
数据传输支持实时同步任务的创建、管理。
版本:2.0.1,认证方式:Kerberos认证
版本:2.3.1,认证方式:无认证(仅支持读)
版本:2.3.1,认证方式:SASL_Plaintext(仅支持读)
版本:2.7.1,认证方式:无认证(仅支持读)
版本:2.7.1,认证方式:SASL_Plaintext(仅支持读) MySQL 支持 支持 版本:5.7、8.0 Oracle 支持 支持 版本:11g、12g、19c PostgreSQL 支持 不支持 版本:13.2 TeleDB 支持 不支持 版本:5.7 SQLServer 支持 支持 版本:2012、2016、2017、2019 TelePG 支持 不支持 版本:42.2.9 Hive 不支持 支持 平台内置Hive集群 Iceberg 不支持 支持 平台内置Iceberg集群,版本:1.2.0 Kudu 不支持 支持 版本:1.16.0 StarRocks 不支持 支持 版本:1.19、2.4、3.2 Doris 不支持 支持 版本:1.1、1.2、2.0 Paimon 不支持 支持 版本:0.8
功能入口: 在数据传输页面,选择左侧导航栏“实时同步任务”,点击“新建任务”进入任务创建页面。
选择数据来源
首先配置数据来源,在选择数据来源环节配置任务基本信息和选择数据来源。
任务基本信息
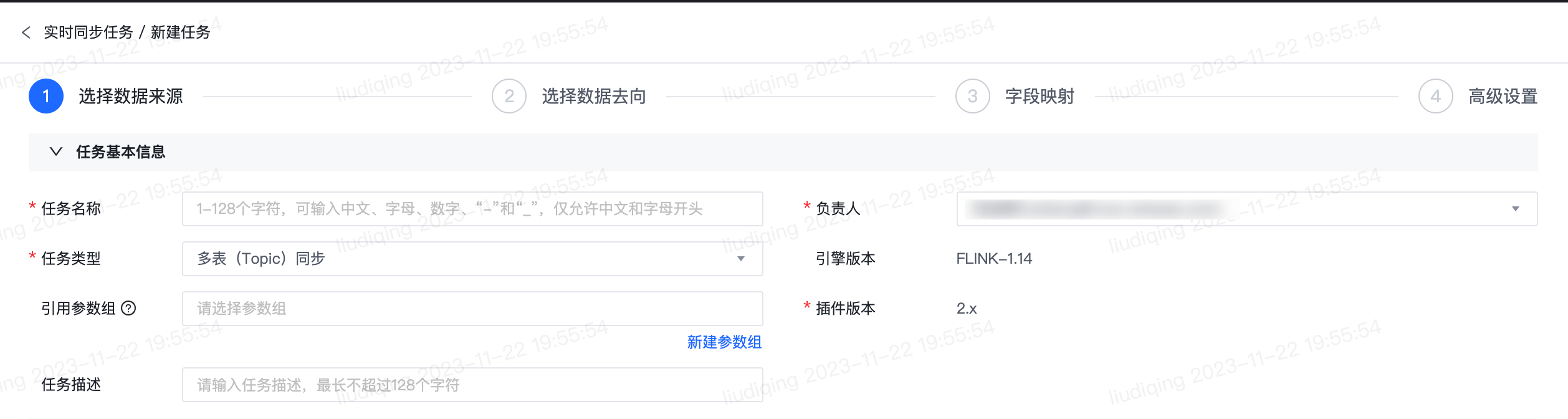
注意:同一项目-集群下不允许存在同名任务 负责人 可选择项目下任意成员,默认为创建任务的用户 任务类型 在实时传输任务中,如需将表结构不一致的多张来源表分别同步至不同的去向表(Topic),任务类型请选择多表(Topic)同步;如需将表结构一致的多张分库分表同步至同一去向表(Topic),任务类型请选择分库分表同步。 引擎版本 当前仅支持FLINK-1.14版本 引用参数组 参数组的使用场景:
1)任务导入导出时对库名、Topic名等进行替换。
2)任务常用的高级配置-自定义参数配置为参数组,可实现不同任务间的自定义参数复用。
功能使用注意事项:
1)同一实时同步任务内多个参数组内有相同参数项时,系统取排在前面的参数组的参数值。
2)如果字段映射支持的内置变量与参数组参数冲突时,内置变量优先级更高。
3) 如果高级设置填写的参数与参数组参数冲突时,则高级设置填写的参数优先级更高。
4)如果导入引用参数组的实时同步任务时,会检测导入端是否存在同名参数组,如不存在则检测不通过,导入失败。如导入端存在同名参数组,则在导入端会将任务引用的参数组id替换为导入端同名参数组的id。
功能详细使用步骤:
数据传输-实时同步任务:“引用参数组”配置项选取需引用的参数组。
1)如参数组的使用场景是:任务常用的高级配置-自定义参数配置为参数组,可实现不同任务间的自定义参数复用,则“引用参数组”配置项选取需引用的参数组即可。
2)如参数组的使用场景是:任务导入导出时对库名、Topic名等进行替换,除“引用参数组”配置项选取需引用的参数组外,请在使用变量处按照${参数组名称}的格式填写参数组参数。示例详见下图。
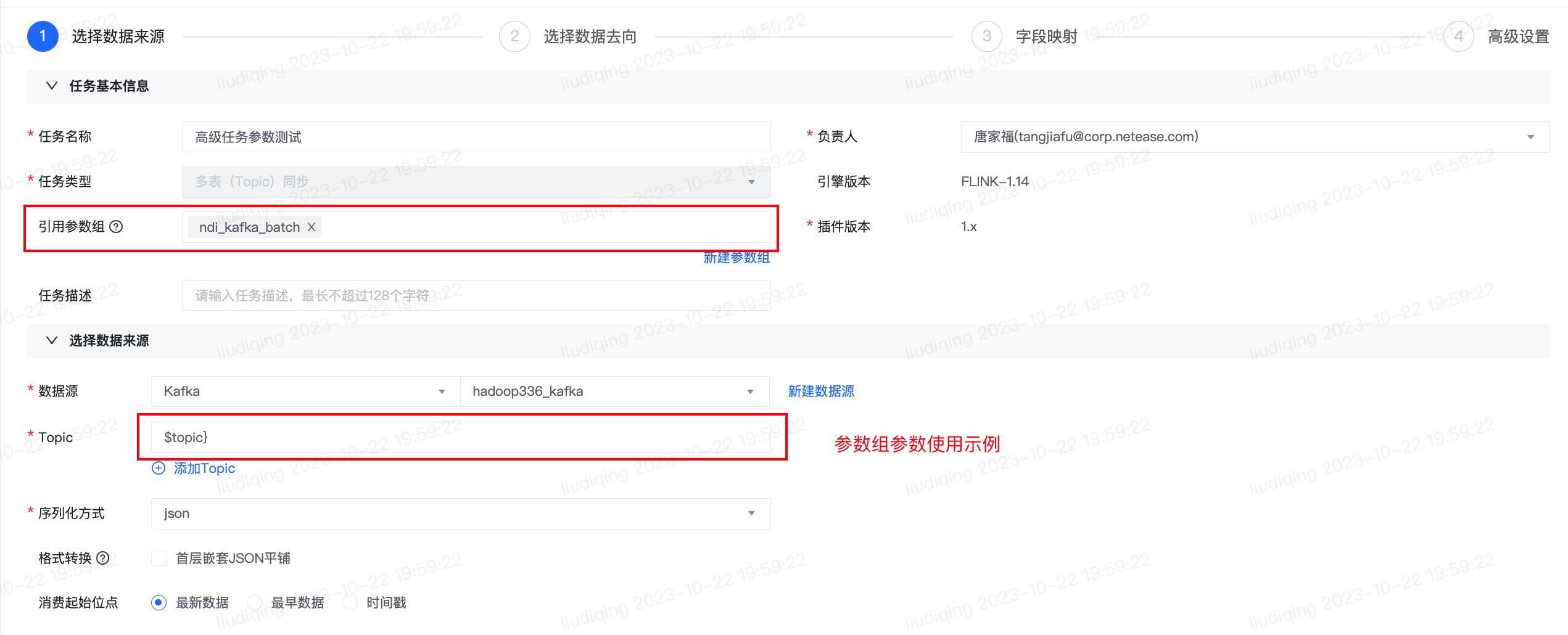
支持使用参数组参数的位置包含:
1)数据来源:
- 数据源类型为Kafka-【topic名称】
- 任务类型为多表同步,数据源类型为MySQL、Oracle、TeleDB、SQLServer-【数据库名称】
- 任务类型为多表同步或分库分表同步,数据源类型为Oracle,增量读取方式为ogg-【Topic名称】
- 来源为Kafka、消费起始位点为时间戳
- 来源为MySQL、消费起始位点为时间戳
- 来源为MySQL、消费起始位点为指定binlog日志-binlog日志位置
- 来源为Oracle、增量读取方式为logminer、消费起始位点为时间戳
- 来源为Oracle、增量读取方式为logminer、消费起始位点为指定scn
- 来源为Oracle、增量读取方式为ogg、消费起始位点为时间戳
- 来源为SQLServer、消费起始位点为指定lsn
- 来源为TeleDB、消费起始位点为指定binlog日志-binlog日志位置
- 来源为TelePG、消费起始位点为指定lsn
2)数据去向:
- 数据源类型为Kudu-【去向表名】
- 数据源类型为Iceberg、Arctic、Hive-【去向库名】和【去向表名】
- 数据源类型为Kafka-【去向Topic】
3)字段映射:
数据去向为Kudu、Iceberg、Arctic、Hive时,来源表字段类型为自定义表达式时,支持填写参数组参数。 引擎版本 当前仅支持FLINK-1.14版本 插件版本 支持的插件版本含:1.x、2.x,新建任务仅支持2.x版本。
选择数据来源
1、Kafka Redaer
1)如果选择json,解析Topic schema时仅解析首层字段。
示例:
{"table":"OGG_TEST.ORDERS","op_type":"I","op_ts":"2020-05-29 10:01:27.000067","current_ts":"2020-05-29T18:01:33.062000","pos":"000000048","after":{"OID":"1","PID":"2","NUM":"3"}}
则字段映射中来源Topic字段为:table、op_type、op_ts、current_ts、pos、after。
2)如果选择canal json,解析Topic schema时除data字段外仅解析首层字段,data嵌套字段内则子字段作为来源Topic字段。
示例:
insert
{"data":[{"id":22,"name":"opt","age":123,"address":"北京市"}],"type":"INSERT"}
update
{"data":[{"id":22,"name":"opt","age":123,"address":"北京市"}],"type":"DELETE"}
{"data":[{"id":22,"name":"opt11","age":123,"address":"北京市"}],"type":"INSERT"}
delete
{"data":[{"id":22,"name":"opt11","age":123,"address":"北京市"}],"type":"DELETE"}
则字段映射中来源Topic字段为:id、name、age、address、type。
3)如果选择debezium-json,解析Topic schema时除before/after字段外仅解析首层字段,以before/after嵌套字段内的子字段作为来源Topic字段。
示例:
insert
{"before":null,"after":{"id":22,"name":"opt1","age":null},"op":"c"}
update
{"before":{"id":22,"name":"opt1","age":null},"after":null,"op":"d"}
{"before":null,"after":{"id":22,"name":"opt1123","age":null},"op":"c"}
delete
{"before":{"id":22,"name":"opt1123","age":null},"after":null,"op":"d"}
则字段映射中来源Topic字段解析为:id、name、age、op。 格式转换 序列化格式为json时,支持格式转换。
如勾选首层嵌套JSON平铺,会将首层中类型为row或map的嵌套字段解析为row类型并分解为单层结构,字段名称为“首层字段名称.次层字段名称”。
示例Topic:
{ "obj": { "time1": "12:12:43Z", "str": "sfasfafs", "lg": { "name": "1" }, "num": 3 }, "arr": [ { "f1": "f1str11", "f2": 134 }, { "f1": "f1str22", "f2": 555 } ], "map": { "key1": 234, "key2": 456 } }
则字段映射中来源Topic字段解析为:obj.time1、obj.str、obj.lg、num、arr、map.key1、map.key2。 消费起始位点 支持从最新数据、最早数据、指定时间戳开始读取。
如从指定时间戳开始读取,请按“yyyy-MM-dd HH:mm:ss.SSS”格式填写,其中“.SSS”可不填。 注意事项 如勾选首层嵌套JSON平铺,除解析出的“首层字段名称.次层字段名称”的列名外,首层和次层的字段名称不允许再包含“.”。如果首层或次层名称包含“.”,例如,首层字段名称:a.bc,此处字段名称:d.ef,则字段映射时请使用自定义表达式:`a.bc`.`d.ef` as 列名 表示该字段。
2、MySQL Redaer、Oracle Reader、PostgreSQL、TeleDB Reader、SQLServer Reader、TelePG Reader
MySQL、Oracle、PostgreSQL、TeleDB、SQLServer、TelePG的配置类似,故此处以TeleDB为例进行详细介绍。
1)多表(Topic)同步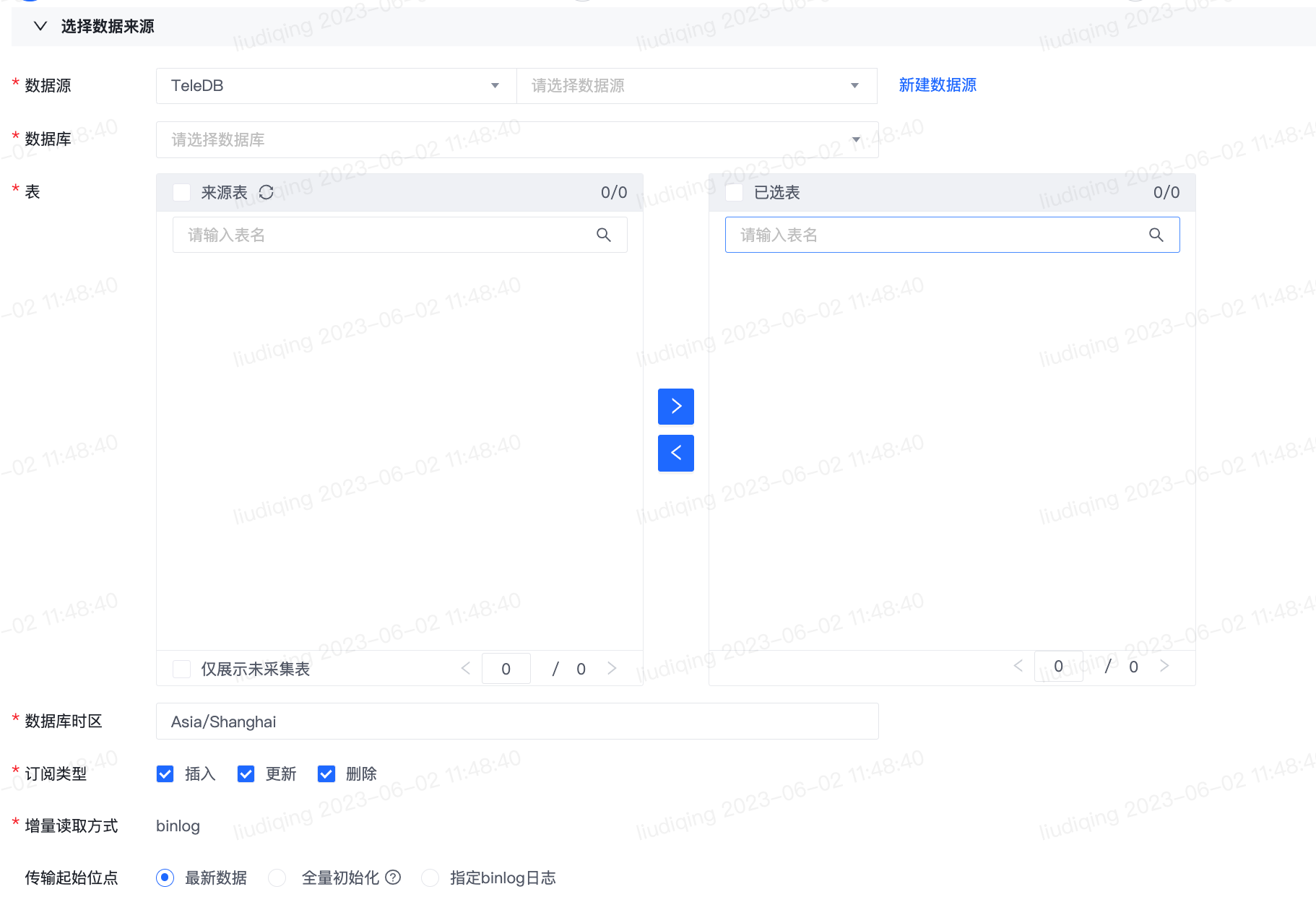
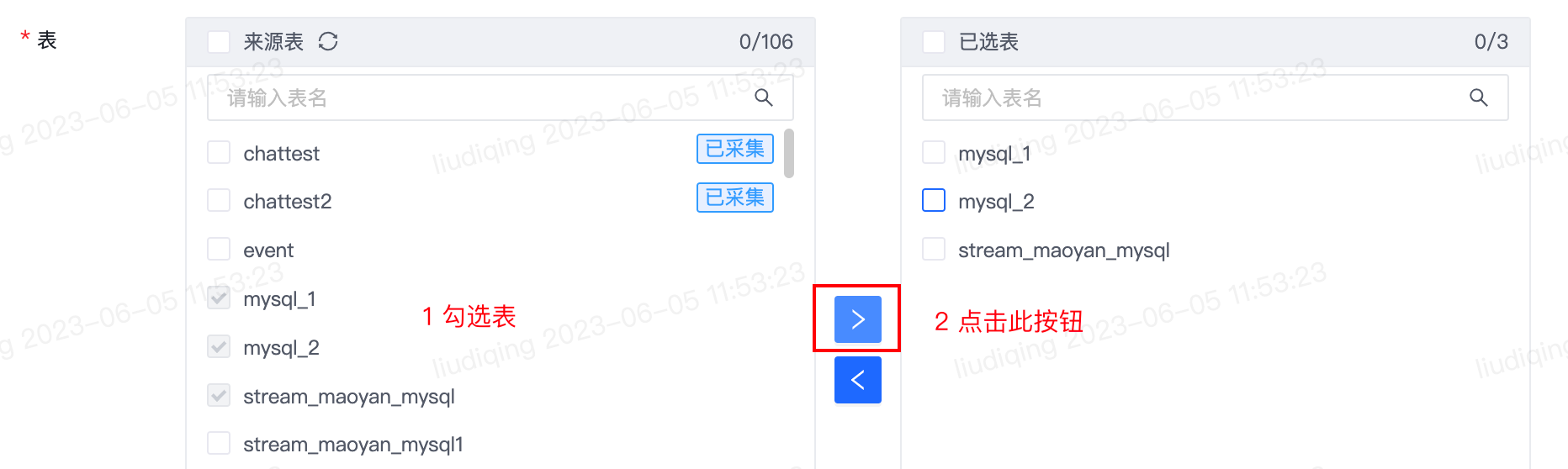
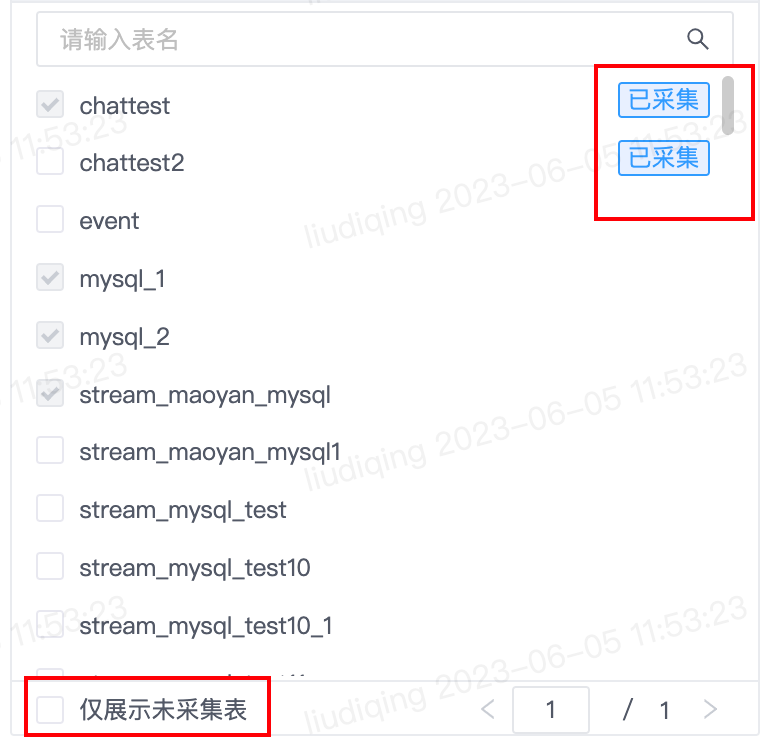
注意:如某张来源表已被项目-集群内的其余实时同步任务采集,则表名后会展示“已采集”的标签,鼠标停留在标签时会提示已采集该表的任务名称。如仅需展示未采集表,可在穿梭框下方勾选“仅展示未采集表”。

数据库时区 请选择数据库的时区,支持模糊搜索。 默认值为Asia/Shanghai。 订阅类型 订阅类型包含:插入(Insert)、更新(Upsert)、删除(Delete),意指binlog的数据库变更类型,可多选,建议全选。 增量读取方式 由该数据库类型决定 消费起始位点 支持从最新数据、全量初始化、指定binlog日志开始读取。如选取全量初始化,则会先同步来源表的历史全量数据再实时同步增量更新数据,块大小和批量条数可根据需求自行调优。全量初始化默认开启并发读取,如果来源表存在主键则以主键作为切分键并发读取,如果来源表不存在主键则默认并发度为1。
2)分库分表同步
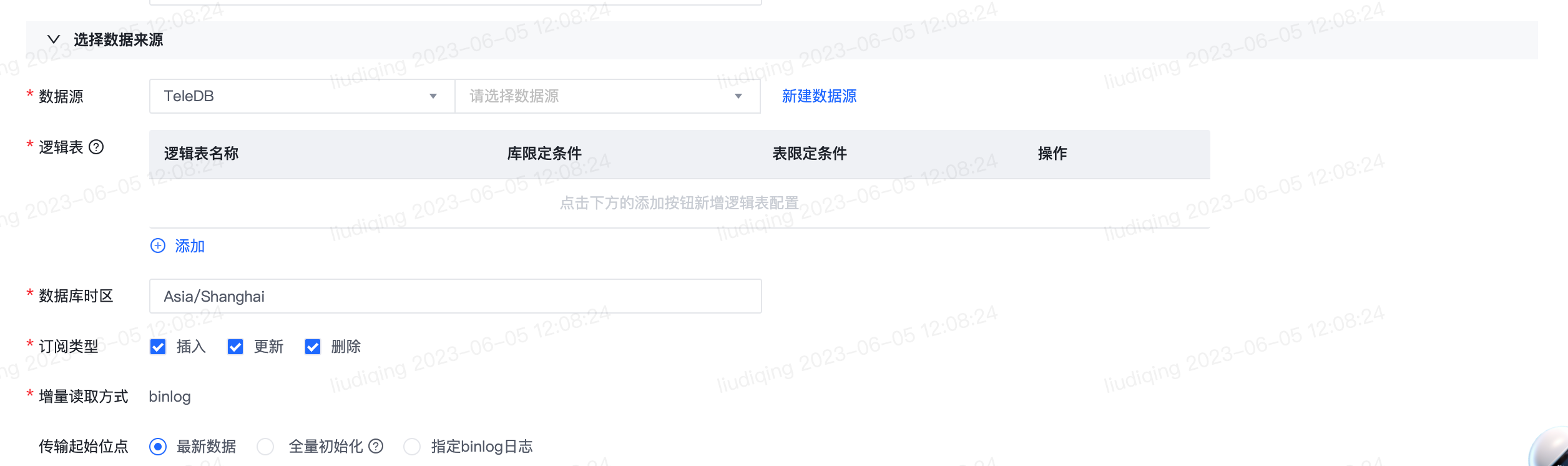
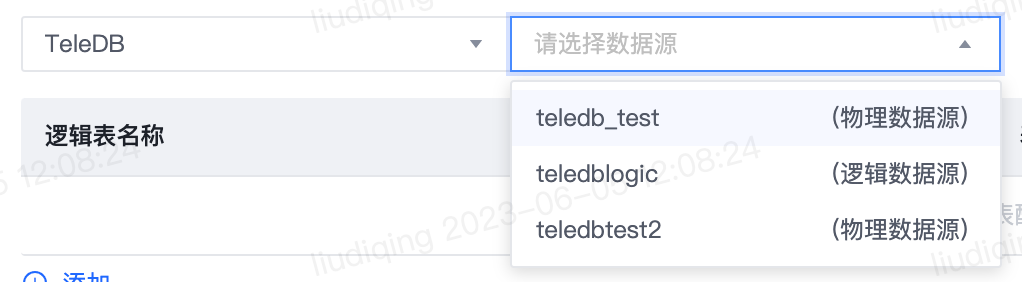
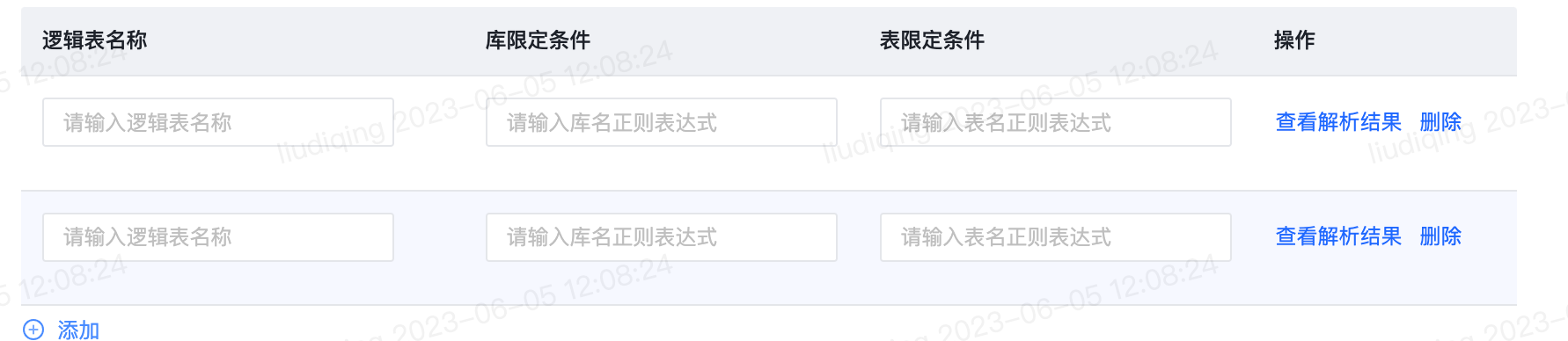
逻辑表 对于分库分表,表结构一致的分库分表对应于1个逻辑表。 请在此处依次逻辑表名称、分库分表的库名正则表达式和表名正则表达式。 点击查看解析结果,可查看符合正则匹配结果的前10张表,用于确认表达式填写是否准确无误。
数据库时区 请选择数据库的时区,支持模糊搜索。 默认值为Asia/Shanghai。 订阅类型 订阅类型包含:插入(Insert)、更新(Upsert)、删除(Delete),意指binlog的数据库变更类型,可多选,建议全选。 增量读取方式 由该数据库类型决定 消费起始位点 支持从最新数据、全量初始化、指定binlog日志开始读取。如选取全量初始化,则会先同步来源表的历史全量数据再实时同步增量更新数据,块大小和批量条数可根据需求自行调优。全量初始化默认开启并发读取,如果来源表存在主键则以主键作为切分键并发读取,如果来源表不存在主键则默认并发度为1。
点击“下一步”进行数据去向配置。
选择数据去向
1、Hive、Iceberg、Arctic、MySQL、Oracle、SQLServer、StarRocks、Doris、Kudu Writer
去向为Hive、Iceberg、Arctic、MySQL、Oracle、SQLServer、StarRocks、Doris、Kudu时,配置相似,仅当去向为Hive时额外支持任务过程中创建Hive表。 故此处以Iceberg为例进行详细介绍。
数据源名称:仅当当前集群存在绑定的Iceberg数据源时,此处可选择Iceberg数据源。数据源名称格式为:项目-集群 Iceberg数据源,可选择当前项目-当前集群的Iceberg数据源和在安全中心存在库表公开给当前项目的其余项目-当前集群的Iceberg数据源。 设置来源表与去向表映射 请选择各来源表对应的去向Iceberg库表。如任务类型为分库分表同步时,此处选择各来源逻辑表对应的去向Iceberg库表。
批量设置源表和去向表映射:
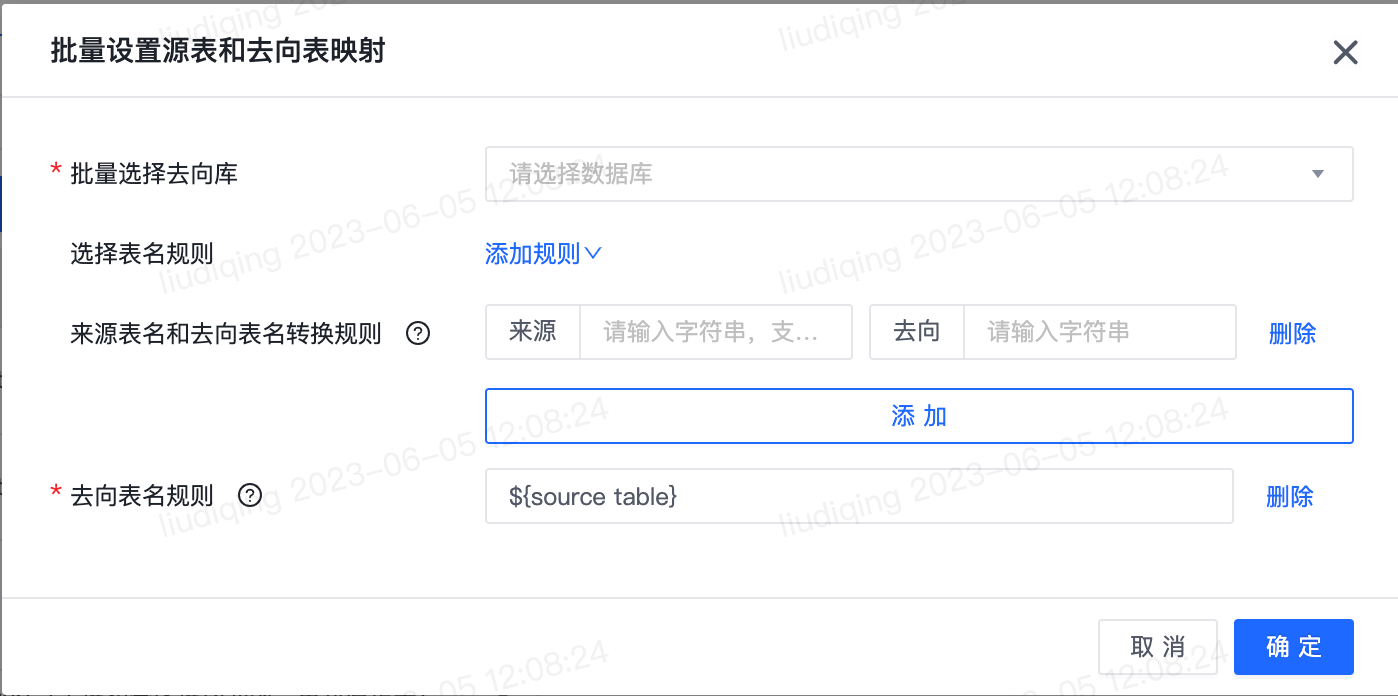
注意:任务类型为多表(Topic)同步、去向为Hive和MySQL时,请勿将多张来源表写入同一去向表,否则任务运行会报错!! 1)批量选择去向库:选中的数据库将批量填充“设置来源Topic和去向表映射”处的去向库名
2)选择表名规则:来源表名和去向表名转换规则 和 去向表名规则可任选其一或组合使用。
-来源表名和去向表名转换规则 :所有的该转换规则都是针对原始表名的转换,转换完成之后的结果可以使用${source table transed},在“去向表名规则”中作为变量来使用。
注意:
1、如果不使用“去向表名规则”,则此规则将直接影响最终实际去向表名。
2、如果使用“去向表名规则”,则此规则将只影响变量${source table transed}的值,不直接影响最终实际去向表名。
-去向表名规则:
1)可以使用内置的变量命名去向表名,比如给表名加前缀“AAA ”,可以使用 AAA${source table transed}。
2)可使用的内置变量如下:
1、${source table}:任务类型为多表(Topic)同步时,表示来源表名;任务类型为分库分表同步时,表示来源逻辑表名。
2、${source database}:任务类型为多表(Topic)同步时,表示来源库名;任务类型为分库分表同步时,此变量不生效。
3、${source datasource}:表示来源数据源名称。
4、${source table transed}:“来源表名和去向表名转换规则”中的转换完成之后的表名。
写入分区 如写入表为分区表,需配置写入分区。支持根据数据写入时间分区、根据字段内容动态分区和根据数据生成时间分区。
1)分区方式为根据数据生成时间分区或根据数据写入时间分区时,支持填写内置变量:yyyy、MM、dd、HH、mm、ss,分别表示数据生成时间/数据写入时间的年、月、日、时、分、秒,支持多个内置变量组合使用,如:yyyy-MM-dd,表示数据生成时间/数据写入时间的当日,示例:2022-01-02。
2)分区方式为根据字段内容动态分区时,支持选择来源表字段,会将源端对应字段所在数据行写入到表对应的分区中。示例:选择来源表字段为A,当A字段值为aa时,实时同步会将数据写入到对应的aa分区中,当A字段值为bb时,实时同步会将数据写入到对应的bb分区中。
3)请保证所有去向表的分区结构保持一致,否则任务可能运行失败。 写入规则 支持的写入规则为:insert into(追加)、upsert(主键和分区键均冲突,覆盖原记录)。
注意:使用upsert要求Iceberg表同时满足两个条件:1、版本是V2,2、有主键或分区键,否则任务会报错。
2、Kafka Writer
数据源名称:仅可选择当前项目组下该数据源类型的数据源。 设置来源表(Topic)与去向Topic映射 请选择各来源表(Topic)对应的去向Topic。
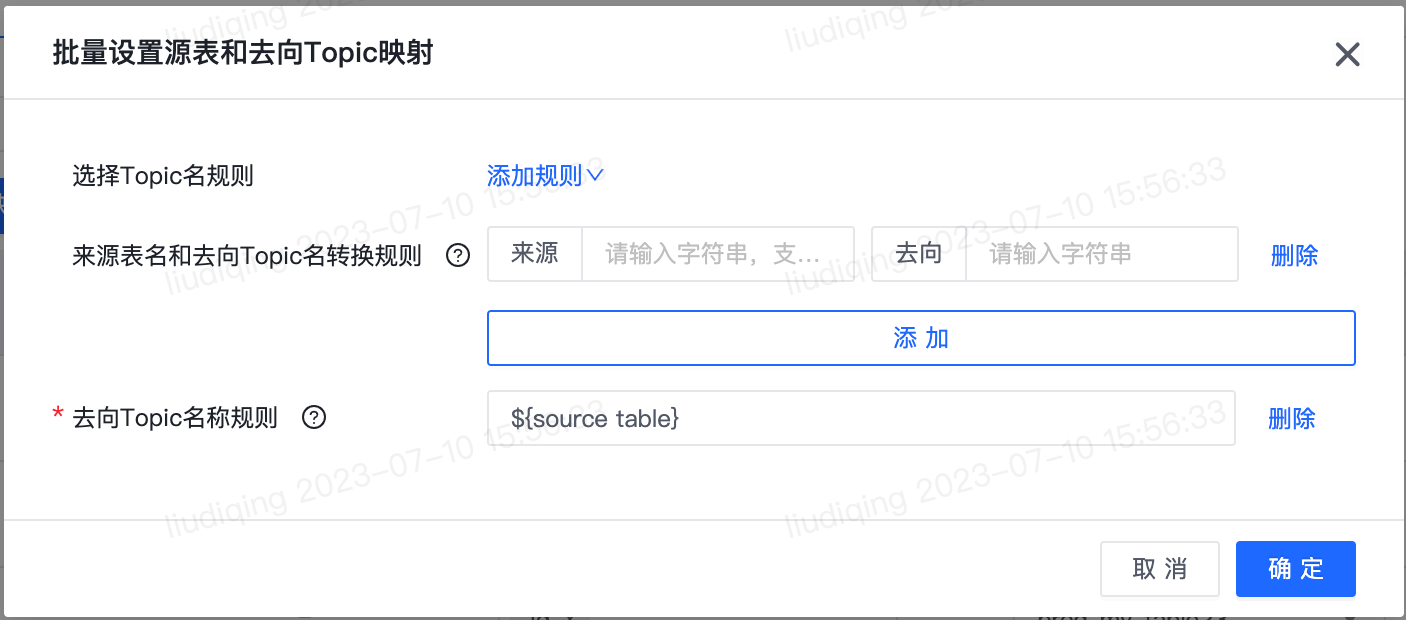
批量设置源表(Topic)和去向Topic映射: 1)选择Topic名称规则:来源表名和去向Topic名转换规则 和 去向Topic名称规则可任选其一或组合使用。
-来源表名和去向表名转换规则 :所有的该转换规则都是针对原始表名的转换,转换完成之后的结果可以使用${source topic transed},在“去向Topic名称规则”中作为变量来使用。
注意:
1、如果不使用“去向Topic名称规则”,则此规则将直接影响最终实际去向Topic名称。
2、如果使用“去向Topic名称规则”,则此规则将只影响变量${source topic transed}的值,不直接影响最终实际去向Topic名称。
-去向表名规则:
1)可以使用内置的变量命名去向Topic名,比如给Topic名加前缀“AAA ”,可以使用 AAA${source table transed}。
2)可使用的内置变量如下:
1、${source table}:任务类型为多表(Topic)同步时,表示来源表名;任务类型为分库分表同步时,表示来源逻辑表名。
2、${source database}:任务类型为多表(Topic)同步时,表示来源库名;任务类型为分库分表同步时,此变量不生效。
3、${source datasource}:表示来源数据源名称。
4、${source topic transed}:“来源表名和去向Topic名称转换规则”中的转换完成之后的Topic名。
同步主键 来源为除Kafka外数据源类型时,需要设置同步主键。
1)同步时会使用同步主键值作为Kafka记录的key,确保同主键的变更有序写入Kafka的同一分区。
2)如来源表有主键,建议使用来源表字段作为同步主键;如来源表无主键,建议使用其他非主键的 一个或几个字段的联合,代替主键作为Kafka记录的key,选取多个字段联合作为同步主键,字段拼接时字段间以;分隔。
3)如同步主键为空,则同步时Kafka记录的key为空。如果要确保表的变更有序写入Kafka,则选择写入的Kafka Topic必须是单分区。 序列化方式 1)支持的序列化格式为json、canal-json、debezium-json、maxwell-json、ogg-json。
2)来源为Kafka、去向为Kafka时,去向的序列化格式要求与来源的序列化格式保持一致。 update变更对应一条记录 1)序列化格式为canal-json、debezium-json、maxwell-json、ogg-json时,支持此功能。 2)勾选后,源端数据库一条记录的一次update变更,变更前和变更后的数据将保存在一条记录中。 3)如未勾选,源端数据库一条记录的一次update变更,将保存在两条记录中,分别保存变更前和变更后的数据。
完成数据去向配置后,点击“下一步”进行字段映射配置。
字段映射
除来源为Kafka且去向为Kafka外,其余数据来源和去向的组合均需配置字段映射。
字段映射支持使用的内置变量如下:
(1)来源为MySQL,去向为Hive、Iceberg、Kudu、Arctic:${op}、${op_ts}
(2)来源为TeleDB,去向为Hive、Iceberg、Kudu、Arctic:${op}、${op_ts}
(3)来源为Oracle、去向为Hive、Iceberg、Kudu、Arctic:增量读取方式为logminer,支持填写${op}、${op_ts}、${scn};增量读取方式为ogg,支持填写${op}、${op_ts}
(4)来源为SQLServer,去向为Hive、Iceberg、Kudu、Arctic:${op}、${op_ts}、${change_lsn}
(5)来源为TelePG,去向为Hive、Iceberg、Kudu、Arctic:${op}、${op_ts}、${lsn}
(6)来源为Kafka且序列化格式非json、去向为Hive、Iceberg、Kudu、Arctic:${op}。此外,当序列化格式为ogg-json时,支持${pos}、${op_ts}、${current_ts}、${source table}
内置变量填写方式:来源表字段选择为自定义表达式,并按照${变量名称}格式输入内置变量,可参照下图。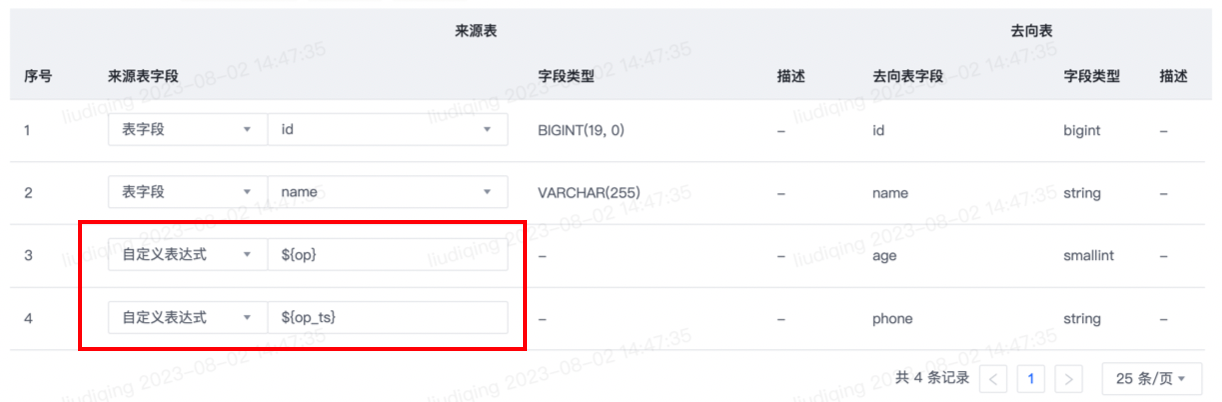
在映射配置中分为全局映射配置和单个来源表(Topic)-去向表(Topic)映射配置。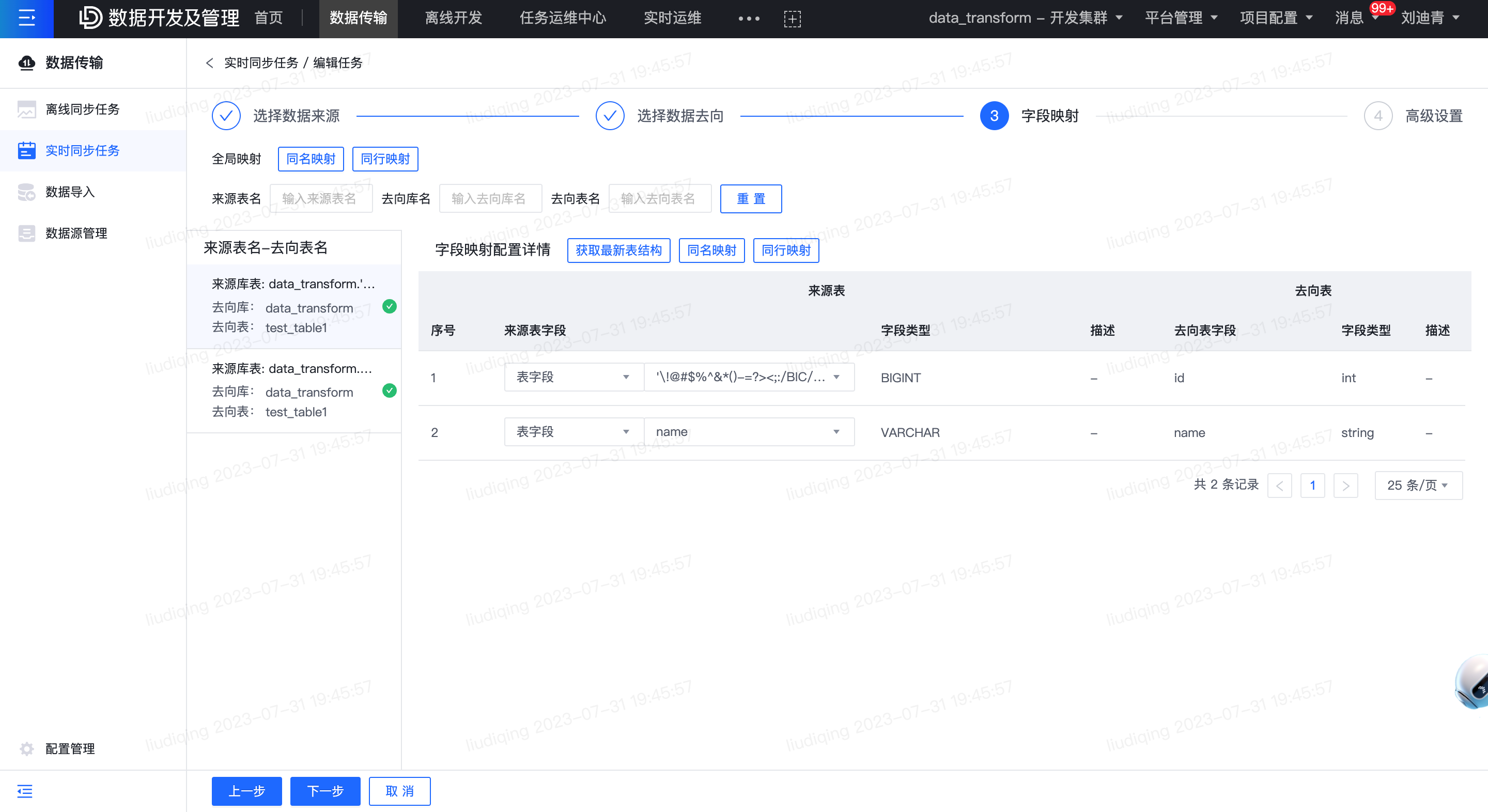
同名映射:根据去向表字段名称匹配同名的来源Topic字段名称,若无法匹配则来源Topic字段置为自定义表达式。
同行映射:根据去向表字段序号匹配序号相同的来源Topic字段名称,若无法匹配则来源Topic字段置为自定义表达式。 来源Topic-去向表 支持根据来源Topic、去向库名、去向表名搜索符合搜索条件的Topic-表映射。
在页面左侧切换Topic-表映射时,可针对选中的Topic-表映射配置字段映射。
对于单个Topic映射配置支持“获取最新表结构”、“一键解析Topic字段”、“同名映射”、“同行映射”、“设置自定义表达式字段类型”。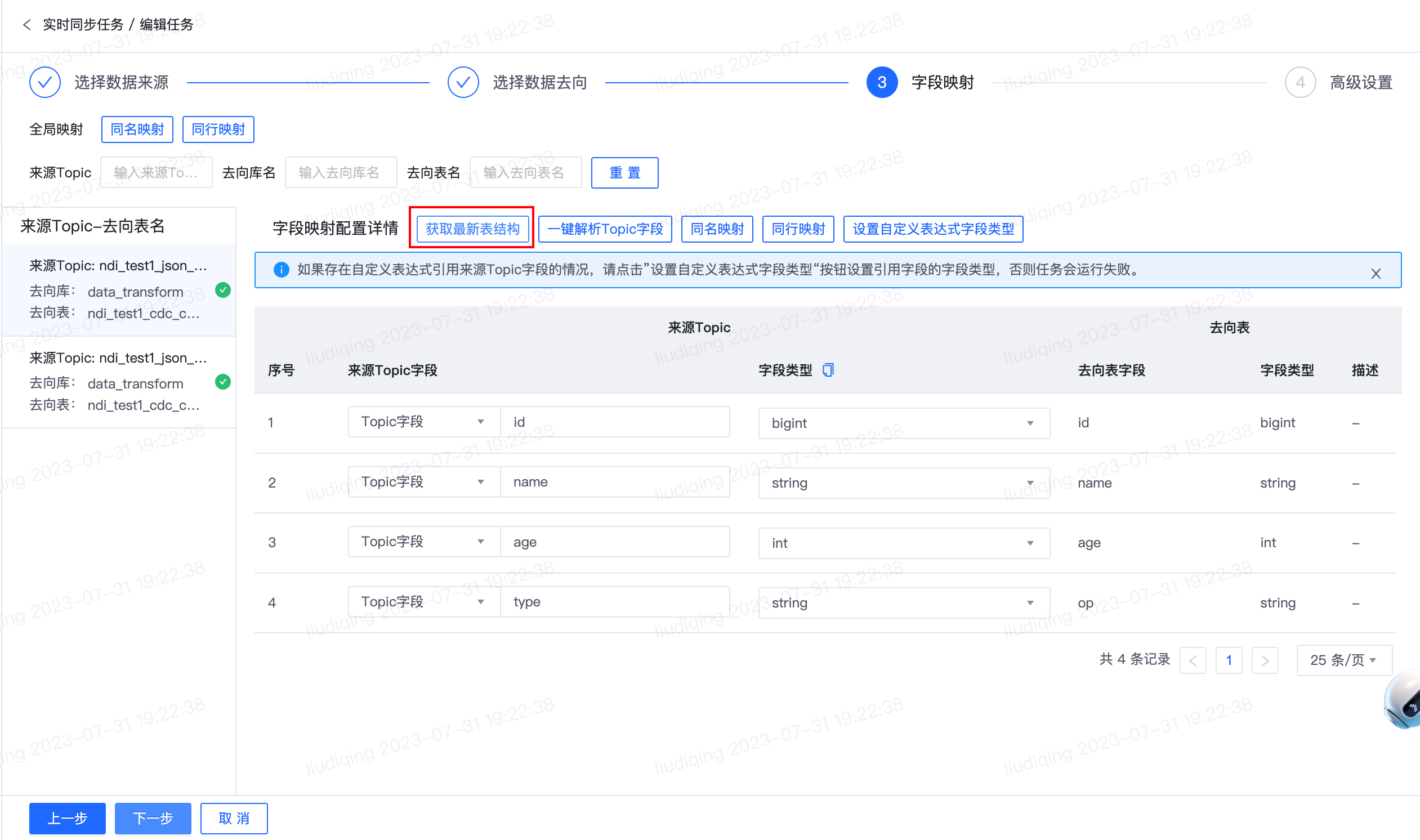
a.新增字段及字段顺序调整:不改变已有的字段映射列表,下拉选项中增加新增字段
b.删除字段:如果被删除的字段原已在列表中被选中,则清空来源表字段选择框的值。
c.字段类型或描述变更:更新“类型”列该字段的字段类型或字段描述 (2)数据去向
a.字段顺序调整:字段映射列表中按变更后的去向表字段顺序展示,并保留映射的来源表字段信息。
b.新增字段:字段映射列表中新增行,行序号为去向表中该字段的列序号。针对该行的来源表字段:先使用同名映射匹配是否存在同名的来源表字段,如存在同名字段则来源表字段置为同名字段,如不存在同名字段则清空来源表字段选择框的值。
c.删除字段:删除字段映射列表中的对应行。
d.字段类型变更:更新“字段类型”列该字段对应的值。
e.字段描述变更:更新“描述”列该字段的字段描述。
(3)消息通知框整体提醒
此外,针对来源或去向的表结构变更,消息通知框中会详细提示各类变更情况以及相应的字段。 一键解析Topic字段 进入字段映射模块时默认会解析各Topic的字段名称和字段类型,点击“一键映射Topic字段”会重新解析一次最新的Topic字段名称和字段类型,在Topic schema更新、首次解析不符合预期等情况下可点击此按钮。 同名映射 根据去向表字段名称匹配同名的来源Topic字段名称,若无法匹配则来源Topic字段置为自定义表达式。 同行映射 根据去向表字段序号匹配序号相同的来源Topic字段名称,若无法匹配则来源Topic字段置为自定义表达式。 设置自定义表达式字段类型 如果存在自定义表达式引用来源Topic字段且字段映射未指定类型时,请点击“设置自定义表达式字段类型”按钮设置引用字段的类型,否则任务会运行失败。 来源Topic字段 支持选择Topic字段或自定义表达式。选中Topic字段时,支持输入或选择Topic字段名称,如果来源Topic为空,此处支持手动填写字段名称;如果来源Topic非空,此处默认会自动解析Topic首层字段名称。选中自定义表达式时,请按照格式填写:“表达式” as 列名,支持填写常量、Flink函数、内置变量current_timestamp(表示数据写入时间),示例:current_timestamp as 列名。 字段类型 系统支持推断Topic字段的字段类型。选中某个Topic字段时,会展示该字段的推断类型,如与字段实际类型存在差异,可手动调整切换字段类型。
关于字段类型,规则如下:
- string定义为string
- int、bigint、tinyint、smallint统一定义为bigint
- float、double、decimal统一定义为decimal
- boolean定义为boolean
- row、map统一定义为row
- array定义为array
- time、timestamp、date、byte、varbinary无法解析,统一定义为string
此外,点击复制图标可将来源Topic字段类型批量映射为去向Hive表字段类型,映射规则如下。在推断类型准确性欠佳时可考虑使用此功能。
其映射规则如下:
完成字段映射配置后,点击“下一步”进入高级配置页面。
高级设置
该页面支持参数的填写。参数名称填写格式:source/target.参数名称,source.表示数据来源端参数,target.表示数据去向端参数。示例:source.json.timestamp-format.standard。
6. 配置完成后,点击“保存”按钮即可完成任务配置。
到此这篇sqlldr导入定长文件(sqlldr只导入指定字段)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/sqlbc/46728.html