素。请务必使用连接符“-”。
回答中的几个截图,命名都不规范,包括神策、GIO官网给的埋点示例(差评!)。
(过去在乙方,也涉及到埋点工作的咨询服务,但当真正来到甲方的时候才发现,乙方的帮助中心/说明手册/模板就是个知识的海洋,要把这些基础能力用好,需要结合业务实践做二次定义和说明,如制定适应于当前企业的标准规范)。
用户进入了商品详情页,我们分配了一个编码,可以知道这个编码上报了多少次,也就知道了这个商品详情页被访问的人数/次数。但分析的时候我们更需要知道的是这是哪个商品的详情页,价格是多少,什么类型的产品等等这些维度信息,商品的名称、价格、类型即属性。
至于需要上报哪些属性,完全由需求方来定,如果我只需要采集商品名称做分析,那商品ID甚至都可以不上报。也有时候,ID虽然唯一,也能代表一个商品,但分析的时候我们要看中文,所以采名称也会有助于理解。(tips:这里建议事物的唯一ID作为必报项)
好,理解了事件名称和事件ID的唯一性和关联性,理解了点位需要管理上报的属性,我们再来看想要提一个埋点需求,要怎么做才能与上下游的同事高效协作?
点位的编码、命名、属性关联,这些信息是开发实施的时候代码侧的必要信息。
如何提一个清晰和专业的埋点需求。不只是给一个事件id和属性ID的清单这么简单。

注意:图中的7列,一列都不能少。
事件ID:事件的唯一编码,全局唯一。
事件名称:定义点位并命名。事件名称全局唯一。命名规范:父页面-动作&目标;字符数最好有限制,通常小于20个字符,连接符“-”必填。
事件描述:补充说明事件的唯一性,便于开发确定点位,便于理解点位所在位置,可通过文字和图片的方式。
属性名称:事件属性的中文名称
属性ID:事件属性的标识符
值示例:对属性的值给出示例,特别是需要特殊处理的值。如值为时长的,均可让在上报环节处理成毫秒或秒上报,对于多值的情况逗号隔开上报,如统计搜索结果数量,可约束值为具体数量,如0,1,2,3...,也可约束为“是/否”,以此代表用户的搜索结果是否有值。
采集时机:明确在什么时机上报数据。采集时机描述通常分4种:click点击即上报/开始加载上报/加载完成上报/返回后端的某一判断结果上报
埋点需求也是需求,那就必须要明确明确再明确,事件描述、值示例、采集时机都是明确需求、保证数据上报准确性的重要依据。在实施前,每个点位也需要开发、测试和需求方一起评审。
业务线单一、组织结构简单,那埋点基本不会太耗时耗人。业务丰富、组织结构复杂,那埋点就不是一份需求文档这么简单的事儿了,可能涉及到埋点管理或者叫数据质量管理了。
埋点其实很简单,50个点位的埋点需求表,前端工程师可以能两个小时就实施完了,本身的技术门槛并不高;
埋点其实也很难,在企业内想要开展这项工作,你可能会面临,如:
1、领导是否重视数据采集?这决定了这部分工作是否优先级会高,今天花1小时埋点了,今天之后的每一天就数据依据了;
2、是否重视数据质量?这需要有规范的埋点需求文档,以及同产品功能一样的实施、测试、上线流程来保证埋点需求、实施与实际上报的数据一致性;
3、企业内应用的平台(如安卓、ios、web、H5、pad、支付宝/微信小程序)覆盖度,这决定了不同应用平台或技术框架下的埋点方法,以及编码管理;
4、业务线的丰富度,这决定了与企业内各业务线之间的协作管理方法,特别是对于变化的管理;
5、埋点数据的生命周期管理,如果没有这一项,数据量会越来越大,造成管理、存储和应用成本的增加~
比如,我目前服务的公司,多款APP需要埋点,需要制定不同的编码规范;APP之间会存在页面/功能共用比如商品详情页(多款APP调用商城的同一个页面),如何管理编码;一个页面APP内外都能打开,如何通过埋点区分数据来源;同一个APP内有20多条业务线,对接埋点需求一共有上百人,如何做好埋点方法培训和知识传达以及日常埋点管理;
从着手这块儿工作到现在,整整用了大半年,才将一份正式的规范文档发布,基本涵盖了当前业务环境下不同业务需求、不同应用、不同角色所涉及的埋点相关的工作。目的是保证一个新人加入,无论是运营还是产品,基于标准和模板可以快速上手并线上协作。当前我们在规划埋点系统建设,将现有的管理流程和方法线上化,提升整体效率。
(这么一捋,还真是一个不小的工程~~~~)
大白话介绍,最后夹杂了点我自己的一些工作内容,有对比,很多事情就知道深浅、知道高低,也就知道自身需要掌握到什么程度,仅供大家参考。
回到问题,埋点需求文档看似是一个偏技术性的东西,但总体来说门槛并不是很高,所以不管是产品还是运营,先不要怂,写一两份埋点需求,对接一两次开发,基本就会了。
埋点只是数据价值发挥的第一步,真正难的反而是结合数据洞察用户、做产品迭代指导、做运营策略的指导~
篇幅有限,如有不明确的需要探讨的可以评论或私信~
未完待续~
2021/11/24更新下文
一直惦记着把这个答案再补充完整。一是自己能有个总结,二是本身这个领域太细分了,再次也希望与各位同行有所交流,相互补充。
最近大半年一直在将埋点管理这套流程和方法给平台化,一点实践,稍作总结。
搜索埋点管理系统,网上会有一些文章,系统的目标和价值是一致的,只是在不同的企业内,根据组织形式不同、业务不同,在功能上会有30%的个性化,但70%是共性的。
比如知乎的埋点管理系统:
比如字节的埋点管理系统:
相同点是,核心都是对点位的编码和定义的管理,增加了一些组织信息、上下文信息的描述。
不同点是,对于一些企业,存在多业务线多组织的形式,可能会存在多应用、多项目管理,以及数据管理员的角色,于是有了需求管理、审核流程等。更甚者,增加了点位的画像,生命周期监控等。
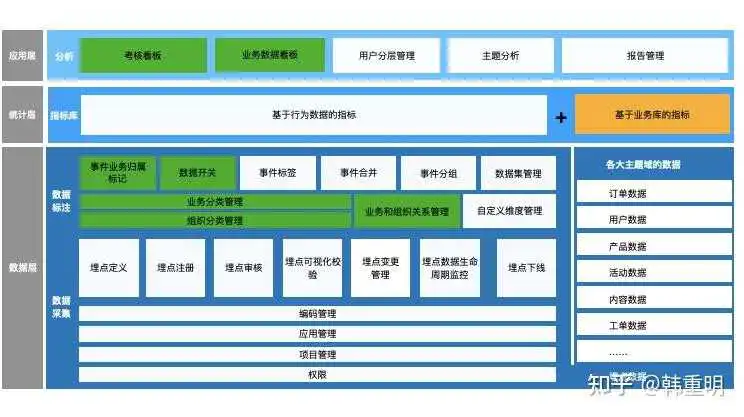
简单画了个架构图,便于理清不同数据产品之间逻辑关系和定义,其中数据标注可能会被忽略。我在数据层单独把这部分拆出来了。

下图是对上图的详细补充,当然,不同的企业内可能细节和定位会有所不同。仅供参考吧。
绿色部分是已经实现的,其他是正在做的。特别是数据层→数据采集模块的相关功能。
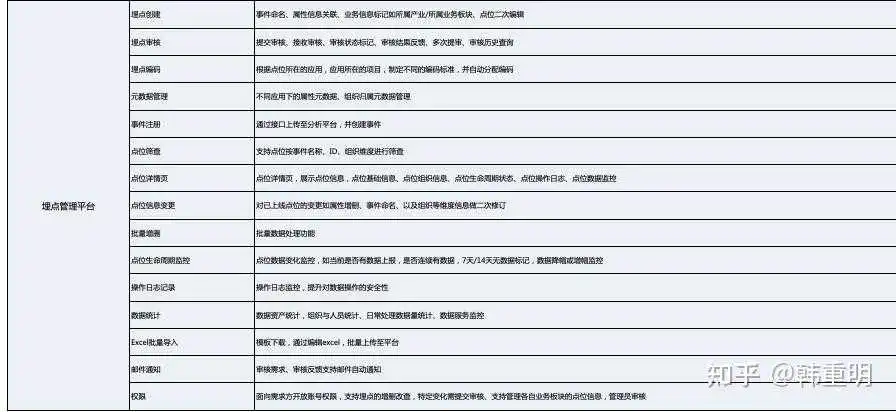
其中数据采集模块下的功能,大体就是埋点管理系统的一些核心内容,下文整理成了功能列表:
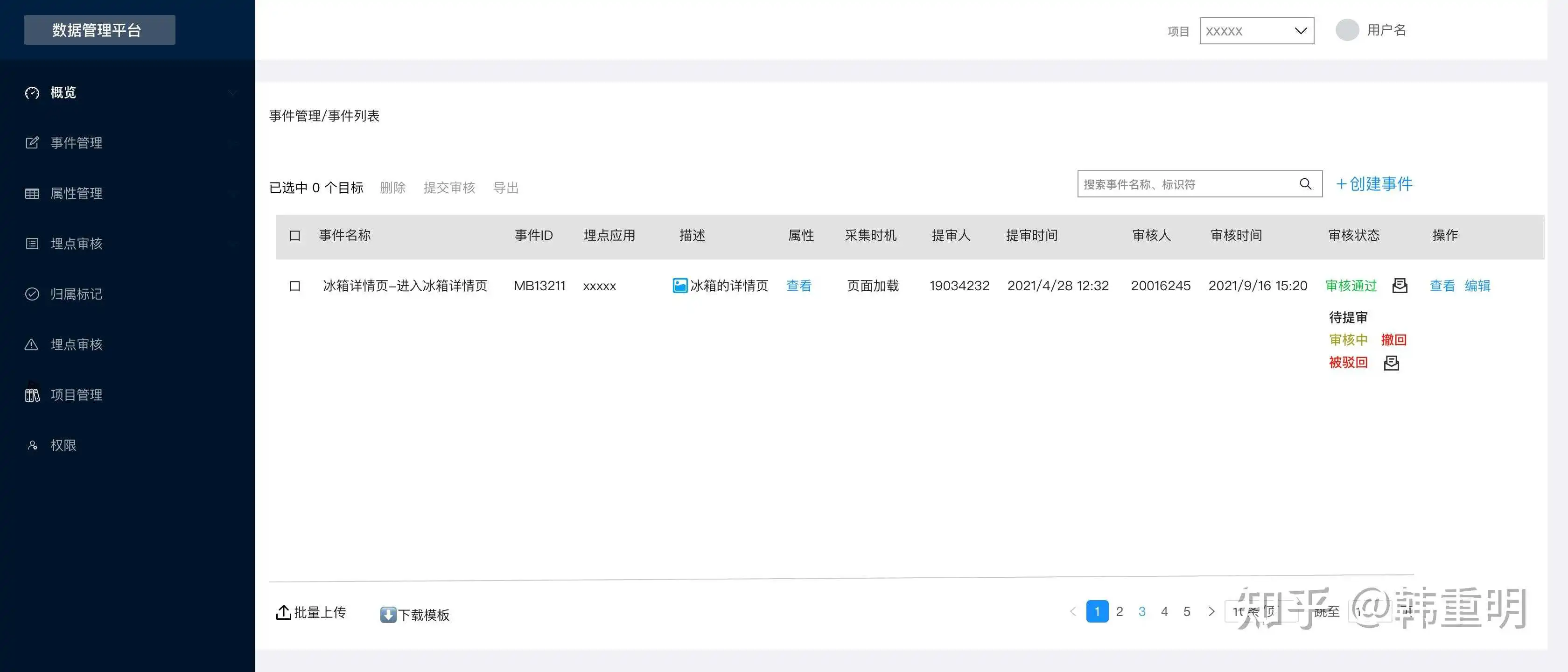
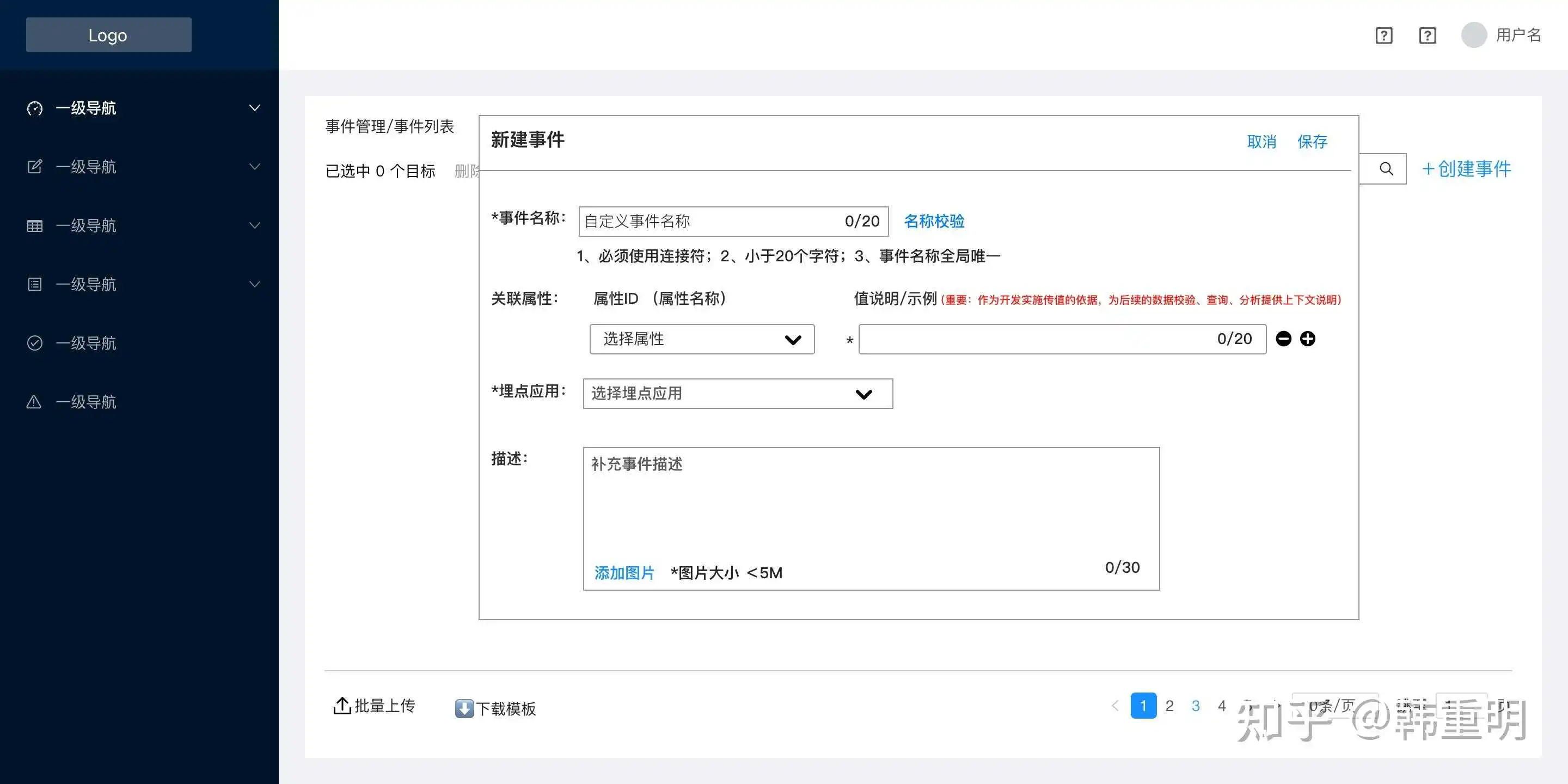
两张示意,在此就不做过多展示。系统本身不存在特别复杂的逻辑,重点是这项业务在企业内开展的方式决定了他的功能。仅供大家参考。
用户行为数据是企业除业务数据意外非常重要的数据类型,在企业内支持软件产品的优化迭代、支持推荐系统、支持营销触达、支持标签计算等等。希望这个回答能让更多的领导者重视用户行为数据的质量管理、重视埋点管理系统的投入和建设。
如果你觉得这篇回答对你有所帮助,希望不吝点赞~
另:我们正在为企业提供大数据与人工智能的整体解决方案。如您企业有CDP、数据治理、用户行为数据采集与分析、智能BI、智能营销平台等的产品需求,欢迎私信联系~
晚安~
1.什么是埋点?
小时候,为了让喜欢的小姐姐注意到我们几个小伙伴,我和几个小伙伴会先摸熟她每天的回家路线,然后提前埋伏在这条路线上的几个地点,然后突然出现,假装偶遇。
这里的埋伏地点和埋点有什么关系呢?
数据分析的前提是要有数据,那么问题就来了,数据从哪里来?
这就需要进行数据采集,采集哪些数据呢?就需要提前规划好采集数据的地点。
我们把小姐姐回家路线看作一款产品(网站或者App)。为了采集到用户数据,比如用户点击某个按钮的次数、观看视频的时长等(为了让小姐姐看到我),需要在产品中提前埋伏好。
也就是在产品中哪个地方想获取到用户数据(我和小伙伴在路线上提前选好几个地点埋伏)。这就是埋点(也就是埋伏地点)。
了解了什么是埋点,下面来说如何埋点。觉得文字看起来麻烦的话,也可以看视频,我结合自己在IBM的数据分析经历和一些大厂的一线业务案例设计了一套数据分析课程,讲解模型结构+逻辑框架,帮助大家搭建数据分析思维,多维度拆解分析方法等也用案例进行讲解,并带大家实践练习。课程为期3天,直播讲解+学习社群的形式。
这个课程对于0基础、想转行的人也非常合适,能让小白短时间内掌握职场上常用的工具操作、分析技巧方法、和数据思维,解决常见的数据分析问题是没有问题的。
2.如何埋点?
实现埋点的技术有两种:
(1)使用第三方工具实现。比如GrowingIO、Talkingdata、友盟、神策等。
(2)有些公司对数据安全要求高或者业务复杂,就自己开发来实现。也就是公司开发人员在产品的某些地方加上(“埋伏”)代码来统计用户行为数据,然后有一个后台可以查看这些采集到的数据,方便日后分析。
3.埋点是谁的工作呢?
通常是产品经理、运营或者数据分析师提前做好埋点规划(也就是想要采集什么数据),然后由开发工程师来根据规划去实施埋点。当然,有的公司职责划分没这么清楚,会使用第三方工具又一个人完成。
4.如何进行埋点规划?
(1)业务流程是什么?
想知道埋伏在哪里才能和放学回家的小姐姐偶遇,就要提前摸清楚她回家的路线。同样的,想要知道在哪埋点,就要知道产品的业务流程。
(2)分析目标是什么?
埋伏在小姐姐放学回家路上的目标是为了偶遇。同样的,埋点的目标是为了方便分析,所以要清楚分析目标是什么。
例如,分析目标是想知道公众号菜单栏的人均点击次数。
人均点击次数=菜单点击次数/菜单点击人数。所以,需要采集的数据是:菜单点击次数、菜单点击人数。
(3)采集哪些数据?
根据前面的分析目标知道要采集哪些数据,然后才能在产品对应的地方埋点。本案例要采集的数据是菜单点击次数、菜单点击人数。
假设完成了上面埋点规划,实施埋点后,采集到了下面的数据。
然后,就可以根据采集到的数据,分析出每个菜单的人均点击次数。通过分析可以知道用户喜欢产品的哪个按钮,然后根据分析结果,不断优化菜单里的内容。
5.总结
(1)什么是埋点?
埋点就是为了采集数据,在产品的某些地方提前埋伏好,来获取数据。
(2)如何进行埋点规划?
通过三步进行:业务流程是什么?->分析目标是什么?->采集哪些数据?
下面这个例子理解埋点也不错
在日常工作中,还有很多像埋点这样的数据分析需求,大到项目管理,营销策略等事关公司盈利的大问题,小到一个表格的快速整理和查漏补缺,只是有时候我们也许意识不到这是数据分析。也因此,现在数据分析成了一个学习热点,我在知乎知学堂的数据分析课程也是针对这样的需求,无论你是想成为数据分析师,还是用数据分析提高工作效率,都是很实用:
感谢合作方妹纸一路指导,没有放弃治疗我,最后CC终于花了半个月搞定了埋点表,技术花了一周埋点,CC又花了快一周设置图表,其中的心酸无法用言语表达了~
看到这,小伙伴是不是对数据埋点更心存畏惧了?
别怕,其实数据埋点没那么难,科科科~
接下来CC将给大家讲下数据埋点的一些思路~

以下案例均来自神策数据,选择TA是因为大家可以去体验里面的demo,我分享的干巴巴的内容也会变得更加生动、有趣~
神策电商demo:https://ebizdemo.cloud.sensorsdata.cn/clustering/?project=default#id=263
神策如想打广告费给我,请直接微信转账,蟹蟹~
一、基础知识
神策数据的逻辑比较简单,主要有两张表:一张事件表,一张用户表。
事件即人干了啥,比如说我买了个商品,我就触发了购买事件;
用户即埋点事件的实施人,上面的购买事件中的用户就是我啦~

事件表的每个事件、每个用户下都会有不同属性,拿常见的浏览事件来讲,属性就是pv、uv、停留时长等等;用户的话,属性就是用户年龄、所在省份、会员等级等等。
同时每个事件发生时我们都记录了时间,因此我们可以从时间维度(秒级、小时级、天级、累计)来查看用户的操作和跳转路径。
根据数据类型、展示形态的不同,我们还可以采用线图、柱状图、饼图和累计图等图表样式展示。
根据业务类型、用户类型等维度,我们还可以将用户分成不同的组,分组查看用户事件操作情况。
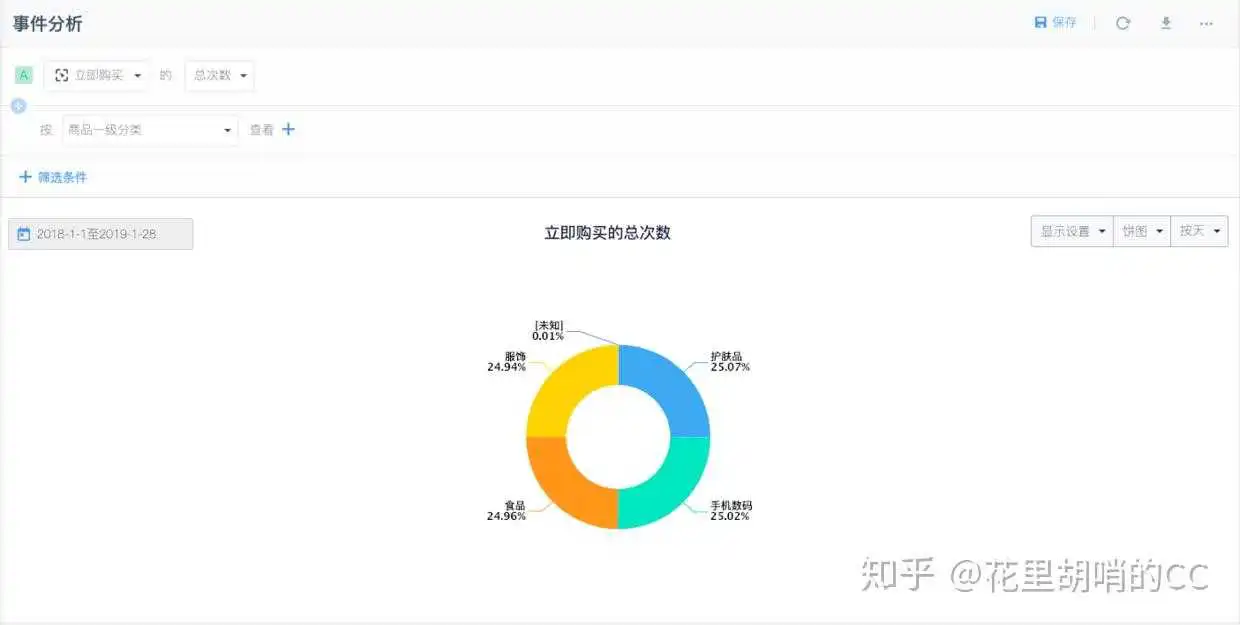
很多数据平台都采用这样的埋点基础,优点是简便易操作,后期维护也比较方便,只需要往第三方平台里面加减事件和事件属性即可。缺点也比较明显,没有动作的数据将没法监测,比如说余额、上架中商品,这两个概念是个持续中的概念,没有人干了啥,所以这类平台就傻B了。
二、事件埋点
(一)事件需要埋哪些点
在此CC给大家展示下电商平台关注的一些事件,具体如下:
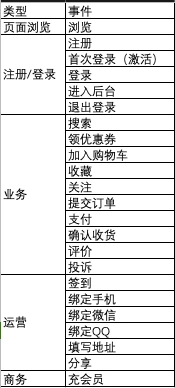
浏览、注册/登录和运营这三类事件,换个互联网行业也是需要埋的,具有非常强的普适性。大家掌握了这三类事件,尤其是浏览和注册/登录事件,基本上已经掌握了大半的数据埋点了。
现在的数据平台都支持前端全埋点,好处在于前端再也不用一个页面、一个按钮这样埋点了,大大大大节省了前端的时间,也挽救了他脆弱的神经。不过类似首页这样的核心页面,还是有必要自行埋点,全埋点对关键性按钮的监测、首页热力图分析不是太友好。
(二)事件需要设置哪些属性
事件属性是数据埋点中的重中之重,所幸常用的事件类型,如浏览、注册/登录,第三方等数据平台已经给设好了,无需谋杀自己的脑细胞了。但如果是业务数据,那就需要自己上了。
浏览事件一般都是前端埋点,在此简单说下常见属性,具体如下:
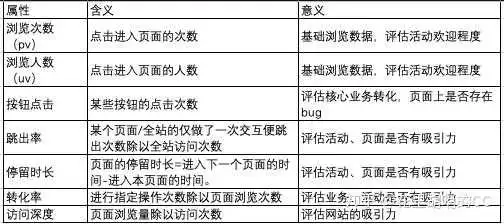
注册/登录事件的属性比较简单,一般统计的是人数。需要注意的是,注册人数和注册次数,登录人数和登录次数一般来说是相等的,如果数据相差过大,就需要找后端开发排查原因了。
这类数据展示平台对大部分注册事件(比如说web注册、APP注册)的支持都是傻瓜操作式的,比较好上手,不过最近几年公众号、小程序崛起,埋点的时候仍需要去了解下机制,避免数据出现错误。
拿web注册事件来讲,一般来说我们都是允许匿名浏览,即游客模式。这个时候,系统会赋予用户一个匿名ID,当用户被平台华丽的内容吸引,觉得非注册不可,提交了自己的注册信息(如手机号、用户名等)后,系统会再赋予用户一个正式的用户ID,并关联原来那个匿名ID,将注册之前的数据继承下来。在此其实发生了3个事件,一为赋予匿名ID,二为赋予正式ID,三为关联ID,那我们如果想要了解下到底注册了多少人,需要统计的事件是二或三(任择一),如果二、三相差很大,那就又需要请后端小哥哥出马了。
如果是公众号、小程序内,用微信授权登录的话,一是一样的。用户如果需要注册,微信会弹窗提示是否授权,用户点击【允许】,我方即可拿到用户的open ID,微信昵称和头像,然后生成一个正式用户ID,关联之前的匿名ID。相比web注册事件,仅仅多了一步获取open ID而已,机制上是雷同的。

除此之外,注册、浏览事件里面有个非常重要的属性,即用户渠道来源。
数据运营的第一课就讲到了一个漏斗的概念,来源于AARRR模型(拉新、促活、留存、转化和分享)。
在漏斗分析当中,必须要了解的就是用户的注册来源。
注册来源的概念来自于百度之类的搜索引擎投放,比如说渠道运营用了3个广告页和10个推广词来获取注册量,如果不做渠道分析的话,他将无法优化转化,提高投入/产出比。但如果仅仅是这样的分析的话,用百度的统计工具就足够了,但在实际工作中,我们还想了解从百度A广告来的用户,后面有没有再次登录、有没有点击我们推荐的新品、购买促销商品,绑定自己的微信号,光查看注册数据已经不能满足需求了,在此就需要采用这类渠道埋点了。
浏览事件也是类似。比如说我们收到10个用户订单,我们想了解下用户是从哪个站内广告进来的,然后才能采取进一步的运营手段,比如说加强带量多的广告,并优化掉无流量的资源位等等。
渠道来源埋点非常简单,只需要在推广链接后面加上spm,然后让前端向后端传递值的时候加上这个spm信息,即可记录了。
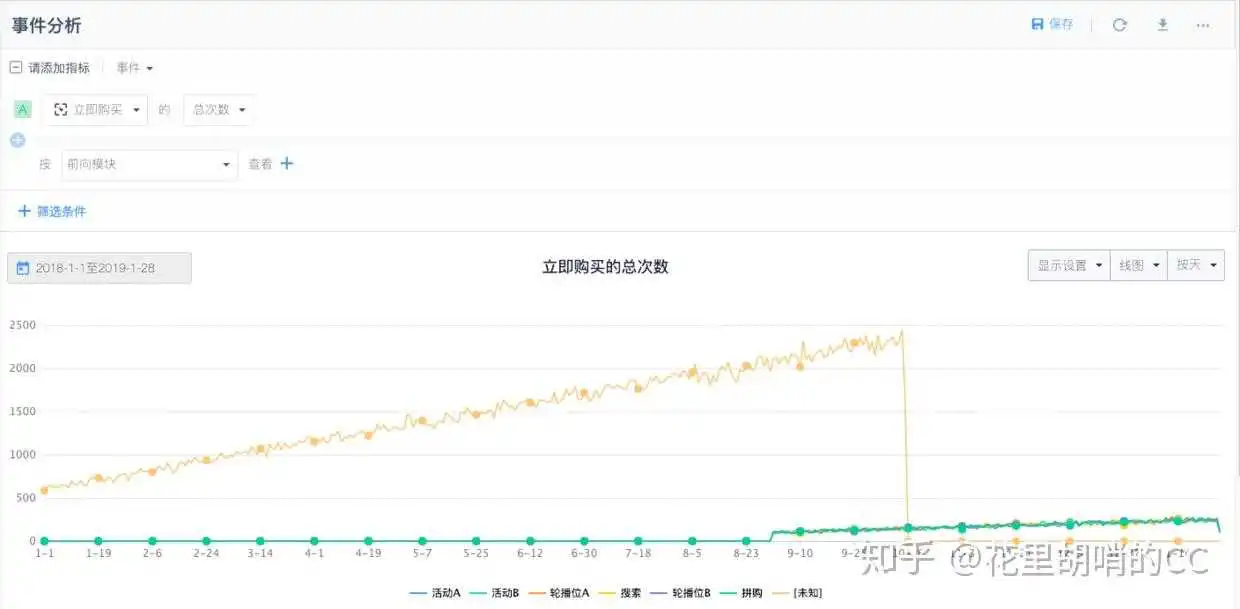
再来说说登录事件,在未登录状态下,系统其实是无法知道现在正在浏览的用户是新人还是老人的,只有用户登录之后,才能确定。因此登录/授权时,其实是在拿信息去数据库匹配,看这些信息是不是已存在,已存在的话,就直接拿那个用户信息了,没有的话,才会提示注册,或者直接触发注册事件,新增一个账户,然后进行ID关联。

接下来我们讲讲业务事件埋点的属性。
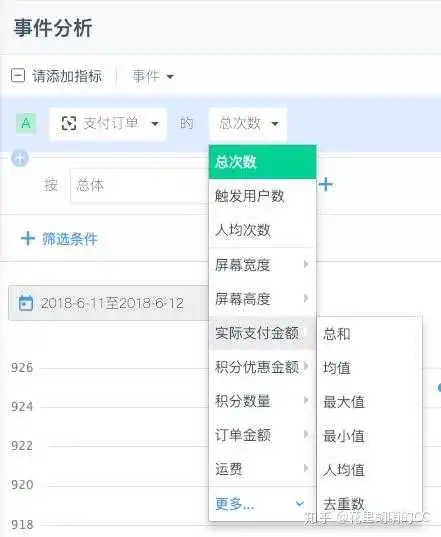
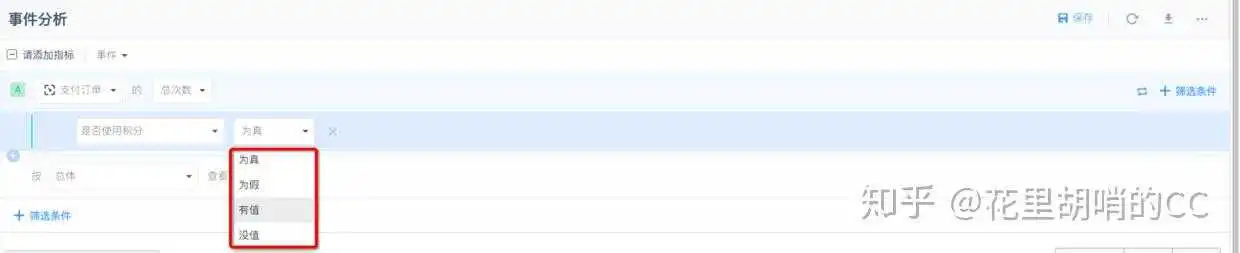
属性的类型其实比较少,主要有数值、字符串和BOOL值。数值的话,一般是次数、人数、金额等等,可以查看总和、均值、最大值、最小值、人均数等,如下图:
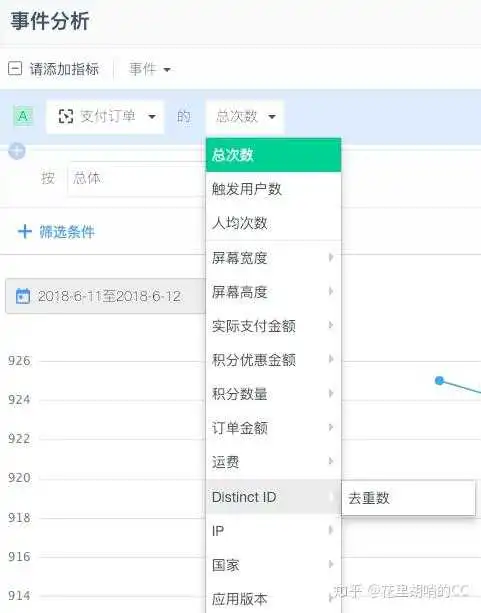
字符串的话,一般是标题、商品名、用户ID等等,因为不具有数字属性,在统计的时候,只能展示去重数,而没有最大数之类的展示,示例如下:
BOOL值看上去会很陌生,其实这是一类我们经常会用到的属性,即是/否,通过/不通过的属性,在第三方平台里面默认展示为真/假,如下图:
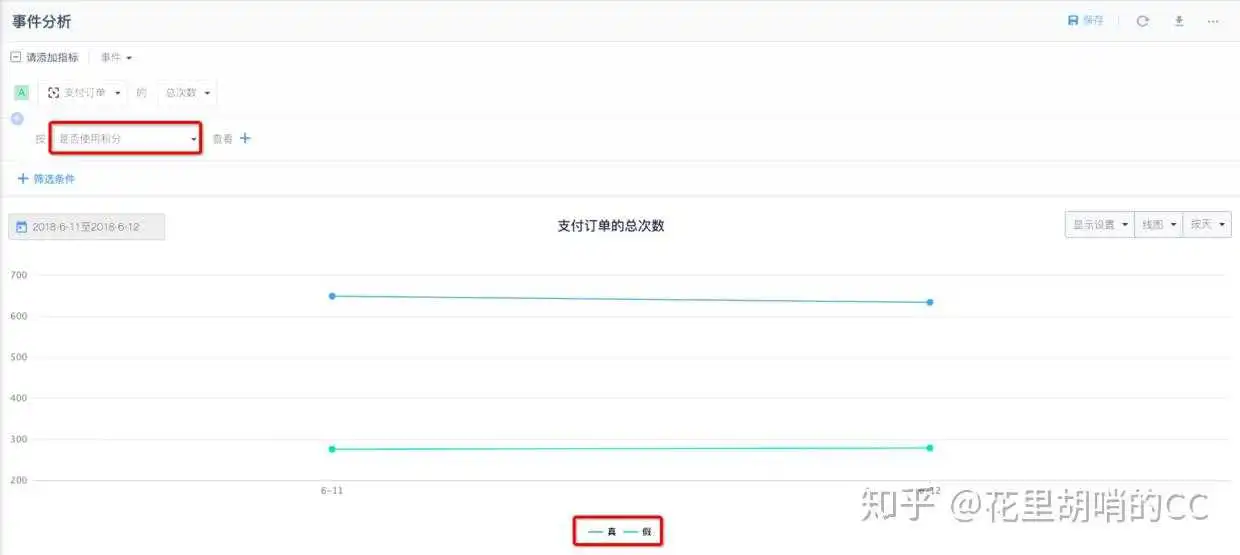
BOOL值埋点是很容易出错的,大家很容易把是/否、通过/不通理解为字符串,设置为两种类型。在看数据概览的时候这两种区别不大,但是需要做一些逻辑筛选的时候,BOOL值的优势就体现出来了,如果到比较复杂的用户分群功能时,就必须用BOOL值了。
(三)非要埋没有动作的数据怎么办
没动作的数据一般是进行中的数据,比如说上架中商品数、账户余额、应收款等等,尤其是财务数据,建议最好再搞个专业的财务数据管理系统。
但老板的想法可能跟我们不一样,他考虑的是性价比,喜欢的是全套方案,如果他花钱买了一个服务,你告诉他没法全覆盖,还需要再买个数据系统,他心里一定老不开心了。
这时候苦哈哈的你就需要探索其他不花钱的方法了。比如说统计上架中的商品数,可以定时去线上跑一个脚本,统计商品数,人为触发一个展示事件。又或者自建数据后台,这类数据就自行埋点,不用第三方的了。

三、用户埋点
(一)用户需要埋哪些点
讲完了事件埋点,我们再来讲讲用户埋点。我们电商平台常用到的用户属性如下:
(二)埋用户表有什么用
不知道大家在平时工作中有没有遇到这样的尴尬:
比如说老板拿着个手机突然跑向你,说某个功能他用着不爽,一定要把按钮突出、字体加粗加红。
又或者客服小伙伴接到一个用户反馈,说自己到某一页就是点击不了,或者出现了一些灵异事件,测试搞了半天还是复现不了,用户对于无法复现这个结论肯定是不满意的,说你们怎么那么辣鸡。
这个时候你就会发现针对单个用户的数据埋点是如此的重要。
做了单个用户埋点之后,你可以观察用户的使用路径,比如说什么时候登录的,什么时候签到了,买了啥,简直是讲道理、撕逼、怼脑残需求的必备良品。
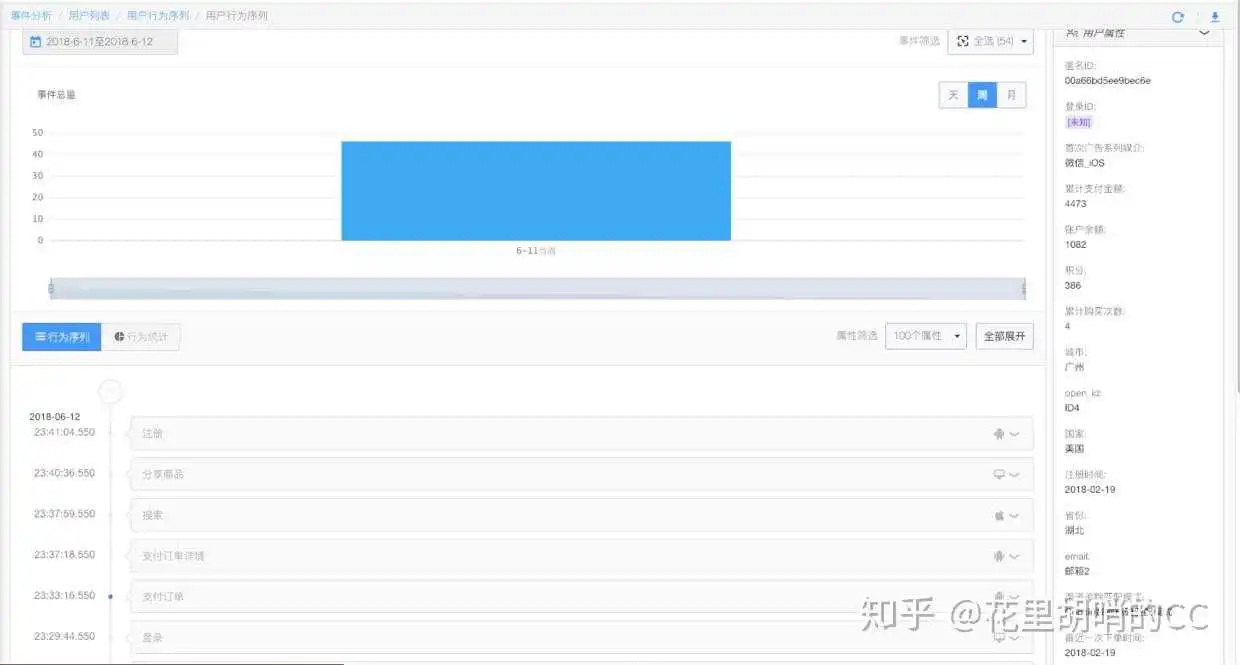
对于一个有理想、有追求的产品经理来说,这个功能的优点还在于可以更加细致地观察用户在体验产品的时候究竟经历了什么,真正的用户路径是什么,某些功能是不是真的在自嗨,而有些功能是不是必须要加上,要不然用户用不了了。
不过这类埋点从某种程度上来讲已经侵犯了用户隐私,现在对用户隐私保护越来越重视,我们也需要提前去了解下数据脱敏、用户授权等方面的知识,做好产品设计和用户调研之间的平衡。
(三)传说中的千人千面怎么操作
不知道大家第一次听到淘宝的“千人千面”的时候,有没有被震慑到。其实“千人千面”是靠一个个的用户数据堆积起来的,根据本人用户数据和操作数据来制定个性化推荐方案,来追求更高的购买转化比。
我个人猜测【千人千面】的数据基础主要有以下几个方向:
1、用户→商品;
2、商品→用户;
3、商品→用户→商品;
4、用户→商品→用户。
【用户→商品】很好理解,根据这个用户的个人信息,比如说年龄、有无子女、有无车,25岁以上且有小宝宝的,进口奶粉可以摆在首页了。
如果我们只获取到用户年龄(通过身份证获取),但是不知道有没有宝宝(CC这种剩女就经常遇到这种尴尬的事情,亚马逊老是给我推荐童书),那我们可以通过她购买的商品,比如说经常买进口婴儿奶粉、纸尿裤,来推测出她有没有宝宝,即达到【商品→用户】。
【商品→用户→商品】也是大家经常会碰到的,比如说你在亚马逊买书,详情页里面就会有【喜欢这本书的还看了】、【购买这本书的还买了】这样的推荐。这方面推荐做得比较出色的还有一些非电商平台,比如说流媒体平台奈飞和比我妈还懂我的网易云音乐,感兴趣的小伙伴可以去搜索下这两个平台的推荐策略。
最后一个【用户→商品→用户】就比较厉害了,比如说A是个26岁有个2岁宝宝的妈妈,她住在杭州,学历是本科,除了买进口奶粉外,她还特别喜欢买一个牌子的湿巾和童装,那么我们可以给一个同住在杭州28岁的本科宝妈推荐下这款湿巾和童装看看,因为这两个用户在很多地方是如此相似,说不定还share同一爱好呢,这就是淘宝“千人千面”的进阶版。
据说目前淘宝的【千人千面】考虑的维度还比较简单,试行的仅为年龄、性别和客单价这三项,但是我们在逛淘宝的过程中,已经会有心意相通的默契感了,说不定哪天你想买什么,打开淘宝它正好在你眼前也说不定。

最后再附上一份来自神策数据的教程,里面讲到了很多数据埋点不能不知的干货,大家如果想深入学习,可以去了解一下。
网址:https://www.sensorsdata.cn/manual/web_analytics_term.html
数据产品经理,或者数据分析师,亦或者其他产品同学,运营同学,一定离不开数据分析。而数据分析的基础,那就是数据。
互联网产品的数据主要途径为埋点和爬虫。爬虫目的一般为获取竞争对手的数据,埋点的目的一般为理解自身数据。以后我们介绍爬虫,这里,主要介绍埋点。
通常,埋点是研发的事儿,前端或者后端埋点。而数据PM或者数据分析师是拿现成的数据来写SQL、完成分析。
但是,一名优秀的数据分析师或者数据产品经理,可以根据埋点的质量来决定怎么使用埋点,在什么情况下用什么埋点数据会更贴近事实,从而在面对别人的质疑时,可以很自信地说你给出的数据是现阶段最可靠的,你的数据无可辩驳。
数据PM或者数据分析师,以及其他优秀的同学们,不会抱怨埋点质量差而影响了自己分析,反而应该想,我如何用好现有的埋点来找到最贴近事实的数据来支持我的结论,埋点质量在不断改进,但我不会等埋点。要永远敢于给出结论。(当然,很多PM,其实是不知道埋点竟然还有好处之分?)
我们一个一个介绍一下,不同的埋点策略是如何实现的。
当网站在吸引外部流量的过程中,如何评判从不同渠道跳转过来的流量效率?
我们举个例子,这个埋点,最早是Google Analytics,也就是GA,这一套埋点引申而来,埋在客户端。举例说明,从http://baidu.com搜索“booking”后单击第一个链接跳转后的url:https://www.booking.com/?aid=;label=baidu-brand-list1&utm_source=baidu&utm_medium=brandzone&utm_campaign=title。
其中:
·aid=是alliance id的简称,一般是企业内部对外投渠道的自定义编码,一般在自建的外放管理平台申请,设置跳转url来管理渠道。这里的是booking对http://baidu.com的渠道编码。如果和百度合作紧密,一个aid下面还有多个子id来区分和百度不同事业部的结算,比如百度地图、百度搜索、百度糯米等。但这里没有记录。
·utm_source=baidu指来源为baidu。
·utm_medium=brandzone指来源于百度的品牌专区。
·utm_compaign=title一般是活动类型,这里是代表直接搜索“booking”过来的流量。
这种埋点,一般是市场部申请好id,拿到url直接给流量方的对接人即可,不需要本公司开发资源介入。这个埋点,可以记录每个流量来源的投入产出ROI,这个产出可以是注册量,也可以是下单量或其他。流量主流结算方式是单击付费CPC,对于引流的价值需要在合理的区间才有长期合作的必要。
当我们想知道,每个页面的访问情况如何?停留时间是多少?就可以用到页面PV埋点了。产品经理一般只要把这个需求给到研发,让研发自己做就可以了。
页面埋点主要应用在如下两个方面:
·当作数据的基准(benchmark)。因为页面埋点格式最为简单,且触发逻辑简单,开发出错的概率最低,所以一般将其作为正常数据的基础。在通常情况下,各个埋点的数据是对不上的,需要找出一个基准,那这个页面埋点最靠谱,其他的如果偏离很大,就需要查找bug。
·通过触发时间差来计算页面停留时间。一般不会单独对页面停留时间埋点,因为正常情况下,下个页面和本页面的埋点触发时间差即为本页面的停留时间。而且为避免异常值干扰,停留时间在计算时一般取中位数,而非平均值。
这个埋点,一般能够包括以下字段包括:
·页面UV:按日对设备号去重。
·页面PV:计算访问次数。
·退出次数:计算从该页面离开网站的次数,用来衡量该页面的质量。
·退出率:退出次数/页面PV。
·页面停留时长:下一页面时间与本页面时间之差,一般取中位数。
这里,我们再聊一下,客户端和服务端埋点的区别,也就是前端埋点和后端埋点的区别。
一般情况下,页面PV和单击等跟用户交互的信息是放在客户端埋点,但也有公司将PV放在服务端埋点。两者的区别在于:客户端埋点一般为页面加载完成/离开的场景触发一次(刷新/回退可能都会PV+1),但是服务端是根据服务的次数来计算PV,如果一个页面是分批加载(另一种情况是,现在很多Hybrid是一个页面预加载,减少页面加载时的用户等待时间),那按照客户端来计算的1个PV,按服务次数来算可能是多个PV,在跨部门对比数据的时候需要和对方沟通清楚这些指标。你们是埋在哪里的,怎么定义的。
下面将区分native和hyrbid,虽然两者解决的业务问题类似,但方法上有较大不同。
比如,新的模块/功能上线后效果如何?有多少人单击这个位置?单击之后的转化率如何?下一步应该如何改进?这时候,就需要用到单击埋点native了。如果只是统计button的单击次数,开发就可以搞定,但如果是在此之外的内容,就需要产品经理在PRD中写明。比如电商中列表页常见的筛选button功能,如果只是筛选button的单击,可以计算“c_filter”的单击,但是如果想知道用户搜索过的内容,比如你有一个搜索框,你想知道用户搜索过什么内容,就需要在扩展字段中记录内容,而这些内容需要产品经理来指明。告诉研发,我要这个东西。
单击埋点native,主要应用在如下两个方面:
·按钮的单击情况。每个按钮的单击UV和单击次数PV。这里需要注意,单看按钮的单击次数的绝对值是没有意义的,需要跟其他按钮比是相对多还是相对少,以及这个按钮的设计初衷是希望用户多点还是少点,这个需要根据不同场景来确定。
·按钮之后的操作行为。更多情况下,产品经理想了解用户在经过这个按钮单击之后的行为和转化率,以及这个按钮有没有加速用户的购物流程。
一般来讲,hybrid开发团队和native开发团队相对独立,编程语言也存在较大差异,支持的业务方也有区别。hybrid一般常用于快速迭代的页面,比如活动页和后服务页面等。一般这个埋点,需要产品经理和研发沟通好,要埋哪儿,以及埋点的难度如何等等。
以某电商后服务页面为例,这些页面的单击后评价,可能是跨平台的行为参考,比如说售后来电数量的下降,针对这样的场景如何埋点,与native又有何异同点?
区别有两个:
·一般直接取用显示的模块/单击名。因为改版非常频繁,有时候文字也会稍微变动,这时候再用英文可能很难直观体现区别(比如“退票”和“退订”很难用英文来区分,用拼音的话还不如直接用中文),有的改版可能就是在文案上做AB测试,所以这里直接记录中文。
·记录订单信息。因为一般后服务页面常常跟客户投诉、客户来电等KPI挂钩,页面功能的设计大多数是为了降低投诉、降低客户来电、减少客服人工成本,所以常有“单击退货按钮后当天用户电话咨询数量”的监测指标需求。那一般是通过订单信息来做这样的关联,所以这个json数组中一般都要包含订单号,其他视产品经理要求而增加。
通过这种埋点,主要给页面的频繁改版提供方向和计算ROI,因为产品经理的需求改动需要计算出合理的价值,而后服务的价值就是这个功能的上线可以减少客户的通话时间,减少多少用户的时间,提升体验,换算出来的价值后再和其他项目PK,依靠结果来争取上线机会。页面上线后评估效果是否符合预期,值得深入细化还是改变方向。这也是数据给产品迭代提供支持的有效例证。
业务埋点常常是因为业务需求而制作,记录业务相关埋点。这种埋点,一般都是产品经理提需求,BI出面制定规则、出方案,由开发执行。流程比较多,是因为这个埋点很复杂,所以需要多方面协商沟通好。
这个埋点有什么用呢?比如,我想知道每个单击之后的转化率,有没有可能把一个用户的每个单击信息都带到订单完成页?就是需要用到业务埋点了。
最主要的场景是利用该标志位细分人群,针对这些人群看一些指标以及针对性做些改进。比如说首页勾选婴儿的人可以理解为“携带儿童者”,转化率相比商务出行转化率如何,流程痛点在哪里,如何评判针对性改进的效果等,都可以利用这个标志位从开始到下单所有页面的转化情况,以及单击情况拎出来淡出分析,这是精细化运营和产品迭代的利器。
要注意的是,业务埋点与PV埋点的不一致。业务埋点一般是在用户离开页面的时候记录信息,理论上应该与页面的UV和PV是一致的,但因为该埋点本身比较复杂,且由于触发机制的问题,会存在5%左右的差距,但是一般这个埋点多用于计算细分人群的转化率,所以分子分母同时缺失对转化率计算是没有影响的。但如果说要单独计算UV和PV,需要考虑到这5%的差异(如果能推动开发查到问题所在,也可以消除这其中的差距,这当然是最好的解决方案)。
曝光其实是控制流量的主要手段,原因是这样子的,对于产品来说,流量分配其实是曝光的分配。曝光埋点理论上与单击埋点可以放在一起,区别对待的考量是如果流量消耗太大,就会出现浪费。=
举个例子,对于app来说,无论是native还是hybrid,曝光是对所有展现内容进行记录并上传,而这些数据本来就是下载到手机端,再从手机端上传,从流量的角度看是非常大的浪费,所以曝光的埋点一般从服务端来埋,不走客户端。也因此,这个埋点,一定要PM和研发沟通好。
以OTA为例,最重要的场景是选择不同的产品排序,不同的产品排序,对整体转化率和利润的影响不同。对不同的供应商的产品进行包装后卖出,在不同的排位上转化率肯定不同,位置变动后此消彼长的转化率对整体的转化率的影响情况,以及对于整体利润的影响情况,这是核心关注指标。曝光埋点,辅之以各种AB Test就可以帮助业务方来做决策。
要记得一点就是,服务端埋点的PV和页面PV一般是对不上的,因为页面PV=1代表访问1次,而服务端PV=1代表页面服务被调用一次,如果一个页面调用多个服务,尤其是在分批加载的时候,两者是明显对不上的。理论上服务端埋点会比前面所述的客户端埋点(包括单击埋点和页面埋点)准确,因为相比客户端,服务端一般人数较少(不用区分是Android或是iOS),会比较少犯错误,实际上也确实是这样。
以上,就是平常会用到的埋点策略了,如果大家遇到更多的情况,我们也可以一起讨论。欢迎作为补充和交流。
来到公司第一件事,就是研发公司自己的埋点
为什么要研发自己的埋点
1、第三方埋点存在数据泄漏风险
2、第三方埋点无法支持之后的数据驱动,之后的AB测试系统,用户画像都需要我们自己的埋点才能实现
3、第三方埋点经常出现数据上报错误
4、第三方埋点每年支付大量现金
···
基于以上各个原因,开始开发自己的埋点
接下来通过以下三个方面讲解一下自研埋点
埋点埋什么取决于我们想从用户身上获取什么信息
一般主要分为用户的基本属性信息和行为信息
用户的基本属性信息主要包括:城市、地址、年龄、性别、经纬度、账号类型、运营商、网络、设备等等
行为信息即用户的点击行为和浏览行为,在什么时间,哪个用户点击了哪个按钮,浏览了哪个页面,浏览时长等等的数据。
以上说的就是一个简单的报文:
什么是报文
报文(message)是网络中交换与传输的数据单元,即站点一次性要发送的数据块。报文包含了将要发送的完整的数据信息,其长短很不一致,长度不限且可变。简单来说就是用户在App内有一个操作行为,就会上报一组带有数据的字段。这些字段组成一个报文。报文一般包含以下字段,简单举例,根据公司业务自行增删
{ "os": "js",
"os_vers": "端上的OS版本",
"dev_id": "设备id",
"model": "设备型号",
"manufacturer": "设备制造商",
"proj_id": "工程id",
"source": "渠道输入数字:1android_2ios_3H5_4小程序_5微信_6服务器后端_7_100其它",
"proj_ver": "软件版本",
"up_time": "报文上传时间-毫秒时间戳",
"face_id": "事件全局唯一标识",
"accs_time": "事件发生时间,毫秒时间戳",
"serv_time": "服务器时间,毫秒时间戳",
"event_type": "view/click", "event_ver":"业务版本/事件版本
"ip": "290.39.55.75",
"longitude": "56°75.343",
"latitude": "143°07.230【非必填GPS关闭无法获取】",
"netwk_typ": "wifi/4G" },
"refer_id": "无埋点场景下所浏览页面的上一个页面的唯一标识",
"duration": "页面浏览毫秒数,关闭页面时统计",
"banner_id": "埋点自定义事件属性值",
"banner_name": "埋点自定义事件属性值",
"banner_type": "埋点自定义事件属性值",
"banner_city": "埋点自定义事件属性值" },
"usr_props": { "gid": "游客id", "uid": "登录账号", "province": ‘上海’】",
"city": "北京",
"city_code": "110",
"age": "22",
"sex": "1男_2女",
"phone": "",
解释一下这些报文的意思
1) trace_id为每个事件的全局唯唯一识别符,trace_id=md5(proj_id+source+accs_time+"salt盐")
- proj_id为工程id,accs_time为端上行为时间
- source为渠道来源:1android_2ios_3H5_4微信小程序_5微信环境_6服务器后端(只填数字)
2) 请求为post提交方式,header中需要添加:projId,source,upTime,uploadId 四个参数,uploadId=md5((projId+source+upTime+"salt盐")
- proj_id为设备id,upTime为上传时间
- source为渠道来源:1android_2ios_3H5_4微信小程序_5服务器后端(只填数字)
- 由于nginx中lua编程接收参数自身原因,header中的参数只能使用驼峰 projId,source,upTime,uploadId
- salt测试环境下为:test,salt正式环境下为:p1@PeFz4ZX
3)uid值在游客状态下为空,登录状态下有值;dev_id值在任何情况下都得传4)上面的报文为一次上报的报文格式,data中可以包括多次事件的信息5)基于客户端每次要使用客户流量才能获取$province,$city,ip,这三个字段保留,但是值为非必填。最终由后端根据请求ip和经纬度计算省市信息。6)报文中的json的所有的key可以不能遗漏,即使是value为空,如果是空值要用双引号"",不要用null。7) proj_id、sdk_ver、event_id,业务属性,必须按照产品需求保证对应关系,否则上报的数据会被丢弃。
在埋点设计时,要将客户端、m站等平台中
全部的页面及按钮按照规律清晰的罗列出来,
并为每个页面,每个按钮配置唯一的id
以此来区分每一个页面及按钮
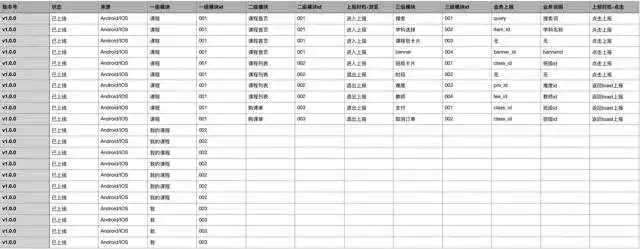
以下埋点需求表仅供参考
这个埋点表中
第一列是App版本号
第二列是埋点上线状态
第三列是安卓或者ios端(因为有一些交互安卓与ios不同所以要做区分)
第四列是一级模块
这里直接说一下一级模块、二级模块、三级模块
一级模块
是指App下方的几个大的button即页面入口。
培优学而思App的 首页、选课、服务、我
是四个一级模块,每个一级模块都有自己的一个唯一id
图中一级模块是选课,id是固定的“11”
二级模块
是指一级模块下的全部页面
不仅仅是入口页面
入口页面下的 点击跳转的页面都算一级模块下的二级页面
比如课程列表页、详情页、购课单页、banner详情页····
每一个页面都有一个唯一id,这个id组成是该页面的一级页面id与页面id串联
图中选课首页的id为11-001、列表页id为11-002、详情页id为11-003···
这样给定一个id就可以查到唯一指定页面
三级模块
是指二级模块全部页面中的全部按钮
每一个按钮都有唯一一个id,这个id组成是一级模块、二级模块、三级模块的id串联
图中搜索框点击事件 11-001-001,
其中11是指选课一级模块
其11-001是指一级选课模块下的选课首页
其中11-001-001是指一级选课模块下的选课首页的搜索框按钮
这样每一个页面每一个按钮都有条理的排列下来了
其中bizinfo是业务字段
业务字段
是在用户点击或者浏览页面时上报的业务数据
比如banner点击事件,用户触发此事件需要上报banner-id,banner名称,banner城市、banner年级等
比如报名按钮点击事件,业务字段上报toast_value,这个toast_value是指用户点击报名按钮后的页面提示
可能是年级不匹配导致报名失败,可能是没有入学诊断导致报名失败,也可能报名成功
收集这样的业务字段为之后的业务数据分析提供保障
其实埋点表还需要有上报时机
这个上报时机是指用户在点击或者浏览页面后什么情况下进行埋点上报,存到数仓中
上报时机一般分为点击即上报 还有回调上报
点击上报很好理解
回调上报是指用户在点击或者浏览页面后有一个返回值,一般是由toast提醒后进行上报
通过设计如图的埋点表
进行需求评审
评审通过之后将其维护到业务库中
埋点系统主要功能
1、维护埋点事件及埋点事件ID。
比如我们增加了一个页面以及页面上全部的按钮,按钮点击之后的下一级页面
那我们需要生成好多埋点id
这个声场埋点id的功能就在系统中进行维护
2、数据异常报警
对于一些埋点数据不能正常上报,或者因为其他原因导致埋点数据丢失
通过埋点系统直观查看哪些点没有正常上报,第一时间进行检查
数据从上报开始——Nginx——Filebeat——Kafka——Spark——Kudu
- DB 是现有的数据来源(也称各个系统的元数据),可以为mysql、SQLserver、文件日志等,为数据仓库提供数据来源的一般存在于现有的业务系统之中。
- ETL的是 Extract-Transform-Load 的缩写,用来描述将数据从来源迁移到目标的几个过程:
- Extract,数据抽取,也就是把数据从数据源读出来。Transform,数据转换,把原始数据转换成期望的格式和维度。如果用在数据仓库的场景下,Transform也包含数据清洗,清洗掉噪音数据。Load 数据加载,把处理后的数据加载到目标处,比如数据仓库。
- ODS(Operational Data Store) 操作性数据,是作为数据库到数据仓库的一种过渡,ODS的数据结构一般与数据来源保持一致,便于减少ETL的工作复杂性,而且ODS的数据周期一般比较短。ODS的数据最终流入DW
- DW (Data Warehouse)数据仓库,是数据的归宿,这里保持这所有的从ODS到来的数据,并长期保存,而且这些数据不会被修改。
- DM(Data Mart) 数据集市,为了特定的应用目的或应用范围,而从数据仓库中独立出来的一部分数据,也可称为部门数据或主题数据。面向应用。
数据仓库(Data Warehouse) 简称DW,顾名思义,数据仓库是一个很大的数据存储集合,出于企业的分析性报告和决策支持目的而创建,对多样的业务数据进行筛选与整合。它为企业提供一定的BI(商业智能)能力,指导业务流程改进、监视时间、成本、质量以及控制。
数据仓库存储是一个面向主题(移动的用户分析也可做为一个主题)的,反映历史变化数据,用于支撑管理决策。
特征:
- 效率足够高,要对进入的数据快速处理。
- 数据质量高,数据仓库是提供很多决策需要的数据支撑,DW的数据应该是唯一的具有权威性的数据,企业的所有系统只能从DW取数据,所以需要定期对DW里面的数据进行质量审,保证DW里边数据的唯一、权威、准确性。
- 扩展性,企业业务扩展和降低企业建设数据仓库的成本考虑
- 面向主题,数据仓库中的数据是按照一定的主题域进行组织的,每一个主题对应一个宏观的分析领域,数据仓库排除对决策无用的数据,提供特定主题的简明视图。
- 数据仓库主要提供查询服务,并且需要查询能够及时响应
- DW的数据也是只允许增加不允许删除和修改,数据仓库主要是提供查询服务,删除和修改在分布式系统.
操作性数据(Operational Data Store) 简称ODS,作为数据库到数据仓库的一种过渡形式,与数据仓库在物理结构上不同。ODS存储的是当前的数据情况,给使用者提供当前的状态,提供即时性的、操作性的、集成的全体信息的需求。ODS作为数据库到数据仓库的一种过渡形式,能提供高性能的响应时间,ODS设计采用混合设计方式。ODS中的数据是"实时值",而数据仓库的数据却是"历史值",一般ODS中储存的数据不超过一个月,而数据仓库为10年或更多。
特征:
- ODS直接存放从业务抽取过来的数据,这些数据从结构和数据上与业务系统保持一致,降低了数据抽取的复杂性。
- 转移一部分业务系统的细节查询功能,因为ODS存放的数据与业务系统相同,原来有业务系统产生的报表,现在可以从ODS中产生。
- 完成数据仓库中不能完成的功能,ODS存放的是明细数据,数据仓库DW或数据集市DM都存放的是汇聚数据,ODS提供查询明细的功能。
- ODS数据只能增加不能修改,而且数据都是业务系统原样拷贝,所以可能存在数据冲突的可能,解决办法是为每一条数据增加一个时间版本来区分相同的数据。
数据集市(Data Mart)简称DM,是为了特定的应用目的或应用范围,而从数据仓库中独立出来的一部分数据,也可称为部门数据或主题数据(subjectarea)。在数据仓库的实施过程中往往可以从一个部门的数据集市着手,以后再用几个数据集市组成一个完整的数据仓库。需要注意的就是在实施不同的数据集市时,同一含义的字段定义一定要相容,这样再以后实施数据仓库时才不会造成大麻烦。
数据集市,以某个业务应用为出发点而建设的局部DW,DW只关心自己需要的数据,不会全盘考虑企业整体的数据架构和应用,每个应用有自己的DM
特征:
- DM结构清晰,针对性强,扩展性好,因为DM仅仅是单对一个领域而建立,容易维护修改
- DM建设任务繁重,公司有众多业务,每个业务单独建立表。
- DM的建立更多的消耗存储空间,单独一个DM可能数据量不大,但是企业所有领域都建立DM这个数据量就会增加多倍。
本文由 斑马 原创发布于产品壹佰平台,未经许可,禁止转载和商用。
有兴趣的小伙伴,可以产品经理的这篇文章
高玮的产品思维:产品经理的职业发展:低确定区域的高确定性
前言目录
- 以始为终,澄清问题与需求;
- 思维混乱,分解聚合很关键;
- 输出文案,清楚明晰易看懂;
- 埋点校验,SQL平稳教过渡;
- 追求卓越,理论管理两不误;
理论准备
- SDK:相当于开发集成工具环境,通常在客户端部署SDK代码,当用户行为触发预定义事件后,会自动存储上报事件点;
- Kafka:分布式的基于发布/订阅模式的消息队列,用于大数据实时处理领域;(后续文章详细描述)
接下来将会对埋点全流程作详细阐述,让我们开始进阶之旅:
在埋点工作正式开始之前,需要根据实际业务情况,确定好埋点需求的出发点至关重要,不仅方便后续埋点维护,更方便日常的数据统计分析工作,抛开理论,以实际埋点为例(不懂参数设定不要紧,后面详细说明)
提示:涉及的字段囊括范围,页面停留时长计算方式等都会详细列出;
广告(Ad)埋点
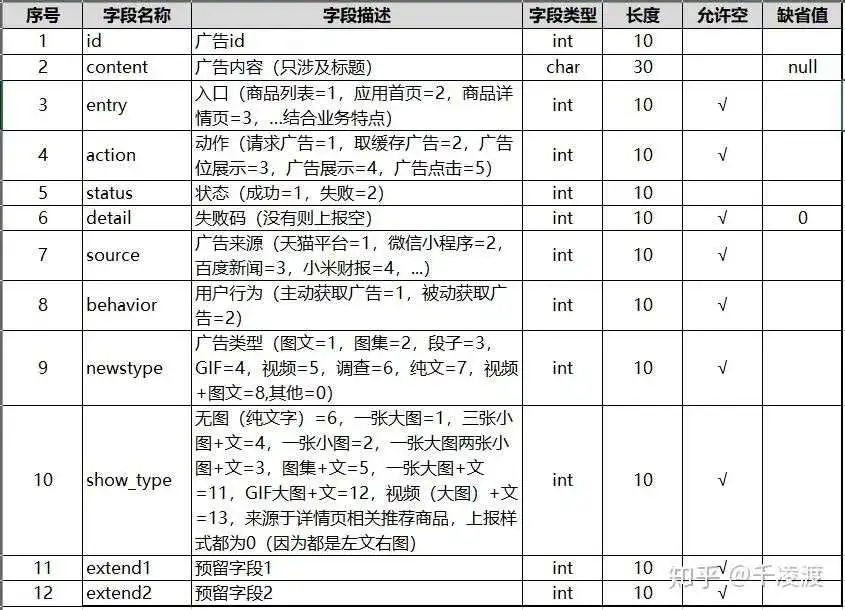
其中,涉及具体业务需求的字段有:entry,source,newstype,show_type,extend等;
- entry涉及到目前现有业务所有广告入口,必须针对业务实际情况罗列;
- source涉及广告对外投放平台,必须针对业务实际情况罗列;
- newstype涉及广告在各入口,各对外投放平台的内容形式;
- show_type涉及广告在各入口,各对外投放平台的展示形式;
- extend1/2为应对产品不断变更的需求增设的预留字段,根据具体业务添加;
内容列表页加载埋点(loading)

其中,涉及具体业务需求的字段有:type,status,extend等;
- type涉及业务中所有的列表页加载方式,通常有底部点击加载、顶部下拉加载、加载按钮、回到顶部自动刷新加载、底部触发加载(内容瀑布流)等
- status涉及业务中所有设定的已知加载错误状态码,通常包含:网络中断、网络异常等等;
- extend1/2为应对实际业务新增设的预留字段,根据具体进行添加;
内容点击(display)
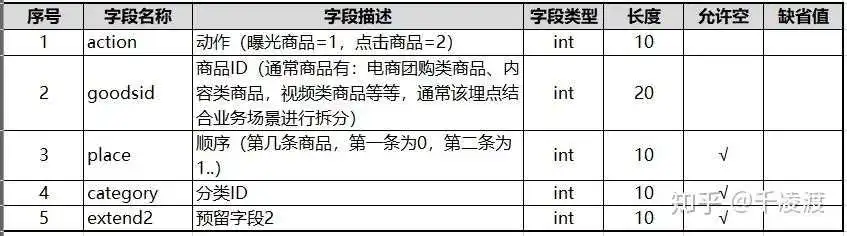
其中涉及具体业务需求的字段有:goodsid,category,extend2等;
- goodsid涉及业务中商品的具体形态,如视频,电商团购商品,内容,课程等等,根据具体的类目指定各自的内容点击(display)数据点字段;
- category涉及商品的分类,像传统电商有三级分类展示;
- extend1/2为预留字段,根据实际业务新增;
内容详情页(detail)
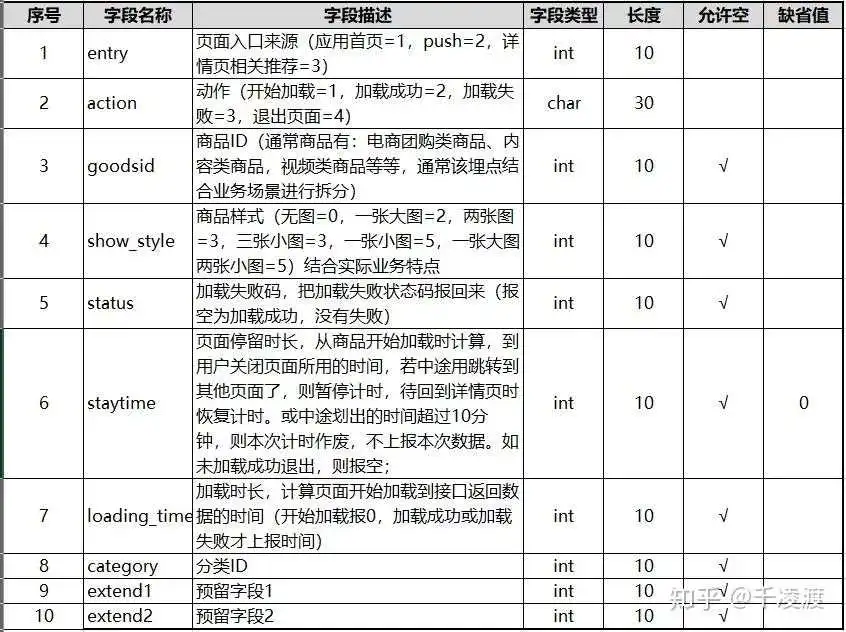
其中涉及具体业务需求的字段有:entry,goodsid,show_style,status,category,extend1/2等;
- entry涉及业务中所有能够进入到商品详情页的位置,类似自身业务广告入口来源,对比理解其实不是很难;
- goodsid涉及业务中所有的实体/虚拟商品ID,最好结合业务对该点进行拆分,不要混为一谈;
- show_style涉及商品在详情页中的展示形式,涉及具体业务可能会明显有所不同;
- status涉及业务中所有设定的已知加载错误状态码,通常包含:网络中断、网络异常等等;
- category涉及商品的分类,像传统电商有三级分类展示;
- extend1/2为预留字段,根据实际业务新增;

凌晨一点了,写的有点累,此外涉及的消息通知、用户前台活跃、用户后台活跃、评论、收藏、点赞、错误日志、启动日志数据等评论区留言,后续慢慢补充,等不急也可以在评论区留言,单独发送;
问题1:刚接手公司前任数据产品经理的埋点文档,如何迅速从需求触发,理清埋点业务框架?
- 用Xmind绘制公司产品架构图,方便从整体上宏观把握业务体系;
- 将旧文档中埋点与产品架构图作对应,找出盲点以及残缺,进行针对性标记;
- 针对旧文档文本表述,利用测试环境设备进行测试,校验数据点是否准确无误;
- 旧数据点有误或者旧文档描述与实际测试结果有差异,及时对埋点文档更新,邮件同步相关人员;
问题2:理清埋点业务框架后,发现数据点不准,该如何处理?
- 首先,根据数据统计,判断是单个或者某个业务相关数据点不准确(远低于99%),还是整体数据都不准确;
- 如果是单个/某个业务相关数据点不准确,可以寻找开发工程师抓取客户端回传数据包和服务端接收数据包比对,查看是否存在丢包问题;
- 如果是整个业务数据点都存在异常,则需要开发工程师检查埋点SDK以及服务器网络稳定性问题;
- 以上两种都排除以后,仍然问题存在,需要数据产品经理与开发工程师详细核对触发逻辑,受个人技术限制,也可以寻求稍微资深的开发工程师寻求帮助,一起检查代码问题;
- 注意:类似神策和诸葛IO等SaaS平台都设计有数据管理功能,对上传接口数据点是否入库以及数据安全性和准确性作校验,检查相关数据点是否被禁用;

问题3:接收数据埋点错误,要不要和开发开会,会不会得罪人,私底下解决可好?
数据产品经理应该对自己所负责数据流负责,出现了任何问题都得去理性,冷静面对;如果开发工程师因为排期问题得不到解决,可以寻求开发领导的协调,数据作为公司业务线的核心驱动力,其重要性可见一斑;勇于承担责任与义务,难的不是技术而是沟通;
那么在了解业务后,梳理接下来需要面对的实际需求:
- 从采集位置上划分为:前端埋点、后端埋点;
- 从功能需求上划分为:业务埋点、监测埋点;
- 从业务路径上划分为:路径埋点、独立埋点;
- 从表现形式上划分为:显性埋点、隐性埋点;
- 从组合形式上划分为:聚合埋点、单一埋点;
- ...
二、思维混乱,分解聚合很关键
在面对数据埋点是,是否点越多越好?
像第一节表格内容一样,你可能对数据点有了充分的认识,大多数情况下,数据点都不是孤立存在的,而是一个业务、功能、性能调优等集合,如何理解数据点为什么要聚合,就得介绍下数据在数据仓库中如何利用:(数仓设计以及背后的技术问题,后续文章更新)
数据仓库通常分为:ODS、DWD、DWS、ADS;
- ODS(operation data store)原始数据层:存放原始数据,通常这一层数据要做备份,防止数据丢失造成无法挽回的结果;(2020年2月25日发生的微盟数据事件足以证明ODS层的重要性)
- DWD(data warehouse detail)明细数据层:与ODS结构和粒度一致,只不过进行了数据清洗;
- DWS(data warehouse service)服务数据层:聚合到用户当日,商家当日等粒度,通常会以某一个主题为线索,组成跨主题的宽表,比如一个用户ID串联该用户的所有操作行为记录及业务数据;
- ADS(application data store)数据应用层:为统计报表提供数据,通常为DWS层数据组合;
数仓开发中涉及的业务表和事件表众多,不可能对于某一个新增需求不考虑其可复用性和扩展性需求,所以在设计时,尽可能合并相关业务点,方便数仓开发工程师利用事件表对数据仓库进行业务梳理分层设计;
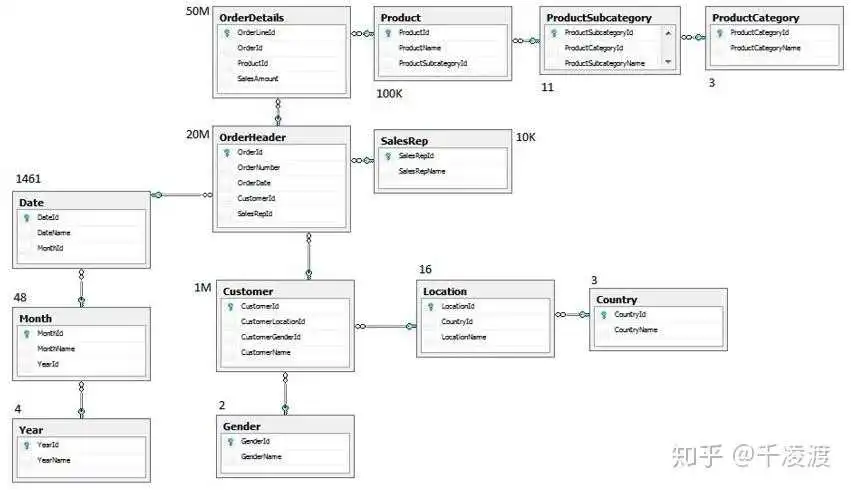
数据仓库各层包含哪些数据,以及这些数据到底如何组织,可以参阅下图。
有了对数据仓库的认识,相信你对如何设计前端业务埋点有了基本的了解,那么接下来介绍如何输出文案,方便技术理解;
三、输出文案,清楚明晰易看懂
输出文案可以向第一节表格内容呈现,但是实际解决问题过程中,面临多个问题需要思考:
- 如何设计埋点,埋点都是由哪些构成的?
- 每次更新文档都比较烦,找不到以前是否埋过这些点?
- 如何成有效管理埋点,产品的进度太快,很多时候研发在埋点文档中看不到哪些是新增的?
- 前端埋点依赖发版,如果多个版本相同埋点参数不一致,怎么能够更好管理埋点?
- 研发不清楚前端页面具体埋点位置,通过单一文档无法识别,如何能更高效输出文档?
- 聚合的埋点在各业务场景中是否存在不同,如何能够更好的说明埋点的参数不同?
- 不懂开发,能不能有一个好的工具方便我管理自己设计的埋点,传统excel在埋点较多时不方便寻找管理?
你是否有过这些疑问,在埋点之初这些问题会一直困扰你,特别是在业务量庞大时,需要的埋点更是难以高效管理版本迭代情况,那么对于追求卓越的数据产品经理,我们如何才能解决业务问题;
根据自己的经验,我设计了一套以Axure为原型的埋点管理系统(需要的私信),能够方便我解决以上的所有问题,因为涉及到具体业务,所以我对原版本进行了大量删除,只保留部分业务作为讲解:
 Axure数据埋点管理系统设计https://www.zhihu.com/video/
Axure数据埋点管理系统设计https://www.zhihu.com/video/
数据埋点管理的功能做简要介绍:
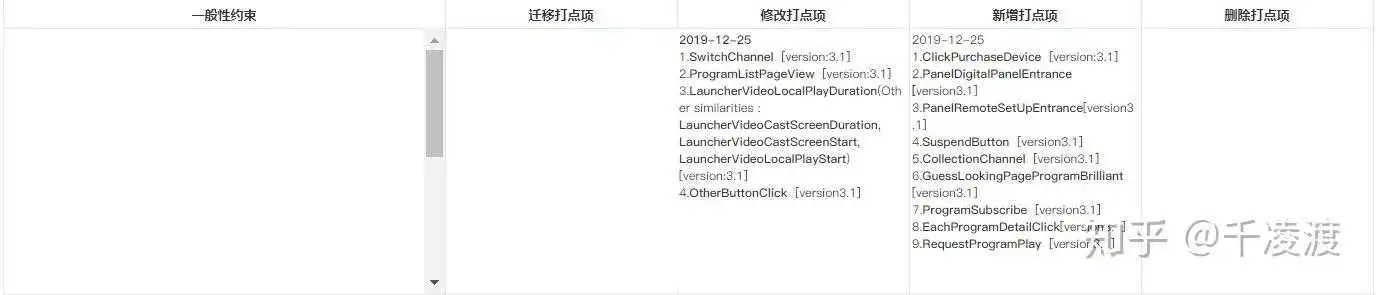
数据点增/删/改记录部分
这部分通常展示当前数据点命名规约,以及旧系统迁移打点,新系统新增、修改、删除打点项,而且Axure自带免费发布功能,能够及时的同步所有修改内容;
搜索功能
通过设置的内置搜索功能,能够方便快速定位到“数据点增/删/改”部分相应变更点;
数据点版本详细描述
通过记录数据点各版本字段保留以及详细说明,一方面方便研发开发,另一方面及时掌握数据点变更原因,变更前状态,有效溯源历史业务场景,管理更加高效便捷;

数据场景描述
针对某个组合数据点出现的业务场景,统一做罗列,很多情况下并不是所有的字段都是可缺省的,根据实际业务的组合场景更加普遍,所有有效的文档才能减少与开发沟通,提高工作效率,目前我的文档不会再和开发详细对细致内容,减少了相互之间宝贵的时间,提高产能;
四、埋点校验,SQL平稳教过渡
介绍了埋点以及埋点的管理,接下来针对用户操作行为数据验证埋点准确性提供几种方法:
- 通常情况可以让测试人员提取客户端上传埋点日志文件和服务端接收日志文件作对比,观察两者是否存在丢包情况;
- 通过在数据库中自查,验证埋点是否已经正确上传:
SELECT 埋点名称 FROM 事件表 WHERE time >= '2019-03-01 00:00:00' AND time <= '2019-07-07 23:59:59'3.检查转化流程中是否存在明显数据异常(以电商为例):
从用户行为中取,下单人数(只要下单次数>0),支付人数(只要支付次数>0),再从日活跃数表中取活跃人数,然后对应的相除就可以了。SQL可以后台回复;
五、追求卓越,理论管理两不误;
简要的数据埋点格式可以参照以下图进行理解:

通过大数据处理、数据统计、数据分析、数据挖掘等加工处理,可以得到衡量产品状态的一些基本指标,比如活跃、留存、新增等大盘数据,从而洞察产品的状态。此外更重要的是随着数据挖掘等技术的兴起,埋点采集到的数据在以下方面的作用也越来越凸显:
驱动决策:ABtest、漏斗优化、用户增长、bug修复、精准营销、流失用户预警
驱动产品智能:智能推荐、场景化提示等
驱动安全:风险识别

五点了,睡觉往后章节会给大家详细介绍数据仓库、数据挖掘算法、SQL高级查询、Python/R与数据挖掘文章,更好的以实践为驱动力,快速成长;
可以私聊我教你PPT也是可以的,对内对外都是必备技能,放几张自己做的胶片:

埋点文档的撰写,各家规范要求各不相同,但是我们理解它的核心后其实都能快速上手。
撰写埋点文档这不是一个人就能完成的工作,撰写的时候,我们需要去请教数据分析师和前端后端研发,大家一起来确立明确的指标,并且让这份文档有可读性而不是自嗨性。
搜索埋点文档,我们都可以搜索出一大堆相关的文档方案。这些方案确实是有用的,但是却忽略了大部分产品本身没有技术背景,很难去看懂或是理解这些文档。
同时大部分公司也不需要那么复杂的埋点文档用于管理埋点,因此对于埋点文档我们理性看待,不要为了装逼而装逼。
工作中,埋点数据需求量最大的无疑是产品的营销运营。这类营销运营会分为常态化专题运营和热点营销活动两类。
常态化运营特点是短平快,要周期性的更新活动主题和内容,核心目的是稳固影响力。热点营销活动主打的是以近期热点作为主题,进行以业务目标为导向的活动。
在这种日常活动中就不适合使用那种完整的埋点文档,我们只需要在需求文档中简单的写明你需要的数据,交付给研发的时候在特别说明下即可。
例如:本次埋点需求
1、统计页面PV(点击浏览量)和UV(去重后的点击浏览量)
2、统计页面中A、B、C、D四个按钮的点击量(点击的PV)和点击人数(点击的UV)
3、统计本次活动的业务订购量
甚至可以让研发单独将这部分写成插件,后续活动直接调用即可,这也花不了多少的时候。这样一个能用的埋点需求就完成了。而接下来的实施部分,可以直接交给研发进行处理,你可以在随后的环节中和研发进行讨论确认一些细节。

例如:记录UV的时候,我们是用什么来作为唯一凭证?
1、手机号:实际能够接收到短信的手机号为准。但会因为需要接受验证码或要求登录从而对参与性要求较高。
2、IP:当前用户访问页面时所在网络的IP地址,会因为切换网络或使用代理进行变更。
3、Cookie:浏览器内保存的标识,包含用户私密信息,可通过服务器进行修改生成,但因大部分手机浏览器不支持而局限。
4、IMEI:移动设备的身份证,具有唯一性。一般需要使用app去获取安卓设备的底层权限。网页H5获取使用。在iOS设备上无法获取。一遍手机都可以修改,需要获取root(最高)权限,在使用软件修改即可。
5、DeviceCheck:iOS设备特有唯一设备码,之前使用uuid,但是因为苹果隐私问题iOS6后就禁止使用了。这个唯一编码只要不退出苹果ID并还原设备,就不会重置,唯一性较高。但是相同的问题,需要app去获取权限,很多H5并不支持。
注:唯一标识,是需求系统的核心指标,常用来作为推荐系统、数据系统等的唯一标识。
相比较上面十分随意的埋点需求描述,在大公司面对完善的产品时,因为需求构建复杂的分析体系,就需要使用有深度规范的埋点文档进行管理,以便更好的在各层次中对埋点的理解达成一致。
所以复杂专业的埋点文档一般是公司体系大,产品完善度高的公司才会使用。
我们常见埋点文档中出现String、bool、key、value等类型注名,但并不理解他们的含量,这先做一个简单的讲解。
1、String(字符串):表现直接存储一段文本内容,可以是中文,也可以是英文。我们可用来记录用户搜索的内容获取发表的内容。
2、bool(布尔):只能表示true(是)和false(否)。我们已经用户记录用户是否点击按钮。
3、int(整型):记录自然数,从-2,147,483,648到2,147,483,647之间的数都可以使用。
4、float(浮点):这也是我们常说的小数点如1.21、5.20、13.14等等。
除了上面4个类型以外其实还有long、char等等类型,但是为了实用性,我们只要了解上面的4个类型,基本对我们撰写文档来说就没太大的问题了。
在撰写较为专业的埋点文档的时候,我们都需要基于需求去撰写。例如:我们的目标是想了解一段时间内我们的app使用率是否处于正常水平了解app(H5页面)的唤醒(打开)率以便评估是否处于均值。有了目标之后就进入第二部分事件拆分。为了完成我们的目标,用户会经历哪些操作事件?
我们一一进行拆解。首先用户会先拿出手机,其次打开或登录我们的app(页面),最后再进行其他的浏览、购买行为。
到了这里这就是一个十分简单的登录(浏览)事件,有了事件接下来就需要我们明确数据指标。在登录(浏览)事件中,我们首先要梳理的是哪个指标可以作为用户在我们系统中的唯一标识。
有了标识后我们要明确用户什么样的行为算一个有效的登录,是只需要打开app、加载页面就算,还是需要进行后续滑动、点击等交互行为后才算。这两个确定后我们就可以撰写文档了。
文档撰写每个公司要求都不一样,但是我们按照“便于理解”,“避免争议”的逻辑去写问题就不大。我们先将他们进行分类,本次埋点属于登录(浏览)事件,我们是以用户是否成功浏览页面作为评判标准,那么我们他们归于页面浏览这一大类中。
随后我们进行细化,页面的浏览也会因为页面的繁多而混杂,这里因为我们属于首页内容的浏览,因此它的第二类就算首页页面。有了这两个分类,我们就可以在后续有需要查询埋点的时候快速理解定位埋点,随后就是具体的埋点参数了。
这里假设我们使用IMEI作为用户唯一标识,之后因为我们是需要通过登录情况去了解我们的用户,这里我们可以判断她是否是首次登录,用于删选重复登录的用户,这样一个简单的埋点文档有雏形了。

同时因为代码是字母编码,所以我们要将文档中的中文名称给确定一个英文名称,这样我们后续就知道埋点在系统中叫什么。不然直接给中文,可能会因为每个人英语水平问题,造成埋点名称各不相同。例如手机号我取名叫number,你取名叫iPhone,他取名叫Telephone number这就乱了。因此我们最好加上他们的英文名称。

到后去业务埋点需求越来越多之后,我们的埋点会越来越多,最后在没有更好的管理下,直接每次找埋点找的崩溃。
所以我们不时对埋点进行整理,将通用的数据进行抽离,将他们单独抽离出来,抽离后形成一张新表,代表每个埋点在搜集数据时,都需要同时收集这张表上的预置内容。
这样后续我们只要慢慢根据我们的目标进行完善埋点即可。
除了预置属性以外,我们要需要一个代码类型《键值对》(我们理解为一个主键一个数值对应)。为什么理解?因为就算使用预置属性我们还是会面对埋点数据过多的问题,因为一个成熟产品最少都拥有10个以上的页面,更别说更加成熟产品了(淘宝、拼多多)。
面对大量页面不同,统计数据相同的埋点,我们要选择一套高效的管理手段。所以我们需要了解《键值对》(方法都是方便文档管理,而实际数据库存储是由研发设计规划,所以建议及时和研发进行沟通)。
键值对:按照名称,key值,value值进行存储。其中一个名称对应多个key值,一个key值对应多个value值,这里不想去理解key和value代表什么,毕竟我们不是研发。我们只需要他们所对应的格式即可,就像一级分类,二级分类,三级分类一样。
例如:
页面浏览(键值对的名称)— 首页页面(键值对的key)— 访问次数(键值对的value)
页面浏览(键值对的名称)— 详情页面(键值对的key)— 访问次数(键值对的value)
页面浏览(键值对的名称)— 购物车页面(键值对的key)— 访问次数(键值对的value)

(我这种方式我感觉只是文档管理方便,对于研发来说,还是需要看需求是否只是需要总数还是详情来设计数据库存储,一样麻烦。)
埋点文档其实没你想象中那么难,也没你想象中那么简单。现在有太多的数据平台,神策、诸葛io、友盟、growingio等等,都是一套的解决方案,从采集到存储以及分析可视化等等。
所以其实去了解下他们的分析解决方案即可,没必要自己进行搭建整个一套,就像我开头说的,如果只是日常需要,就直接写想要什么数据给到研发就行,强行搭建费时费力,并且还不一定好。如果真要搭建那么还需要你多和研发进行沟通,毕竟代码是实现功能的基础。
-END-
作者:wcof,在努力做产品不做产品经理的人
在互联网行业,产品经理、数据分析、运营同学经常会给开发同学提各种埋点需求,有些需求做起来让程序同学直呼头疼,那么为什么要提这么多复杂繁琐的埋点需求呢,今天我们就聊下埋点在游戏行业的应用,以及利用埋点数据能做哪些游戏数据分析。
一、游戏中埋点目的:
收集用户的行为数据,上报给可视化后台,为产品优化做数据支撑服务。
二、埋点在游戏中有哪些应用
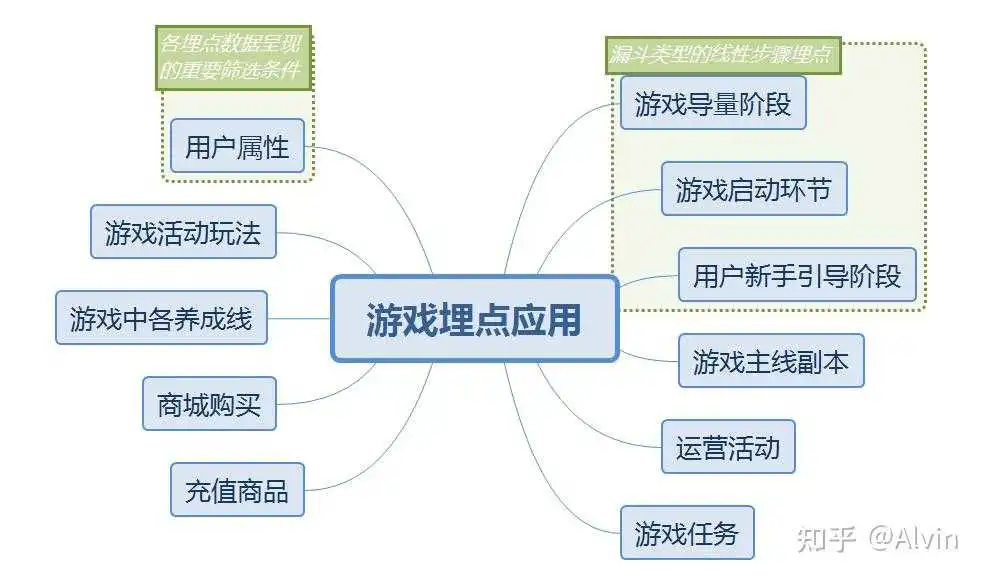
三、埋点内容详情:
1.游戏买量阶段的埋点应用
- 埋点内容:记录广告页面触达的用户、广告的点击数据、点击下载安装的用户、安装完成用户数
- 埋点作用:通过埋点我们可以得出两个重要指标点击率和下载率,这两个指标直接跟投放素材的质量有关,直观的反馈了素材的吸量程度,以及平台用户的属性匹配度,有了这些数据可以让买量同学及时切换买量素材,调整投放策略。
2.游戏启动环节的埋点应用
- 埋点内容:记录游戏启动、请求版本信息、获取CDN版本信息、下载资源更新完成、客户端热更新完成、开始加载游戏资源、加载游戏资源完成、游戏登录界面、SDK登录成功、获取服务器列表完成、开始请求连接服务器、连接服务器完成各环节的触达人数和次数
- 埋点作用:通过以上埋点我们可以监控在游戏启动环节是不是有明显的问题,在转换率低的步骤及时优化解决问题。
3.用户新手引导阶段的埋点应用
- 埋点内容:将每一步新手引导按线性步骤进行埋点记录,记录每一步触达的用户和完成情况。
- 埋点作用:查看玩家在新手引导哪一个环节进行驻留流失,定位新手引导期流失问题
4.游戏主线副本的埋点应用
- 埋点内容:副本id、副本类型、副本战斗方式(扫荡、手动打)、副本参与人、副本参与次数、副本参与结果(0失败、1星、2星、3星)、副本战斗时长、通关战力、副本产出物品、上阵英雄(ARPG一般都是3个角色英雄、卡牌会相对多一些、5-7个角色)。
- 埋点作用:很多游戏都会在主线副本设置卡点、对主线副本的完成情况可以反应出副本的难度,为数值策划调整难度做数据支撑
5.游戏任务埋点应用
- 埋点内容:任务类型、任务id、任务触达用户、任务状态(接取、完成、放弃)、奖励获得。
- 埋点作用:通过埋点数据可以得出各任务的参与和完成情况。
6.游戏活动玩法(日常玩法、限时玩法)
- 埋点内容:活动类型(日常、限时)、活动玩法id、触达用户(一般活动都会有一个开启条件,比如用户等级,这里可以作为触达用户的筛选条件)、参与用户、参与次数、奖励获得
- 埋点作用:通过埋点数据可以得出各活动的参与和完成情况。
7.商城购买应埋点应用
- 埋点内容:商城id、子商城id、商品id、商品购买数量、购买用户、消耗的货币类型(除了货币的种类还需要细分绑定与非绑定)、消耗货币数量、购买时间.
- 埋点作用:通过上述埋点我们可以得到商城各商品的每日购买数量、购买人数、消耗货币数量,反映用户对各类物品的喜好程度。
8.充值商品埋点应用
- 埋点内容:充值商品id、购买用户id、订单id、商品购买次数、购买消耗RMB、购买时间、购买结果
- 埋点作用:通过以上埋点可以得出各充值商品每日的销售情况、同时也与订单充值系统互补。
9.英雄养成埋点应用
- 埋点内容:玩家拥有英雄数量、对英雄的操作(获取、升级、升品、升星、觉醒、技能升级、解锁技能、游戏类型不同、不同游戏对英雄养成名称也有所不同、需要根据自己游戏产品命名埋点)、当前英雄状态(英雄等级、品阶、星级、觉醒状态、技能等级)
- 埋点作用:通过以上埋点可以得各英雄玩家获取、培养情况、玩家喜好度等。
10.其他养成线埋点应用
- 埋点内容:玩家对养成线操作(升级、升星、升阶)、消耗物品ID、物品数量、玩家当前各养成线的养成状态 。
- 埋点作用:通过以上埋点可以得出玩家对各养成线的认可度。
11.运营活动参与埋点应用
- 埋点内容:
- 充值类活动(限时充值、礼包推送):活动id、活动触达人数、充值人数、充值次数、充值金额、各档位奖励领取人数
- 活跃类活动(签到领取、特定玩法的活跃活动):活动id、活动触达人数、活动参与人数、各阶段奖励领取人数。
- 消耗类活动(转盘、限时卡池):活动id、活动触达人数、活动参与人数、参与次数(单抽、10连)、消耗货币数量。
- 埋点作用:通过以上埋点评估活动效果。
12.玩家用户属性埋点应用
- 埋点内容:账号id、角色id、角色名、区服id、渠道id、设备id、账号注册时间、创角时间、首次付费时间、当前各类货币的剩余情况、登录次数、登录时长、最后一次登录时间、最后一次付费时间、角色当前等级,vip等级,当前累计充值金额、
- 埋点作用:角色数据的埋点作为公共事件使用,多数情况下可以用于其他数据的筛选条件,从不用户的不同数据维度去查询反馈数据。
不同游戏对于埋点的内容需要进行细分,以上只是个人埋点的一些思路,埋点靠第三方后台展示的需要注意埋点的格式,下面举例角色属性部分埋点格式。
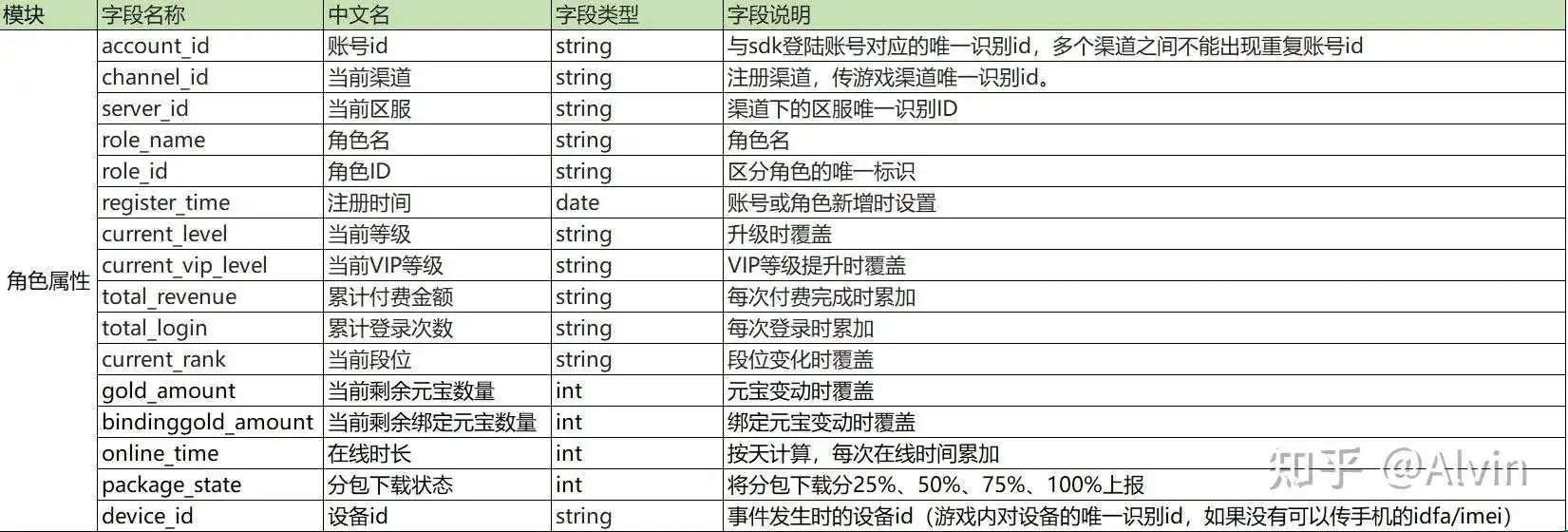
上图中的模块内容、中文名以及字段说明是必须有的内容,字段名称和字段类型这个可以是程序同学按照后台格式需求去定义书写,只要字段名能够被上报识别就好。
既然埋点都已经提前做好了,下面就开始做数据分析内容了,在游戏的运营的不同阶段,针对的分析重点也不同,下面以付费测试的阶段对游戏整体的数据分析为例。
一、游戏测试阶段数据分析哪些内容:
二、数据分析内容详情(以下所有数据内容均为自编)
1.整体宏观数据:(图例数据为自编数据)



- 分析目的:分析游戏的宏观数据可以直接揭示游戏整体在哪些方向上存在问题,同时也可以看出不同渠道与产品的匹配情况。
- 主要指标:分渠道的新增、留存、付费率、活跃ARPU、ARPPU、LTV数据。
- 分析内容:游戏商业化方面分析用户的付费率、活跃ARPU、LTV成长情况,游戏宏观品质分析玩家的留存衰减情况,通过对留存数据的提取并制作留存衰减的数据表,7日留存符合目标数据,但3留衰减过快,可能是因为第三天的开放玩法预告没有做好,不吸引玩家继续游戏,也有可能是三日奖励内容不够好,不能激励用户继续游戏,这里可以通过对玩家调研去确认玩家第二登录的玩家在第三天没有登录的原因,通过调研玩家反馈第三天登录奖励没什么吸引力,且就没有看到即将开放的玩法内容,从LTV增长情况来看,开服前7日LTV成长进度较快,符合预期数据,在开服7日活动结束后,玩家付费增长缓慢,导致LTV增长变缓可能是在没有活动刺激的情况下,付费意愿降低,也可能是头部付费玩家部分成线进度已经到底成长顶部,且其他养成线玩家不认可,不愿意付费,需要结合玩家养成线进度去分析是否是养成线问题导致的不愿意继续付费,养成线问题验证留到后面去进行。
结论及优化建议:
- 上图三个渠道数据,B渠道在新增、付费、留存的整体数据明显好于A和C渠道,在所有渠道中需要重点维护。
- 从留存衰减情况来看次留衰减符合目标数据,3留衰减过快,4、5、6、7留存衰减相对缓慢,符合目标数据,需要针对第三天登录奖励内容加大,在用户留存方面需要加强游戏第2,3天玩法预告表现,第三天奖励内容适当加强。
- 开服前7日LTV成长进度较快,符合预期数据,在开服7日活动结束后,玩家付费增长缓慢,建议在活动空档期开服8-14天时间可以适当增加定向的限时礼包推送,维持付费增长,需要继续观察开服第14天新角色UP池上线对游戏拉收情况。
PS:留存的改善不是简单的修改奖励就能优化,需要对游戏更多细节玩法内容去优化,留存数据是游戏中最难调的数据,上文只是通过在宏观数据表现给出的优化方向,前题是整体留存数据比较好,表明游戏在内容上没有大问题,通过奖励和玩法的预告展示效果去吸引玩家继续游戏,平滑衰减曲线。
2.游戏启动环节分析
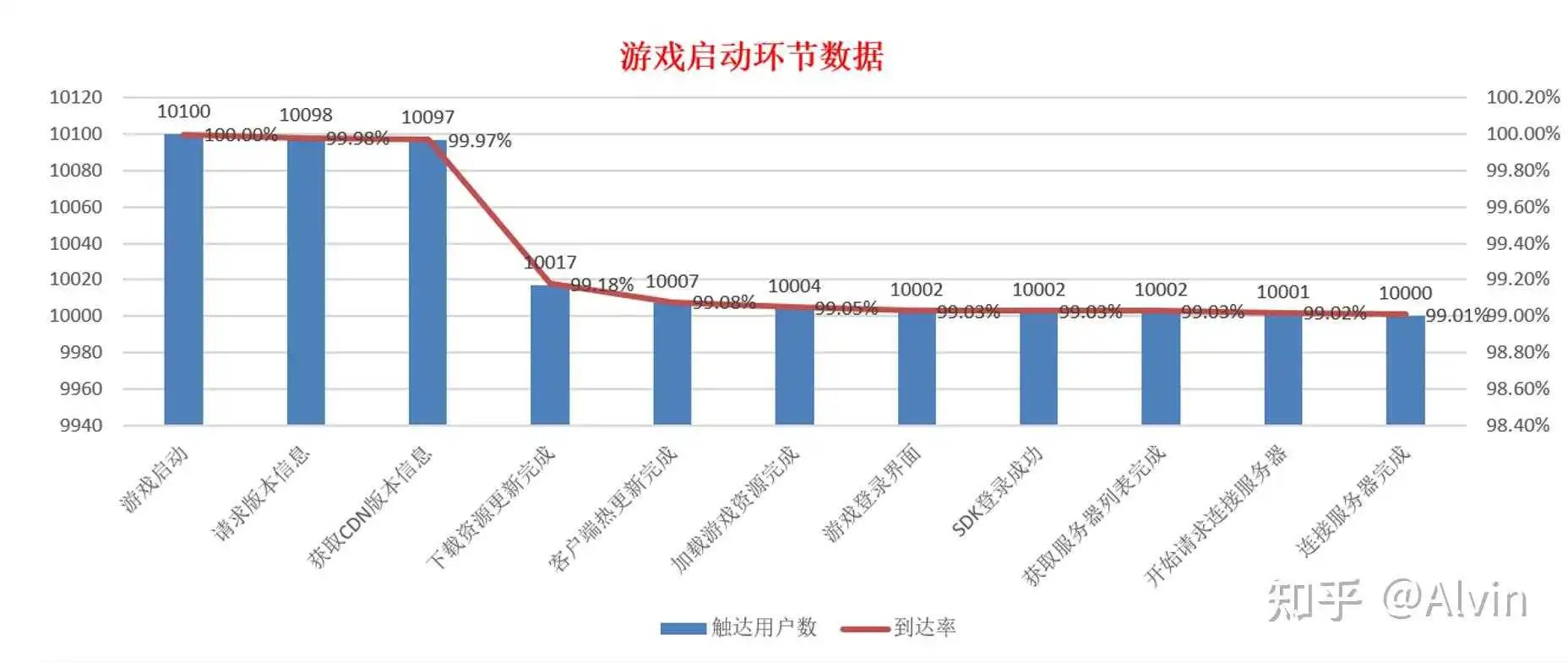
- 分析目的:定位游戏启动环节导致玩家流失的点,优化该问题点,提高转化率。
- 主要指标:启动环节各步骤的触达用户数,各步骤的完成用户数。
- 分析内容:将游戏启动环节的各步骤数据的触达用户数和完成用户通过数据后台提取出来,制作成表格,找出到达率低的点(上图为游戏启动环节常规流程步骤),启动环节共有0.99%用户流失,其中在下载资源更新完成步骤转化率最低,可能原因为游戏这次的更新资源包内容过大导致用户不愿意继续下载更新等待,也可能是用户无法下载到资源包,我们可以通过对该步骤未完成的玩家数据进行提取验证,通过查看未完成下载的用户在该页面停留时间(用户在该页面停留时间过短则说明用户不愿意等待下载资源),以及资源包下载进度情况去定位问题(用户在该页面停留时间较长,但是下载进度缓慢,最后不愿意等待流失),通过数据得出是因为玩家在下载页面下载进度缓慢而流失的。
结论及优化建议:
- 从整个启动流程的转化率看符合预期,启动环节共有0.99%用户流失,载资源更新完成步骤转化率最低,因小部分玩家在下降资源步骤下载缓慢导致用户不愿意等待,建议在优化资源包下载基础上,同时在下载环节增加tips提示玩家在下载资源缓慢时请切换网络尝试。
3.新手引导分析
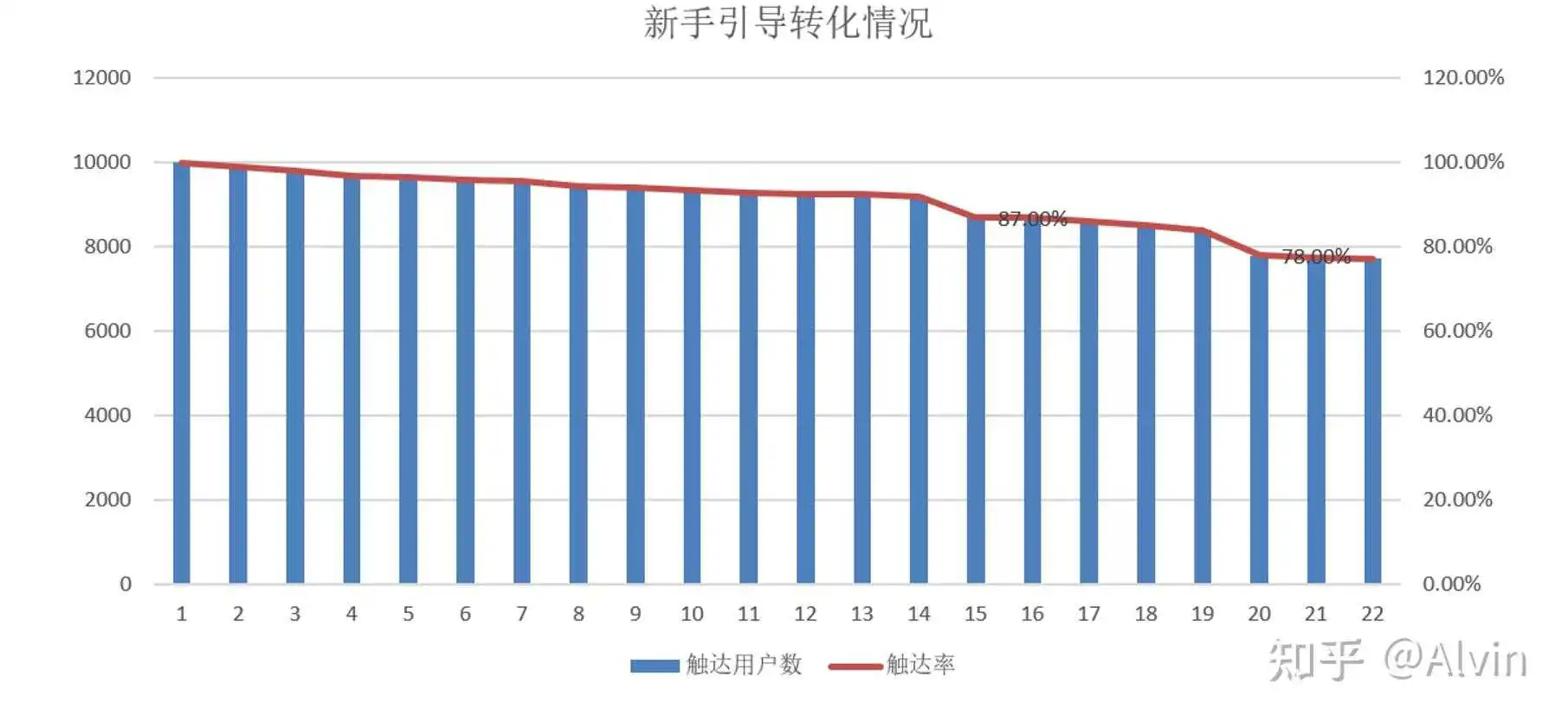
- 分析目的:通过分析新手引导转化率,找出流失高峰点,进行优化,让玩家能在游戏中体验多更多内容,增加玩家的流失成本。
- 主要指标:启动环节各步骤的触达用户数,各步骤的完成用户数。
- 分析内容:将游戏新手环节的各步骤数据的触达用户数和完成用户通过数据后台提取出来,制作成表格,通过表可看出新手引导前几步流失的比较平滑,在步骤15时和步骤20流失用户较多,步骤15为开放了角色法宝养成玩法,并引导玩家去强化养成,玩家在该步骤流失可能是因为对该养成线开放表现形式不好而流失,也有可能是该步骤存在问题导致玩家无法完成,通过在游戏中多账号反复体验以及玩家的BUG收集反馈,没发现步骤15存在相关问题,排除BUG导致流失,玩家流失单纯是因为养成线表现形式老套没新意,步骤20为通关2-6副本,可能是副本难度导致玩家无法通关后流失,也有可能是该关卡中存在非毕现的问题导致的,或是该副本在战斗表现效果明显比前面副本体验差,通过查询该副本通关率可以确定是否为该副本难度导致的部分玩家流失,通过在游戏中反复验证可以检查BUG问题,通过数据后台查询该关卡通关率明显低于其他关卡,并且该关卡未发现BUG问题,也不存在表现效果比其他关卡明显差距问题。
结论及优化建议:
- 新手引导前几步流失的比较平滑,步骤15因新养成线开放的表现形式老套没新意,需要进行包装优化。
- 步骤20因副本难度导致部分玩家流失,建议在新手引导期间的副本难度尽量降低难度,减少玩家因挫败感在新手阶段流失
4.副本通关情况
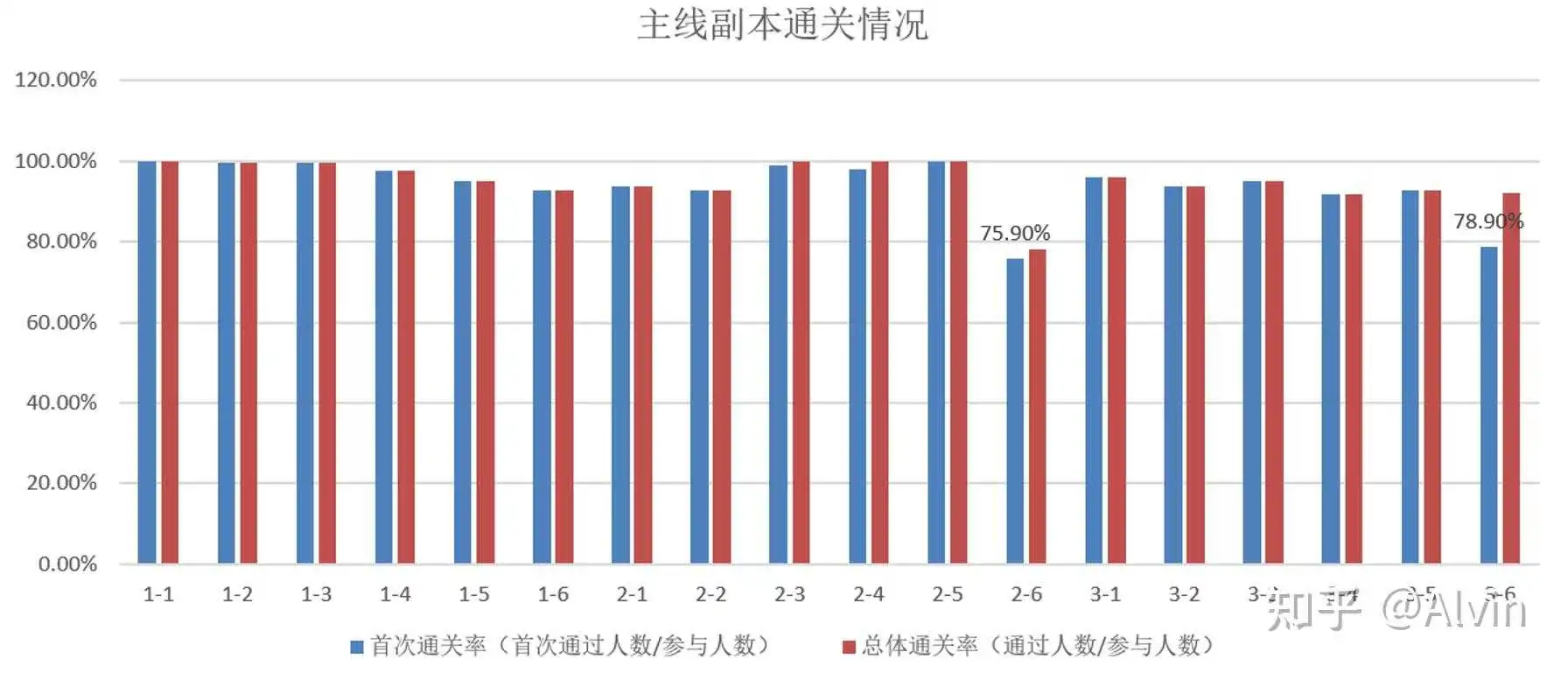
- 分析目的:验证副本设计难度是否合理,配合等级驻留和新手引导定位流失原因。
- 主要指标:各关卡参与次数、通关次数,参与人数、通关人数,首次战斗通关情况(以上数据均为手动战斗数据不包含扫荡数据)
- 分析内容:通过各关卡参与次数、通关次数,参与人数、通关人数,首次战斗通关情况可以制作出各关卡的首次通过率(去重)和总体通过率(去重)数据表,通过数据表我们可以看出在2-6关卡前首次通关率比较高在95%左右,2-6关卡设计为第一次卡点副本,首次通关率符合预期,但整体通关率并没有增长太多,可能难度设置太高玩家多次尝试都没能通过关卡,也可能在玩家首次战斗失败后没有很好的引导玩家进行提升,通过查询该关卡参与次数可以确定玩家是否是难度太高,参与多次都无法通关,通过查看该关卡参与次数,明显高于前后两个关卡的参与次数,可以确定玩家经过多次尝试仍然失败导致整体通关率并没有提升多少,3-6迎来第二次卡点,但总体通过率明显加强,可能是玩在失败后玩家进行较好的养成,增加了副本成功率。
结论及优化建议:
- 在2-6关卡前首次通关率比较高在95%左右,2-6为第一次卡点副本,首次通关率符合预期,但整体通关率因难度过高导致并没有增长太多,需要在2-6关卡战斗失败后加强玩家培养引导,增加二次通过率.
- 3-6迎来第二次卡点副本,但总体通过率明显加强,在失败后玩家进行较好的养成,增加了副本成功率。
5.玩家等级驻留情况分析
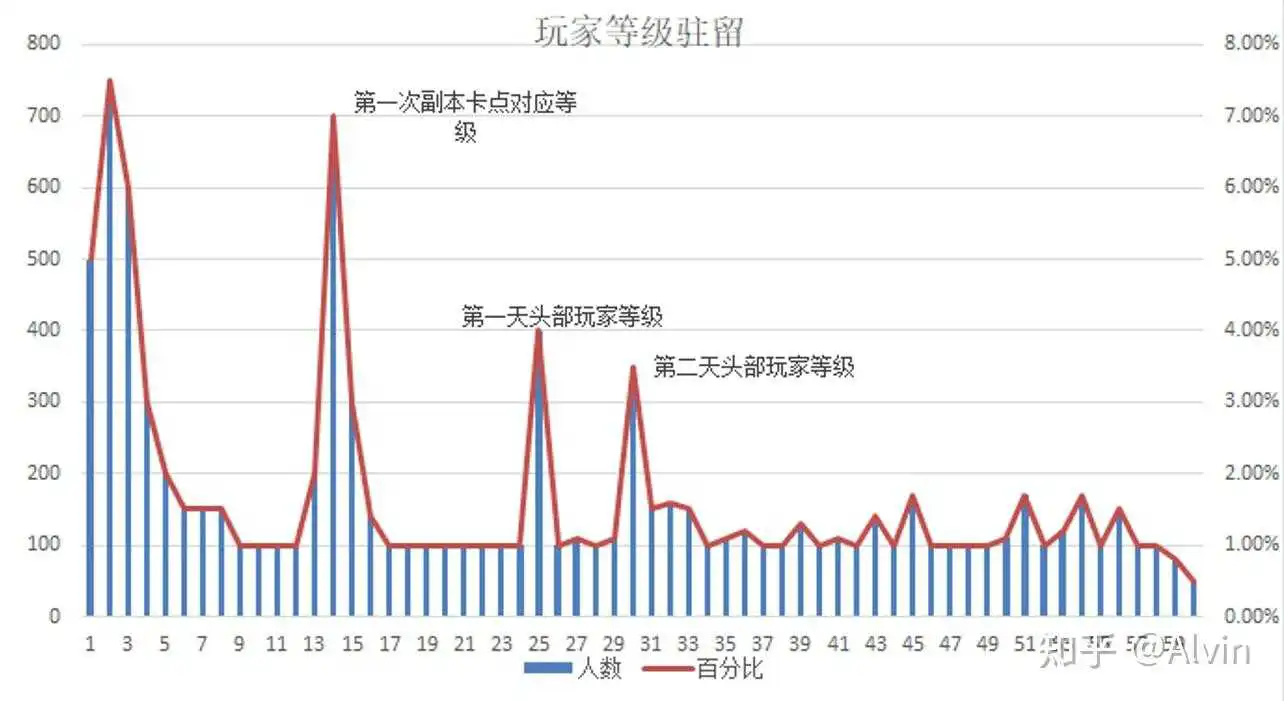
- 分析目的:跟进玩家等级停留点,找出玩家驻留高的点对应的游戏进度(副本情况、任务情况)
- 主要指标:各等级玩家停留人数、高驻留对应事件
- 分析内容:通过各等级停留人数制作等级分布表,前10级为用户筛选环节,驻留等级占比小于30%,14级为第一个高峰驻留点,对应第一次副本卡点,可能因副本难度导致玩家驻留,第二高峰驻留点为第一天头部玩家等级卡点,部分玩家可能再第二天没有上线,导致驻留过高,30级头部用户的第二天等级卡点,可能因用户没有登录导致驻留人数过多
结论及优化建议:
- 前10级为用户筛选环节,驻留等级占比小于30%,14级为第一个高峰驻留点,对应第一次副本卡点,需要优化第一次关卡卡点难度,加强战斗失败引导。
- 25级为第二高峰驻留点是第一天头部玩家等级卡点,30级为头部玩家第二天等级卡点,在二天、第三天玩法预告和登录奖励内容上做好PUSH,加强展示效果,同时可以通过APP推送提醒玩家上线。
6.玩家等级成长情况
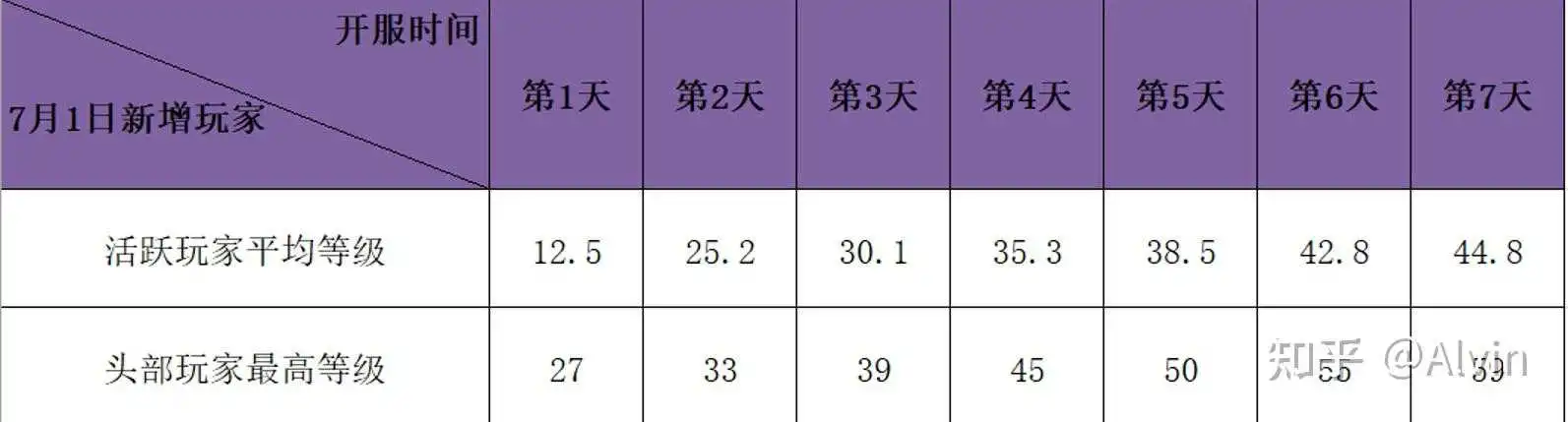
- 分析目的:分析用户的等级成长情况与预期设定数据进行比较,确保成长进度在预期范围内,防止内容消耗过快。
- 主要指标:日均活跃玩家等级、最高玩家等级
- 分析内容:通过拉取玩家等级数据、制作日均活跃玩家等级、头部最高玩家等级表,与预期设定等级表对比,头部玩家等级成长在第2天开始略高于预期范围,可能是邮件赠送奖励导致的,也有可能等级任务奖励调整导致的,通过邮件发放记录可以查看奖励是否包含了过多的体力,通过任务经验配置表可以确定经验奖励是否有增加或配置错误问题,最后经过查询确定是因邮件补偿了过多的体力导致头部玩家最高等级略高于预期设计等级。
结论及优化建议:
- 等级成长进度因邮件补偿了过多体力使得头部玩家等级略高于预期设定值,在奖励补偿时尽量多元化,不要影响服务器进度。
7.用户登录及在线时长情况分析
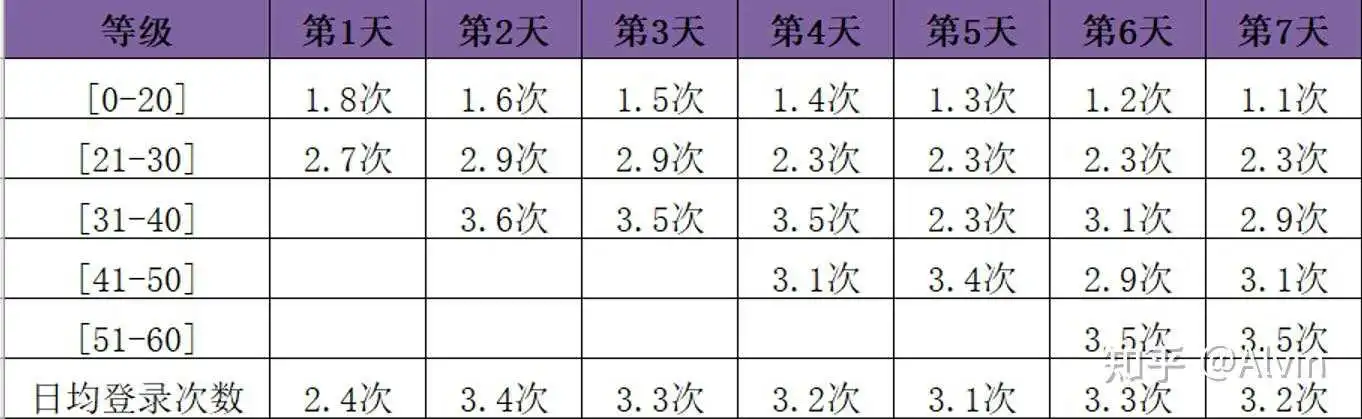

- 分析目的:通过分析用户日均登录次数来看游戏对用户的黏度、通过分析用户日均在线时长分析游戏每日内容是否够用户体验。
- 主要指标:用户日均在线时长、用户日均登录次数
- 分析内容:通过用户等级条件筛选,分层产看各等级用户的登录情况,第一天用户平均登录次数低可能是因为首日流失用户导致的,通过分等级查看0-20用户的平均登录次数明显低于20-30用户,通过用户日均在线时长可以看出首日的用户在线时长也明显低于后续几天,首日在线时长低可能因为首日用户自身对游戏筛选,流失用户多拉低了整体的日均在线时长,结合首日等级驻留情况来看,部分玩家在低等级流失是导致首日在线时长低的主要原因。
结论及优化建议:
- 随着一次登录用户的流失,从第2天起玩家日均登录次数明显增加,但总体的日均次低于同品类均值,需要增加用户登录黏度的内容,如免费抽卡、放置收菜玩法等,登录时长符合预期设定。
- 游戏时长上符合游戏设定。
8.玩家充值分析
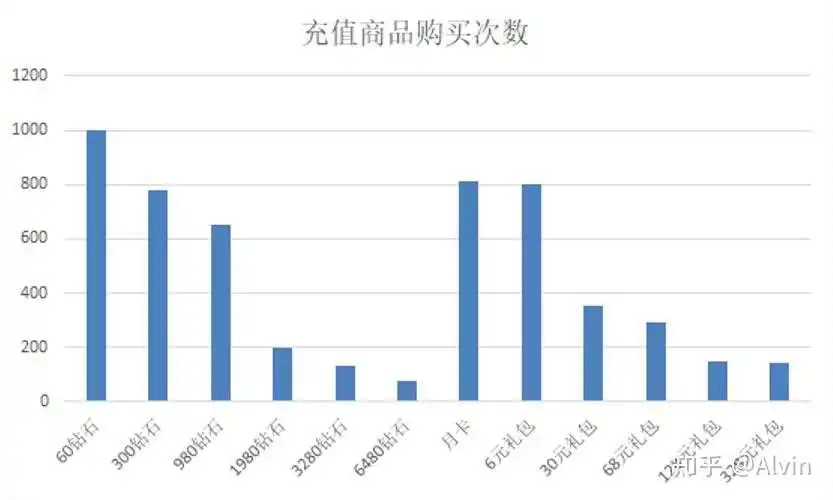
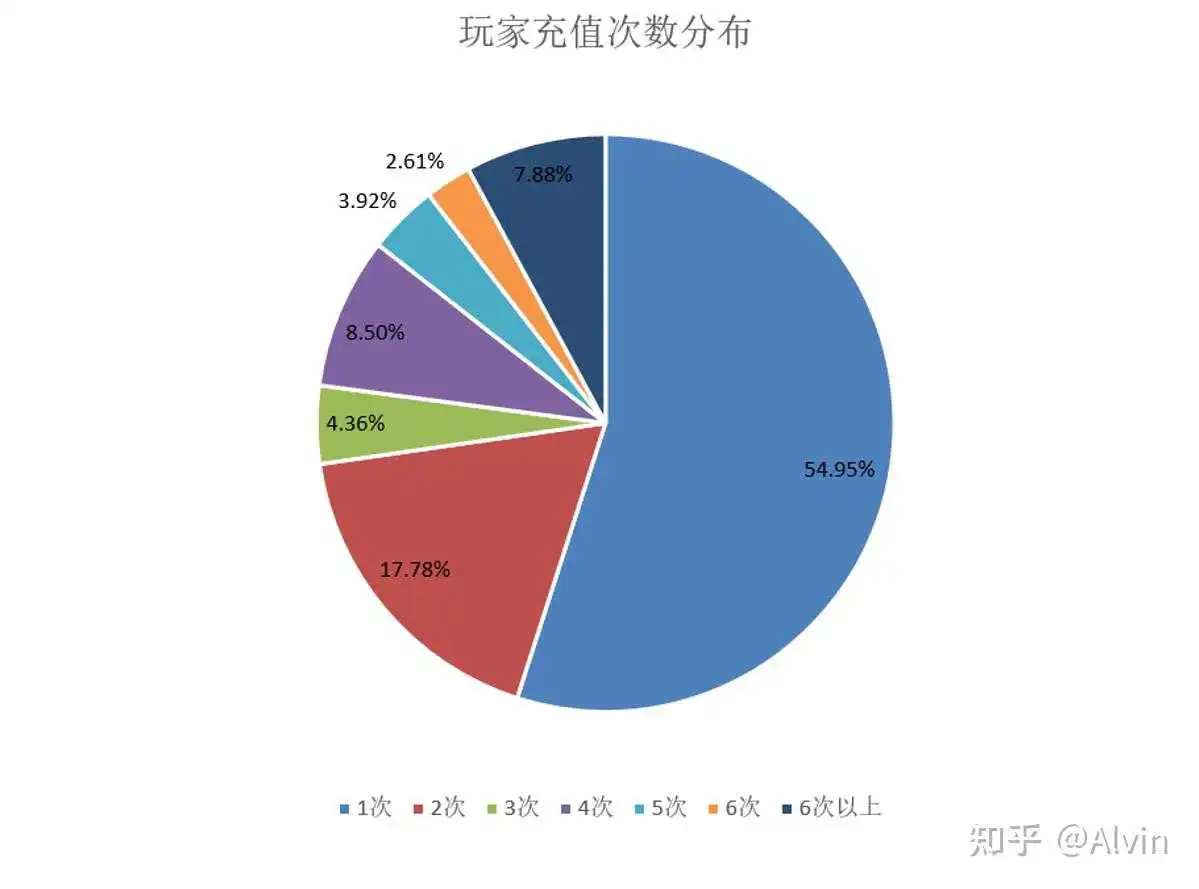
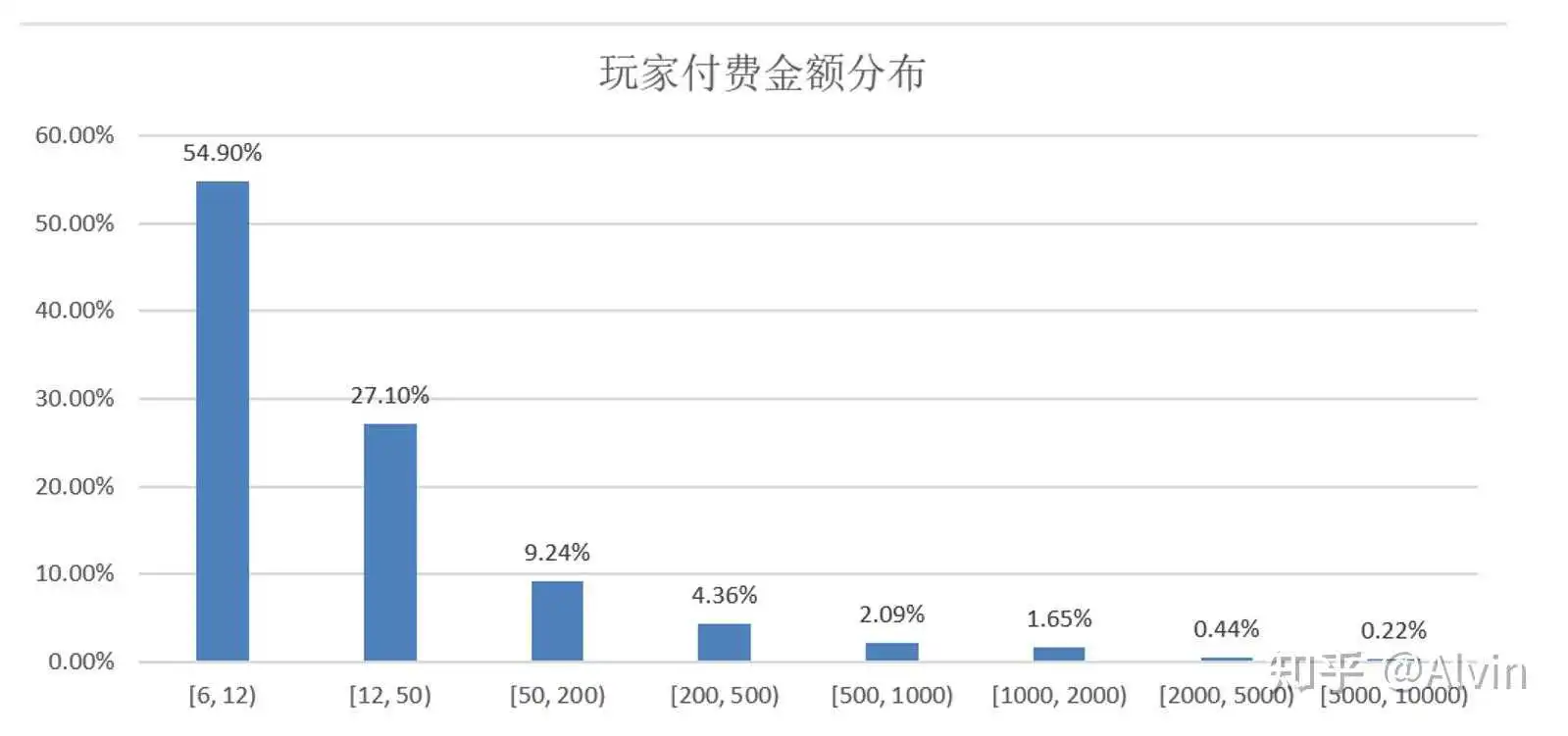
- 分析目的:通过分析得出玩家喜欢的付费内容和游戏内各玩家付费层级结构,制定优化付费结构计划,改善付费结构。
- 主要指标:玩家付费次数、各计费点购买情况、玩家付费金额分布
- 分析内容:通过玩家付费次数、各计费点购买情况、玩家付费金额分布,制作付费次数、计费点购买次数、充值金额分布表,通过表可以看出1次付费用户占比过高,可能这部分用户为单纯的首充用户,注重性价比不愿意继续付费,也有可能部分充值一次玩家已经流失,可以通过查询这部分玩家的登录情况是否还在继续游戏,通过后台数据查询,1次付费玩家多数还在持续登录游戏,玩家不愿意付费,是注重性价比的首充用户,通过对计费的购买情况分析,小额计费点购买次数较高符合常理,但30元和68元的礼包相对30元钻石和980钻石购买要低很多不合理,可能是礼包限购导致的礼包购买次数低于同档位的钻石购买次数,也有可能礼包性价比低,用不愿意购买。可以通过去重查看购买同档位的钻石和礼包购买人数对比,确定是否因礼包限购导致购买次数低,通过查询发现30元礼包和68元礼包购买人数同样远低于30元钻石和980钻石,排除限购数量的影响,确定是玩家对礼包性价比不认可导致购买次数低。
结论及优化建议:
- 小额充值、月卡和6元礼包玩家购买意愿高,但30元和68元相对30元钻石和980钻石购买要低很多,认这两个礼包付费针对人群仍然为小R,但性价比和礼包内容对当前小R需求不符合,需要对30元和68元礼包内容进行优化,
- 从玩家充值次数来看,一次用户占比过高,需要增加刺激点激励玩家进行二次付费,例如增加小额的累充,在10元附件设置一个档位,让首充玩家理想状态下购买6元礼包+6元的双倍钻石,解决好多次付费问题同时可降低12元以下用户比例,付费上重点解决6元到12元用户转化。
9.重要货币消耗
(1)钻石消耗分布
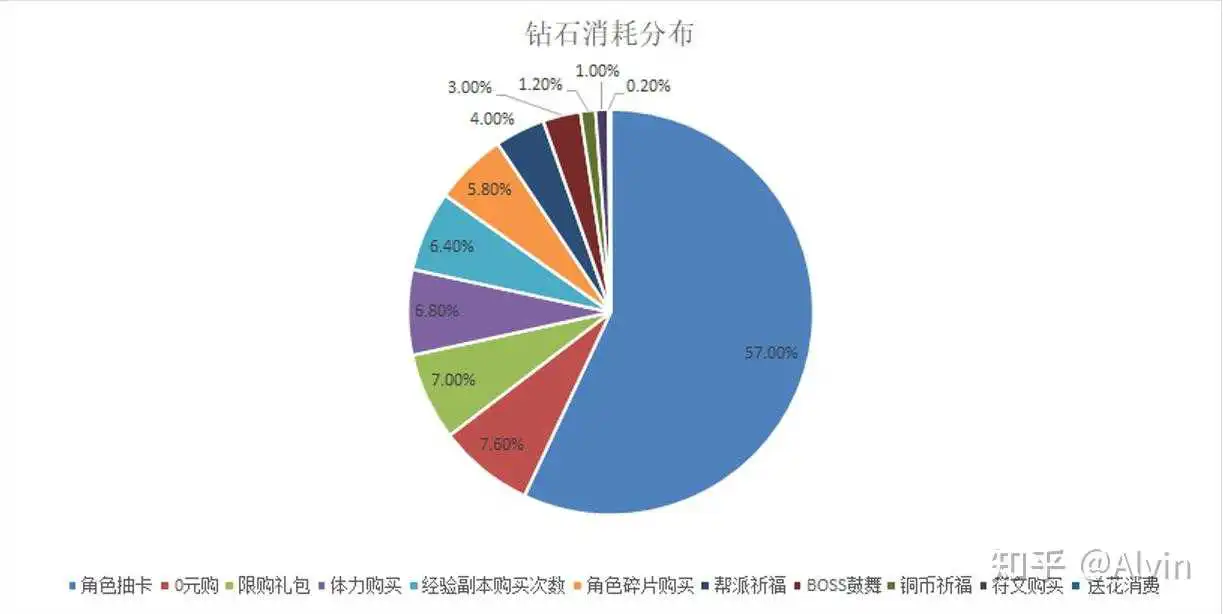
- 分析目的:分析用户将充值货币花费到哪些地方,是否与预期的设定符合,当不符合预期及时调整用户付费方向。
- 主要指标:各消耗点消耗钻石数量
- 分析内容:通过各消耗点消耗钻石数量,制作成钻石消耗占比分布图,通过实际消耗分布图与预期设计的消耗分布图进行对比,铜币祈福1.20%消耗分布不符合预期,可能是因游戏内铜钱的产销比例不合理,导致玩家手中存放了过量铜钱,不愿意再付费祈福获得铜钱,可以通过数据后台查询玩家货币存储情况和服务器每日产出货币和消耗货币数量进行确定,经过数据查询发现玩家身上存储铜币过多,且每日服务器消耗的铜钱数量与产出的铜钱数量比例过低,符文购买1%同样不符合预期,可能因符文对玩家成长性价比较低,玩家前期不认同,可以通过玩家调研看玩家对符文的反馈,以及物品价值表自查符文性价比,通过上述方法玩家对符文包装的认可度低,且符文系统开放的相对较晚,需要继续观察后续消耗情况。
结论及优化建议:
- 从玩家钻石消耗情况来看,与角色获取相关的占比最高62.80%、其次是0元购礼包7.60%、限购礼包7.00%、体力购买6.8%、购买经验副本次数6.40%,因游戏内铜钱产销比例不合理导致铜币祈福占比仅为1.20%,不符合预期设计,需要调整铜币的产销比例,
- 符文购买占比1%也不符合预期设定,玩家对符文性价比认可度低,需要通过包装方式让玩家对符文认可度增加,同时因符文系统开放较晚,需要继续观察随着玩家成长符文养成消耗是否有提升。
(2)铜币消耗分布
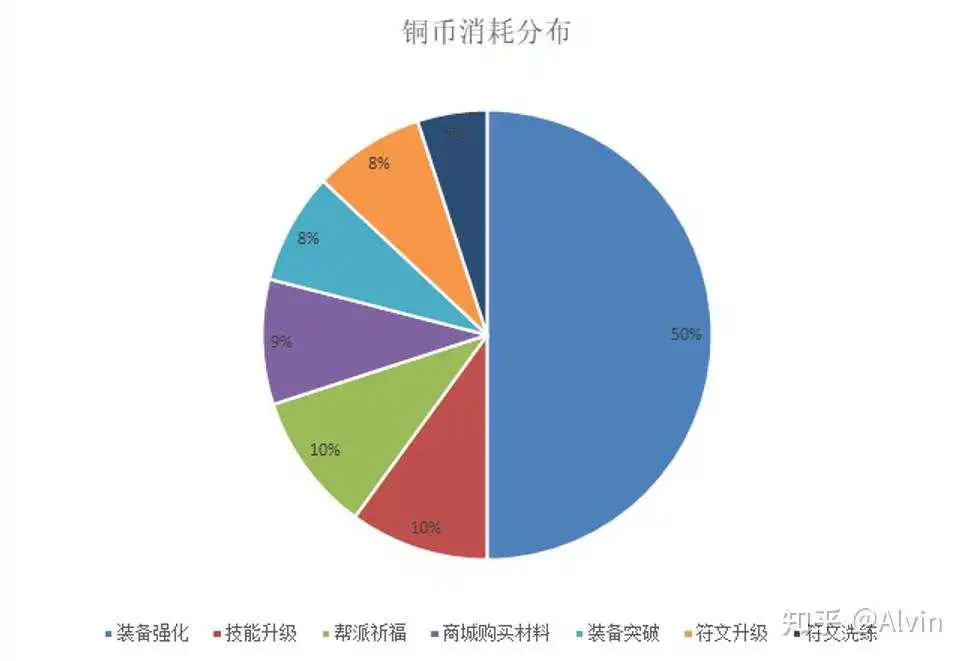
- 分析目的:分析用户将铜币花费到哪些地方,是否与预期的设定符合,当不符合预期及时调整用户付费方向。
- 主要指标:各消耗点消耗铜币数量
- 分析内容:通过各消耗点消耗铜币数量,制作成铜币消耗占比分布图,通过实际消耗分布图与预期设计的消耗分布图进行对比,铜币整体消耗分布符合预期
结论及优化建议:
- 铜币整体消耗分布符合预期,主要集中和装备有关的强化和突破占比58.00%。
- 需要注意的是随着玩家等级成长缓慢,装备强化需求也随之降低,需要有新的铜币消耗点去填补装备消耗铜币的空缺。
10.商城购买情况
- 分析目的:分析玩家在商城购买行为,获取不同层级玩家在商城消费需求,是否符合预期设定,针对不同用户制定运营活动奖励。
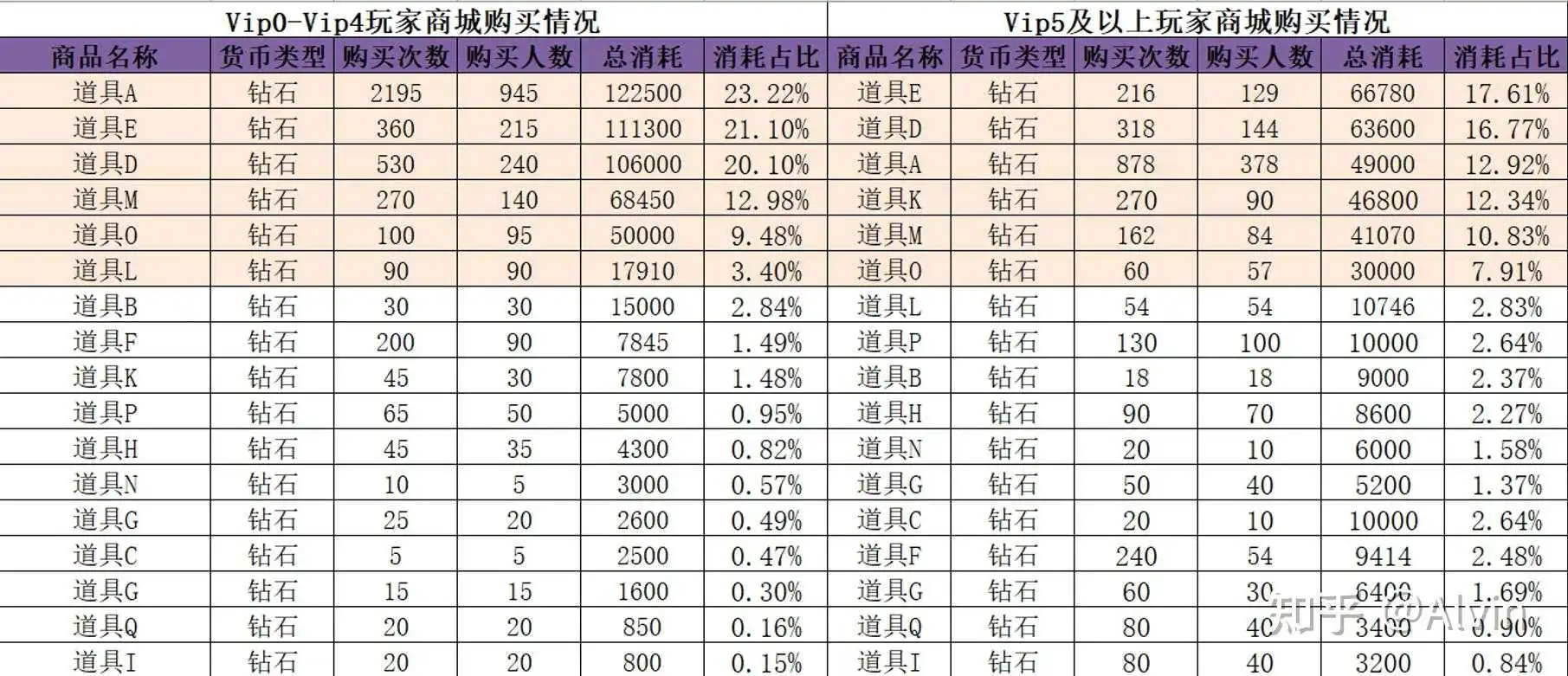
- 主要指标:各道具的购买次数、购买人数、购买消耗、消耗占比
- 分析内容:通过VIP等级划分用户层级,分析不同层级玩家在商城的购买行为,以Vip5作为划分点(看产品定位,无Vip系统的直接用充值金额划分就好),制作Vip5以下和Vip5及以上玩家商城购买情况表,首先与预期设计表进行比较,对比数据与预期基本相符,进一步确定该阶段玩家在商城消耗的需求。
结论及优化建议:
- Vip0-4玩家在商城消费符合预期设定、玩家在商城消费主要用于购买道具E(占比23.22%)、道具E(21.10%)、道具D(占比20.10%)、道具M(占比12.98%)、道具O(占比9.48%)、道具L(占比3.40%),在制定小额充值或小额礼包奖励时可考虑将道具A、E、D、M、O、L用与主赠奖励或附赠奖励。
- Vip5及以上玩家在商城消费符合预期设定、玩家在商城消费主要用于购买道具E(占比17.61%)、道具D(16.77%)、道具A(占比12.92%)、道具K(占比12.34%)、道具M(占比10.83%)、道具O(占比7.91%)、在制定中、大额充值或中、大额礼包奖励时可考虑将道具E、A、K、M、O用于附赠奖励。
11.货币产销情况
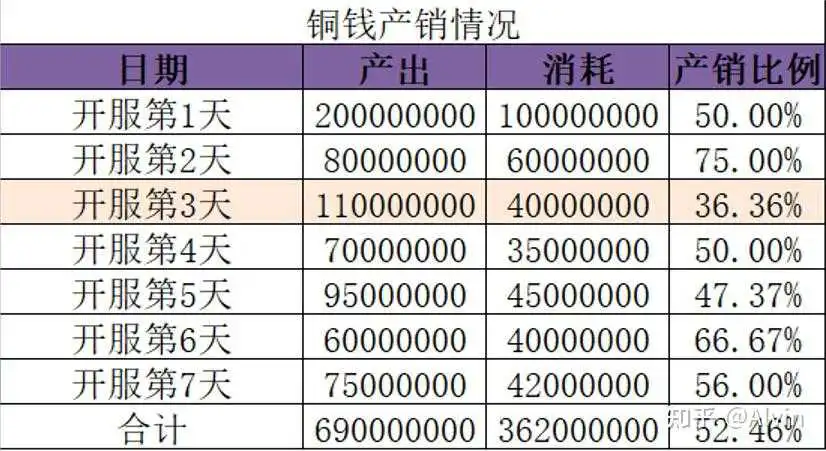
- 分析目的:分析服务器主要货币产出和消耗情况,确保产销比例合理。
- 主要指标:服务器日产出铜钱数量总和、铜钱消耗数量总和,产销比(消耗/产出)
- 分析内容:通过铜钱消耗数量与产出铜钱数量比得出产销比例,服务器在第三天产销比例明显失调,可能是玩家产出途径增加但消耗点没有增加导致的,可以通过系统开放的节奏表去对比,通过分析得出第三天增加了新的铜币获得途径(首次通过会获得大量铜钱),但消耗点没有增加,导致比例失衡。
结论及优化建议:
- 从货币产出消耗情况明显产出过剩,开服第3天产销比例只有36.36%,进一步确认了玩家铜币祈福过低的原因,需要对铜币产出进行优化,减少产出数量的同时,增加消耗数量,平衡产销比例。
12.游戏内玩法参与情况分析
(1)玩法时长分布
- 分析目的:通过分析玩家在各玩法参与时长得出各玩家对各玩法的喜好程度,同时与预期设定进行对比,将不符合预期的玩法进行优化。
- 主要指标:各玩法参与时长
- 分析内容:制作玩法时长分布表,与预期数据进行对比,通过对各玩法时长分析,玩法时长分布上除第二天时间衰减过多,其他3-7天均符合预期,第二天衰减过快通过数据可以看出主要是玩法A参与时长明显降低导致的,玩法A为主线副本,可能是因为主线副本进度推进变慢,且设置了等级卡点导致玩家参与时长降低,可以通过玩家关卡进度情况去确定是不是明天玩家可通关卡数量明显减少了,通过数据查看得出确实是因主线副本进度推进变慢导致第二天衰减过快。
结论及优化建议:
- 游戏整体玩法时长分布符合预期,但总体时长分布在第二天衰减过快,主要因为主线副本进度推进变慢,在第三天、第四天开启新的玩法内容填补了主线副本的空档时间,从第四天起时间总时间在72分左右趋于稳定,后续几天时长符合预期。
(2)玩法参与率
- 分析目的:通过分析玩法参与率可以看玩家对各玩法喜好程度,及时发现参与低的玩法,进行优化。
- 主要指标:各玩法开放触达人数、各玩法参与人数
- 分析内容:这里需要说下,玩法参与率=玩法参与人数/玩法开放用户数,不能使用活跃用户数,否则会导致分母过大,参与率过低,通过各玩法开放触达人数、各玩法参与人数制作出玩法参与率表,玩法B参与率明显随着开服时间增加而逐渐降低,可能因该玩法奖励对玩家没有吸引力导致参加人数逐渐降低,也有可能该玩法不成熟存在BUG导致玩家不愿意参与,可以通过对玩家进行调研询问玩家不愿意参加的原因,通过调研玩家反馈该玩法奖励太差,且组队困难,还有BUG存在。
结论及优化建议
- A玩法参与率每日参与率最高,最受玩家喜爱,
- 玩法B经常出现BUG,且奖励没什么心意,组队困难,导致玩法B参与率最低,且在逐渐降低,需要解决玩法B存在的BUG,优化玩法组队匹配机制(增加机器人、跨服匹配等),适当调整奖励内容。
13.各养成线进度分析(当前只举例2条)
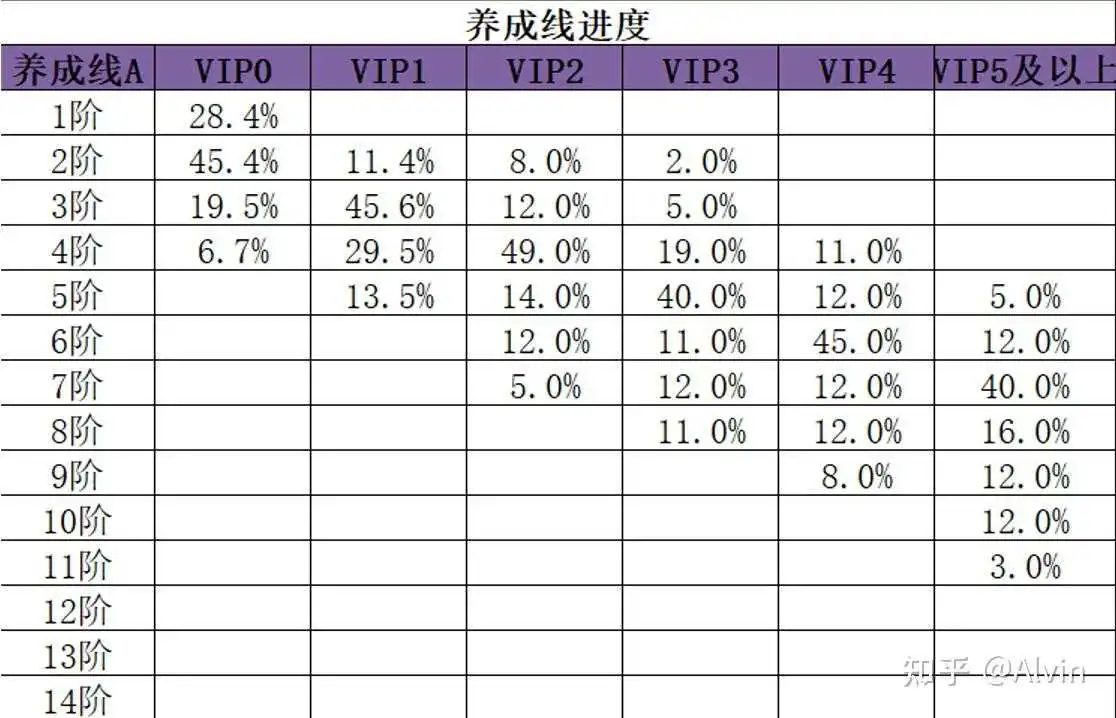

- 分析目的:分析养成线进度得出玩家各养成线情况,确保在头部玩家养成进度到底前开放新的内容,同时找出玩家不受欢迎的养成线内容进行优化,改善玩家认知。
- 主要指标:各养成线玩家养成进度分布、VIP等级
- 分析内容:以VIP等级作为用户划分条件,通过查看各不同层级的玩家在养成线养成进度情况得出养成线A最受玩家喜好,各层级用户都愿意投入资源养成,B养成线最不受玩家欢迎,无论哪个层级的玩家参与养成进度都低,付费玩家和普通玩家没有拉开差距,可能因为该养成线在包装的展现形式上好,也有可能该养成线性价比偏低,通过游戏内直观感受可以确定养成线B包装形式与A的区别,通过数值表可以看养成线B的性价比情况,通过以上方法得出养成线B在包装展示上没有外显特性,是单纯的数值养成内容,性价比上和A养成线没有明显差别.
结论及优化建议
- 从玩家整体参与情况来看,A养成线最受玩家欢迎,且消耗过快超出预期,需要及时补偿养成线深度,满足头部玩家追求。
- B养成线最不受玩家欢迎,无论哪个层级的玩家参与养成进度都低,付费玩家和普通玩家没有拉开差距,需加强玩家对B养成线认可,在无法改善包装情况下,建议适当做该养成线促销特价获得,增加性价比弥补在表现层上的劣势。
主要结论总结:
- 渠道B用户质量更高,更符合目标用户,后续需要重点维护。
- 新手引导步骤15时流失用户较多,需要进行相关优化。
- 需要在第一副本卡点2-6战斗失败后加强玩家培养引导,增加二次通过率。
- 铜钱产出过剩,产销比不合理,需要优化产出数量,加强消耗数量。
- 养成线B参与度太低,需要优化。
- 玩法B需要优化BUG问题,需要更改组队机制,优化奖励内容吸引玩家参与。
- 加强开服二三天玩法预告和奖励内容展示效果,适当加强第三天登录奖励缓解流失衰退太高问题。
以上是个人对游戏埋点和数据分析内容在游戏中的应用理解,文中数据皆为自编且部分内容合理可能存在瑕疵,对于有疑问和有异议的地方大家可以评论或私聊进行讨论。
这是可视化埋点系列的一篇文章,重点是整个平台搭建的总览及各个环节的实现方案。本系列其他文章见下:
- 可视化埋点平台(一):从0到1搭建可视化埋点平台。主要是平台搭建的总览。也就是本篇文章。
- 可视化埋点平台(二):intersectionObserver 实战经验。介绍曝光埋点采集时的一些实战细节。
- 可视化埋点平台(三):元素圈选器实现。主要讲述元素圈选器的实现。
- 可视化埋点平台(四):如何维持 Xpath 稳定性,主要介绍 xpath 的边界条件及稳定性增强。
正文从以下开始:
近期一直在团队内开发可视化埋点平台,目前已经落地并成功在多个复杂业务中落地使用,在其中也踩了不少坑。故写此篇文章,给想要在团队内落地可视化埋点平台做一份参考,也是对笔者自己实现过程的一个记录。
笔者见过的团队,埋点大致有几种合作模式。
- 最原始的方案:wiki 维护埋点信息,产品丢给开发一份 wiki 文件,记录了需要埋点的元素,比如按钮A,按钮B,图片C,同时如果是一个列表,比如一个音乐播放列表的下载按钮,那么产品可能还想要获取下载的音乐名称。开发拿到记录好埋点的 wiki,在点击时上报埋点,携带元素名称,比如按钮A,按钮B,而对于音乐列表的下载按钮,再携带音乐名称。
- 录入平台方案:基本同上一方案一致,但是产品和开发的交流,通过录入平台来维系。这一模式解决了 wiki 维护带来的后续查找不便和随意性。但是录入平台导致了产品要录入更多的信息,比如该该元素截图、附加信息、所属应用等等。而开发侧,由于平台的存在,每一个埋点与平台间,必然存在一个独一无二的 key 维护,开发上报埋点时将其携带,从而在平台上可以进行关联。
- 可视化录入方案:开发侧接入可视化埋点脚本,产品侧直接在可视化埋点平台进行圈选(类似 chrome inspector),圈选后埋点自动上报。
- 全埋点方案:开发侧接入全埋点脚本,用户的所有点击均会上报,但是由于上报的数据太多,对于存储侧的压力较大。同时由于上报的埋点比较零碎,对数据分析的要求较高。
上述的方案1和方案2,可以统称为手动埋点,其优劣如下:
- 手动埋点:产品侧和开发侧都有不少的繁琐的工作量。但是该方案非常灵活且埋点的准确性非常高。同时对于不同的页面状态的支持非常简单。
- 可视化录入:开发侧和产品侧都没有什么工作,方便的圈选模式能让产品轻易的进行埋点。但是该方案依赖可视化平台的能力,同时埋点的准确性可能会存在一定的问题。同时,如果页面有不同的状态,此时必须模拟用户进入该状态,才可以进行埋点的圈选工作
- 全埋点 or 无埋点:开发侧和产品侧无额外工作。但是全埋点数据收集上来之后,怎么对数据分析是一个问题,此处笔者并不了解,不做赘述。
可视化埋点平台功能上的核心,便是提供用户一个可以方便对元素进行圈选的方案。用户可以对目标页面进行元素的选择,从而实现埋点的录入。大致的效果如下:
用户通过选择元素,录入名称,即可完成埋点的录入。同时,为了满足一些高级场景,可以顺带提供一颗同浏览器几乎一样的元素选择器,如下图:
与此同时,可视化埋点平台还需要具备反向圈选的能力,以便给使用者一个正向反馈,可以作为一个埋点是否正确的验证能力。如下图:
整体的架构图如下:
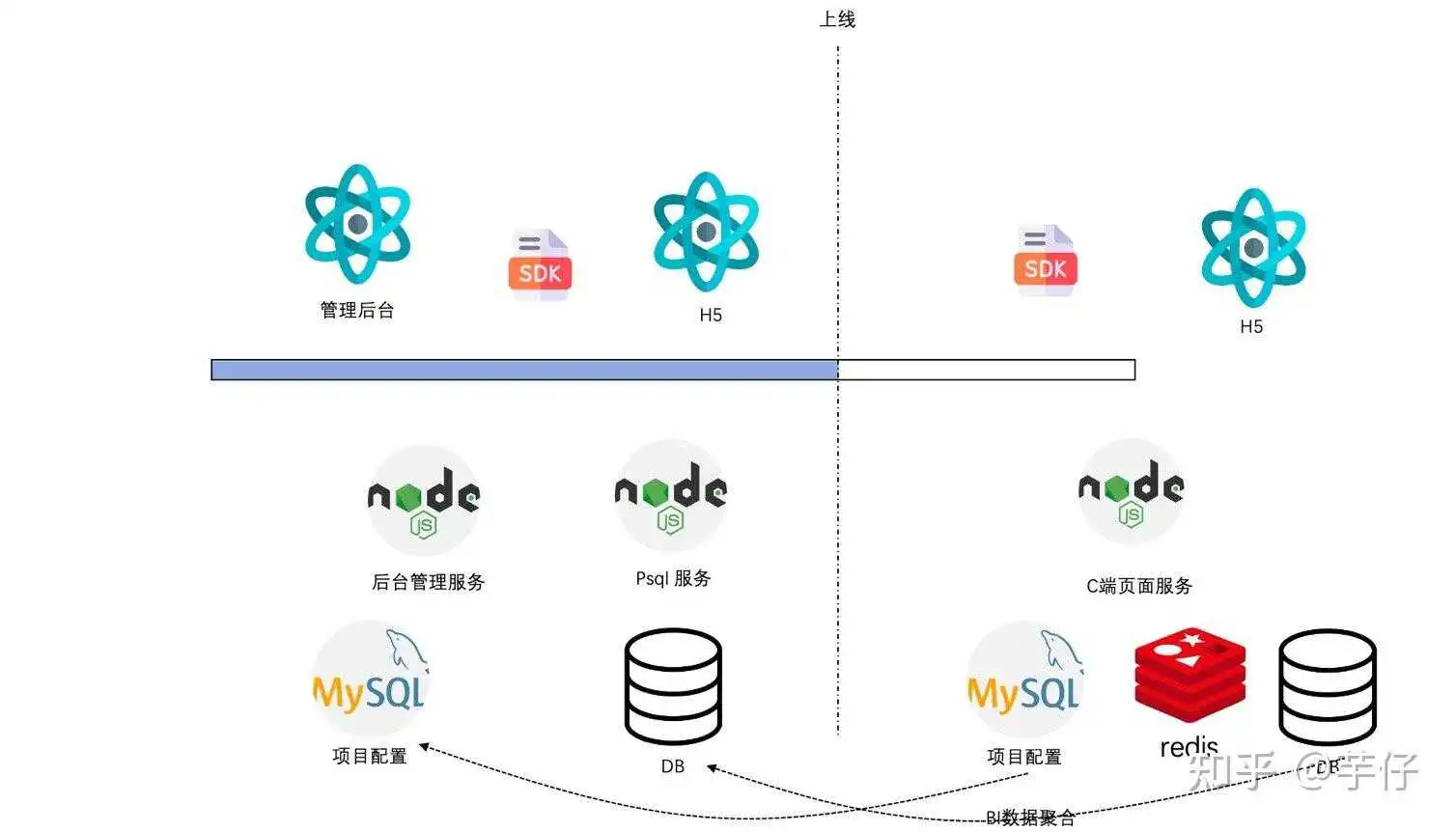
图中,共分为4个区域:
- 管理后台 + 圈选 sdk:位于图中的左上角部分。承担了可视化埋点项目维度的创建,圈选逻辑的实现,以及数据可视化等等功能,是用户能够看到的页面
- node 后台服务及数据服务:位于图中的左下角。其承担了项目的常规后台增删查改的部分,以及同已有的埋点数据对接的能力(由于笔者落地的可视化埋点,其埋点数据的存储及格式沿用了已有的平台)。
- c端页面 采集 sdk:位于图中的右上角部分,主要负责根据后台存储的该页面的埋点信息,反查元素,实现埋点数据的上报
- c端后台:位于图中的右下角部分,主要负责根据 c 端页面返回其埋点配置,由于需要应对大流量的问题,node 端单独拉了出来。
其中,2、4部分是 node 端提供的一些接口,相对而言比较常规,本文不做赘述。同时,1中项目管理、数据可视化,也是常规的前端页面,并非本文的重点。
本文将着重讨论1、3部分中,圈选功能和数据采集的实现。
从表面上来看,用户的操作路径如下:
- 点击圈选按钮
- 鼠标划入目标页面,在想要埋点的元素上进行点击
- 在唤起的弹窗中录入埋点名称,即可完成埋点的录入。
- 完成录入后,自动对这些元素进行埋点。
而实际的内部核心流程如下(一些边界的场景进行了简化):
- 用户在圈选页面打开圈选开关(需要通知目标页面)
- 目标页面(以 iframe 的形式嵌在平台内)收到打开消息,开启圈选模式,此时鼠标的移动会在元素上增加浮层
- 用户点击,此时需要生成元素的唯一标识,传回给埋点平台
- 埋点平台收到消息,让用户填写埋点名称,即可完成这个埋点的录入流程。
- 真实用户打开页面后,该页面先获取录入的埋点元素标识
- 根据元素标识来反向选择到真实元素
- 监听真实元素的曝光和点击,上报埋点
可以看出: 可视化埋点平台的设计中,存在几个关键点:
- 如何获取元素的唯一标记,并可通过该标记反向选择元素
- 如何随着鼠标的移动,给元素添加浮层
- 频繁的跨域 iframe 通信,该如何简化
- 元素的曝光和点击如何同元素标记匹配上报
要实现不人工埋点,那么就需要给每一个 dom 元素进行标记,而这个标记,本文选择的便是 xpath。本质是记录其在整个 dom 树中的位置,这是一项比较久远的知识。说实话,在做可视化埋点平台前,笔者作为一名前端开发,也基本没有听说过 xpath。
举个 xpath 的实例,如下图,一个元素在 dom 树中的位置如下:
那么可以通过右击 -> 复制 -> 复制xpath/复制完整xpath:
// xpath const xpath = '//*[@id="__next"]/div[1]/div/div/section[1]/article/h1[1]' // 完整 xpath const fullXpath = '/html/body/div[1]/div[1]/div/div/section[1]/article/h1[1]' 其本质是从当前元素开始,首先确定当前元素处于兄弟节点中同 tag 元素的第几个,比如上图中,其处于 h1 标签的第一个,便是 h1[1],(如果同级只有一个 h1 元素,那么 chrome 会直接丢弃 [1])。依次往上执行,一直查找到根元素,也就是 html,即可得到元素的完整 xpath。
但是 chrome 本身没有把这个方法暴露出来,故需要开发者自行实现,一个非常简易的获取元素 xpath 的代码如下:
function getXpath(ele) { let cur = ele; const path = []; while (cur.nodeType === Node.ELEMENT_NODE) { const currentTag = cur.nodeName.toLowerCase(); const nth = findIndex(cur, currentTag); path.push(`${(cur.tagName).toLowerCase()}${(nth === 1 ? '' : `[${nth}]`)}`); cur = cur.parentNode; } return `/${path.reverse().join('/')}`; } // 其中 findIndex 代码如下: function findIndex(ele, currentTag) { let nth = 0; while (ele) { if (ele.nodeName.toLowerCase() === currentTag) nth += 1; ele = ele.previousElementSibling; } return nth; } 通过 getXpath 方法,可以拿到元素的唯一标记,此时需要做的,便是根据元素的标记,反选回该元素,浏览器提供了原生的方法,如下:
function getEleByXpath(xpath) { const doc = document; const result = doc.evaluate(xpath, doc); const item = result.iterateNext(); return item; } 上述方法,可以返回匹配到的第一个元素,即可获得目标元素。
但是在实际的落地过程中,笔者发现了一些有趣的问题:
svg元素,无法通过上述的getEleByXpath进行反向选择。且监听元素曝光的 api: intersectionobserver,也不支持监听svg元素。/div/ul与/div[1]/ul,对于/div的场景,如果 dom 结构中,存在两个div,如果第一个div下,不存在ul元素,而第二个div下,存在ul元素,那么此时getEleByXpath('/div/ul')的第一个元素,便会命中第二个div,会出现误判- 对于实际业务中非常常见的动态弹窗场景,由于这些动态弹窗基本都是动态挂载在
body下,且关闭后直接就销毁,那么对于下一个动态弹窗,由于位置一致,此时非常容易判定为同一个元素,带来误判 - 对于实际业务中,常见的三元表达式的场景比如:
show ? <div /> : null,由于show变量的存在,导致其后面的兄弟元素的位置,会发生变化,从而导致xpath不稳定。 - 对于实际业务中,策略组件的场景,也非常容易带来
xpath的重叠,比如const Comp = comp[type]; return <Comp /> - 圈选功能的元素浮层,是否会对 dom 结构带来干扰,如何避免?
- 列表元素如何标记?
这些问题相对而言比较细节,留待后续文章进行讨论,此处还是以串联整个可视化埋点核心链路为准。
有了元素唯一标识,接下来便是对元素的圈选。(备注:此处参考了开源的 dom-inspector,在其基础上对多选、xpath,元素浮层等能力进行了解耦和加强,以满足实际场景的需要。)
圈选的本质,便是在用户鼠标移动的时候,在元素上层出现一个同样大小的浮层,以便用户识别。
获取用户鼠标移动和鼠标移动处的元素,在 body 上监听 mousemove 事件并取其 target 即可获取目标元素,接下来只需要获取元素的 content 大小、padding、margin 大小及元素的位置,然后根据其位置挂载浮层即可。
获取元素大小及位置的方法很多,本文列举的仅仅是比较常规的方法(有更好的方案可以评论区讨论交流),如下:
// 获取元素的位置 function findPos(ele) { const computedStyle = getComputedStyle(ele); const pos = ele.getBoundingClientRect(); // left,right, top 均 不包含 margin // 减去 margin,可以获取元素加上 margin 后,距离左侧和上侧的真实距离 const x = pos.left - parseFloat(computedStyle['margin-left']); const y = pos.top - parseFloat(computedStyle['margin-top']); const r = pos.right - parseFloat(computedStyle['margin-right']); return { top: y, left: x, right: r, }; } // 获取元素大小 export function getElementInfo(ele) { const result = {}; const requiredValue = [ 'border-top-width', 'border-right-width', 'border-bottom-width', 'border-left-width', 'margin-top', 'margin-right', 'margin-bottom', 'margin-left', 'padding-top', 'padding-right', 'padding-bottom', 'padding-left', 'z-index', ]; const computedStyle = getComputedStyle(ele); requiredValue.forEach((item) => { result[item] = parseFloat(computedStyle[item]) || 0; }); // 用 offsetWidth 减去元素的 border 和 padding,来获取内容的宽高 // 不用clientWidth 是因为内敛元素,该属性为0 const width = ele.offsetWidth - result['border-left-width'] - result['border-right-width'] - result['padding-left'] - result['padding-right']; const height = ele.offsetHeight - result['border-top-width'] - result['border-bottom-width'] - result['padding-top'] - result['padding-bottom']; result.width = width; result.height = height; return result; } 其中,使用 offsetWidth 而不是 clientWidth 是因为 clientWidth 在内联元素中为 0。具体可见 clientWidth vs offsetWidth,而不使用 getBoundingClientRect().width 是因为元素用了 transform 后,该值会随 transform 发生改变,具体可见 offsetWidth vs getBoundingClientRect().width。
当然,上述代码隐藏了 svg 元素的处理,可以使用 getBoundingClientRect().width 或 svg 元素 特有的 getBBox 处理,本文不再赘述。
计算出元素的位置及宽高后,即可在其位置分别添加:元素内容区、元素 padding 区、元素 border 区、元素 margin 区,以及元素的 tag + 宽高。
综上,想要实现一个元素圈选器,那么只需要做如下操作:
body上监听mousemove事件(捕获阶段)- 在事件回调中,计算 target 的大小和位置
- 依次为元素添加内容、
padding等浮层,即可完成一个元素圈选器的功能。
在实际应用中,还需要增加圈选开关来控制圈选器的打开与关闭,以免影响用户的正常点击行为,并可以增加上一次 target 的缓存来减少浮层的销毁与创建的频率等等。
在圈选的过程中,平台侧需要通知 iframe 内目标页面开启圈选模式,而 iframe 中,当用户选中元素后,需要计算元素的 xpath 反向通信给平台侧。此处为了方便,后续将平台侧成为 main,而 iframe 内目标页面称为圈选 sdk。main侧记录埋点后,为了便于验证,也需要在用户 hover 到埋点上,通知圈选 sdk 进行元素反选,从而验可以对录入的埋点进行反向验证。
下图简单描述了两者之间的一个通信:
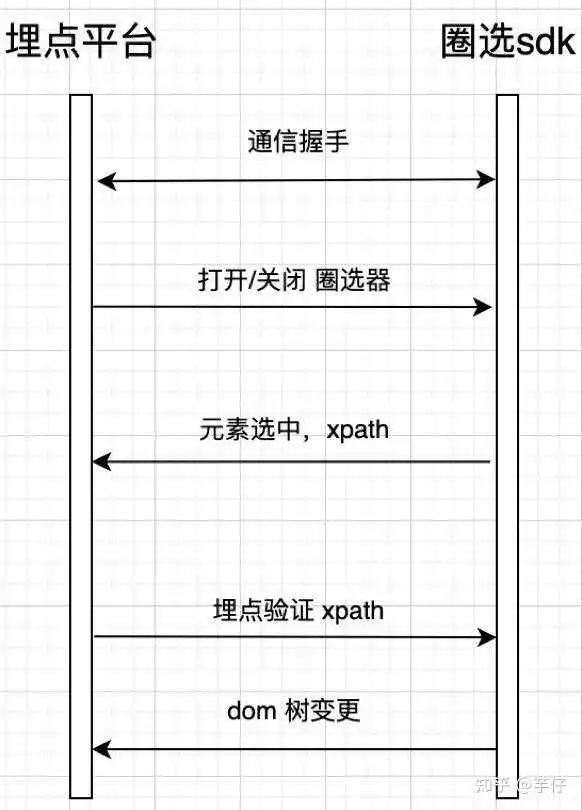
可以看出,这中间需要频繁的一个 iframe 通信,同时也是一个双端通信,故笔者结合发布订阅模式抽象了一个通用的 iframe 跨域通信类,main 和 圈选sdk 均基于此类进行上层建设。核心代码如下:
class MsgCenter { constructor({ sender, // 在 main 中 是iframe.contentWindow || 在圈选 sdk 中则是 window.parent receiver, // window in main and iframe source, // current window origin target, // target window origin }) { this.sender = sender; this.receiver = receiver; this.target = target; this.source = source; this.receiver.addEventListener('message', this._handleMessage.bind(this)); this.listeners = {}; } /* data: { type: '' // must define ext: {} // 用户自定义数据 source, // 源页面 origin target, // 目标页面 origin } */ sendMessage(type, ext) { if (!this.target) return; this.sender.postMessage( { source: this.source, target: this.target, type, ext, }, this.target ); } // 监听type类型消息 on(type, callback) { if (this.listeners[type]) { this.listeners[type].push(callback); } else { this.listeners[type] = [callback]; } } // 取消type类型消息的监听 off(type, callback) { if (this.listeners[type]) { this.listeners[type].forEach((cb, index) => { if (cb === callback) { this.listeners[type].splice(index, 1); } }); } } // 内部根据type分发消息 _handleMessage(event) { const { data, origin } = event; // 判断消息来源是否是来自于目标的页面 if (origin === this.target) { if (this.listeners[data.type] && this.listeners[data.type].length) { this.listeners[data.type].forEach((callback) => callback(data.ext)); } } } } 在上述代码中,借助发布订阅模式,便可简化 main 和圈选 sdk 中的通信流程,具体使用方法如下:
// 在 main 中 const msgCenter = new MsgCenter({ target: iframe.origin, // iframe 页面的 origin source: window.location.origin, // 当前页面的 origin receiver: window, sender: iframe.contentWindow, // 指向 iframe 的 window }); // 向 iframe 发送消息,比如打开圈选开关等 msgCenter.sendMessage('enableSelector', { /* * 可传递自定义数据 */ }); // 监听来自 iframe 消息 function receiveXpath(data) { console.log(data.xpath); } msgCenter.on('targetSelect', receiveXpath); // 移除监听 msgCenter.off('targetSelect', receiveXpath); 而圈选 sdk,无非就是 sender 不同,使用伪代码如下:
// 在 iframe 中 const msgCenter = new MsgCenter({ target: main.origin, // 圈选平台 页面的 origin source: window.location.origin, // 当前页面的 origin receiver: window, sender: window.parent, // 指向圈选平台 main 的 window }); 有了上述方法,可以大大简化代码中关于 iframe 双工通信的监听与取消。
至此,整个圈选流程的核心模块即可跑通:
开启圈选时,平台侧 main 向 目标页面 iframe 发送开启圈选消息,iframe 侧收到消息,开启元素圈选功能,选中后,再传递给平台侧,完成元素埋点的录入。同时平台侧 main,在埋点列表被 hover 时,也可向 iframe 发送选中元素消息,iframe 中收到消息,选择对应元素,以便验证埋点对应的元素是否可识别。
埋点一共两种类型,元素的曝光和点击,下图是其基本流程:
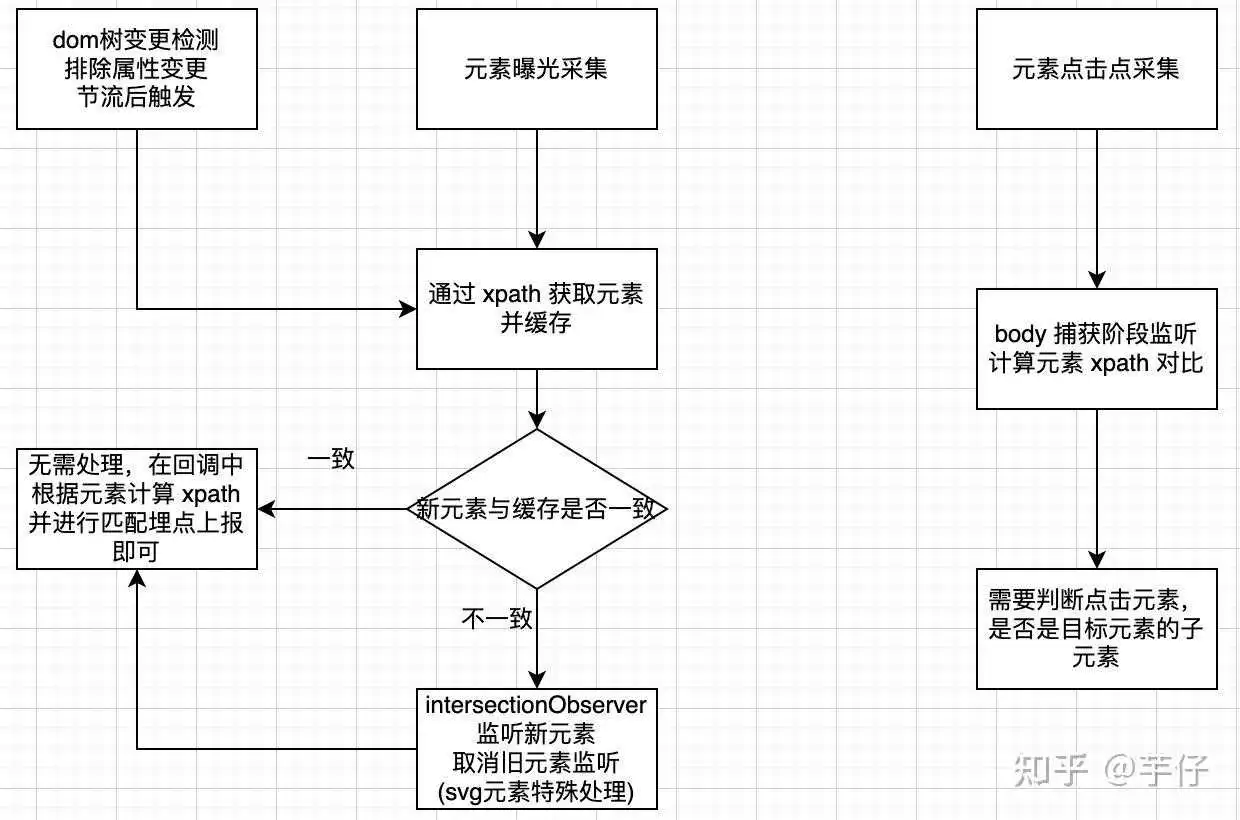
下面分别对其进行介绍:
首先是元素的曝光,目前基本都采用 intersectionObserver,该 api 兼容性也已经很高,同时也有 polyfill,基本上使用无虞。
对于元素的曝光埋点,理论上仅遍历一次埋点列表的 xpath,通过前文元素唯一标识介绍的方法 getEleByXpath,找到对应的元素并使用 intersectionObserver 进行监听即可。
但是不出意外的话,意外便发生了。
在实际的应用场景中,存在 dom 树变更的场景,此时需要借助 mutationObserver 来进行 dom 树的监听
- dom 树变化,原本不存在的元素可能就出现了,原本存在的元素消失了,如果不做 unobserver 的话,会存在内存泄漏问题
- 埋点数量较多的话,遍历可能会带来性能的损耗
- dom 树频繁变化,也会带来性能损耗
对于 dom 树变化带来的新旧元素的交替,可以存储一份 xpath -> dom node 的映射,在每次遍历时,对比新旧元素,新元素进行 observer, 旧元素进行 unobserver,来避免内存泄漏,其相关细节具体可参考前文,可视化埋点平台元素曝光采集的思路—intersectionObserver的实战经验。
而对于埋点数量多,遍历可以通过 requireIdleCallback 包裹执行,不过实际并不会存在太大的性能问题。
对于 dom 树频繁变化,一方面可以在 mutationObserver 的初始化时,由于属性的变化不会带来 dom 结构的变化,故可忽略属性的变化,减少 mutationObserver 触发的频率,而另一方面,也可通过消抖节流来减少频率。
元素点击的匹配相对而言会简单一些,只需要在 body 上捕获阶段监听 click 事件,通过计算 event.target 的 xpath,同埋点列表中的 xpath 进行匹配即可判定。但是当 xpath 不完全匹配时,还需要判断点击元素,是否是埋点元素的子元素,如果是子元素,那么也算是匹配,这是因为:
如果用户录入了一个按钮的元素,而该按钮内部有文字,图片等等其他元素,那么此时点击图片、文字,均可触发该按钮的曝光,故需要对父子元素的场景进行判定,认为符合点击条件,进行上报。
本章从元素唯一标识 xpath 讲起,做为圈选侧和采集侧沟通的标记。
接下来介绍了元素圈选的核心实现,通过计算元素大小、位置,在 mousemove 时为元素添加浮层,实现元素的圈选。
同时根据发布订阅模式,抽象了圈选平台页面和 iframe 页面的通信环节,为平台和 圈选 sdk 频繁通信打下基础。
最后介绍了采集侧匹配的方案,从而走通整个可视化埋点的核心链路。
上文介绍了整体的架构和圈选部分核心的细节,本章主要对整个系统的链路进行串联,以便更好的描述整个平台的逻辑。整体结构如下图:
平台侧的埋点录入页面,配合圈选 sdk,完成埋点的录入及验证(反向圈选),采集侧 sdk 通过对埋点进行匹配,对埋点数据进行收集,最终通过 node 服务对数据聚合后,在埋点平台进行可视化的数据呈现。
如上文所述,笔者可视化埋点平台的核心,便在于元素的唯一标记 xpath、iframe 通信及圈选器能力。
该方案能够实现预期的效果,对于大部分的场景,都能够满足,但是也存在一些边界问题:
- 元素唯一标记 xpath 的不稳定性及可能的重叠问题,需要进行改进
- h5 页面依赖 iframe,而 iframe 中,运行环境毕竟是浏览器,故实际情况可能与客户端内运行不一致,且存在登陆问题(iframe 跨域不携带 cookie问题)。
- pc 端页面的支持
其中,iframe 的依赖,可以通过将通信层改造成 websocket,圈选页面可以通过扫码在移动端打开,从而模拟和实际用户一摸一样的环境,也顺带解决了登陆问题。
而对于 xpath 的不稳定性,此处边界场景太多,后续会单独出一篇文章来介绍 xpath 在实际场景中遇到的重叠、不稳定问题,而解决后的 xpath 足以支撑非常复杂的移动端 h5 页面。
整体来讲,可视化埋点平台的搭建,还是比较有趣的一个项目,确实同我们平时的业务开发不同,在此过程中,笔者也熟悉了像 mutationObserver、intersectionObserver,这样的存在已久平时却也不接触的原生 api,也熟悉了出现很久的 xpath,而 dom 树的可视化、列表元素的判定,也是比较有趣的一些开发过程。
同时该平台也确实可以减轻产品/运营、开发埋点的不便,整体的方案及细节相信本文也讲的比较详细了,觉得还不错的话可以点赞鼓励下哦。
到此这篇前端数据埋点实现(前端数据埋点实现方法)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/sjkxydsj/69616.html