
CRUD:Create(创建), Retrieve(查找), Update(修改), Delete(删除).
语法:
插入测试
案例:
插入否则更新
假设现在数据量非常大,我们不知道之前有什么数据而且现在想要插入新的数据,如果和之前的数据冲突就使用现在的数据覆盖之前的数据。
语法:
案例:
受影响的行数
语法:
案例:
结论:replace功能上等同于上面insert的on duplicate key,不过字数更少。
案例:
全列查找
指定列查找
查询字段为表达式
字段重命名
语法:
案例:
结果去重
比较运算符:
逻辑运算符:
这些运算符可以在SELECT语句的WHERE子句中使用,用于对表中的数据进行条件判断和过滤。
案例:
英语不及格的同学及英语成绩(<60)
语文成绩在 [80, 90] 分的同学及语文成绩
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
姓陈的同学 及 陈某同学
语文成绩好于英语成绩的同学
总分在 200 分以下的同学
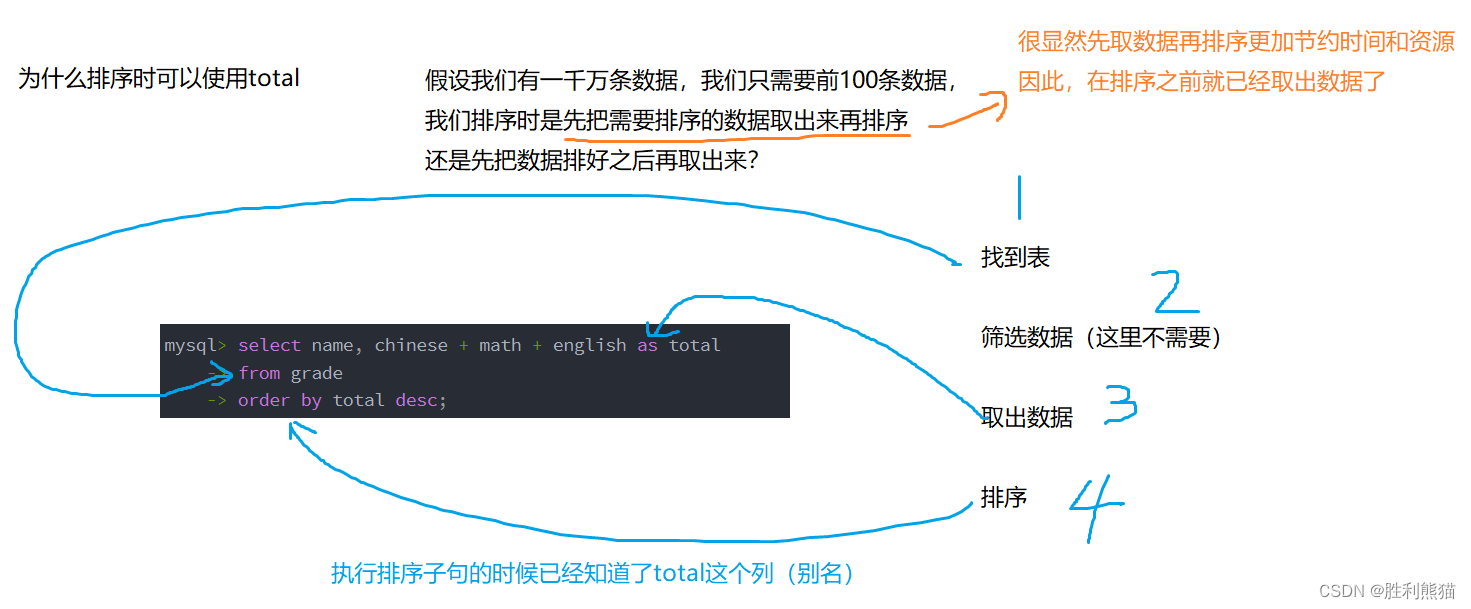
拓展1:语句的执行顺序(重要,下面还会涉及)

语文成绩 > 80 并且不姓陈的同学
陈某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
NULL 的查询
语法:
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
案例:
同学及数学成绩,按数学成绩升序显示
带有null的排序
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
查询同学及总分,由高到低
查询姓陈的同学或者姓魏的同学数学成绩,结果按数学成绩由高到低显示
语法:
语法:
案例:
将陈平安同学的数学成绩变更为 80 分
将刘羡阳同学的数学成绩变更为 60 分,语文成绩变更为 70 分
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
将所有同学的语文成绩更新为原来的 2 倍
注意:更新全表的语句慎用!
语法:
案例:
删除陆沉同学的考试成绩
删除整张表
删除操作只会删除表中的数据,并不会影响表的结构,并且delete删除时并不会重置auto_increment计数。
语法:
注意:该语法慎用
- truncate只能对整表操作,不想delete可以删除部分数据;
- truncate实际上不对数据进行操作,因此比delete速度更快,但是truncate不经过事物,因此无法回滚(以后的文章会讲);
- truncate会重置auto_increment计数。
案例:
语法:
案例:
统计班级共有多少同学
统计本次考试的数学成绩分数个数
统计数学成绩总分
统计平均总分
返回英语最高分
返回 > 70 分以上的数学最低分
在select中使用 order by 子句可以对指定列进行排序,且默认排升序。
补充:以下是一张员工表:
补充:获取员工的 员工号、员工姓名和工资(注: 工资为基础工资 + 奖金),并且按照工资的升序排列。
为了探究员工工资与入职时间长短是否有关系,下面我要获取员工的员工号、员工姓名、入职时间以及工资,并且入职时间从早的员工排在前面,如果入职时间相同,工资越高排名越靠前。
问题拆解:获取的信息已经告诉了我们:员工号、员工姓名、入职时间、工资;
关于排序,入职时间早的排在前面,也就是对入职时间排升序(order by 默认就是升序);
入职时间相同,工资越高排名越靠前,也就是入职时间相同时对工资排降序;
下面我们就来讲一讲order by 的其他一些用法:
在最开始给出的 order by 语法中我们看到 order by 子句后面可以跟很多列,并且后面还有一对中括号[asc, desc],
而当我们在 order by 后面跟很多列时,排序规则为:第一列先排列,第一列相同再采用第二列的排序规则,第二列也相同再…
再之后的 asc 既:升序(Ascending Order),desc既:降序(Descending Order)。
知道了上面的规则,下面我们开始完成上面的要求:
由于没有入职时间相同的,因此这里看不出:入职时间相同时,按照工资降序排列,但是我们可以很明显地看出:入职时间确实是降序,但是工资并不是有序的,为什么?因为只有在入职时间(column1) 相同时才会继续比较后面的列(column2, …) ,当入职时间(column1) 能够比较出大小时就不需要比较后面的列(column2, …) .
在select中使用group by 子句可以对指定列进行分组查询
统计男生数学平均分
统计男女数学平均分
在MySQL中,当使用GROUP BY子句对结果进行分组时,SELECT语句中的列可以包含两种类型:聚合函数和分组列。
- 聚合函数:例如AVG、SUM、COUNT等,用于对分组后的数据进行计算,返回一个单一的结果值。
- 分组列:用于指定分组的条件,这些列的值相同的记录会被归为一组。
根据SQL的标准规定,在SELECT语句中,如果包含了分组列,那么SELECT列表中的非聚合列必须是分组列或者通过聚合函数进行计算的列。这是为了保证查询结果是明确的,每个分组只有一行结果。
显然,id列既不是分组列也不是聚合函数。
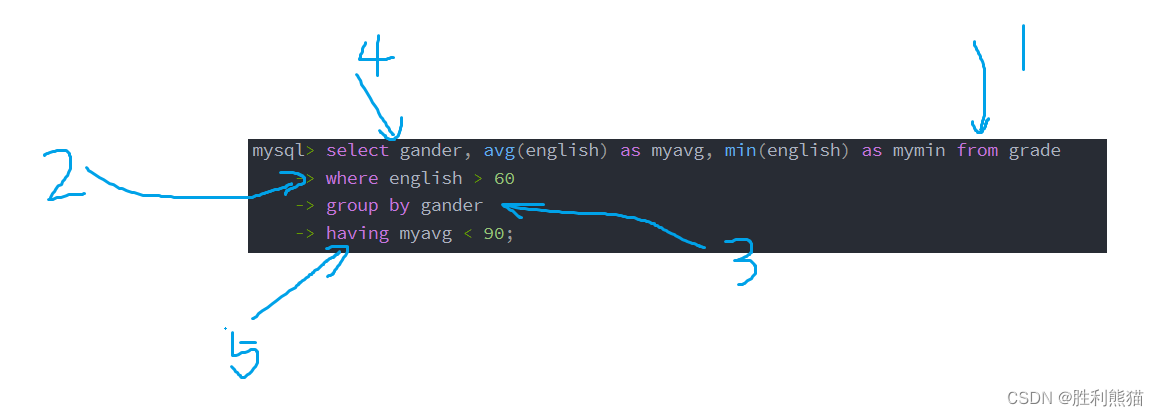
统计男女英语成绩的平均分,平均分 < 60 则显示平均分和最低分
having子句的执行顺序

男女英语成绩 > 60 的 同学的平均值,低于90时输出他们的均值和最小值
where与having都是用来筛选结果的,但是它们的应用范围和执行顺序并不相同:
上方例子中,查询的操作顺序如下:
- 通过WHERE子句筛选出满足条件(英语成绩大于60)的行。
- 根据gander列进行分组。
- 计算每个分组中英语成绩的平均值和最小值。
- 通过HAVING子句筛选出满足条件(平均值小于90)的分组。
- WHERE子句:
- WHERE子句用于在执行SELECT语句时对表中的行进行筛选。
- WHERE子句通常出现在FROM子句之后,且在GROUP BY子句之前。
- WHERE子句可以包含任意的条件表达式,用于过滤满足条件的行。
- WHERE子句过滤的是表中的原始数据,即在进行分组之前进行过滤。
- HAVING子句:
- HAVING子句用于在执行SELECT语句后对分组后的结果进行筛选。
- HAVING子句通常出现在GROUP BY子句之后。
- HAVING子句可以包含任意的条件表达式,用于过滤满足条件的分组。
- HAVING子句过滤的是分组后的结果,即在进行分组之后进行过滤。
补充:获取不同部门各个岗位的平均薪资
问题拆解:不同部门,不同岗位,平均薪资 --> 安装部门和岗位分组,求薪资平均值
要理解子句的执行顺序,不需要死记硬背,按照逻辑一步一步走一遍就理解啦!
(先执行的在前面:from > where > group by > select > having > order by)
到此这篇MySQL增删改查(MySQL增删改查命)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/sqlbc/36768.html